基于Simhash算法的作业查重系统设计
2020-02-25王法胜李绍民
李 玲, 王法胜, 李绍民
(大连民族大学 信息与通信工程学院,辽宁 大连 116605)
目前高校普遍存在课程作业抄袭的现象,由于部分学生缺乏诚信意识,贪图抄袭带来的便捷,使得教师布置的课程任务无法实现应有的考核效果,因此应该提出有效的方法来遏制这种现象[1]。作业查重是课程形成性考核中的减少抄袭现象的重要手段,能够有效提高课程形成性考核的效果。目前,我国在学位论文查重方面制定了大量规范,通过中国知网平台、万方平台等提供的查重功能,来检测学位论文的重复率,但这类商业化平台在查重时收取费用较高,难以用于数量和频次较多的课程作业查重。目前,在课程形成性考核方面,很少有高校投入资金开发针对课程作业的查重系统,而一些商业化的系统,如北京航空航天大学开发的希冀平台,带有查重功能也仅限于程序设计类课程的代码查重功能。2018年,清华大学推出的作业查重服务已在清华大学全校推广使用[2],有效减少了作业抄袭现象。
针对课程形成性考核中的作业查重问题,本文设计了一种基于Simhash算法的作业查重系统。本系统融入了自然语言处理领域中的Simhash算法,并且联合Bootstrap、jQuery、SSM框架等多种技术进行设计开发。本文设计的系统,在加强课程质量管理、鼓励学生坚持原创意识、提高学生的诚信意识、杜绝作业抄袭和拷贝等学术不端行为具有重要意义。
1 关键技术综述
1.1 Simhash算法简介
Simhash算法最早是由Google提出来用来网页去重的算法,其主要思想是将高维的具有表征文本效果的指纹向量进行降维处理,从而在后续进行文本内容重复率比对时能够大幅度提高其计算的效率[3]。Simhash算法的出现是建立在传统的hash算法之上的,hash算法将原有的文本映射成一系列分散的签名值,但是在后期与其他文本进行相似程度的比对时,如果两篇文档的签名值不相等,只能说明它们不是完全相同的,并不能反映出来实际上存在的差异程度,因此后期提出了能够反映出文本相似度的Simhash算法[4]。Simhash属于一种局部敏感哈希算法(Locality-Sensitive Hashing,LSH)。其主要思路是将原始的文本内容先通过一些哈希映射转换后划分成能够代表该内容的集合,这些集合被分配到哈希表的各个位置,在进行相似性比对时,将待查文本进行哈希映射的操作,得到其在哈希表中的位置,然后根据位置关系将数据进行逐一的线性比对,进而发现与待查数据相似性更高的数据,从而减少海量数据比对时的计算量[5,6]。此外,Simhash算法不仅应用在文本相似度计算方面,还在生物测序数据去重、多媒体数据检索、恶意代码检测等领域有着广泛的应用[7]。
1.2 文本相似度分析的相关研究
