基于确定性系数模型与逻辑回归模型耦合的地质灾害易发性评价
——以贵州省开阳县为例
2020-02-24覃乙根杨根兰江兴元鲁鲲鹏李子安
覃乙根, 杨根兰*, 江兴元, 鲁鲲鹏, 李子安
(1.贵州大学资源与环境工程学院,贵阳 550025;2.贵州大学喀斯特环境与地质灾害重点实验室,贵阳 550025)
地质灾害易发性评价又称地质灾害敏感性分析(geological hazard susceptibility),是地质灾害风险评价的基础[1]。近数十年来,随着地理信息系统技术(GIS)的迅速发展,不少学者建立或发展了不同的地质灾害易发性评价模型,其中,单一模型方面,向喜琼等[2]将人工神经网络模型和GIS进行有机整合,对长江三峡示范区(巴东-新滩)的区域地质灾害危险性进行了分析和区划;柳源[3]利用层次分析法对全国地质灾害危险性进行了分析研究;兰恒星等[4]、许冲等[5]、王志恒等[6]将确定性系数(CF)模型应用于区域滑坡易发性和敏感性分析方面的研究;王佳佳等[7]、余国等[8]将信息量模型应用于区域的滑坡易发性及稳定性评价;邢秋菊等[9]、赵良军等[10]基于GIS平台,应用逻辑回归模型进行区域滑坡危险性评价研究。随着定量评价模型的广泛应用,越来越多学者关注不同模型方法的对比和优化研究,杨栓成等[11]、刘邵晨等[12]、魏江波等[13]采用确定性系数模型与层次分析相结合的方法区域地质灾害危险性进行了研究;樊芷吟等[14]对汶川地区,开展了基于信息量、逻辑回归模型以及信息量-逻辑回归耦合模型的地质灾害易发性对比研究;刘光辉等[15]以都江堰虹口乡为例,开展了基于证据权法与确定系数法的滑坡危险区划对比分析。以往研究表明,使用逻辑回归(logistic regression, LR)模型和确定性(certainty factor,CF)模型进行滑坡易发性评估效果较理想因而应用较普遍,但是两种模型也分别具有局限性,CF模型可解决评价因子内部不同特征值对易发性影响的敏感程度,却忽略了各因子对易发性影响的差异性[13],而逻辑回归模型在能很好地确定影响因子之间的权重大小,但不能较好解决评价因子不同特征值对易发性影响的敏感程度问题[14]。因此,将CF模型与逻辑回归模型相结合,能够很好地解决影响因子的权重的确定和异类数据合并的难题。
开阳县地质条件复杂,区内地质灾害频发,根据最新的数据(2018年)显示,开阳共有145处地质灾害隐患点,给人民的生命财产安全造成巨大的威胁。而以往对开阳县地质灾害易发性方面的研究相对较少,因此,对该区的地质灾害类型及分布特征进行研究,划分地质灾害的易发性区域具有十分重要的现实意义。现以贵州省开阳县为研究区,基于GIS的栅格数据模型,分别采用CF模型、逻辑回归模型以及CF模型和逻辑回归模型相耦合的方法,开展贵州省开阳县的地质灾害易发性评价,通过对不同模型的易发性评价方法与预测成果及精度进行对比探讨,探索更为理想的定量评估模型,为县级区域地质灾害易发性评价以及提供理论指导和技术参考。
1 研究方法
1.1 确定性系数模型
确定性系数CF为一个概率函数[11—13],其表达式为

(1)
式(1)中,PPa为事件在a分类中发生的条件概率,即在数据a类单元中灾害点个数与该类单元面积的比值;PPs为事件发生的先验概率,即整个研究区地质灾害隐患点数量与研究区面积的比值。
由式(1)可知,CF的变化区间是[-1,1]。CF越接近1,地质灾害确定性越高,越接近-1,确定性越低;当CF接近0时,表示确定性与区域平均值接近。
1.2 逻辑回归模型
逻辑回归模型是二项分类变量的回归分析模型,描述的是二元因变量和一系列自变量之间的关系[16]。在进行易发性评价时,设P为地质灾害发生的概率,那么Q=1-P为地质灾害不发生的概率。将P/Q取对数为ln(P/Q),则以地质灾害发生概率P为因变量、影响因素集[x1,x2,…,xn]为自变量,建立回归方程:

(2)
式(2)中,α为回归常数;βi(i=1,2,…,n)为回归系数;xi(i=1,2,…,n)为影响因子的指标值,于是可得逻辑回归方程:

(3)
1.3 CF-Logistic回归耦合模型
将CF模型计算得到的评价因子各分级的CF作为Logistic回归分析的指标值,进行二项逻辑回归分析,得到各影响因子的回归系数,在此基础上建立逻辑回归方程,进行地质灾害易发性评价。
2 案例分析
2.1 研究区概况
开阳县地处黔中,地貌呈东西向分布的高原丘陵。开阳县属亚热带季风气候。西部、南部降水量较多,北部降水量偏小。主要水系有乌江、清水江、谷撒河等。县内分布着前震旦系、寒武系、石炭系、二叠系、三叠系、奥陶系和第三系、第四系地层,总体近东西向的黔中白马洞断裂为区内主断裂,褶皱构造具有背斜短而宽缓呈穹状,向斜窄而紧凑呈线状的特点。
开阳县主要发育地质灾害包括滑坡崩塌、泥石流等,根据最新的地质灾害排查数据(2018年)显示,开阳共有145处地质灾害隐患点,其中滑坡70处,崩塌35处,不稳定斜坡32处,地面塌陷和泥石流各4处如图1所示。

图1 开阳县地质灾害分布Fig.1 Distribution of geohazards in Kaiyang
2.2 数据来源
所采用的数据主要包括:贵州省开阳县地质灾害隐患点数据(2018年最新排查成果);30 m分辨率数字高程数据(91卫图助手);1∶5万地质图;Landsat 8 遥感影像(地理空间数据云);由数字高程模型(digital elevation model,DEM)提取出来的坡度、坡向和地形起伏度数据;由地质图提取出来的水系和工程岩组数据;根据岩层倾向与坡向的夹角关系计算得到的斜坡结构数据以及根据遥感影像数据波段反射率计算得到的归一化植被指数(normalized difference vegetation index, NDVI)等。
2.3 评价因子的选取与分级
进行地质灾害易发性评价的基础是选取评价因子。在选取地质灾害发育的因素时应结合野外实地调查资料选取评价因子[17]。通过对开阳县最新的地质灾害排查数据资料的分析,结合对典型灾害点的详细勘察研究,得出开阳县地质灾害主要受地形地貌、地层岩性、地质构造及水系的控制。主要分布于河流两岸以及断层密集的地区,海拔低的地区灾害点数明显高于海拔高的,寒武系地层地质灾害分布数量占总量的58%。
在研究开阳县地质灾害的孕灾环境的基础上,结合前人关于地质灾害影响因素的研究结论[11,14],共选取高程、坡度、地形起伏度、坡向、工程岩组、斜坡结构、断层、水系、NDVI这9个影响因子作为评价地质灾害易发性的指标。结合地质灾害点的发育特征对各因子进行分级,分级情况如图2、表1所示。其中高程、地形起伏度和NDVI因子采用自然间断法对其进行分类。
3 地质灾害易发性评价
3.1 基于CF模型
基于GIS平台,将要素图层转换成栅格数据,并将各图层单元格大小设置为30 m×30 m,将各个评价因子的图层(图2)和地质灾害点分布图层(图1)进行叠加分析,共得到2 217 519个独立的属性单元。
统计每一个分级的面积和各分级所包含的地质灾害点的个数,利用CF模型计算出各分级的CF(表1)。在此基础上进行加权求和,得到各单元地质灾害易发性指数,其计算公式为[15]
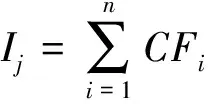
(4)
式(4)中,Ij为第j个评价单元的易发性指数;CFi为第i个影响因子各分级的CF。
3.2 基于Logistic回归模型
随机选取260个(130个发生,130个没有发生地质灾害)独立单元作为易发性评价的统计样本。其中1表示发生,0表示没有发生,将9个影响因子的分级指标值作为自变量,是否发生地质灾害作为因变量,将样本导入SPSS 22.0软件进行二元Logistic回归分析,回归结果如表2所示。逻辑回归分析结果显示,9个影响因子的Sig都少于0.5,说明9个因子有效 (Sig<0.5才能说明样本显著有效[16])。将9个因子的回归系数代入模型,得到易发性评价的逻辑回归公式:

(5)
式(5)中,P为发生地质灾害的概率;x1~9分别表示高程、坡度、地形起伏度、坡向、工程岩组、斜坡结构、断层、水系、NDVI这9个影响因子各分级的指标值。
3.3 基于CF-Logistic回归耦合模型
在CF模型的基础上,将9个影响因子各分级的CF作为自变量,是否发生地质灾害作为因变量,利用SPSS 22.0软件进行二元Logistic回归分析(回归结果见表3),得到逻辑回归公式:

(6)
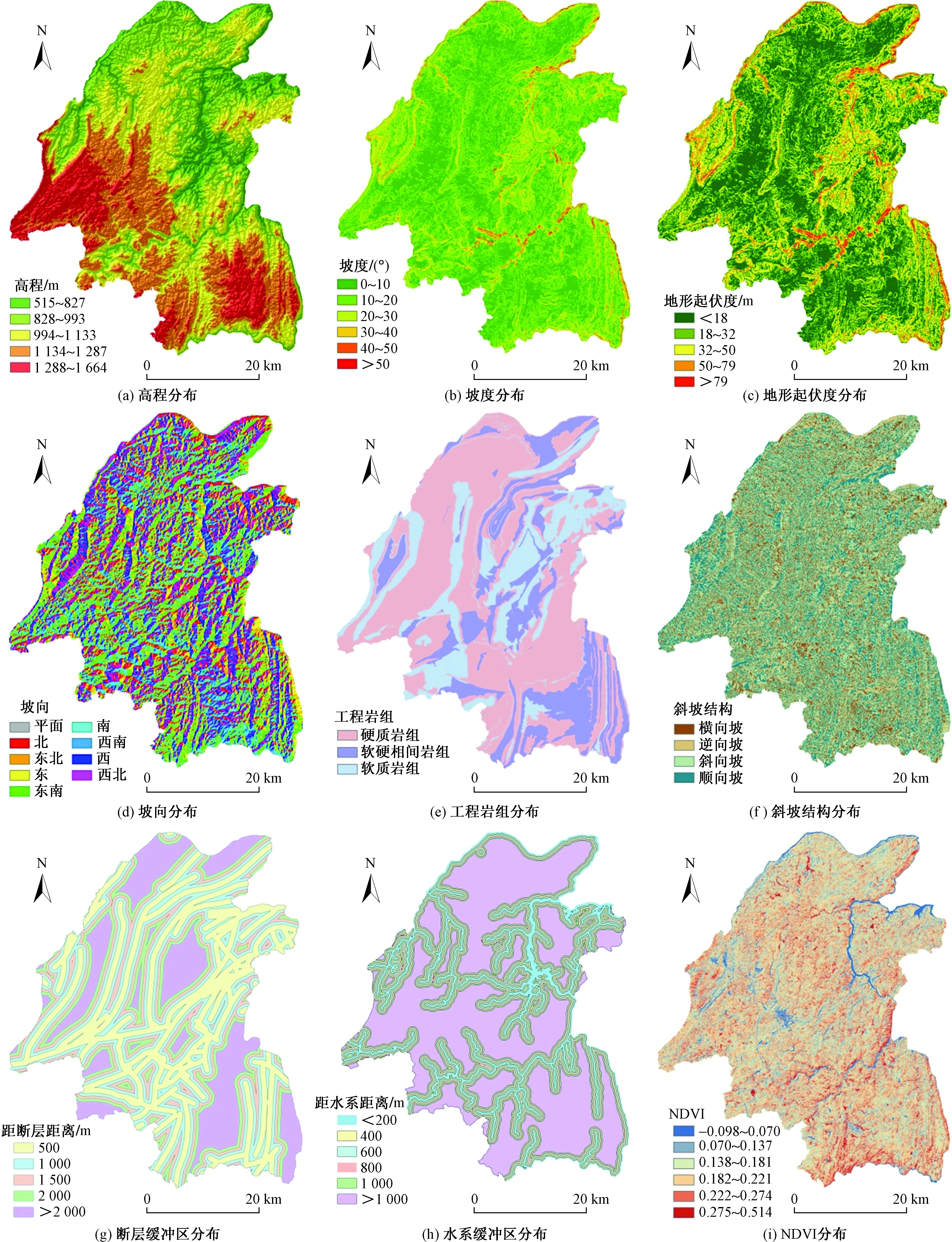
图2 影响因子分级Fig.2 Evaluation of different factors
式(6)中,P为发生地质灾害的概率;x1~9分别表示高程、坡度、地形起伏度、坡向、工程岩组、斜坡结构、断层、水系、NDVI这9个影响因子各分级的CF。

