面向非易失内存写优化的重计算方法
2020-02-19刘璐荣李子怡
张 铭 华 宇 刘璐荣 胡 蓉 李子怡
(武汉光电国家研究中心(华中科技大学) 武汉 430074) (华中科技大学计算机学院 武汉 430074)
随着大数据时代数据规模的快速增长,数据存储与访问给内存带来了更高的性能要求.传统的DRAM技术因其易失性以及刷新功耗大等问题在系统的可靠性以及能耗等方面会面临诸多挑战.而非易失存储器[1](non-volatile memory, NVM)可以按字节寻址用作持久性内存[2],具有非易失、能耗低以及存储密度高等优点,为构建更高效的存储系统带来了机遇,是下一代内存的理想选择.按字节寻址的非易失存储器主要包括相变存储器[3-4](phase change memory, PCM)、阻变存储器[5](resistive random access memory, RRAM)、磁随机存储器[6](magnetic random access memory, MRAM)以及自旋矩存储器[7](spin transfer torque random access memory, TT-RAM)等.英特尔公司与镁光科技公司于2015年公布了非易失存储技术3D XPoint[8],并于2018年发布了基于3D XPoint的商用非易失DDR4内存Optane DC Persistent Memory[9],可以配合现有的Skylake-SP架构Intel Xeon处理器用于数据服务器.随着硬件技术日渐成熟,基于NVM的下一代存储系统也成为了当前的研究热点[10].
然而使用NVM作为内存应用于计算机系统中仍面临着诸多挑战,这主要包括2点:一是NVM的写延迟比DRAM高[11];二是NVM的擦写次数有限,使用寿命比DRAM短[12].因此如何优化NVM的写操作是一个非常重要的问题.
现有的解决方案从写暂停、对比写、翻转写、减少写数据量以及磨损均衡[13]等角度对NVM的写操作做了优化.由于NVM读操作的延迟和耗能都低于写操作,因此Qureshi等人[14]提出了写取消及写暂停策略,使得系统可以优先处理读请求以缩短系统响应速度.Yang等人[15]利用NVM的字节寻址特性提出了对比写的策略,在数据更新时通过对比新旧数据只修改发生变化的比特.Cho等人[16]提出了翻转写的策略,使用一个标志位记录翻转操作,当修改的数据位超过一半时,翻转标志位和未修改的数据位,当修改的数据位不超过一半时直接写入修改的数据位并保持标志位不变,以此保证数据更新时修改的数据位不超过一半.Tseng等人[17]使用线性规划方法寻求任务的最佳调度顺序以减少对脏数据的写回,从而达到减少写数据量的目的.Chen等人[18]使用计数器以及基于桶的磨损均衡算法为物理页维护一个空闲页面和磨损避免页面以达到磨损均衡的目的,从而提高NVM的耐久性和使用寿命.
为了解决NVM写延迟高和写寿命短的问题,与上述解决方案不同,本文从计算替换存储的角度提出了一种基于结点出度的重计算方法称作ROD(re-computation scheme based on the out degree of computing nodes),ROD方法利用NVM材料读写延迟的不对称性,通过读取输入数据重新计算代码块的结果以减少对NVM的写次数.具体而言,首先按照程序指令间的数据依赖关系在编译期构造数据流图[19](data flow graph, DFG),DFG中的每个结点表示一条程序语句,从输入开始到输出结束,再跟据指令执行周期以及NVM的读写延迟对DFG决策出所有的存储结点和重计算结点,最后根据重计算结点的计算路径完成重计算过程.其中存储结点表示该结点的计算结果写入NVM,需要使用时直接从内存中读出,重计算结点表示该结点的计算结果不写入NVM,当使用时需要回溯到最近的存储结点并将计算路径重新执行一遍.传统的存储主导的方法便是将所有计算结果存入内存,需要使用时再从内存中取出.一种贪心重计算的方法是只对当前结点的重计算开销和存储开销做比对从而作出决策.由于在DFG中结点的重计算路径越长则开销越大,因此需要适当地选择存储结点,而结点的出度决定了数据被依赖的程度,出度越高说明结点被使用的次数越多,读开销或重计算开销也就越大,这是贪心方法未考虑到的,因此ROD方法结合结点的出度可以做准确的决策.
本文的主要贡献包括3个方面:
1) 提出了基于结点出度的重计算方法称作ROD,从而减少NVM的写操作,缓解CPU与内存之间的IO开销.
2) 设计并实现ROD方法的3个组成模块,分别是数据流图的构建、结点的决策算法以及重计算路径的生成.
3) 使用搭载NVMain的Gem5模拟器对ROD方法、贪心重计算方法以及存储主导的方法做了性能对比,验证了ROD方法的有效性.
1 研究背景
本节首先介绍现代CPU与内存之间的性能差距,这是重计算的动机所在,然后介绍重新计算的定义和内涵,接着描述重计算路径图,最后介绍对程序语句执行结果的重计算或存储的权衡策略.
1.1 CPU与内存间性能瓶颈
现代CPU性能比内存性能高3个数量级[20],频繁读写内存不仅会缩短NVM的使用寿命,而且较大的IO延迟会导致CPU空转,从而浪费计算资源并降低系统性能.
在传统的执行方式中,程序的中间计算结果写入内存,需要时再从内存中读出.考虑到CPU与内存间的性能瓶颈,重计算方法通过丢弃部分需要写入内存的计算结果,需要时再按计算路径重新计算出来,以此降低IO的开销,对于以NVM为内存的系统即可减少对内存的写操作,提高NVM的使用寿命.
1.2 定义及研究方向
与重计算相关的研究主要可分为2类:1)降低系统访存次数;2)系统容错和恢复.