文本相似度分析是自然语言处理领域中的一个重要分支,是一项基础性研究,文献[8]对目前存在的各种文本相似度分析算法进行了较为全面的综述性研究。作为最常见的可视的信息载体,文本是一种最为普遍的信息表现形式,因此文本相似度算法应用的范围也十分的广泛。
Orellana G等人[9]所提出的通过文本相似度计算对教学大纲中的内容进行语义比较的方法,能够成功计算高等教学大纲间的相似性,方便解决学生因流动带来的学分验证问题。Soleymanzadeh K等人[10]提出一种释义识别系统,该系统利用机器翻译和通用文本相似性度量的组合作为特征,完成确定一个文本是否是另一文本的重述的分类任务。汤建明等人[11]以文本相似度分析算法为依托,开发了海量网络文本去重系统,能够给浏览网页的用户带来更好的体验。陈江华[12]将文本相似度分析算法应用于对科技项目申报书中文字的重复性检测中,有效地减少了部分科研项目重复申报的问题,同时大大节省了申报书审核的成本,提高了审核的效率。Lemantara J等人[13]提出的在线考试的模型,能够以百分比的形式显示学生答案与正确答案间的相似度,帮助教师更快、更客观地评价作文,同时可以显示学生答案之间的相似度,从而防止抄袭行为的发生。李刚[14]结合网络信息检索系统与查重系统,对数据库中的文本进行挖掘,同时借助遗传算法的思想,实现了网络环境下的中文查重系统。
2 算法设计
2.1 分词插件设计
分词作为自然语言处理领域中的第一道工序,其效果的好坏直接影响了后续的相关工作和结果,因此要选取符合系统需求的分词器。对于本作业查重系统来说,不同专业都存在大量的专业词汇,选取的分词器不仅自身要包含一个很大的词汇库,还要有能够扩展词库的接口。
本系统采用了最新的IKAnalyzer 2012版本,该版本相较于其他版本来说,具有标志化的分词歧义排除算法,这种标志化的算法使得IKAnalyzer分词器不再被认为是单纯的中文词典分词器。IKAnalyzer2012分词器同时支持细粒度和智能分词两种分词处理模式,每秒能够处理大约160万字,处理效率极高,分词器的处理系统同时支持英文字母、数字、中文等多种词汇。目前该分词器在主词典上自带有27万字左右的基础汉语单词量,后期还可以进行多种途径的自定义词汇扩展[15]。该分词器在分词处理能力、分词效果、后续词典优化等方面都能够满足本系统功能开发的需求,其流程如图1。
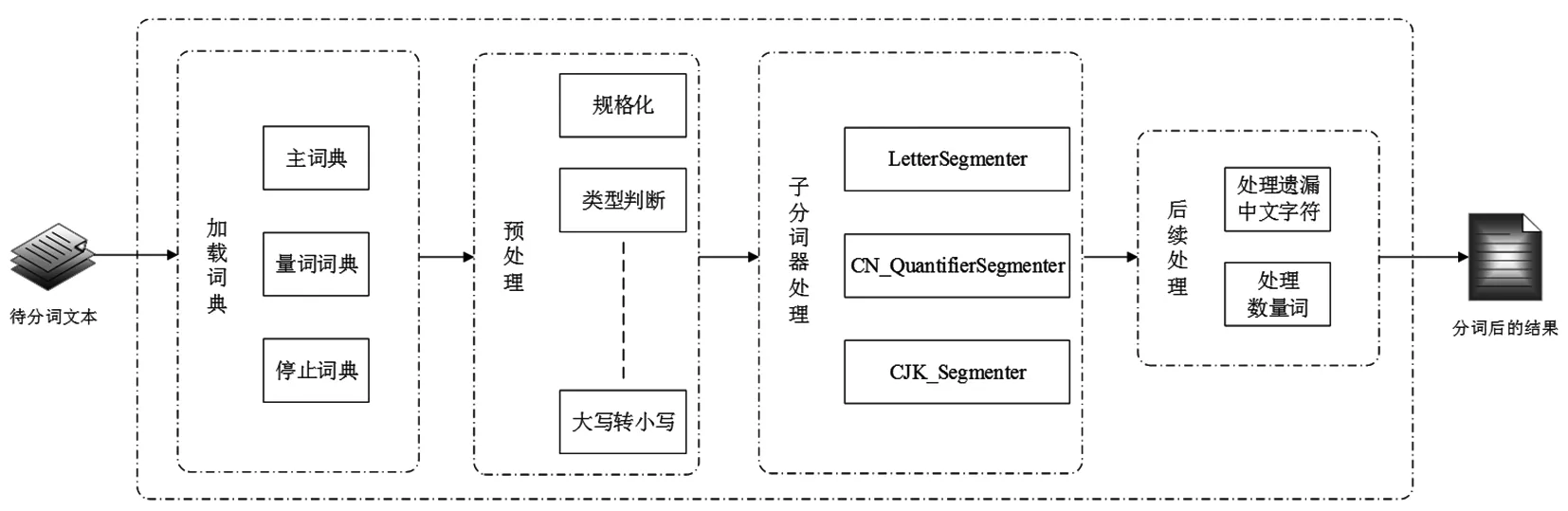
图1 IK分词器流程图
2.2 算法匹配
分词后的结果并不能被计算机所理解,因此要将结果转化成计算机能够理解的,可以表征待查重文本的特征向量,本系统选用的是Simhash算法,具体流程图如图2。

图2 Simhash算法流程图
