基于冲突检测的高吞吐NVM存储系统
2020-02-19牛德姣刘佩瑶陈福丽
蔡 涛 王 杰 牛德姣 刘佩瑶 陈福丽
(江苏大学计算机科学与通信工程学院 江苏镇江 212013)
存储系统是当前计算机系统的瓶颈,近年来出现了一系列新兴的非易失性存储器[1-5](non-volatile memory, NVM),如3D-Xpoint,PCM(phase change memory),Battery-backed NVDIMMS,FeRAM(ferroe-lectric RAM)等,这些NVM存储设备具有接近内存(dynamic RAM, DRAM)的读写速度和支持字节寻址等特性,成为解决存储系统性能瓶颈的重要方法,但这些特性也给现有的存储系统管理方法带来了极大的挑战.
由于传统存储设备缺乏处理能力,现有存储系统需要依赖文件系统利用主机CPU管理访问请求,并使用锁机制实现访问请求之间的互斥;但文件系统无法获得存储设备和数据分布的特性,缺乏针对NVM存储设备的特性的优化机制;文件系统的锁机制是以文件为管理单位,这限制了多个访问请求的并发执行,无法利用NVM存储设备内部多个通道的并发执行能力;同时使用锁机制,需要将相应的进程在阻塞和就绪状态之间进行调度,所需的大量时间开销严重影响了NVM存储系统的IO性能;当前NVM存储设备还是使用PCIe(peripheral component interconnect express)或SAS(serial attached SCSI)等接口,这些相对NVM存储器件较慢的接口是影响NVM存储设备IO性能的瓶颈,但现有存储系统只能借助主机CPU完成访问请求的管理任务,并通过存储设备接口获取数据状态,这需要在存储设备和主机之间频繁地传输数据,从而进一步加重了存储设备接口对NVM存储系统IO性能的影响,同时还给主机CPU带来了很大的计算压力.总的来说,NVM存储设备接近DRAM的数据读写速度使得现有IO栈(IO stack)成为影响NVM存储系统IO性能的重要因素,相关研究[6]表明在用于NVM存储系统时IO系统软件的开销占总开销的94%以上;而NVM存储设备具有较强的嵌入式处理能力,具备自主完成管理访问请求的基础,同时内部拥有多个可以并发的访问通道,这给增加执行访问请求并发度、提高NVM存储系统吞吐率提供了良好的基础,但现有存储系统还缺乏相应的优化机制.
首先给出了当前NVM存储系统相关的研究,分析了提高存储系统吞吐率的相关策略.接着分析存储系统中现有基于锁的访问请求管理机制,在此基础上设计了基于冲突检测的高吞吐NVM存储系统(HTPM).并在开源的NVM存储设备模拟器上实现HTPM的原型,使用Filebench和Fio等通用测试工具对HTPM的吞吐率和IO性能进行测试与分析,验证HTPM的有效性.
本文的主要贡献如下:
1) 将存储系统访问请求管理功能从文件系统迁移到NVM存储设备中,能利用NVM存储设备支持字节访问和支持多通道读写等特性,缩小执行不同访问请求时需要互斥的数据块粒度,提高访问请求的并发执行能力.
2) 使用基于存储设备的冲突检测方法代替基于锁的文件系统访问请求互斥机制,能有效增加存储系统执行访问请求的并发度,提高存储系统的吞吐率.
3) 利用NVM存储设备的嵌入式处理能力,自主管理访问请求,减少NVM存储设备和主机之间传输的数据量,缓解NVM存储设备接口对存储系统IO性能的影响,减轻主机CPU的负担.
4) 利用NVM存储设备内具有能并行访问的多个通道,增加执行访问请求的并发度,提高NVM存储系统的吞吐率.
5) 实现基于冲突检测的高并发NVM存储系统的原型HTPM,使用Filebench中的Webserver,Varmail,Fileserver负载测试吞吐率,使用Fio测试顺序读写和随机读写的IO性能,结果表明HTPM与PMEM相比最高能提高31.9%的IOPS值和3.2%~21.4%的IO性能.
1 相关工作
VM存储设备具有低延迟、支持字节读写和接近内存的传输速度等特性,研究者们针对这些特性开展了大量的研究.下面分别从NVM的新型文件系统和构建NVM与DRAM的混合内存2方面介绍主要的研究工作.
1.1 针对NVM的新型文件系统
Dulloor等人[7]设计了一种新型的轻量级POSIX(portable operating system interface of UNIX)文件系统PMFS,利用NVM存储设备的字节寻址的能力来减少IO栈开销,使得应用能直接访问NVM存储设备.此外,PMFS还利用处理器的分页和内存排序功能减少日志记录的粒度并支持更大的页面,在保证一致性的同时提高内存映射和访问的效率.Ou等人[8]提出的HiNFS使用写缓冲策略隐藏NVM较长的写延迟,并直接从DRAM和NVM存储设备读取文件数据,避免关键路径中双重复制的开销.Sha等人[9]提出一种基于“文件虚拟地址空间”的新型文件系统SIMFS,充分利用了在文件访问路径上内存映射硬件.SIMFS将打开的文件地址空间嵌入到进程的地址空间中,将文件的处理转交给存储器映射硬件.通过这样的方法极大地提高了文件系统的吞吐性能.NOVA文件系统[10-11]通过优化日志提高并发度.它为每一个文件提供一个单独的日志,在正常操作和恢复期间能有效提高执行访问请求的并发度;同时利用NVM存储设备支持字节读写的特性,以链表的形式存储日志,避免了在内存中需要连续空间存储日志;对于那些涉及到多个inode的操作,NOVA使用轻量级的日志来减少时间和空间开销.总的来说,NOVA能有效利用NVM存储设备的特性提高日志结构文件系统的吞吐率和减少垃圾的开销.XPMFS[12]提出了一种NVM存储设备的自管理算法,利用NVM存储设备中的嵌入式处理器完成存储系统的管理,减少NVM存储设备与CPU之间的传输,提高元数据管理效率并降低NVM存储设备的写放大问题.Zeng和Sha等人[13]设计了一种适用于NVM和块设备的混合型文件系统NBFS,将单个文件的数据页分发到NUMA(non uniform memory access architecture)架构和多个块设备的多个存储节点,还设计了一种基于数据访问的数据迁移机制和优化了块设备的资源池,减少了额外的存储开销.Kannan等人[14]设计的DevFS是一种用户级直接访问的文件系统,使用按需分配内存的机制,与文件相关联的数据结构如IO队列和日志等在文件打开或创建时才分配,直到文件删除时才被释放;使用动态分配的文件IO队列和内存日志,能根据需求动态调整大小.Zheng等人[15]提出的Ziggurat能根据应用程序访问模式、写入大小以及应用程序在写入完成之前停止的可能性来管理对NVM,DRAM或磁盘的写操作.