对于第1类研究,重新计算是指在需要程序的中间计算结果时将其重新计算出来,以替代将计算结果写入内存并在需要时读取出来的方案[21].该方案的优势在于可以减少写NVM的次数,提高NVM的耐久性并降低IO开销,但问题在于会带来额外的计算开销.因此需要合理地对计算结果做存储或重计算的决策,以较少的额外计算开销换取较大的写开销.
对于第2类研究,重计算大多应用于高性能计算系统的容错和恢复中[22],在应用程序运行崩溃时,保存在NVM上的数据不会丢失,即可恢复计算场景以重新计算出结果,因此如何减少保存的数据量和加快系统恢复速度是其主要的研究问题.
这2类研究方向的具体工作将在第4节“相关研究工作”做详细介绍.本文的研究内容是利用重计算降低系统访存次数,以减少对NVM的写操作.
1.3 重计算路径
由于重计算不保存部分计算结果,因此需要确定重新计算执行的指令及其顺序,来保证程序运行的正确性.将程序按数据依赖划分为代码段,为了方便描述,使用生产者与消费者的概念,如图1所示,代码段G需要直接使用代码段F的运行结果,称F是G的直接生产者,也即G是F的直接消费者.若代码段F的计算结果没有保存至NVM,那么在执行代码段G时需要重新运行代码段F以产生G的输入数据.若F的直接生产者D的计算结果没有保存,那么需要递归回溯到最近的保存了计算结果的生产者.由此可知,将耗能较高的读写内存操作替换为计算指令,便可得到重计算路径,它是一条沿着数据流递归回溯的路径.

Fig. 1 The re-computation path图1 重计算路径图
图1展示了一个具有4层结点的重计算路径图,这是一棵倒长的树.其中A,B,C表示程序的输入,其结果需要写入内存;D,E,F为中间计算结点,不保存它们的计算结果;G为程序输出结点.第1层的结点对应于根结点的直接生产者,从第2层往上,第i层的结点对应于第i+1层结点的直接消费者.每个结点的入度表示其直接生产者的个数,出度表示其直接消费者的个数.由于代码段D,E,F的计算结果没有保存,因此在计算G时,需要重新计算D,E,F的结果,故需要沿着数据流回溯到结点A,B,C,从内存中读取数据重新计算.
1.4 权衡策略
重计算虽然能减少对NVM写的次数,但如果对于代码段执行结果的存储或重计算的决策不佳,可能会使得重计算路径过长导致计算开销过大,或者存储结点过多导致写NVM开销增大.本节介绍对代码段执行结果的存储或重计算的权衡策略.
考虑图2所示的2种重计算路径形态,图2中灰色圆形表示程序的输入,其结果保存到内存,结点G表示程序的输出.图2(a)的结点层数较多,只保存输入结点,会使得后续结点的重计算路径过长,需要递归回溯执行的指令过多,更优的策略应适当存储中间的计算结果,避免重计算开销过大.而图2(b)的结点层数较少,计算路径短,将中间计算结果都存入NVM必然会造成大量的写开销,因此对中间结点做重计算的优势能更好地体现出来.

Fig. 2 Different forms of re-computation path图2 不同形态的重计算路径
Kandemir 等人[23]提出了贪心的决策方法,即只考虑当前的计算结果,当保存到内存的开销小于将其重新计算出来的开销,即使用存储策略,否则使用重计算策略.但是贪心方法忽略了数据的使用次数,当一个数据在短期内被重复使用时,选择保存该数据的结果能获得更大的收益.
2 基于结点出度的重计算方法
为了减少对NVM的写操作,提出基于结点出度的重计算方法ROD,其考虑指令间数据依赖的程度,对计算结果做出合理的存储或重计算的决策.本节先介绍ROD方法的总体设计,再介绍各个组成模块的具体实现.
2.1 总体设计
本节介绍ROD方法的总体流程设计,共有3个主要的功能模块,分别是数据流图的生成模块、结点决策模块以及重计算路径的生成模块,如图3所示.

Fig. 3 The process design of ROD scheme图3 ROD方法总体流程设计
ROD方法通过数据流对程序按语句划分结点,一条语句即为一个结点,结点之间的箭头指向关系即表示生产者结点与消费者结点之间存在数据依赖.在本方法中,数据分为可重计算数据与非可重计算数据,程序的输入数据属于非可重计算数据,除了输入结点,中间结点的重计算开销大于存储开销的数据也属于非可重计算数据,其他数据则属于可重计算数据.产生非可重计算数据的结点称为存储结点,其计算结果需写入到NVM中.产生可重计算数据的结点称为重计算结点,其计算结果被使用到时需按照数据依赖关系回溯到最近的存储结点,将其值读出后按计算路径重新计算出结果.
为了得到结点之间的数据依赖关系必须先构造数据流图.使用LLVM[24]工具对源程序生成中间表示(intermediate representation, IR)指令,即可根据IR表示中的loadstore指令找到对应的结点,再使用词法分析的方式对这些结点提取对应的操作数,最后依赖操作数之间的读写依赖构造数据流图,如图4所示,图中每个结点表示一条语句,结点Vi指向结点Vj表示第j条语句的执行依赖第i条语句的计算结果.