首先定义一个规定长度的特征数组用来存储后期hash计算产生的hash值,本系统规定的长度为64位。接下来读取数据库中学生提交待查重文本的分词结果,然后对分词结果进行处理,其中包括过滤标点符号、过滤超频词汇等,得出一组能够表征文本的词汇数组。接着对词汇数组中的每个词汇进行hash值计算,随机生成64位长度的01数列。最后赋予每个词汇相应的权重,对词汇的hash值进行加权处理,然后对所有加权后词汇的hash值进行合并和降维处理,得到本篇文档的Simhash签名。通过计算两篇文档对应的Simhash签名的汉明距离可以得到其相似程度。汉明距离指的是两个长度相同的字符串对应位置字符不同的数量,是一种简单有效的计算并度量两个向量之间的距离的方法,其计算公式如下所示[16]:
(1)
式中:⊕表示的是xi与yi进行异或操作,即对应位置两数相同置为0,两数不同置为1,汉明距离就是两个等长的二进制码字之间,位置相同但数值不同的码字的数量,也就是异或操作后得到的1的数量。本系统中,规定汉明距离在0~2之间为严重抄袭行为,3~4之间为中等抄袭行为,5~6之间为轻微抄袭行为。
3 系统的设计与实现
3.1 系统的架构
选择一个合适的架构对系统的高效开发至关重要。因此架构设计是系统开发和实际应用过程中的一个关键步骤,针对不同的系统功能和应用需求,选择合理的系统架构。
本系统总体的设计架构是基于SSM框架进行搭建,前端页面的设计采用了Bootstrap框架,使用最新的jQuery技术、HTML、JavaScript和CSS完成开发。同时采用了B/S模式、Maven工具等进行了系统的联合开发。除此之外,系统中还嵌入了自然语言处理领域中的Simhash算法,以完成抄袭检测模块的功能开发。系统中数据存储采用的是关系型数据库MySQL,可以同时处理大量用户需求,处理超过五千万的相关记录,命令响应的速度快,相较于其他的关系型应用数据库,MySQL是一个完全开源且更加简单快捷易用的关系型数据库,本系统的整体架构如图3。
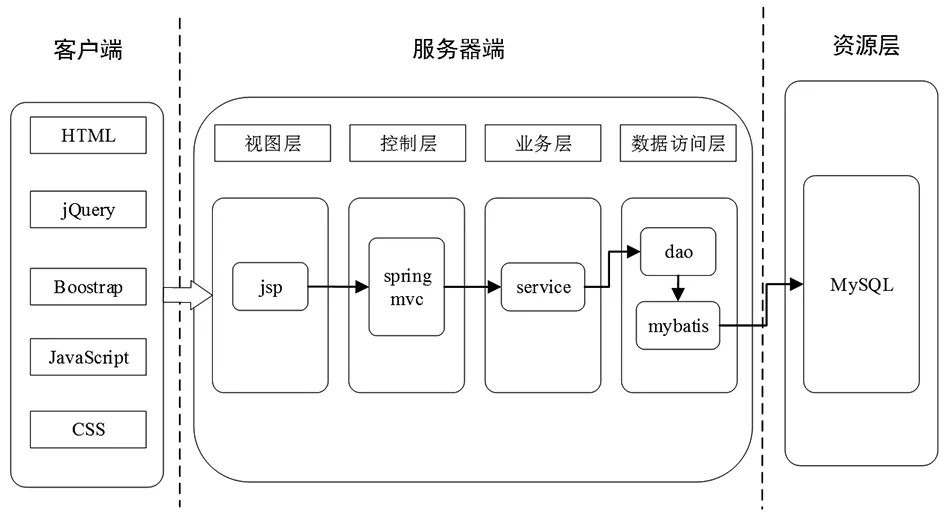
图3 系统整体架构图
3.2 系统模块设计
本系统主要包括用户管理、课程管理和作业查重三个模块,其模块功能图如图4。用户管理模块中被细分为了登录注销和基本管理两个子模块,其中登录注销子模块是面向系统所有的用户,各个用户首先在登录界面中输入注册账号和设置的密码并选择其对应的登录角色,系统将根据用户输入的账号和信息调用身份验证程序进行登录验证,验证的主要内容包括该用户是否存储在数据库中,以及检测输入的密码是否正确,最后是该用户的角色是否对应正确,若以上验证内容有一项存在错误则登录失败,并根据用户系统登录失败的原因进行对应的错误提示,反之则直接进入到相关角色的系统主界面。在用户基本管理子模块中,管理员具有该模块最大的权限,不仅具有和其他用户一样可对个人的基本信息进行查看修改的功能,还可对系统中所有的用户进行查看、删除、修改以及新建系统用户并且赋予其相应的角色类型的操作。
