动态模糊粗糙特征选取算法*
2020-02-20刘阳明赵素云李翠平
倪 鹏,刘阳明,赵素云+,陈 红,李翠平
1.中国人民大学 数据工程与知识工程教育部重点实验室,北京 100872
2.中国人民大学 信息学院,北京 100872
1 引言
近年来,粗糙集理论因不需要太多额外的知识且容易理解,而获得了较多的关注。大量的基于粗糙集的挖掘技术被提出[1-10]。其中,大部分的方法基于同一个前提:数据是静态的。一旦数据随着时间和空间动态地更新,这些静态方法的学习结果已不适用,需要重新扫描更新后的数据集重新计算。显然,重新扫描整个数据集的操作导致时间与空间的浪费,甚至数据规模较大时,这些静态方法不再适用[11]。
增量学习是一种适用于增量数据的数据挖掘方法,该方法通过分析新增数据与已有数据的结构及关系来更新已有的学习结果,避免重新扫描整个数据集,从而大大降低了计算量,提高了计算效率[12-17]。近年来,为了解决数据的动态增长,已有很多学者将增量学习的思想引入粗糙集的应用研究中[4,11,18-22]。
目前,基于粗糙集的增量学习方法分为三种:知识表示的更新、规则约简的更新和特征选择的更新。首先,知识表示的更新方法是指在动态数据集中快速有效地更新粗糙近似表示。比如,一些学者探索了基于不同粗糙集扩展模型的更新上下近似的方法:粗糙集[20,23]、紧邻粗糙集[24]、优势关系粗糙集[25]、贝叶斯粗糙集[26]、决策粗糙集[11]和粗糙模糊集[18,27]等。以上这些更新方法针对数据示例的逐个更新、数据示例的批量更新、特征的增减更新等不同的情况,分别讨论分析了粗糙近似知识表示的相应增量学习机制。其次,一些学者在规则约简更新中提出了增量的更新方法。其中,一些增量的方法只考虑了在一个个添加示例的情况下规则的更新方法[28-30]。考虑到数据更新多是批量更新的,一些学者研究了一组组添加示例的过程中学习规则的更新[31-32]。此外,有一些规则学习的增量方法针对的是属性集的更新[11,25,33]。
相较于其他两种方法,特征选择的动态更新的研究较少。一些学者提出了增量约简算法针对数据集中数据一个个的增加的情况[22];还有一些学者提出的增量算法解决数据一组组增量的情况[21]。然而这两种方法只考虑离散值数据集的动态变化情况。虽然有学者提出的增量算法针对的连续值数据集[34],但是该算法针对的是属性集更新的情况。
通过以上分析可以看出,目前尚没有针对连续值数据示例动态改变的属性约简的算法。考虑到模糊粗糙集技术是处理连续数据的有效工具,本文提出了一个基于模糊粗糙集的增量属性约简算法,来解决动态连续值数据集上的属性约简问题。当前,主要关注在数据集示例的动态增加。
首先,通过分析添加示例前后模糊正域的变化,提出了模糊正域计算的增量机制。基于这个增量机制可以通过避免在动态数据集上的冗余计算,显著地减少计算时间。然后,基于严格的理论推导发现了已有约简的辨识能力改变的关键数据。这些关键数据的发现使得在有限的数据上快速更新已有约简变得可行。最后,提出了一个增量属性约简算法。数据实验表明了该增量算法是有效且高效的,特别是在高维数据集上效果更加突出。
2 模糊粗糙集相关研究
本章简单回顾一些模糊粗糙集及其经典的约简算法。关于该理论的更多细节,可以参考文献[35-38]。
2.1 模糊粗糙集简介
数据集可以描述成一个决策表,表示成一个三元组DT=<U,R,D>。这里U是一个非空示例集{x1,x2,…,xn}。每个示例由一组条件属性R={a1,a2,…,am}以及一组决策属性D来描述。决策属性将论域划分为q个决策类U/D={D1,D2,…,Dq},这里U=,且任意两个决策类相交为空。
如果R是可以模糊化的(如连续值属性),那么决策表DT=<U,R,D>表示一个模糊决策表。在模糊决策表上,粗糙集被推广为模糊粗糙集。模糊粗糙集是融合了粗糙集和模糊集的概念而提出的理论。模糊粗糙集不仅将近似对象从离散集扩展到了模糊集,而且将等价关系扩展到了模糊相似关系。
定义1对于P⊆R以及给定的三角模T,属性子集P的模糊相似关系可定义为P(∙,∙)。对于任意x,y,z∈U,P(∙,∙)满足:(1)自反性(P(x,x)=1);(2)对称性(P(x,y)=P(y,x));(3)T-传递性(P(x,y)≥T(P(x,z),P(z,y)))。
例如,模糊相似关系可以按照如下方式计算得到:r∈P,∀x,y∈U,P(x,y)=minr∈P(r(x,y)),这 里r(x,y)=1-(max(r(x),r(y))-min(r(x),r(y)))。此时,P(∙,∙)即为属性子集P所描述的模糊相似关系,它满足自反性、对称性和TL=max{0,x+y-1}三角传递性。
模糊粗糙集定义了模糊上下近似概念,如下。
定义2给定模糊决策表DT=<U,R,D>,对于A⊆U,那么模糊上、下近似定义如下:

在模糊粗糙集中,整个论域上的粗糙度量方式之模糊正域定义如下。
定义3给定模糊决策表DT=<U,R,D>,示例x∈U的模糊正域定义如下:

继而,决策属性D对条件属性子集P⊆R的依赖度可以定义如下。
定义4给定模糊决策表DT=<U,R,D>和∀P⊆R,决策属性D对于属性子集P的依赖度定义如下:

该定义度量了属性子集P⊆R相对于决策属性的依赖程度。
2.2 模糊粗糙集基本性质讨论
本节深入讨论了模糊粗糙集的一些性质。
性质1依据定义2,给定模糊决策表DT=<U,R,D>和∀A⊆U,示例x∈U相对于A的下近似定义可以简化为:
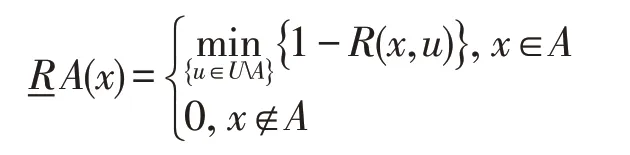
证明具体证明,请参考文献[38]。 □
性质1给出了下近似的几何意义。即x属于它所在的决策类的,下近似为离x最近的异类示例点u的距离;x属于其他决策类的,下近似为0。基于此,可以得到性质2。
性质2依据定义3,给定模糊决策表DT=<U,R,D>,示例x∈U的正域可以简化为。这里,[x]D={u∈U|D(x)=D(u)},即[x]D表示与x属于同一决策类的示例集。
证明根据性质1和定义3易得。 □
性质2表明了模糊正域和下近似之间的关系。下面的性质进一步讨论了依赖度随着属性的增加是如何变化的。
性质3给定模糊决策表DT=<U,R,D>,如果P⊆Q⊆R,那么。
证明对于P⊆Q⊆R,有:

性质3表明了依赖度函数随着属性的增加是单调不减的。这一结论是设计属性约简启发式算法的理论根据。
2.3 基于依赖度的属性约简
约简的核心思想是找到一个最小的属性子集,该子集保持了全属性集的辨识能力。约简的定义如下,更多的细节可以参考文献[33,37-38]。
定义5给定模糊决策表DT=<U,R,D>和∀P⊆R,当P满足条件:(1)∀a∈P,时,称P是模糊决策表的一个约简。
基于依赖度经典的非增量属性约简算法,简写为CAR(classical attribute reduction),已被提出,并得到广泛的应用。
算法1经典约简算法(CAR)
输入:DT=<U,R,D>
输出:red。

3 模糊粗糙集上的增量机制
给定一个动态的模糊决策表DT=<U∪ΔU,R,D>,其中U={x1,x2,…,xn} 为原始实例,ΔU={xn+1,xn+2,…,xn+s}。基于第1章的概念和算法,针对增量数据,需要重新计算模糊正域,既费时又存在重复的计算。因此,本章提出了几个基本概念的增量机制,从而实现动态快速更新模糊正域。
3.1 模糊正域增量机制
首先,在动态数据集上计算更新后的模糊正域POSU∪ΔU(x)很有必要。这是计算依赖度的先决条件。
定理1给定模糊决策表DT=<U,R,D>,如果一些新示例ΔU={xn+1,xn+2,…,xn+s}加入进来,那么:
(1)如果x∈U,则:

(2)如果x∈ΔU,则:
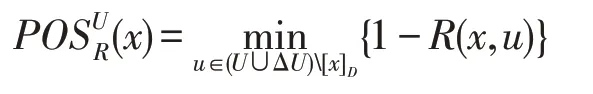
证明依据性质2,对于x∈ΔU的情况,很显然成立。
对于x∈U的情况:

由此,定理1得证。 □
定理1理论分析并给出了一个快速更新模糊正域的方法,从而避免了递增动态数据集上的模糊正域的冗余计算。
3.2 增量关键示例集
基于定理1,可以很快地得到POSU∪ΔU(x)。并且发现,对于模糊正域来说,存在一个增量关键集。
定义6给定模糊决策表DT=<U,R,D>和P⊆R如果一些新示例ΔU={xn+1,xn+2,…,xn+s}加入进来,那么令,称之为增量关键示例集。
由定义6可知,如果x∉ΔS,那么。这意味着已经达到最大。因此,只需要在x∈ΔS如何选择属性。
4 基于模糊粗糙集的增量属性约简
本章基于以上增量机制,设计了一个增量约简算法,简写为IAR(incremental attribute reduction),见算法2。
算法2基于依赖度的增量约简算法(IAR)