1.2 构建NVM与DRAM的混合内存
NVM存储设备具有接近内存的读写速度,研究者考虑将NVM存储设备和DRAM设备一起构建混合缓存,来解决DRAM容量不足的问题.
Fan等人[16]提出了基于NVM和DRAM的协作混合高速缓存策略Hibachi,分离读缓存和写缓存,设计不同的方式分别管理以提高缓存的命中率;同时,Hibachi能够动态地调整clean缓存和dirty缓存的大小,来适应不同的运行负载;此外,Hibachi能够将随机写转化为顺序写来提高存储系统的吞吐量.Zuo等人[17]设计了一种基于位置共享的散列冲突解决方法,提出了一种写入友好的路径散列算法来减少NVM存储设备的额外写入操作.Liu等人[18]提出一种硬件与软件协作的缓存机制HSCC,通过维护NVM到DRAM的地址映射,以及对页表和TLB的扩展来跟踪NVM页面的访问计数;从而简化了硬件的设计,并为优化软件层中的缓存提供了支撑.Sha等人[19]提出虚拟线性可寻址桶(VLAB)的索引方法,通过建立连续的虚拟地址空间来提高地址查找的效率.Qureshi等人[20]提出了一种基于PCM的混合主存架构,同时具有DRAM低延迟和PCM大容量等优势;此外还设计了减少混合内存系统写入操作的方法,能够显著延长混合主存中PCM的寿命.文献[21]设计了NVMain2.0,使用NVM和DRAM构建混合型存储系统,具有用户接口灵活、IO性能显著提高和刷新粒度小等特点.Son等人[22]提出了一种日志文件系统中高性能的事务机制,通过分析Ext4JDB2事务传输过程中的IO操作以及加锁机制,采用lock-free的数据结构,设计了以协作方式并发执行IO操作的方法,提高读写数据的效率;但该方法主要从应用层和文件系统层优化锁机制,无法利用NVM存储设备的嵌入式处理能力,也不能减少NVM存储设备和主机之间需要传输的数据量.Dulloor等人[23]设计了一种基于DRAMNVM的异构存储架构,使得开发人员能够借助其提供的库快速优化存储系统.陈吉等人[24]设计了一种层次化的NVM和DRAM的异构内存系统SSLDC,该系统能在层次化混合内存上支持大页.SSLDC使用直接映射的方式将NVM映射到DRAM上,并以4 KB的粒度来对数据快进行管理.与此同时,SSLDC还实现了一种DRAM的数据过滤机制来降低了粗粒度打来的内存带宽的压力.
当前的研究虽然能够提高NVM存储系统的性能,但未改变存储系统中串行的访问请求方式,无法利用NVM存储设备所具有的多通道特性,存在执行访问请求效率低和导致大量数据复制等问题.
2 存储系统中基于锁的访问请求管理机制
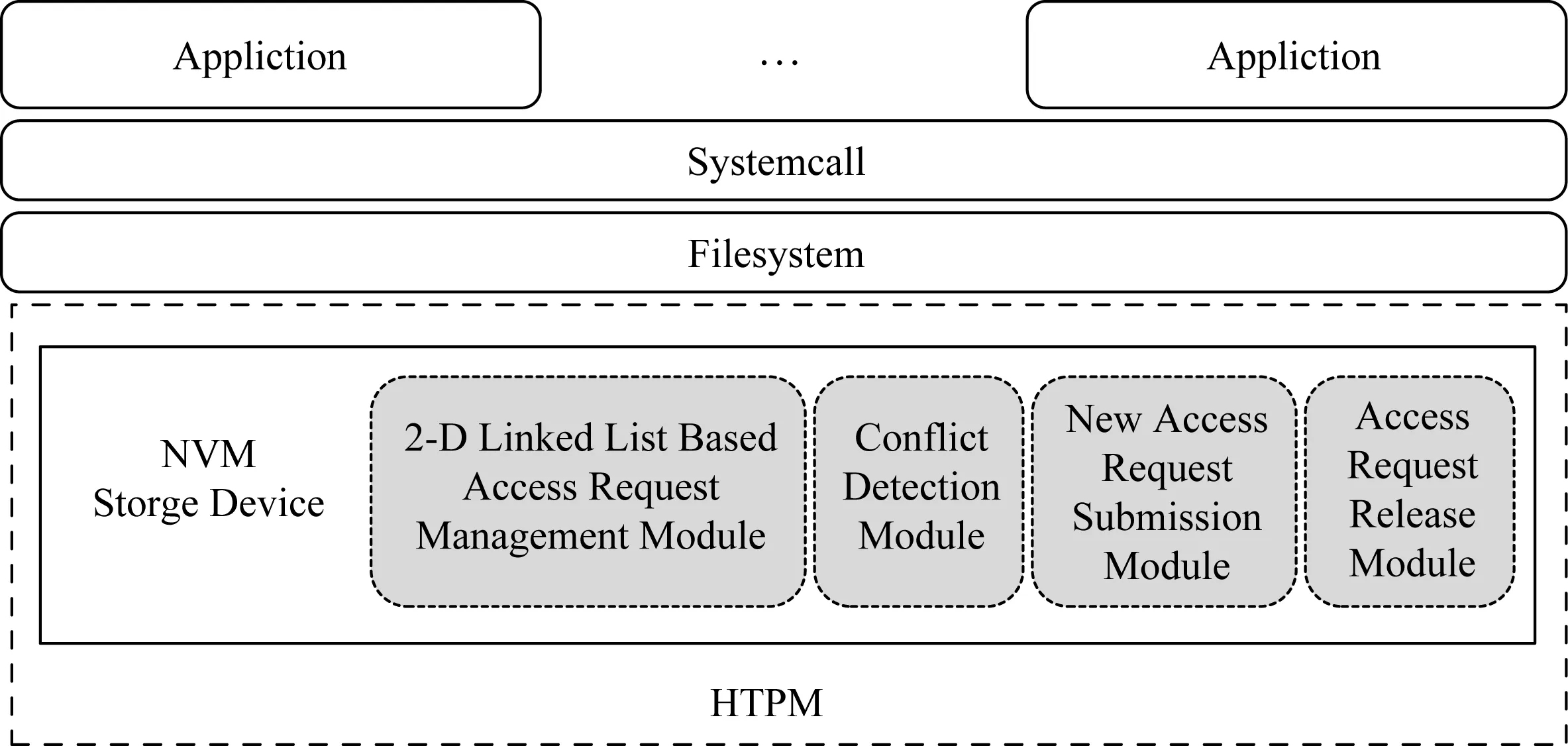
Fig. 2 Overall design of high concurrent NVM storage system based on conflict detection图2 基于冲突检测高吞吐NVM存储系统的结构
传统存储设备不具备处理能力,只能依赖主机CPU完成访问请求的组织和管理,需要在主机和存储设备之间反复传输管理访问请求所需的大量数据,这不仅仅增加了主机CPU的负担,也使得较慢的存储设备接口速度这一瓶颈问题更加突出.此外,访问存储系统需要给大量不同的应用提供数据存储与访问服务,需要保证大量访问请求之间的互斥,这给存储系统的IO性能带来了很大的挑战.