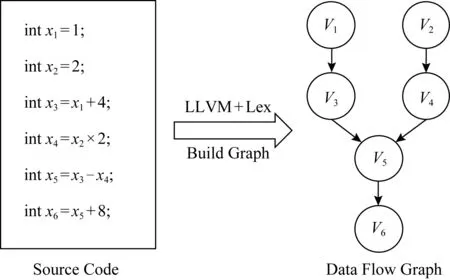
Fig. 4 Transform the source code to the data flow graph图4 将源程序转化为数据流图
在得到数据流图之后,便可以计算结点的存储开销和重计算开销来确定存储结点和重计算结点.ROD方法在决策的过程中综合考虑了结点出度(即直接消费者个数)的影响,结点的出度越大,说明其所在的重计算路径越多,因此保存其计算结果往往会有利于其他结点的重计算过程.
例如,经过决策后将图4的数据流图转换为决策图,其中S结点表示存储结点,R结点表示重计算结点,如图5所示,可以看出程序的输入和输出结点都被标为存储结点,其他中间计算结果均可通过重新计算得到,比如计算结点V5需要重新计算结点V3和结点V4,而计算结点V6则需要重新计算结点V3、结点V4和结点V5.

Fig. 5 The decision of the store node and the re-computation node图5 存储结点和重计算结点的决策
通过决策图5可以回溯每个重计算结点的重计算路径,重计算路径应从重计算结点开始一直回溯到距离它最近的存储结点为止,以此为每个重计算任务生成重计算函数.由于本方法是在编译期确定重计算结点,在所有重计算函数确定后,便可以运行程序,在遇到重计算结点时进入相应的重计算函数得到计算结果即可,因此程序实际执行的指令数量也相应地增多了.
2.2节将详细介绍数据流图生成的实现,2.3节将详细介绍ROD方法中对于存储或重计算选择策略的实现细节,2.4节将对如何寻找重计算路径并生成重计算函数做详细的介绍.
2.2 生成数据流图
本节将介绍生成数据流图的实现细节.通过使用LLVM工具链中Clang编译器为源程序生成IR指令,通过分析IR中的loadstore指令在源程序中找到对应的读写内存的语句,其中loadstore指令的具体含义表示如下:
1) load指令.读内存,需要记录读取的地址与存入的操作数.
2) store指令.写内存,需要记录被保存的数据与写入的地址.
对含load和store操作的IR指令举例如下:
%p=alloca i32;
store i32 8,i32*%p;
%v=load i32,i32*%p;
首先向内存申请一个32 b的整型空间p,然后将32 b的数8写入地址p处,再从内存中读出地址p处的值,将其存入v中,此时v的值为8.
在得到所有读写内存的程序语句之后便可以利用词法分析的方式提取左右操作数存入每个结点中.在这之后便可对每条语句的左操作数遍历匹配所有在其之后语句的右操作数,匹配成功就说明语句间有数据读写关系,将二者连接起来便构成数据流图的边.这个过程中要考虑到操作数被覆盖写(overwrite)的情况,即结点A和结点B含有相同作用域的左操作数Lop,且A的语句顺序在B之前,那么在遍历到B时,对A的Lop的匹配任务应立即停止,因为Lop将被B的计算结果写覆盖,B之后所有用到Lop的结点将不再依赖A.在得到所有的结点和边之后,便可通过构造邻接表(adjacency list)的方式构造数据流图,用于决定结点的存储或重计算的策略.
2.3 存储与重计算策略
介绍ROD方法所使用的结点存储或重计算决策模型的设计与实现细节.使用Vi表示每个结点,定义写内存开销为Mw(Vi),读内存开销为Mr(Vi).使用0-1变量αi来决定是否将结点Vi的计算结果存入内存,如式(1)所示:

(1)
定义每个结点的生产开销为P(Vi),如式(2)所示,分为计算开销C(Vi)和保存计算结果的开销Mw(Vi)这2部分.
P(Vi)=C(Vi)+αiMw(Vi),
(2)
其中计算开销C(Vi)的定义如式(3)所示,包括结点计算自身结果所产生的开销o(Vi)以及访问其所有直接生产者的开销D(Vj).
(3)
结点数据要么从内存中读出,要么通过计算产生,因此结点的直接生产者开销D(Vj)如式(4)所示:
D(Vj)=αjMr(Vj)+(1-αj)C(Vj),
(4)
当αj=1时,说明其生产者结点为存储结点,只存在读内存的开销Mr(Vj),当αj=0时,说明其生产者结点为重计算结点,因此需要使用式(3)递归计算其开销.由此可以看出重计算路径越长,其递归层数越深,重计算开销也就越大.
1.4节介绍了一种贪心的决策方法,即只根据当前结点的重计算开销和存储开销做决策,不考虑所做的决策对其消费者产生的读开销,即:
1) 若当前结点Vi采用存储策略,则将计算结果保存到内存,需要用到时直接从内存中读取,产生的开销为Mw(Vi);
2) 若当前结点Vi采用重计算策略,则不保存计算结果,需要时重新计算产生,产生的开销为C(Vi).