课程管理模块共包含四个子模块,分别是新建课程、查看课程信息、删除课程和修改课程基本信息。其中查看课程信息中可对课程基本信息、课程任务记录和课程作业记录进行查看。管理员拥有该功能模块的全部操作权限,可在线新建课程,并且对现有的课程进行删除、修改和查看相关课程信息。教师用户可查看自己所教授课程信息,如有修改基本信息的需求可在线进行修改。学生用户只拥有查看自己所修课程信息的权限。
作业查重模块只面向教师和学生两个用户。教师可在系统中发布课程任务并且查看已发布的课程任务记录,同时对学生提交的课程作业可进行在线查重批阅。学生用户可查看教师发布的课程任务,并且在规定时间内根据教师发布的课程任务进行作业在线编辑和提交,在教师批阅完之后可以查看自己的作业分数。

图4 系统模块功能图
3.3 数据库的设计
在进行系统的数据库设计时,要在保证系统数据准确的情况下,尽可能的做到实时的传输和存储。系统界面显示的相关数据要从系统的数据库中取出,用户可以通过界面操作直接修改、删除数据库中的对应数据,并且还可在线向数据库里写入数据。针对本系统的需求,设计了admin_tab、stu_tab、tc_tab、user_tab、mission_tab、class_task_tab等15个数据表,分为基础数据表和业务表两类。基础数据表中包括了系统用户信息表、课程信息表等,而课程任务记录表、课程作业记录表属于业务表,系统的E-R图如图5。
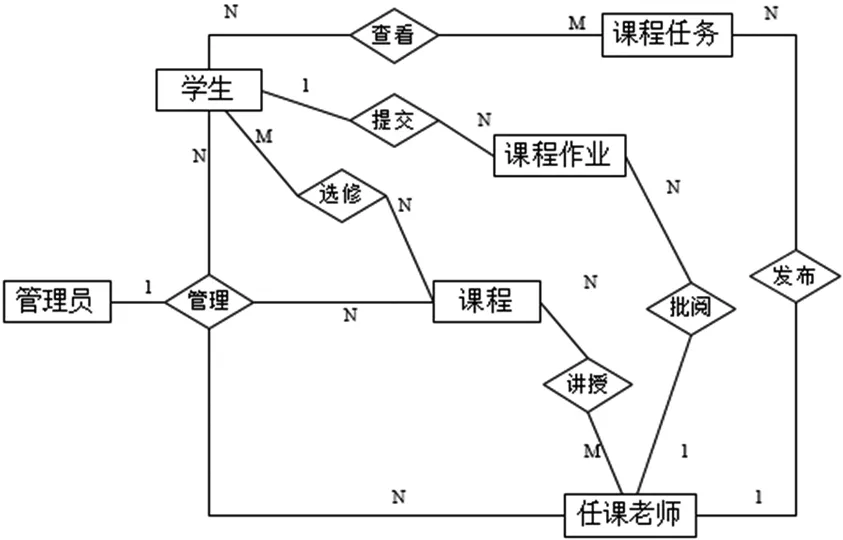
图5 系统E-R图
3.4 系统的实现
在本系统的开发过程中,前端开发使用了Bootstrap和jQuery等技术,并且采用了B/S架构。前后端整合技术选取的是SSM开发框架,其中Spring MVC是基于MVC模式进行设计的用来完成Web前端开发的框架,它给架构的使用者提供了可自主制定的处理器映射器以及视图解析器,相比于其他的Web MVC框架,使用起来更具有灵活性,Spring框架作为业务逻辑层提供原始的URL地址映射以及特定的自主制定的策略,MyBatis框架的连接方法不同于传统的JDBC数据库,它可以通过现有的插件生成DAO层代码[17-19]。Tomcat作为后端Web服务器用来响应HTML页面的访问请求,为了保证能够有序管理系统中的模块和jar包,加入了Maven管理工具[20]。
4 结 语
针对学生和教师使用的教务及作业提交等系统中存在的问题,结合师生日常教学发展中的实际需求,设计并实现了符合实际情况的作业查重系统。设计系统时充分考虑了应用功能性、安全性等多方面的需求,同时,系统中留有接口,方便日后的扩展和维护。该系统的使用能够大大降低教师批阅作业的时间和工作强度,同时能够督促学生认真完成作业,有效减少作业抄袭的现象,为营造良好的学习氛围提供了有力保障。