现有基于文件系统的锁机制一般以文件为单位进行访问请求的互斥,如图1所示,访问请求A在访问前需要对文件加锁,但其仅需要访问其中的少量数据或某一个数据块;访问请求B虽然与访问请求A所访问区域不重叠,但由于文件被加锁机制,需要等待访问请求A执行完成后才能执行.这种方式无法利用NVM存储设备支持字节读写的特性,严重影响了执行访问请求的并发度,使用传统存储设备时对存储系统IO性能的影响较小,但应用于NVM存储设备时推迟执行访问请求对IO性能的影响很大.
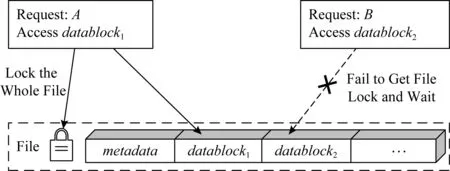
Fig. 1 Traditional lock mechanism access process图1 现有存储系统的锁机制
现有锁机制会将被锁访问请求对应的进程调度到阻塞状态,等待唤醒后再切换到就绪状态;进程的调度和状态转换需要大量额外的时间开销,而现有存储系统中访问请求的管理都是由主机CPU完成,这不仅需要反复在主机和NVM存储设备之间传输大量数据,严重影响NVM存储系统的IO性能,还会给主机CPU带来大量的计算开销.
NVM存储设备中存在多个并发通道,能同时执行对NVM存储设备不同区域的访问请求,但现有的访问请求管理机制和锁策略缺乏相应的优化策略,使得访问请求在存储设备中还是以串行方式运行,严重影响了NVM存储系统的吞吐率.
3 基于冲突检测高吞吐NVM存储系统的设计
我们首先给出基于冲突检测高吞吐NVM存储系统的结构,再给出访问请求的管理、调度、提交和释放等方法.
3.1 基于冲突检测高吞吐NVM存储系统的结构
NVM存储设备具有极高的读写速度,传统的锁机制会严重影响其IO性能;同时NVM存储设备具有处理能力,能独立管理访问请求.因此改造NVM存储设备,使用访问请求冲突检测代替传统锁机制,设计高吞吐的NVM存储系统,其结构如图2所示.
HTPM在NVM存储设备中增加了基于二维链表的访问请求管理模块、基于冲突检测的访问请求调度模块、新访问请求提交模块和访问请求释放模块.其中基于二维链表的访问请求管理模块负责存储NVM存储设备中的读写访问请求,减少管理访问请求的时间开销;基于冲突检测的访问请求调度模块用于代替基于文件系统的锁机制,通过检测访问请求是否与现有的访问请求存在冲突,判断访问请求能否执行;新访问请求提交模块负责管理NVM存储设备所接收的新访问请求;访问请求释放模块用于在访问请求执行完成后,对与其冲突的访问请求进行管理.
由此HTPM能利用NVM存储设备的嵌入式处理能力,自主组织和管理访问请求,采用检测访问请求的方法代替时间开销大的锁操作,能减少NVM存储系统与主机之间通信的数据量,提高NVM存储系统执行访问请求的并发度和吞吐率.
3.2 基于二维链表的访问请求管理方法
存储系统中读与写访问请求存在很大的差异,读访问请求之间可以互相并发,但写访问请求之间、读写访问请求之间则可能存在互斥的关系;同时NVM存储设备存在写寿命有限的局限,以字节为单位执行写操作能延迟其使用寿命,而以字节为单位执行读操作则会给管理访问请求带来复杂性;因此将读写访问请求分开,使用不同的数据结构和方法进行管理.首先给出读和写访问请求的组织结构,再给出基于二维链表的访问请求管理方法.
HTPM的读访问请求以块为单位进行管理,如果上层应用提交的读访问请求包含多个数据块,则将读访问请求以数据块为单位拆分为多个读访问请求.图3给出了HTPM中读访问请求的结构HtReq_read,使用五元组(Req_id,Block_id,R_in_id,Next_req,Wait_write)表示.其中,Req_id是该读访问请求的标识;Block_id表示该读访问请求所对应的数据块标识;R_in_id表示上层读访问请求被拆分后对应子读访问请求的内部序号,用于在所有子读访问请求全部执行完之后,再依据R_in_id将这些子读访问请求重新组合;Next_req用于保存当前读访问请求的下一个读访问请求;Wait_write指向与该读访问请求存在冲突的写访问请求链表,也是等待该读访问请求的所有写访问请求列表.

Fig. 3 Structure of read request图3 读访问请求的结构
HTPM的写访问请求以字节为单位进行管理,在收到上层应用提交的写访问请求后,长度大于一个数据块的写访问请求按照HTPM中划分的数据块进行拆分.如图4所示,使用七元组HtReq_write(Req_id,Start_address,Length,W_in_id,Next_req,Wait_write,Wait_read)表示每个写访问请求.其中,Req_id是写访问请求的标识,Start_address是该写访问请求的启始地址,Length是该写访问请求的大小,W_in_id是上层写访问请求被拆分后对应子读访问请求的内部序号,Wait_write是等待该写访问请求的写访问请求的链表,Wait_read是等待该写访问请求的读访问请求的链表.

Fig. 4 Structure of write request图4 写访问请求的结构
在此基础上,给出二维结构的访问请求管理方法.用读执行队列(read execute queue, REQ)表示可执行读访问请求管理结构,如图5所示,REQ是不与其他访问请求冲突的所有读访问请求的链表,读访问请求之间可以并发,但与写访问请求会存在冲突,因此在每个HtReq_read结构中再使用Wait_write链接与其存在冲突的写访问请求.