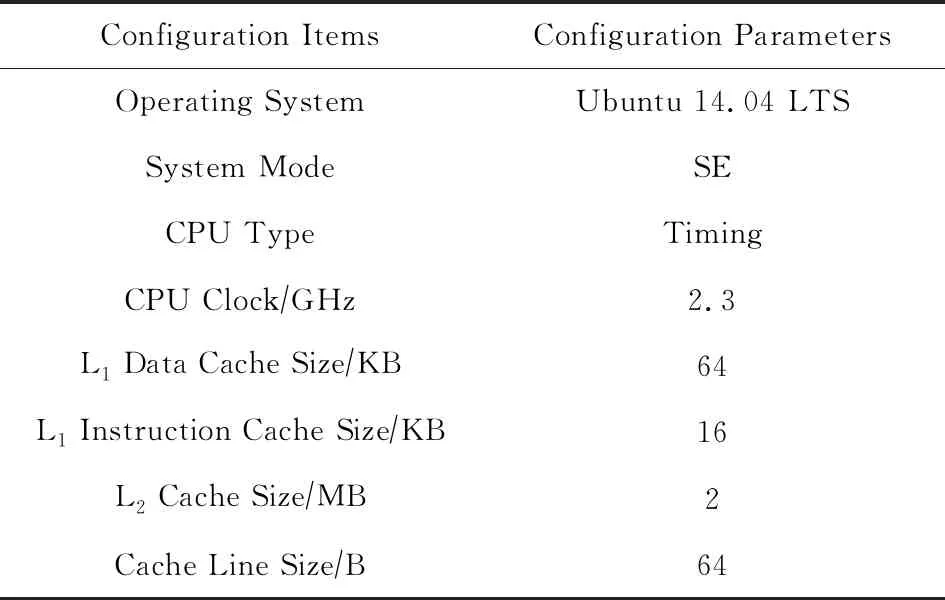
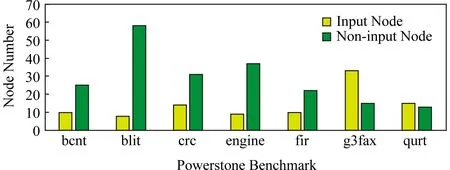
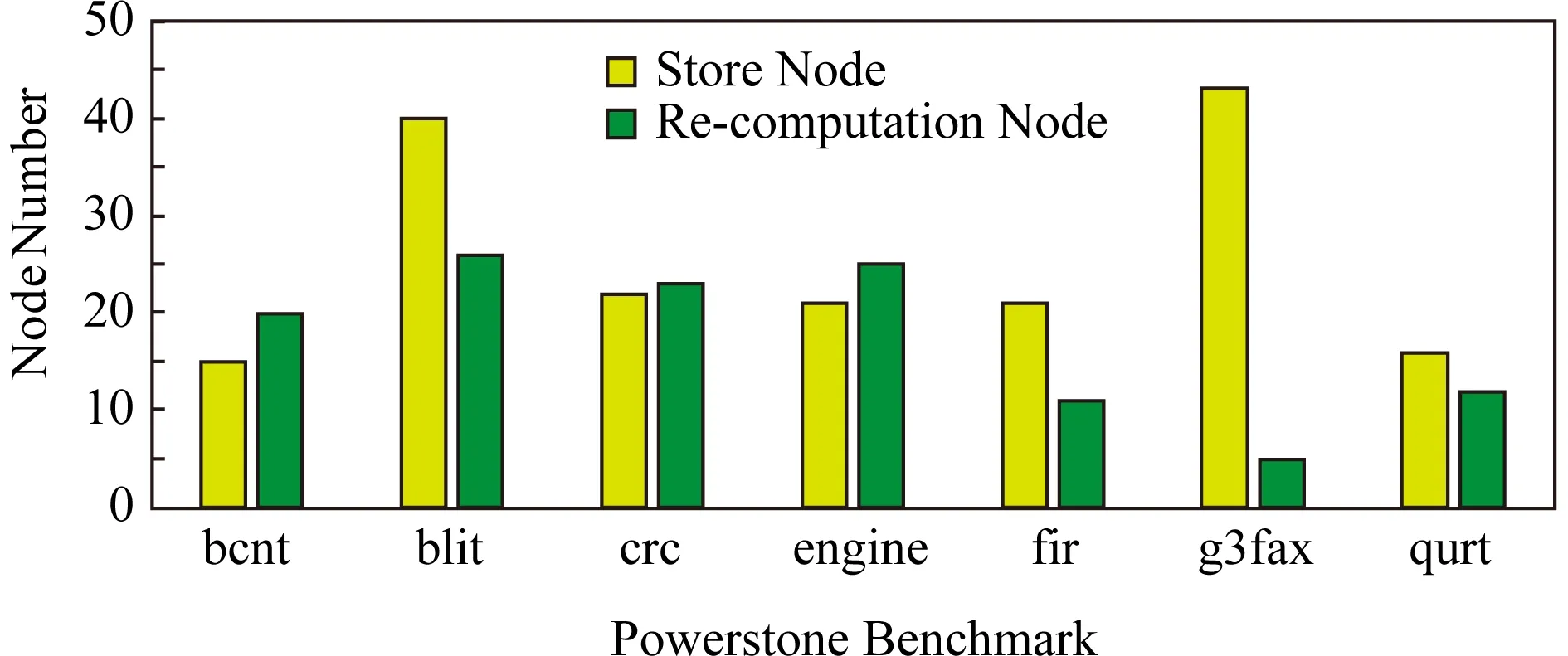
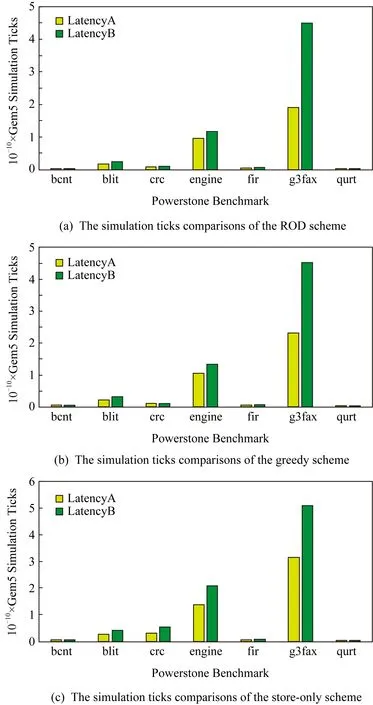
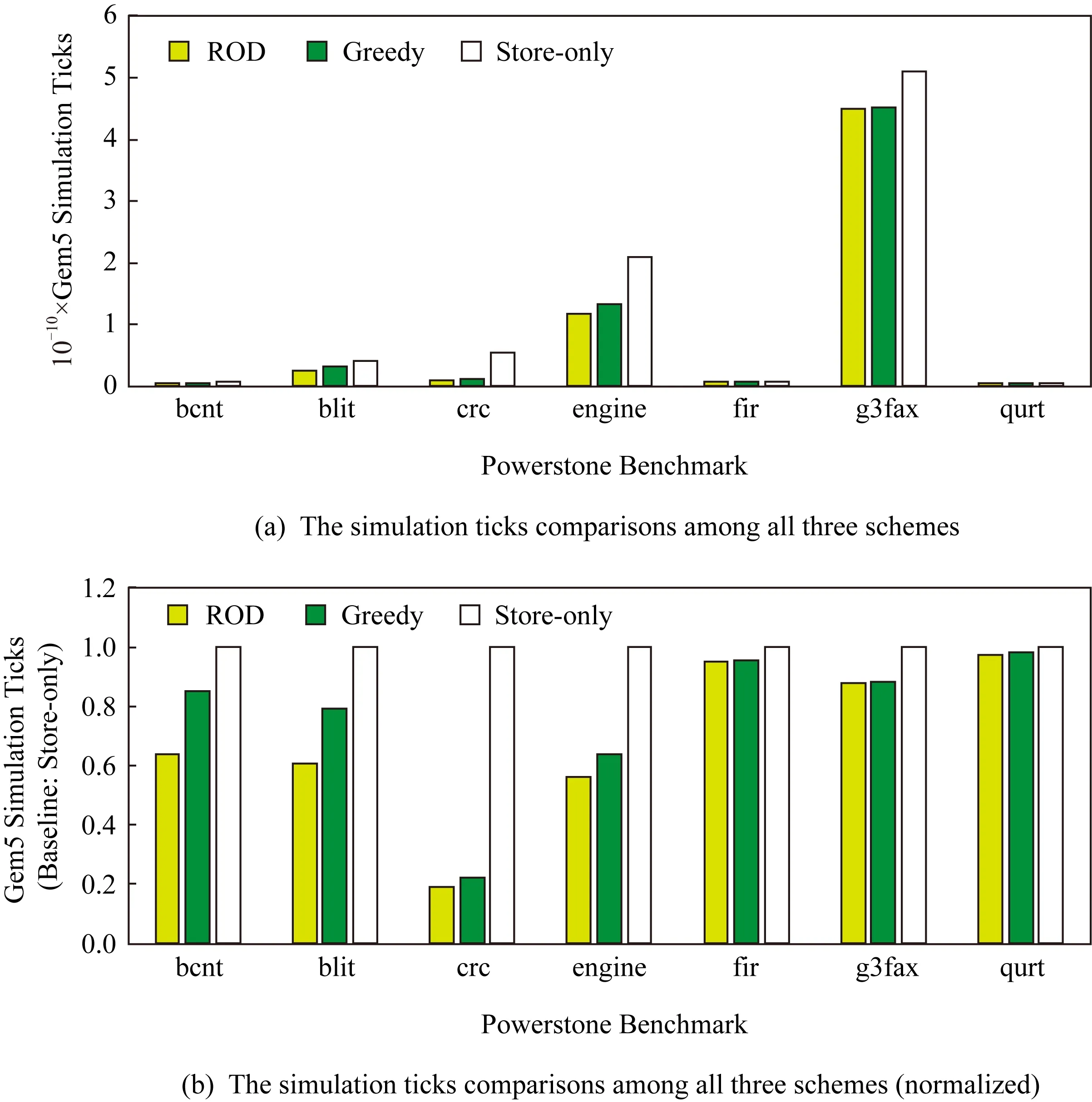
由于程序的输入结点不可重计算,因此输入结点均采用存储的方案,其余结点则需要比较Mw(Vi)与C(Vi)之间的大小关系,Mw(Vi) 为此提出一种新型的决策模型.记每个结点Vi的出度为φi,那么该结点若使用存储策略,则其计算结果将被读φi次,若使用重计算策略,则需要被重计算φi次.因此结点的存储开销WS和重计算开销WR如式(5)所示: (5) 其中C(Vi)的定义同式(3),当WS 算法1.结点存储或重计算的决策算法. 输入:程序的数据流图DFG; 输出:存储结点集合A和重计算结点集合B. ①A←∅,B←∅; ② for each nodeNin DFG do ③ ifN是输入结点then ④ addNto setA; ⑤ else ⑥P←producer ofN; ⑦φ←the out degree ofN; ⑧RCost←0;*RCost为重计算开销* ⑨ whilePis not NULL do ⑩ addP’s cost toRCost; 算法1的行③~⑤表示存储所有的输入结点,第⑥行的P表示结点N的一个生产者,由于采用邻接表法表示数据流图,因此结点N的其他生产者均可以由P访问到.行⑨~表示累加结点N的所有生产者的开销,得到再加上结点N自身的计算开销o(N),最后利用式(3)(5)即可得到结点N的重计算开销RCost.在决策时认为每条IR指令运行的CPU时钟周期数为1,通过IR指令的数量与C程序语句的数量之比即可确定计算每个结点的时钟周期数.行通过式(5)计算结点N的存储开销,在实现中采用的是PCM的读写延迟.行~通过比较RCost与SCost来决定结点N的计算结果是存储还是重计算. 为了更好地理解重计算过程,对不同的存储与重计算策略进行举例说明.图6是包含7个结点的数据流图,共有3个输入结点、1个输出结点以及3个中间结点,其中图6(a)表示只存储输入结点的数据,记为决策(a).图6(b)表示不仅存储输入结点的数据,还存储中间结点V4的计算结果,记为决策(b). Fig. 6 Different decisions on store or re-computation图6 关于结点存储或重计算的不同决策 在传统的执行流程中需要将7个结点的计算结果都写入NVM,但决策(a)中只存储结点V1~V3,决策(b)中只存储结点V1~V4.决策(a)在执行过程中对每个结点所产生的操作如表1所示: Table 1 Operations on Each Node of Decision (a)表1 决策(a)对每个结点的操作 从表1可以看到决策(a)产生了10次读NVM、3次写NVM、5次重计算,相比较于传统执行流程减少了4次写NVM的操作.决策(b)在执行过程中对每个结点所产生的操作如表2所示: Table 2 Operations on Each Node of Decision (b)表2 决策(b)对每个结点的操作 从表2可以看到决策(b)产生了7次读NVM、4次写NVM、2次重计算,相比较于传统执行流程减少了3次写NVM的操作. 这2种决策方案相较于传统的执行流程都可以减少对NVM的写操作,虽然决策(a)比决策(b)少了1次写操作,但却多出了3次读操作开销和2次重计算开销.由此可以看出不同的决策方案即使相似,也可以对系统性能产生截然不同的影响. 通过2.3节的结点决策算法得到决策图后,下一步便是从决策图中寻找重计算路径,对此部分做详细介绍. 