分布式作业调度管理技术研究
2020-02-20徐炫东杜舒明吴永欢
徐炫东,杜舒明,吴永欢
(广州供电局有限公司,广东 广州 510620)
0 引 言
随着云计算、移动互联网、物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代。这些新技术的兴起,正深刻改变着当前的市场格局。
数据的爆炸式增长和价值的扩大化,将对企业未来的发展产生深远影响,数据将成为企业的核心资产。越来越多的企业开始重视大数据战略布局,重新定义自己的核心竞争力,从数据中揭示规律,了解过去、知悉现在、洞察未来,让一切业务数据化,同时也让企业数据业务化。
在这种新的技术革命形势下,遵循“互联网+”的模式,基于云计算、云服务的理念,建设包含技术平台、数据应用平台、数据产品、数据服务及数据监控平台等全栈式大数据平台尤为重要,可为企业数字化转型、业务创新、决策支撑、流程优化及风险监控打下坚实的基础。
公司大数据平台将在Hadoop和云计算等技术的基础上,对现有量收系统、数据分析综合服务平台的历史数据、数据模型、报表应用等进行移植,全面整合公司业务数据。数据来源涵盖公司所有的生产和管理系统,并可接入同业及相关市场甚至互联网信息,建立清晰的企业画像、用户画像及业务画像,让数据形成资产、形成驱动力,真正做到让一切业务数据化,同时也数据业务化,从而逐步蜕变成国内一流、世界领先的大数据平台。
1 总体需求理解
大数据平台需支持多应用管理,即支持对应用的服务级别管理(SLA),能够实现应用的访问资源控制,支持资源隔离,同时支持多租户功能,如全局管理平台,实现租户的准入、操作、分组、分层、授权以及隔离等功能。
大数据平台应具有统一运维监控,可以图形化实现安全管理、用户管理、监控运维、服务调度、应用部署、资源管理、作业编排以及服务接口等。
大数据平台应同时支持作业调度管理,即实现统一的作业调度与编排管理功能,支持使用工作流的可视化方式对工作任务进行统一编排和调度,同时支持作业的资源管理、流程管理、任务管理、数据管理、应用管理、租户管理以及多ETL调度任务的部署和并行处理等功能。
2 核心功能
2.1 数据质量管理
2.1.1 数据采集
首先,互联网上的数据与传统的数据库中的数据不同。传统的数据库都有一定的数据模型,可以根据模型具体描述特定的数据,同时可以很好地定义和解释相关的查询语言。而互联网上的数据非常复杂,没有特定的模型描述,每一站点的数据都各自独立设计,且数据本身具有自述性和动态可变性。
其次,要解决Web上的数据查询问题。因为如果所需的数据不能有效得到,对这些数据进行分析、集成和处理就无从谈起。
2.1.2 数据清洗
(1)数据分析。数据分析是指从数据中发现数据的普遍规则,如业务规则、字段域等。通过对数据的分析,可定义数据清洗的规则,并选择合适的算法,如血缘分析、影响分析等。
(2)数据检测。数据检测是指根据预定义的清洗规则和相关数据算法,检测数据是否正确。例如,检测记录是否是重复记录,是否满足字段域、业务规则,字段是否齐全等。
2.1.3 数据修正
数据修正是指手工或自动修正检测到的错误数据、处理重复的记录及补全数据等。
对于数据清洗应该满足:数据清洗应该能检测和消除所有主要的错误和不一致,包括单数据源和多数据源集成时;数据清洗方法能被这样的工具支持,人工检测和编程工作要尽可能少,并具有可扩展性。
2.1.4 数据融合
在信息化建设过程中,经常出现数据集成或融合问题。数据采集与清洗后的数据,需要进行融合使用。
数据融合使用过程中,通常会遇到如下3种情况。
(1)各个数据源中所有的原始数据合并到一个新的数据源中,通常用于数据仓库。数据仓库作为新的数据源进行更全方位的数据分析,提供给前端应用使用。
(2)各个数据源中所有的原始数据并不合并到一个新的数据源中,但要求各个数据源中所有的原始数据作为一个整体数据源供用户使用。该情况的出现主要是不同的企业或部门之间的数据很难打通,如银行与房企、社保与医院等。
(3)前两种情况同时存在。这种情况的出现,常见于智慧城市建设过程中不同部门不同领域的各种数据进行相互集成。
2.2 多应用管理
大数据平台对企业级用户提供多应用场景的支持。如通过Stream提供实时数据计算场景支持,通过Inceptor提供批处理场景支持,通过Hyperbase提供在线数据服务场景支持,通过Discover提供数据分析和挖掘场景支持。
大数据平台通过云平台系统实现大数据平台多应用管理,支持对应用的服务级别管理(SLA),实现应用的访问资源控制,支持资源隔离。