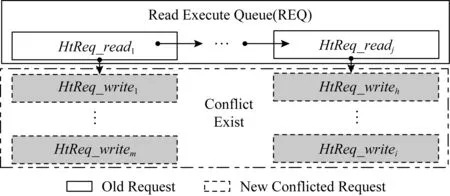
Fig. 5 Read access request management structure based on two-dimensional linked list图5 基于二维链表的读访问请求管理结构
图6给出的是可执行写访问请求管理结构的示意图,用写执行队列(write execute queue, WEQ)表示,对应的是当前不与其他访问请求冲突的所有写访问请求链表;写访问请求与其他读、写访问请求之间均可能存在冲突,因此每个HtReq_write使用2个指针Wait_write和Wait_read链接与其存在冲突的写访问请求和读访问请求.

Fig. 6 Write access request management structure based on two-dimensional linked list图6 基于二维链表的写访问请求管理结构
由此,能适应读写访问请求的不同特性,使用不同粒度管理2类访问请求,为减少访问请求之间冲突的概率,提高执行访问请求的并发度提供支撑.
3.3 基于冲突检测的访问请求调度算法
在HTPM基于二维链表访问请求管理结构的基础上,设计基于冲突检测的访问请求调度算法,替代现基于文件系统的锁机制,减少管理访问请求时的额外时间开销.
HTPM收到一个新访问请求后,依据HtReq_read中保存的Block_id以及HtReq_write中的Start_address和Length,判断与现有访问请求对应的数据区之间是否存在覆盖,决定新访问请求与当前的可执行访问请求之间是否冲突.如图7(a)所示,假设当前只有访问请求A,判断新访问请求B与现有可执行访问请求之间无冲突,则新访问请求B可以执行;如图7(b)所示,新访问请求B与现有可执行访问请求之间存在数据区覆盖,则判断访问请求B与访问请求A之间存在冲突.
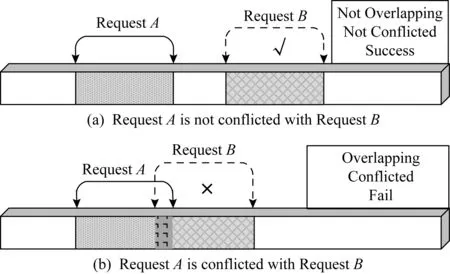
Fig. 7 Conflict detection mechanism图7 冲突检测方法
当HTPM检测新访问请求与现有访问请求之间存在冲突时,会出现以下4种情况.
第1种情况:新增读访问请求与现有读访问请求之间存在冲突.如图8所示,读访问请求之间可以并发执行,虽然新增读访问请求与现有读访问请求之间存在冲突,但新增读访问请求同样可以执行,因此将其加入到REQ的尾部.

Fig. 8 Conflict between the new and current read request图8 新增读与现有读访问请求之间的冲突
第2种情况:新增写访问请求与现有读访问请求之间存在冲突.如图9所示,此时新增写访问请求必须等待现有读访问请求执行完才能执行,因此将其加入到现有读访问请求中Wait_write所指向的等待队列中.

Fig. 9 Conflict between the new write and current read request图9 新增写与现有读访问请求之间的冲突
第3种情况:新增读访问请求与现有写访问请求之间存在冲突.如图10所示,此时新增读访问请求必须等待现有写访问请求执行完才能执行,因此将其加入到现有写访问请求中Wait_read所指向的等待队列中.

Fig. 10 Conflict between the new read and current write request图10 新增读与现有写访问请求之间的冲突
第4种情况:新增写访问请求与现有写访问请求之间存在冲突.如图11所示,此时新增写访问请求必须等待现有写访问请求执行完才能执行,因此将其加入到现有写访问请求中Wait_write所指向的等待队列中.
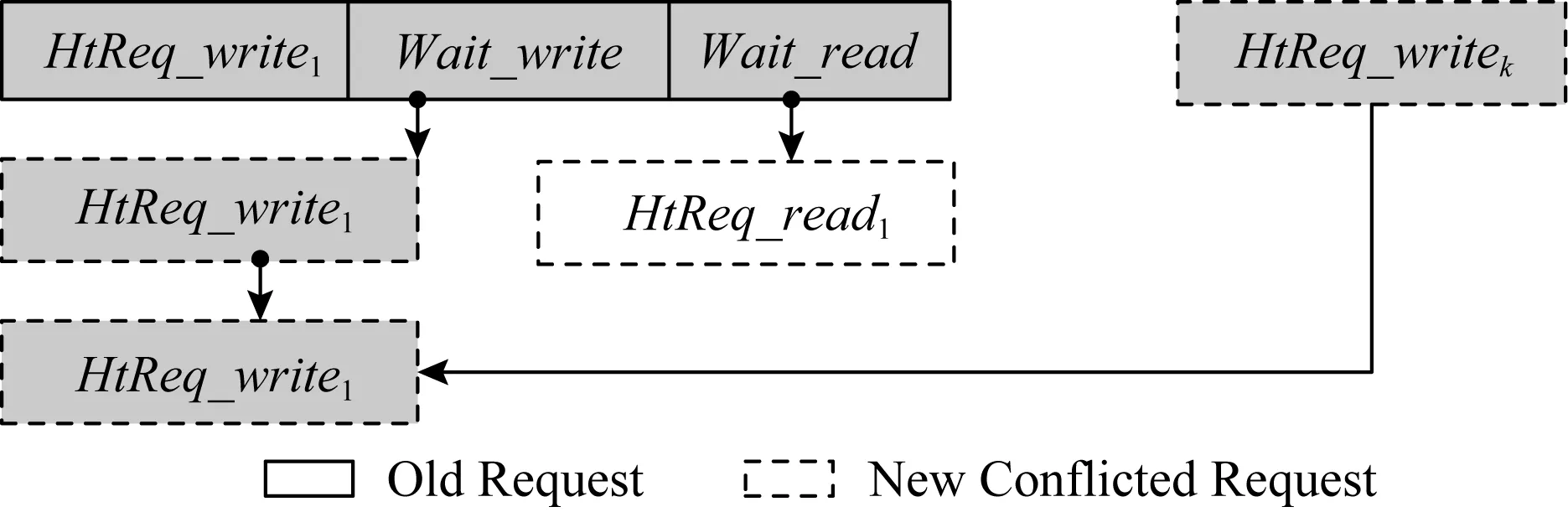
Fig. 11 Conflict between the new and current write request图11 新增写与现有写访问请求之间的冲突
由此,使用基于冲突检测的方法代替基于文件系统锁机制,配合3.2节所设计的访问请求管理方法,能有效降低访问请求冲突的概率,提高执行访问请求的并发度;同时将需要访问请求的互斥管理分散到各个访问请求中,降低了管理访问请求的复杂度,也减少了修改访问请求管理结构时需要封锁的粒度,通过降低管理访问请求对应数据结构所需时间开销,提高NVM存储系统的性能.