由于重计算结点并不保存计算结果,因此需要从其生产者结点开始回溯到最近的存储结点,从NVM中读取相应的值,再从存储结点开始顺着回溯的路径重新计算出所需的结果,这条回溯的路径便是重计算路径,本文通过构造重计算函数来实现重计算路径. 第1步.为了找到回溯的路径,需要记录每个重计算结点的直接生产者,通过逐级查找的方式找路径.为了达到这个目的,需要在构造数据流图时通过结点链表记录每个结点指向的所有生产者结点,在经过ROD方法的决策之后,便可以得到所有的重计算结点及其直接生产者结点的关系表,进而找到重计算路径.例如,对于图4的源代码及图5的决策结果,其重计算结点及重计算路径如表3所示: Table 3 Re-computation Nodes and TheirRe-computation Paths表3 重计算结点及其重计算路径 ROD方法采用深度优先全路径遍历的方式寻找重计算路径.对于结点V3,其直接生产者为V1,但V1是存储结点,没有直接生产者,因此重计算V3的路径为V3→V1.同理可得结点V4的重计算路径为V4→V2,对于结点V5,其直接生产者V3和V4均可在表3中找到,需要对V3和V4做递归遍历,因此其路径遍历的结果为V5→V3→V1和V5→V4→V2. 第2步.在找到每个重计算结点的重计算路径之后,需要实现重计算这个过程,因此需要构造重计算函数,构造重计算函数的过程实质上就是根据重计算路径做递归计算的过程.例如,对于上述的重计算结点V3,V4,V5,它们的重计算函数rec_x3,rec_x4,rec_x5如图7所示: intrec_x3(intx1){ returnx1+4; } intrec_x4(intx2){ returnx2×2; } intrec_x5(intx1,intx2){ returnrec_x3(x1)-rec_x4(x2); } int main(){ intx1=1; intx2=2; intx3=x1+4; intx4=x2×2; intx5=rec_x3(x1)-rec_x4(x2); intx6=rec_x5(x1,x2)+8; } Fig. 7Theimplementationofre-computationfunctions 重计算方法虽然具有减少写NVM次数的优点,但也会有计算开销大的缺点,因此在实际的决策过程中,要充分考虑到NVM材料的读写开销与指令的执行开销,选择保存出度较大的结点的计算结果可以对后续结点的重计算过程更有利,这也是ROD方法的核心决策观点. 在实现数据流图的生成、结点决策算法以及重计算路径的生成等模块之后,使用Gem5模拟器对比了ROD方法、存储主导方法和贪心方法的性能. 在Ubuntu操作系统上使用LLVM套件,C++语言以及g++编译器完成各功能模块的开发部分,各开发工具的版本号如表4所示: Table 4 The Version Configurations of Development Tools表4 开发工具的版本配置 完成开发后使用Gem5[25]模拟器对各方法做性能评测.Gem5模拟器用于计算机系统架构的相关研究,包括系统级架构和处理器微架构.为了模拟非易失内存的读写延迟,使用NVMain[26]作为插件配合Gem5做模拟,NVMain是一个体系结构级的非易失内存模拟器,可以准确地模拟内存系统的时序和能耗.Gem5实现了x86指令集中的clflush[27]指令和mfence[28]指令,可以利用这些指令将缓存行的数据有序的刷回NVM中,Gem5模拟的系统配置如表5所示,其中NVMain的配置与Choi等人[29]提出的PCM配置相同,使用NVMain内置的PCM_ISSCC_2012_4GB.config即可,其中PCM的频率为500 MHz,读延迟为120 ns,写延迟为150 ns. 实验采用的测试集为powerstone benchmark[30],它包含一系列嵌入式和可移植的应用程序,包括分页、自动控制、信号处理以及图像处理等方面,程序中数据依赖关系明显,具有不同的访存特征.