云平台系统基于Docker容器技术,支持一键部署各个组件,支持优先级的抢占式资源调度和细粒度资源分配,让大数据应用轻松拥抱云服务,满足企业对于构建统一的企业大数据平台来驱动各种业务的强烈需求。
2.3 多租户管理
在实际业务开展过程中,面对的不同应用需求,通过集群管理方式,满足业务全天候(7×24 h)服务,可以结合公司资源管理系统,快速、动态、灵活部署业务,随需销毁或创建集群。
在保障资源安全的情况下,隔离方面需要通过资源管理系统对计算资源和内存资源进行管理,避免不同应用、不同服务互相抢占资源。
同时,在实际业务过程中,逢大型节日、特定周期业务迎来峰值,需要通过在已申请的资源配额里进行资源动态分配,合理归还,保障各业务系统都有合理资源可用。
对不同的租户操作员进行分组分类分级管理,利用Kerberos和LDAP对租户应用授权,支持对计算资源和内存资源的管理能力,避免高消耗服务争抢资源,设置租户的数据访问能力,实现数据隔离。
2.4 统一监控平台
本方案提供统一的运维监控服务,主要通过云计算系统实现,而云计算系统的核心是Docker和Kubernetes。本方案涉及的所有软件的部署都通过Docker打包成镜像文件,以便快捷地部署实施。内部系统通过镜像数据接口交互层进行交互,通过外部接口层纳入集团运维平台进行统一监控。
整个架构通过Docker打包,并提供服务接口,这种服务接口分为两层[1]。(1)镜像层:①提供接口文件;②提供数据接口。(2)外部接口层;①提供API;②提供URL嵌入;③提供数据接口;④提供XML接口(包括定制XML、JSON等);⑤ESB接口。
整个接口层的设计便于产品之间和系统之间的交换,也便于整个架构对接IBM Tivoli、BMC ControlM等监控平台,引入监控或者外推监控,更好地融入公司的监控体系,便于统一监控。
2.4.1 Hadoop集群自动化部署
大数据平台提供集群自动化部署服务。用户只需要安装Manager管理平台软件,就可以在友好的图形化界面上安装、部署和配置所需要的服务。整个安装过程不需要用户使用任何终端命令或者代码。
平台提供了强大的在线扩容功能,不需要宕机停库,不需要停止业务,就可以添加新的节点实现扩容。节点添加完成后,可以立即对新添加的节点进行角色分配,一旦配置成功,则新加的节点会马上投入运算。扩容后的数据节点不需要停机进行数据重分布,系统自动选择空闲时间进行数据重新分布。同时,扩容的操作可以方便地在界面进行操作。
2.4.2 Hadoop集群资源管理
大数据平台提供计算任务管理和作业管理,包括作业的上传、配置、启动、停止、删除和状态查看等功能。
在大数据平台中,资源可以从多个方面进行管理。从资源管理模块YARN的层面,用户通过配置不同的Scheduler定义不同的资源使用策略,目前支持FIFO Scheduler、Fair Scheduler以及 Capacity Scheduler,实现作业动态调整、支持对任务系统资源占用进行实时调配以及改变作业调度优先级等操作。
2.4.3 图形界面方式多租户管理
用户可以使用图形化界面配置多租户的用户、组的权限。管理员用户可以新建、编辑用户的信息。同时,用户可以按需创建、按需销毁计算集群,且创建集群时只需要指定所需计算资源,无需指定具体的物理机器。
2.5 作业调度管理
Trinity产品充分支持集团数据服务技术方面的技术需求,数据流架构图如图1所示[2]。
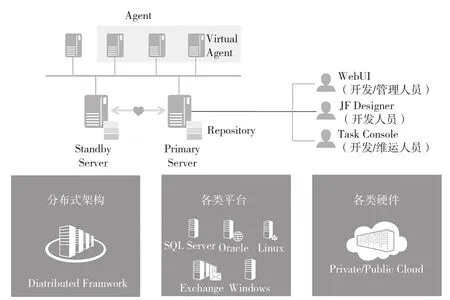
图1 数据流架构图
Trinity提供功能完整、性能优异的ETL框架支持平台建设。针对数据的预处理和中间的转换清洗,包括写入目标时针对异常数据的捕获。整个过程由Trinity提供的调度平台和元数据管理平台提供支撑,让各部分之间紧密合作又各司其职。
针对此项目复杂的业务系统和管理,Trinity提供完善的调度功能,以更好地对各个模块进行良好调度管理,相应逻辑如图2所示。
调度平台是平台的数据流核心,让相关的业务系统、处理系统按照一定的业务逻辑,在客户的安排下像流水线一样,或串行或并行,按照一定的依赖关系,在每日每周定时触发,依次执行。Trinity提供完善的接口和管理模块,让众多的作业管理简易高效。
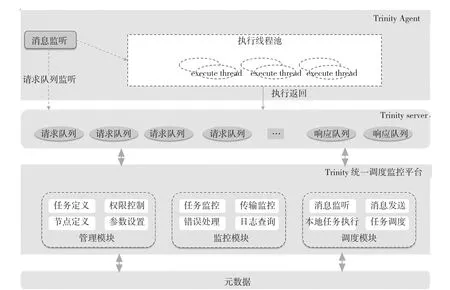
图2 相应逻辑
3 结 论
大数据分布式作业调度的应用场景和ETL的定义过程、数据引擎和业务场景的需求有着重要关联。分布式调度过程通过场景化驱动逐步完善,电网企业大数据的作业调度在满足通用调度后发现存在数据解释、细粒度更新延迟等问题,也开启了逐步迭代的完善过程。