3.4 提交新访问请求
HTPM收到上层应用提交访问请求后,需要使用基于冲突检测的访问请求调度算法分别与REQ和WEQ中可执行的读写访问请求进行比较,以判断新访问请求能否提交给HTPM执行.
新增读访问请求向HTPM的提交算法流程为:将一个新增的读访问请求提交到HTPM时,因为读访问请求之间可以并发执行,仅使用WEQ中可执行写访问请求hr与新增读访问请求hrr进行冲突检测;如存在冲突,那么就将hrr插入到hr的Wait_read指针所指向的冲突链表中,并结束循环.如果hrr和WEQ中所有可执行写访问请求hr均无冲突,那么就将其插入到REQ的末尾,作为可以执行的读访问请求,并等待HTPM的执行.
算法1.新增读访问请求向HTPM的提交算法.
输入:HTPM中的读请求hrr.
① for eachhrin WEQ do
② lethr与hrr进行冲突检测;
③ ifhr与hr存在访问冲突 then
④ lethrr插入到hr.Wait_read;
⑤ break;
⑥ else
⑦ continue;
⑧ end if
⑨ end for
⑩ lethrr插入到REQ.tail.
新增写访问请求向HTPM的提交算法流程为:写访问请求与现有可执行读和写访问请求均可能存在冲突,所以提交一个新写访问请求时,需要将其与REQ和WEQ中可执行的访问请求均进行冲突检测;首先将新增写访问请求hrw分别与REQ和WEQ中的可执行访问请求hr进行冲突检测.如果存在冲突,那么将hrw插入到REQ和WEQ中可执行访问请求的Wait_write指针指向的冲突链表中;否则,将该新增写访问请求hrw插入到WEQ的末尾,并提交给HTPM执行.
算法2.新增写访问请求向HTPM的提交算法.
输入:HTPM中的读请求hrr.
① EQ是REQ和WEQ的并集;
② for eachhrin EQ do
③ lethr与hrr进行冲突检测;
④ ifhrr与hr存在访问冲突 then
⑤ lethrr插入到hr.Wait_write;
⑥ break;
⑦ else
⑧ continue;
⑨ end if
⑩ end for
3.5 释放执行完访问请求
HTPM在执行完REQ或WEQ中某个访问请求后,需要释放REQ或WEQ结构中记录的存在冲突读写访问请求,但这些读写访问请求还可能会与其他现有可执行访问请求存在冲突.
在访问请求中保存冲突数或冲突指针等方法,可以用于判断能否释放访问请求,但每次修改冲突计数或冲突指针均需要进行加解锁操作,带来了较高的时间开销,难以适应NVM存储系统读写速度高的特性.
同样,利用NVM存储设备的嵌入式处理器检测等待释放的访问请求,代替传统的锁机制,设计已有访问请求释放算法,如算法3所示:
算法3.HTPM中请求释放算法.
输入:HTPM中的读请求hrr(hrr已执行).
① ifhrr是读请求 then
② for eachhrinhrr.Wait_write;
③ 使用算法1处理hr;
④ end for
⑤ else ifhrr是写请求
⑥ letlist=intersection ofhr.Wait_readandhr.Wait_write;
⑦ for eachhrinlistdo
⑧ 使用算法1处理hr;
⑨ end for
⑩ end if
当一个读访问请求hr执行完成后,遍历其Wait_write链表中的访问请求,将这些访问请求作为HTPM的新访问请求,使用3.3节和3.4节中给出的算法进行检测.当写访问请求hr执行完成之后,遍历其Wait_write和Wait_read链表中的访问请求,同样将这些访问请求作为HTPM的新访问请求,使用3.3节和3.4节中给出的算法进行检测.
由此避免了使用锁机制,便于提高NVM存储系统执行访问请求的并发性,从而提高NVM存储系统的吞吐率.
4 原型系统的实现
我们首先给出模拟NVM存储设备的方法,再给出HTPM原型系统的实现方法.
4.1 NVM存储设备模拟
由于没有可用的NVM设备,我们采用Intel的基于内存的开源NVM存储设备模拟器PMEM[25]来模拟NVM存储设备;同时在Linux内核地址的尾部预留40 GB的空间作为PMEM的存储地址空间.
PMEM是使用DRAM存储数据,没有模拟NVM存储介质写速度低于DRAM的特性,我们在PMEM中增加写入延迟,参考文献[8,26]中的方法,在每次clflush和mfence指令之后增加200 ns的延迟来模拟NVM存储介质写入速度低于DRAM的特性.
4.2 HTPM原型系统的实现
首先在开源的PMEM的nd_pmem模块中,增加了读写请求结构HtReq_read和HtReq_write以及读写请求执行队列结构REQ和WEQ.接着在PMEM中增加基于二维链表的访问请求管理模块、基于冲突检测的访问请求调度模块、新访问请求提交模块和访问请求释放模块,构建HTPM的原型,修改和增加了约1 000多行代码.
此外,对4.4.4112版本内核的EXT4文件系统和XFS文件系统模块进行修改,去除读写函数内的加解锁操作,使访问请求直接被提交至HTPM,由HTPM统一管理访问请求、实现多个访问请求访问同一数据时的互斥.
5 测试和分析
使用一台服务器构建HTPM原型系统的测试环境,该服务器的配置如表1所示:

Table 1 Configuration of Evaluation表1 原型系统测试环境的软硬件配置
分别在HTPM上加载Ext4和XFS这2种文件系统,数据块大小设置为4 KB,首先使用Filebench中的Webserver,Varmail,Fileserver负载,模拟存储系统的不同运行环境,测试HTPM的吞吐率,再使用Fio测试顺序和随机读写的IO性能,并与PMEM进行比较.
每项均测试10次,并在每次测试之后重启服务器来和禁用缓存以消除缓存对测试结果的影响,最后取10次测试的平均值作为测试结果.
5.1 Webserver负载测试
分别在PMEM和HTPM上加载Ext4和XFS文件系统,使用Filebench的Webserver负载,模拟用户访问Web服务器的情况,设置测试文件数量为1 000,每个目录中创建20个文件,每次IO大小为1 MB,IO操作中读写访问请求的比例为10∶1,测试时间为60 s,测试线程数量为2,4,6,8,10,12,14时的吞吐率IOPS(InputOutput operations per second)值,结果如图12所示.