实验选取了powerstone benchmark部分测试程序,各测试程序的描述[30]如表6所示. Table 5 The Configurations Parameters of Gem5表5 Gem5配置参数 Table 6 The Description of Benchmark表6 Benchmark各程序描述 为验证ROD方法的有效性,对比了传统的无重计算的存储主导方法和1.4节所描述的贪心方法,并测试在不同PCM读写延迟下3种方法的运行耗时. 1) 测试不同程序按数据依赖划分出的结点数,包括输入结点数和非输入结点数.实验中提取了每个测试程序的所有赋值语句,每条赋值语句为一个结点,赋值语句之间存在典型的数据依赖关系.赋值语句中不可被重计算的属于输入结点,其他可以被重计算的属于非输入结点.测试结果如图8所示. 分析上述实验结果,除了g3fax和qurt,不同应用程序的非输入结点数较多,平均占比约为65%,由于只有非输入结点才可以被重计算,因此程序的输入结点越少,临时的存储开销就越少,重计算方法的多算少读的优势就会越明显. Fig. 8 The number of input nodes and non-input nodes of different programs图8 不同测试程序的输入结点数和非输入结点数 2) 测试ROD方法对结点的决策结果.由于程序输出结点的计算结果一般会被写入NVM,因此每个程序的存储结点数会比输入结点数多.ROD方法通过结点的出度权衡读开销和重计算开销,其决策结果如图9所示: Fig. 11 The performance comparisons among the ROD scheme, the greedy and the store-only schemes图11 ROD方法、贪心方法和存储主导方法之间的性能对比 分析上述实验结果,g3fax的重计算结点数较少,占比总结点数的12.5%,所有程序的重计算结点数占比平均为44.3%,最高为68.5%.这也说明了使用ROD方法最多能减少程序68.5%的写NVM操作,这一方面可以减少IO带来的延迟,另一方面也能提高NVM的寿命. 3) 测试贪心方法对结点的决策结果,结果如图10所示: Fig. 10 The decision result of the greedy scheme图10 贪心方法的决策结果 分析上述实验结果,g3fax的重计算结点数较少,占比总结点数的10.4%,所有程序的重计算结点数占比平均为39.8%,最高为57.1%,存储结点数平均比ROD方法增多了4.5%.虽然贪心方法也能减少对NVM的写操作,但从结果看ROD方法更优. 从图10可以看出,经过贪心方法决策出存储结点的数量和ROD方法的决策结果相近.但其实对选择哪些结点做存储,二者有着不同的结果.比如对于程序engine,ROD方法和贪心方法分别存储了20个和21个结点的计算结果,但ROD方法存储了4个贪心方法未存储的结点,而贪心方法存储了3个ROD方法未存储的结点. 4) 测试ROD方法、贪心方法以及存储主导方法的性能.三者数据流图的生成算法相同,ROD方法和贪心方法的重计算路径生成算法相同,存储主导的方法将每个结点的计算结果都存储到NVM,无重计算路径.Gem5中使用ticks数作为程序的运行耗时,通过运行后的统计信息可知1 000 ticks为1个CPU时钟周期.使用3种方法的程序运行耗时结果如图11(a)所示.以存储主导方法为基准,对程序运行耗时做归一化处理,结果如图11(b)所示. 分析上述实验结果,使用式(6)计算ROD方法相对于贪心方法的性能提升. (6) 结果显示ROD方法的运行耗时比存储主导的方法平均减少28.1%(最高68.6%),比贪心重计算的方法平均减少9.3%(最高19.4%). 从图11可知由于g3fax程序的输入结点占比过多,导致其存储开销大,虽然非输入结点占比少,但重计算仍可以有效减少IO开销.