5 实验分析
本章构造了一些对比实验。使用的数据集来自UCI数据库(https://archive.ics.uci.edu),数据的详细信息见表1。实验环境为Ubuntu release 16.0,Intel®CoreTMi7-4790 CPU@3.60 GHz,8 GB内存。编程语言为C++。

Table 1 Description of datasets表1 数据集信息描述
实验中对比了一种非增量的Naive依赖度算法,它在新数据到来时并不更新经典依赖度算法,而只是利用之前的约简作为新约简的候选,这个算法简写为NonIAR,在本章中NonIAR和CAR均被用来与IAR进行对比。实验中每个数据集被平分为两份。一份看作是原始数据,另一份看作是新增的示例集。
NonIAR算法设计如下:
算法3非增量的Naive依赖度算法(NonIAR)

5.1 执行时间对比分析
三种算法的执行时间(单位:s)的比较结果见图1、图2。
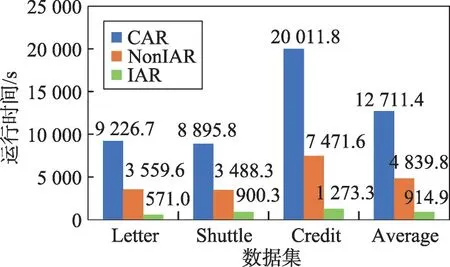
Fig.1 Execution time on low dimensional data图1 低维数据上的运行时间图

Fig.2 Execution time on high dimensional data图2 高维数据上的运行时间图
从图1和图2中可以观察到NonIAR相比CAR已经快了不少,但IAR更快。这说明IAR明显加速了基于依赖度的约简算法的速度。
进一步分析图2,发现在高维数据上IAR加速更加明显,这表明IAR更适合高维数据的属性约简。
5.2 约简效率对比分析
在本节中,将比较CAR、NonIAR和IAR的约简效率。比较的结果呈现在表2与表3中。在表2与表3中,这三个算法的约简率都是相似的。在低维数据上,例如在表2的数据集上平均约简率依次为0.532/0.532/0.569;在高维数据上,例如在表3的数据集上平均约简率依次为0.004/0.005/0.003。这说明这三个算法有着相近的降维能力,甚至在高维数据上,增量算法表现出的能力更强。

Table 2 Comparison of reduction rates on low dimensional data表2 低维数据上约简率的比较
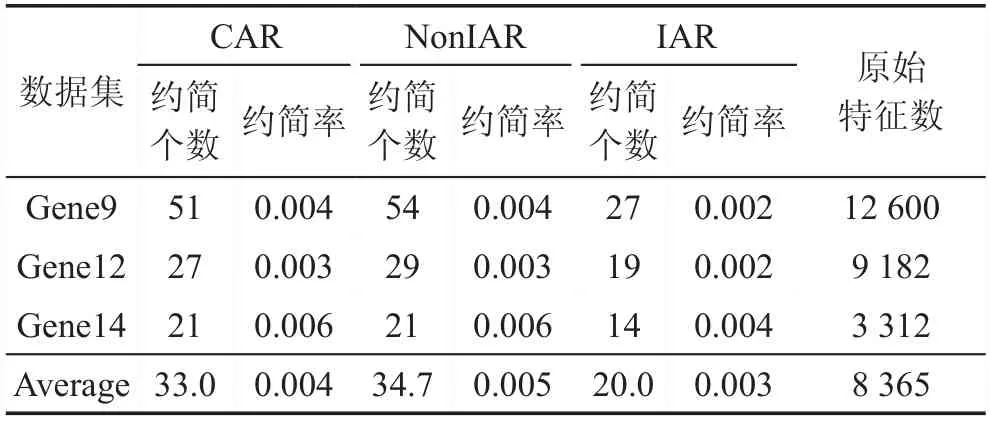
Table 3 Comparison of reduction rates on high dimensional data表3 高维数据上约简率的比较
5.3 约简分类能力对比分析
本节应用KNN(K取3)分类算法来检验CAR、NonIAR和IAR的约简分类能力[39],其中采取五折交叉验证来确保分类结果的公平性与稳定性。分类比较的结果在表4、表5中。
在表4和表5中,很容易看出来,这些算法有着相近的平均分类准确度。比起全集属性来说,差别并不是很大。
综上所述,本文提出的增量约简算法可以在节省时间的同时,获得与非增量算法相近分类性能的约简。

Table 4 Comparison of classification accuracy on low dimensional data表4 低维数据上分类准确度的比较 %

Table 5 Comparison of classification accuracy on high dimensional data表5 高维数据上分类准确度的比较 %
6 结束语
本文提出了基于模糊粗糙集增量属性约简算法,本文主要有以下特点:
(1)提出了模糊粗糙集中的一些概念的增量机制,并且有着严格的理论推导,这是设计增量属性约简算法的基础。
(2)基于增量机制,提出了一个增量约简算法。算法有效地利用已获得学习结果,比如模糊正域与约简,避免大量重复的计算。
(3)实验结果验证了提出的增量算法的高效性和有效性,特别是在高维数据集上增量算法表现更为高效。