从图12可以看出,相比PMEM,HTPM能有效提高Ext4和XFS的IOPS值.当线程数量为2时,IOPS值分别提高了6.1%和6.3%.这是因为Webserver负载中大部分是读访问请求,还不能充分体现HTPM中基于冲突检测的访问请求调度算法相比传统锁机制的优势.随着线程数增加到8,PMEM上Ext4和XFS的IOPS值达到了最大值,之后随着线程数的增加,IOPS的值逐渐下降,这是由于随着线程数的增加,访问请求之间的锁操作越来越多,影响了访问请求执行的并发度;而HTPM在线程数为8时,相比PMEM,Ext4和XFS的IOPS值分别提高了17.2%和17.1%;同时随着线程数的继续增加,HTPM上Ext4和XFS的IOPS值能保持不降低,这是由于HTPM中基于冲突检测的访问请求调度算法避免了多线程时锁机制带来的额外时间开销.这些结果表明,HTPM能更好地适应多线程环境的访问特性,相比PMEM具有更稳定的吞吐率.

Fig. 12 Webserver workload test图12 使用Webserver负载的测试
5.2 Varmail负载测试
使用Filebench的Varmail负载,模拟Email服务器的使用情况.设置文件数量为1 000,每个目录中创建的文件数量为1 000 000,每次IO大小为1 MB,IO操作中读写访问请求的比例为 1∶1,测试时间为60 s,测试线程数量为2,4,6,8,10,12,14时的吞吐率IOPS值,结果如图13所示.
从图13可以发现,HTPM上Ext4和XFS的IOPS值相比PMEM均有所提高.在线程数小于6时,XFS的IOPS值随着线程数增加而逐步提高;在线程数为6时,PMEM上XFS的IOPS值达到最大值,此时HTPM上XFS相比PMEM上XFS能提高18.2%的IOPS值;随着线程数的进一步增加,PMEM上XFS的IOPS值开始逐步下降,而HTPM上XFS的IOPS值则始终保持不变.
Ext4的IOPS值情况类似,PMEM上Ext4的IOPS最大值出现在线程数为14时,此时Ext4在HTPM上的IOPS值要比在PMEM上提升了25.5%.此外,使用Varmail负载时,HTPM上Ext4的IOPS值比XFS的IOPS值高出很多,这是由于Varmail负载中小文件居多,而XFS读写小文件的效率低于Ext4.
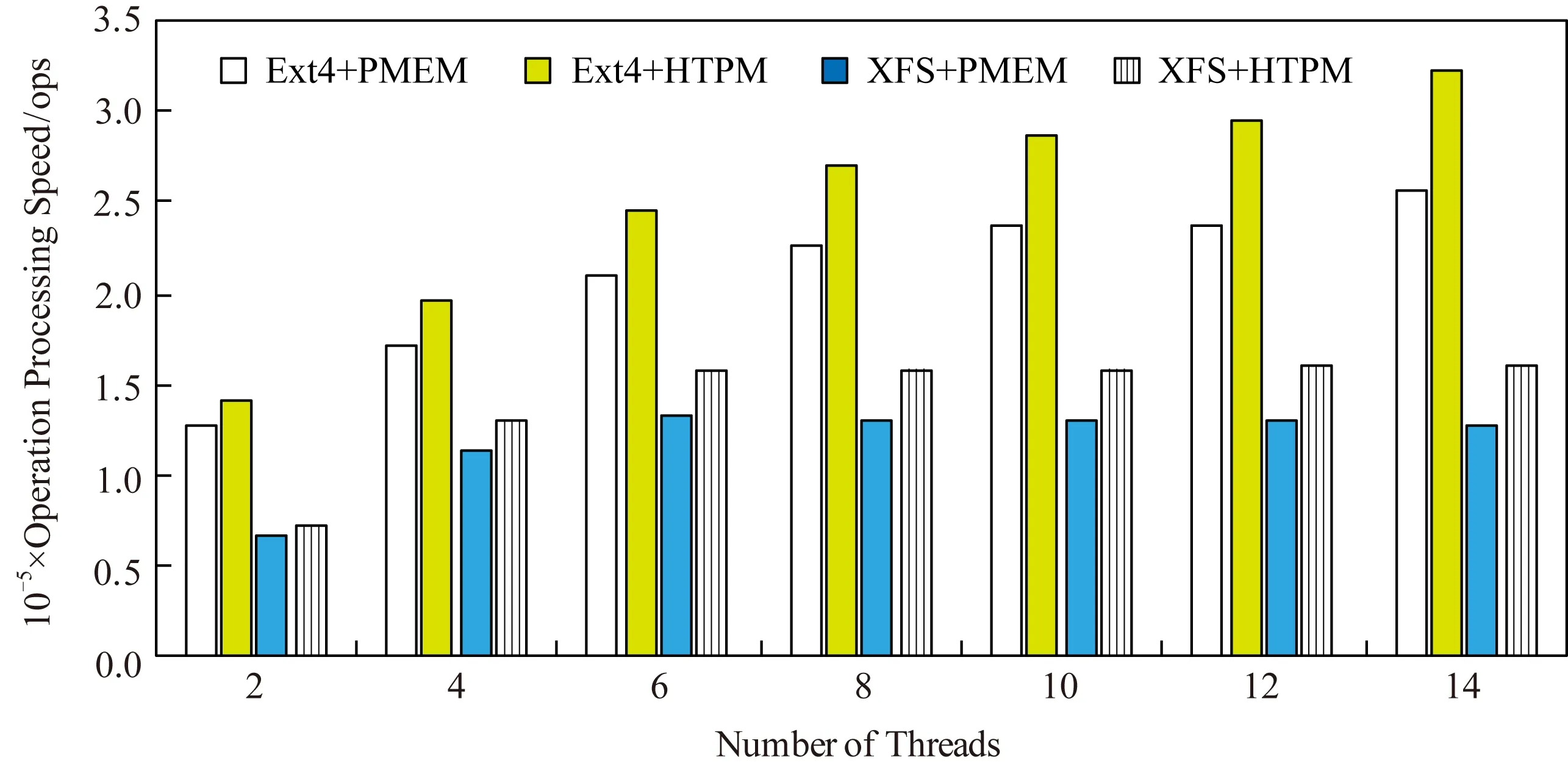
Fig. 13 Varmail workload test图13 使用Varmail负载测试的测试
5.3 Fileserver负载测试
使用Filebench的Fileserver负载,模拟文件服务器中文件共享和读写操作等情况.设置文件数量为10 000,每个目录中创建20个文件,每次IO大小为1 MB,IO操作中读写访问请求的比例为1∶10,测试时间为60 s,测试线程数量为2,4,6,8,10,12,14时的吞吐率IOPS值,结果如图14所示.