由于fir程序和qurt程序的指令数较少,运行时间短,因此在3种方法下ticks数相差不大.从图9可知bcnt程序的重计算结点数是其存储结点数的2倍,但重计算方法的性能相比于存储主导方法的性能只提升了19.5%左右.分析其源程序可知,所有重计算结点均在主循环内,且循环次数为256,因此对于重计算路径较长的结点而言是不利的,这样的路径需要被循环计算256次,因此对于bcnt程序而言,重计算所带来的收益不是很明显. 5) 测试在不同的PCM写延迟下,ROD方法、贪心方法以及存储主导方法的运行耗时.图9~11展示了在PCM读延迟120 ns,写延迟150 ns,记为延迟A(latencyA)情况下的实验结果.为了进一步探究写延迟对重计算方法的影响,根据Kim等人[31]关于PCM延迟的工作选取了另外一组延迟,其中读延迟仍为120 ns,写延迟设置为338 ns,记为延迟B(latencyB). 如2.3节所述,PCM的写延迟会影响结点的存储开销或重计算开销,因此对于不同的PCM写延迟,ROD方法和贪心方法对结点的存储或重计算策略均有着不同的选择.测试在不同写延迟下,程序使用3种方法的运行耗时,实验结果如图12所示: Fig. 12 The performance comparisons between different latencies with the ROD scheme, the greedy and the store-only schemes 图12 不同延迟下使用ROD方法、贪心方法和存储 主导方法的性能对比 分析上述实验结果,对于ROD方法、贪心方法和存储主导方法,程序使用延迟B的运行耗时比使用延迟A的运行耗时分别平均增加了32.1%,31.6%,40.8%.由于存储主导方法没有使用重计算以减少写次数,因此其运行耗时增加的幅度最大. 在使用延迟B的情况下,各测试程序使用ROD方法、贪心方法与存储主导方法的运行耗时结果如图13(a)所示.以存储主导方法为基准,对程序运行耗时做归一化处理,结果如图13(b)所示. Fig. 13 The performance comparisons among the ROD scheme, the greedy and the store-only schemes图13 ROD方法、贪心方法和存储主导方法之间的性能对比 上述实验结果显示ROD方法的运行耗时比存储主导的方法平均减少31.3%(使用延迟A为28.1%),比贪心重计算的方法平均减少10.7%(使用延迟A为9.3%).与延迟A相比,延迟 B中NVM的写延迟更高,因此ROD方法通过减少写操作,在使用延迟B的情况下性能提升也更大. 6) 实验总结.以上实验结果验证了ROD方法的有效性,并说明了重计算“以计算换存储”的方式可以有效减少对NVM的写操作,进而提升程序的运行效率,同时也应当对结点做出合理的决策以避免重计算路径过长导致计算开销过大的缺点. 实验中,在编译期根据决策模型对结点做静态决策,以确定需要重计算的数据.因此编译期的开销在时间和空间上包括数据流图的构造开销、结点的决策计算开销和生成重计算函数的开销. 由于是静态决策,无法得知程序运行时CPU缓存的状态,因此在结点决策时不考虑CPU缓存对数据loadstore的影响,load操作默认为从NVM中读取数据,store操作默认为向NVM中写数据.实验中读写NVM开销和重计算开销的产生过程如下: 1) 对于存储结点均使用clflush和mfence指令,显式地将其计算结果从CPU缓存直接刷回NVM,这一部分是结点的读写NVM开销; 2) 对于重计算结点的计算结果,CPU缓存并不将其刷回NVM,而是通过编译期静态决策所确定的重计算路径,在使用时将其重新计算出来,这一部分是结点的重计算开销.程序运行时,如果重计算所需的输入数据存在于CPU缓存中,则可以加速计算过程,但由于CPU缓存状态的不确定性和多样性,所以在静态决策时没有考虑这种情况. 对同一结点做不同的决策,通过比较读写NVM的开销和重计算开销以体现重计算方法的先进性. 