表1 影响因子分级及CF
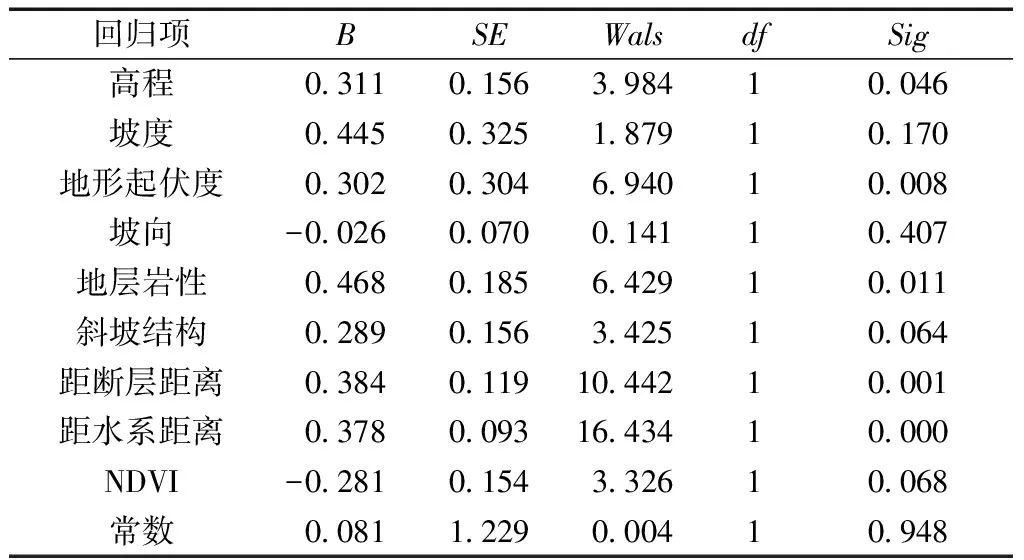
表2 逻辑回归分析结果
注:B代表模型中各因子的回归系数,SE为标准差,Wals为卡方值,df为自由度,Sig表示显著性。