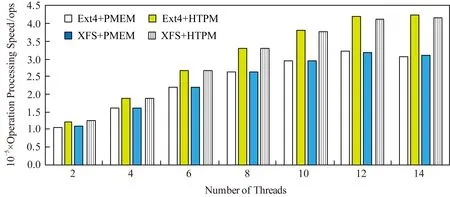
Fig. 14 Fileserver workload test图14 使用Fileserver负载的测试
从图14可以发现,当线程数为2时,HTPM上Ext4和XFS的IOPS值相比PMEM提高了15.2%和17%;随着进程数量的增加,相比PMEM,HTPM上Ext4和XFS的IOPS值所增加的幅度不断提高;在线程数为12时,PMEM上Ext4和XFS的IOPS值达到了最大值,此时Ext4和XFS在HTPM上相比PMEM提高了31.9%和30.3%;随着线程数继续增加,PMEM上Ext4和XFS的IOPS值开始下降,而HTPM上Ext4和XFS的IOPS值则保持稳定.相较于Webserver和Varmail负载,使用Fileserver负载时,HTPM上Ext4和XFS的IOPS值提高幅度更大.这是因为Fileserver负载中写访问请求的比例较高,所导致的锁操作也更多,从而能更好地体现出基于冲突检测的访问请求调度算法相比锁机制的优势.
5.4 顺序读写的测试
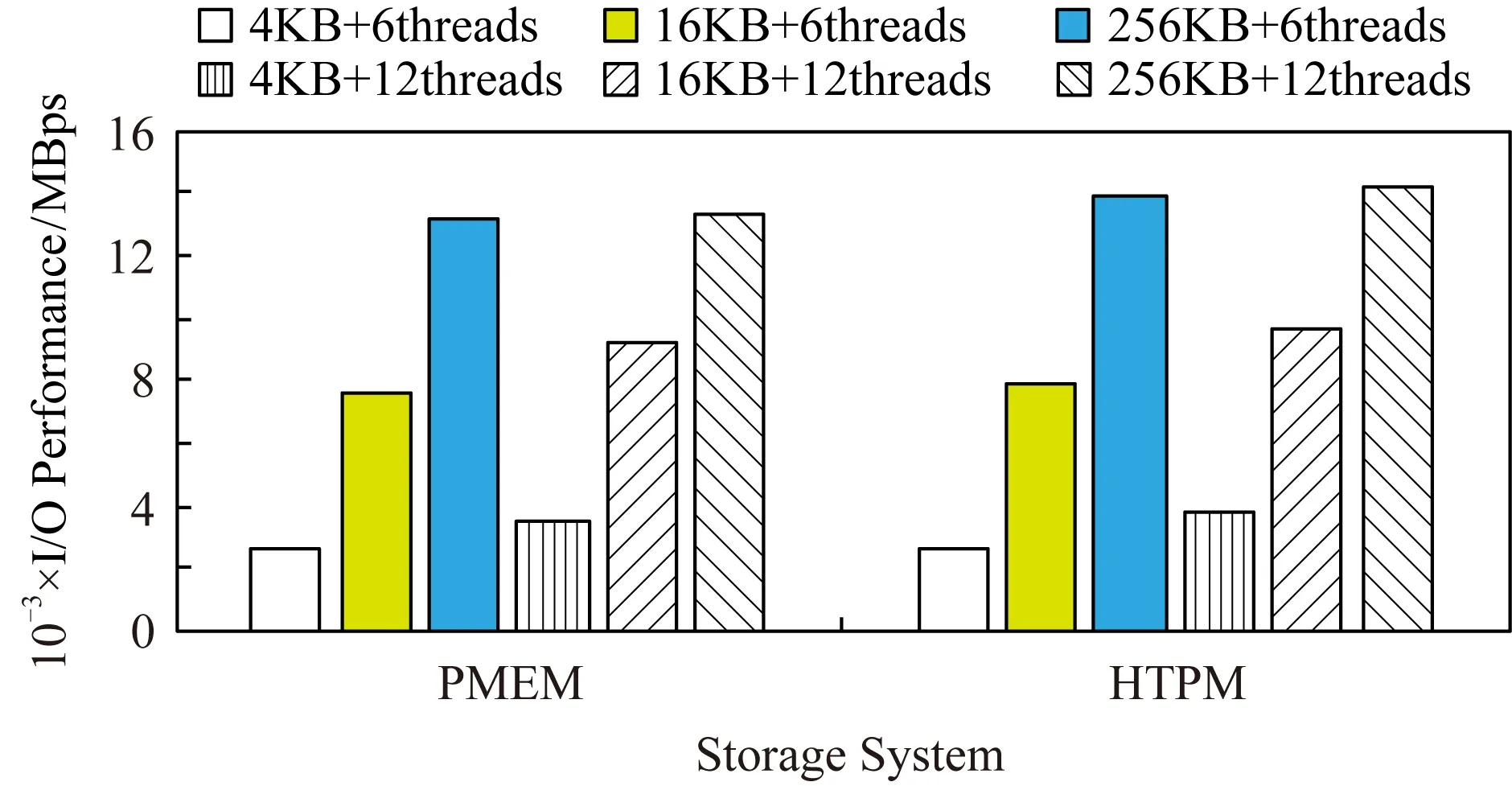
Fig. 15 Sequential read test图15 顺序读的测试
从图15可以发现,当线程数为6读写块大小为4 KB,16 KB,256 KB时,HTPM顺序读IO性能相比PMEM分别提升了3.4%,4.3%,5.4%;当线程数为12时,HTPM所提高的IO性能比例更高;这表明HTPM能更好地适应高并发的运行环境,发挥NVM存储设备的优势,通过增加执行访问请求的并发度,提高存储系统的IO性能.

Fig. 16 Sequential write test图16 顺序写的测试
从图16可以看出,在线程数为6读写块大小为4 KB,16 KB,256 KB时,HTPM顺序写IO性能相比PMEM分别提升了12.3%,14.7%,17.3%;当线程数为12时,HTPM的顺序写IO性能相比PMEM分别提升了15.6%,18.4%,21.4%;相比顺序读,HTPM相比PMEM在执行顺序写操作时所提高的IO性能比例更高,这是因为写操作会导致更多的锁操作,从而更好地体现了基于冲突检测访问请求调度算法的优势.
5.5 随机读写的测试
NVM存储设备相比传统存储设备随机读写性能更高,但同时也会使得现有IO栈成为影响存储系统IO性能的瓶颈.再使用Fio测试HTPM随机读写IO性能,首先测试随机读的IO性能,选择Fio中的异步IO引擎libaio,队列深度设置为32,测试数据的大小为10 GB,测试时间为60 s,使用direct参数跳过缓存,测试线程的数量分别为6和12,读写块大小分别为4 KB,16 KB,256 KB.结果如图17所示.