实验模拟的CPU使用了缓存,主要目的是缓存中间计算结果,因为决策是以C语言一条语句为粒度,但一条语句可能产生多条汇编指令,这其中会产生中间计算结果.如果不用缓存,虽然可以确保loadstore指令只面向NVM,但中间计算结果可能会写入NVM,会导致重计算过程对NVM产生额外的写操作. 需要说明的是,clflush指令可以指定刷回数据的地址,确保数据写入NVM,但带来的副作用是此缓存行的其他数据也被刷回NVM,会造成一定的额外开销. 首先讨论在系统容错和恢复方面的工作,然后讨论重计算在减少对内存写操作方面的相关工作. 1) 系统容错和恢复.在高性能计算(high per-formance computing, HPC)应用或者并行的大规模系统中容易出现运行错误的情况.Alshboul等人[32]提出了基于重计算的故障安全方法,并证明了它对HPC应用中循环代码的适用性,该方法只记录足够的应用级数据来启动重新计算,并且相比日志文件和检查点文件方法能大幅减少执行时间以及额外的写次数.Ren等人[33]基于HPC应用的固有容错性,引入了EasyCrash框架,在应用程序执行期间选择性地持久保存应用程序数据对象, 与传统检查点技术一起使用提高系统效率. 2) 减少对内存的写操作.Hu等人[34]结合数据迁移和重计算,利用嵌入式系统的便笺存储器(scratch pad memory, SPM)减少对NVM的写操作,其工作将数据在多个核之间的迁移转化为图计算并寻求最短迁移路径,如此,不同的核便可以利用迁移的数据进行重计算.Huang等人[35]提出用重计算方法减少嵌入式系统中寄存器分配过程的变量溢出数目,从而减少对NVM的写操作.Hu等人和Huang等人关注的重点是嵌入式系统中减少对NVM的写操作,并分别从数据迁移和寄存器分配过程中的变量溢出数目的角度应用重计算方法.Koc等人[36]利用距离处理器更近的片上存储(on-chip memory)的数据重新计算远离处理器的数据,而不是直接访问远数据,以减少访问延迟.Akturk等人[37]给出了在微架构级别的概念性验证,对重计算能耗和存储能耗做了比较,提出通过最后一级缓存(last level cache, LLC)是否缺失的方法以动态决策重计算.Koc等人和Akturk等人均从被访问的数据与处理器之间距离的角度考虑重计算方法,并没有限定存储器的种类. 与现有的这些重计算方法相比,本文更关注如何对程序的中间计算结果做存储或重计算的决策,以较小的重新计算开销换取较大的写NVM开销.为此提出基于结点出度的重计算方法,本方法的创新点在于对结点做存储或重计算的决策时考虑到其直接消费者个数对于决策的影响. 相比于DRAM,新兴的非易失存储器(NVM)作为持久性内存带来了非易失性、低能耗以及高存储密度的优点,但同时也存在写操作延迟高和写寿命短的缺点,因此如何减少对NVM的写操作成为一个非常重要的问题.为了解决这个问题,本文设计并实现了一种基于结点出度的重计算方法称作ROD.ROD方法按数据流图对程序语句划分结点,利用结点的出度规划了重计算或存储的选择策略,通过选择性丢弃要写回NVM的数据,需要时再重新计算产生,以此减少对NVM的写操作,降低系统的IO开销.在搭载了NVMain的Gem5模拟器中使用powerstone测试集对ROD方法做了性能评测,并与贪心重计算方法和传统的以存储为主导的无重计算方法作比较.实验结果显示,ROD方法相比于存储主导的方法平均减少44.3%(最高68.5%)的写操作.ROD方法的运行耗时比存储主导的方法平均减少28.1%(最高68.6%),比贪心重计算的方法平均减少9.3%(最高19.4%).



2.4 重计算路径的生成


图7 重计算函数的实现3 实验结果与分析
3.1 实验环境


3.2 实验结果

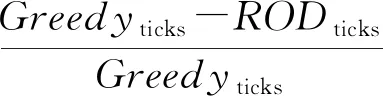
3.3 实验细节
4 相关研究工作
5 结 论