表3 基于确定性模型的逻辑回归分析结果
注:B代表模型中各因子的回归系数,SE为标准差,Wals为卡方值,df为自由度,Sig表示显著性。
4 易发性评价结果
根据式(4)~式(6),利用ArcGIS的栅格计算器工具叠加计算出各单元的易发性指数。并根据ArcGIS自带的自然间断法将开阳县易发性分为4个等级:高易发区、中易发区、低易发区、极低易发区(图3、表4)。
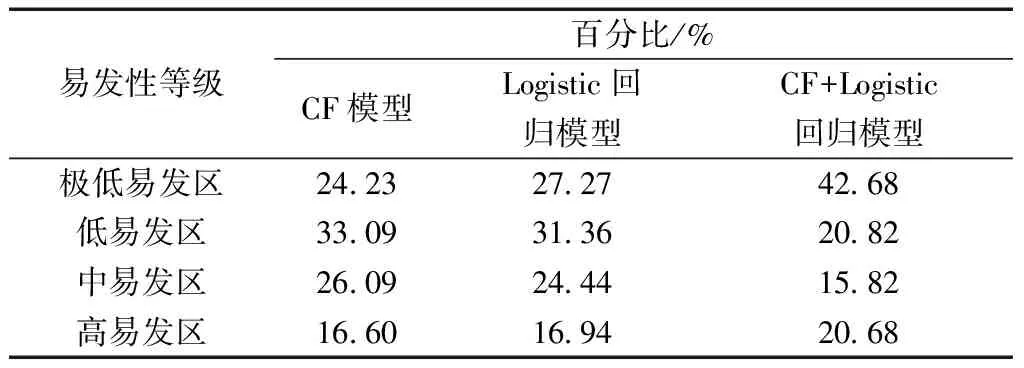
表4 易发性评价结果

图3 模型评价结果Fig.3 The evaluation results of each model
由图3可知,地质灾害高易发区主要分布于中部花梨镇、西部金中镇等河流以及断层密集的地区。极低易发区主要分布于南部龙岗镇、北部楠木渡镇等地形较平缓、地质条件较好的地区。由表4可知,CF模型和Logistic回归模型的易发性各分级的面积比相近;CF和Logistic回归耦合模型中,高易发区面积占比为20.68%,高于CF模型的16.60%和Logistic回归模型的16.94%;极低易发区的面积占比为42.68%,高于CF模型的24.23%和Logistic回归模型的27.27%。
5 模型精度评价对比
5.1 灾害点分布状况
通过统计各易发性分级下的灾害点数量占总灾害点数量的百分比,可以对评价结果的准确性进行检验[18],统计结果如表5所示。
由表5可知,CF和Logistic回归耦合模型中,有86.90%的地质灾害点落在中-高易发区,高于CF模型的82.89%和Logistic回归模型的80.65%。表明采用CF和Logistic回归耦合模型的评价结果比CF模型和Logistic回归模型更合理。
5.2 ROC曲线分析
基于SPSS 22.0平台,进行成功率曲线(receiver operating characteristic, ROC)分析,对评价模型的精度进行检验(图4),ROC曲线的线下面积(AUC)越大,表明模型的准确性越高[19-20]。由图4可知,采用CF模型的AUC为0.853,Logistic回归模型的AUC为0.871,CF和Logistic回归模型结合的AUC为0.895,表明采用CF模型和Logistic回归相结合模型的结果成功率要高于分别采用CF模型和Logistic回归模型的结果。

图4 各模型ROC曲线Fig.4 The ROC curve of each model
6 结论
分别采用CF模型、Logistic回归模型以及两者相耦合的方法,开展开阳县地质灾害易发性评价研究,并利用灾害点的分布和ROC曲线对评价精度进行检验,得出以下结论。
(1)耦合模型较CF模型和Logistic回归模型的评价结果准确度更高。耦合模型中,中-高易发区的灾害点百分比高于CF模型和Logistic回归模型的占比。说明耦合模型能够很好地解决影响因子的权重的确定和异类数据合并的难题。
(2)通过对比分析9个因子各特征值的CF和回归系数B的大小可知,地层岩性、距断层距离、距水系距离3个影响因子对易发性贡献较大。特别是在距离断层1 000 m内,距离水系800 m内和软质岩组较易发生地质灾害。
(3)耦合分析结果表明:贵州省开阳县地质灾害高易发区主要分布于花梨镇、金中镇等河流以及断层密集的地区,面积为414 km2,占总面积的20.68%,极低易发区主要分布于龙岗镇、楠木渡镇等地形较平缓、地质条件较好的地区,面积为855 km2,占总面积的42.68%。