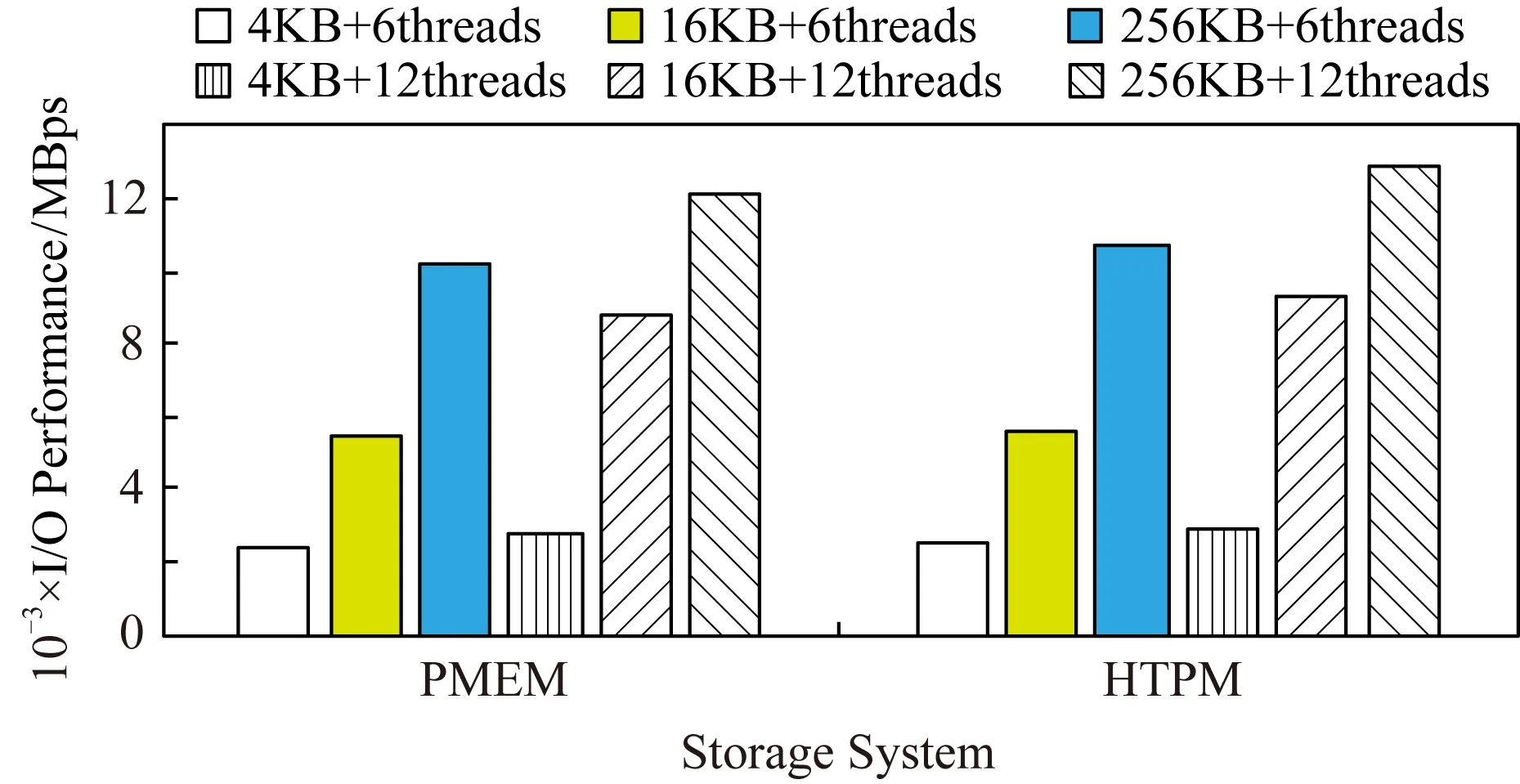
Fig. 17 Random read test图17 随机读的测试
从图17可以看出,在线程数为6读写块大小为4 KB,16 KB,256 KB时,HTPM相比PMEM分别提升了3.2%,4.1%,5.1%的随机读IO性能;在线程数为12时,HTPM的随机读IO性能相比PMEM分别提升了5.1%,5.4%,5.9%;总的来说,HTPM相比PMEM随机读IO性能提高的比例与顺序读接近,这表明HTPM在执行随机读操作时同样具有较好的优势.
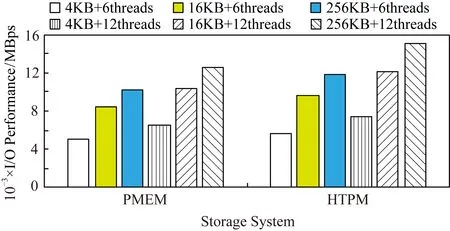
Fig. 18 Random write test图18 随机写的测试
从图18可以看出,在线程数为6读写块大小为4 KB,16 KB,256 KB时,HTPM相比PMEM分别提升了11.4%,13.2%,17.1%的随机写IO性能.当线程数为12时,HTPM的随机写IO性能相比PMEM分别提升了14.5%,17.2%,20.4%.此外与顺序读写的测试结果类似,HTPM在执行随机写操作时所提高IO性能的比例高于执行随机读操作时.
6 小 结
NVM存储设备能有效解决计算机系统的存储墙问题,具有接近DRAM的读写速度、嵌入式处理能力、内部多通道并发读写能力和较慢速的设备接口等一些列特性,这给现有IO栈带来了很大的挑战.基于文件系统的锁机制是影响其构建的NVM存储系统性能的重要因素.
本文将存储系统访问请求的管理嵌入到存储设备中,使用基于冲突检测的访问请求调度算法代替现有基于文件系统的锁机制,提高NVM存储系统的吞吐率.首先给出了高吞吐NVM存储系统的结构;接着给出了基于二维链表访问请求管理方法、基于冲突检测的访问请求调度算法、新访问请求提交和已有访问请求释放流程,利用NVM存储设备的嵌入式处理器自主完成访问请求的管理,提高访问请求执行并发度,缓解速度较低的设备接口所带来的瓶颈问题;最后实现了HTPM的原型系统,使用Filebench中的多种负载和Fio测试了HTPM的性能,实验结果表明,HTPM相比PMEM最大能提高31.9%的IOPS值和21.4%的IO性能.
HTPM还未考虑REQ和WEQ之间的协调和优化队列管理,也未考虑多核环境下的优化策略,下一步拟从这2方面进行改进,进一步提高NVM存储系统的性能.
