基于Markov 时间博弈的移动目标防御最优策略选取方法
2020-02-09谭晶磊张恒巍张红旗金辉雷程
谭晶磊,张恒巍,张红旗,金辉,雷程
(1.信息工程大学三院,河南 郑州 450001;2.河南省信息安全重点实验室,河南 郑州 450001)
1 引言
全球性网络安全攻防竞赛[1]已经达到前所未有的强度,各类网络攻击事件愈演愈烈,网络攻击者不断制定新的攻击策略。其中,移动目标攻击(MTA,moving target attack)技术是最受攻击者欢迎的攻击方法之一,它利用各种不确定的攻击手段隐藏攻击意图,并试图逃避传统网络防御的检测机制。由于传统网络防御机制无法准确预知攻击者下一步攻击行动,MTA 技术在网络攻防博弈中逐渐获得竞争优势,这不仅对网络空间造成了很大的安全威胁,而且产生了高昂的防御成本。
近年来,网络安全战略经历了从被动防御到主动防御的演化升级,新兴的移动目标防御(MTD,moving target defense)技术[2]已经成为平衡网络安全竞争环境的新方法,它通过引入动态性、随机性以及异构性来保护网络空间,旨在利用攻击面的动态变换打破网络系统的静态特性,向攻击者呈现一个不可预测的网络状态,以阻止攻击者的恶意行为,增加攻击者攻击成功的难度。
MTA 与MTD[3]依据攻防成本和收益选取最优策略攻防收益最大化,具有关系非合作性。在移动目标攻防对抗过程中,MTA 试图通过各种攻击手段控制系统攻击面,将攻击面的暴露范围不断扩大,为后续持续性攻击做好准备;而MTD 则通过动态化、随机化和多样化的方法控制系统攻击面,转移或者减少系统攻击面,以拒止MTA 的攻击行动,因而移动目标攻防双方具有目标对立性。移动目标攻防双方对于最优策略的选取不仅仅取决于自身,同时也取决于对手,因此移动目标攻防双方具有策略依存性。移动目标攻防过程所具有的关系非合作性、目标对立性和策略依存性与博弈论的理论特性相契合,博弈论可在选取移动目标防御最优策略的研究中发挥重要作用。
姜伟等[4]提出了一种基于完全信息博弈的最优防御策略选取算法,通过构建攻防随机博弈模型,预测攻击行为,并由此制定最优防御策略。林旺群等[5]提出了基于完全信息动态博弈的最优策略,通过引入“虚拟节点”将攻击图转换为博弈树,采用非合作动态博弈求解最优防御策略,但是该模型并没有给出详细的策略选取算法。Manadhata 等[6]则提出了基于随机博弈的最优攻击面变换方法,为了权衡安全性和可用性,将移动目标防御形式化为二人随机博弈。然而,单阶段博弈难以有效刻画移动目标防御持续动态变化的特性,因此Vadlamudi 等[7]提出了基于贝叶斯攻击图的移动目标防御最优策略选取方法,它利用贝叶斯攻击图描述了攻击方利用的脆弱性间的关联关系,以及防御方可观测到的攻击行为和网络安全状态,但是仍然难以表征攻防对抗的动态性。为了刻画MTD 攻防对抗的动态连续特性,Lei 等[8]将攻防双方对资源脆弱性的利用抽象为攻击面和探测面的变化,并在收益函数的计算中考虑了跳变的性能消耗。由于攻防双方的行为策略会导致网络系统状态的改变,且状态转移具有Markov 性,Maleki[9]提出了基于Markov 的移动目标防御博弈模型,通过将Markov 决策过程与博弈模型相结合,对单目标IP 跳变和多目标IP 跳变策略进行分析,证明多元素跳变可以有效提高防御的收益,但是基于Markov 的博弈收益量化仍然依赖攻防对抗的历史数据和专家经验。
虽然现有的研究取得了一定成果,但在模型构建和收益量化方面仍存在不足。一方面,现有的研究工作大多基于随机博弈、贝叶斯博弈等博弈模型,难以有效刻画MTD 攻防的动态连续特性;另一方面,现有的收益量化方法大都基于历史数据与专家经验表征刻画,难以保证决策结果的客观准确性。基于此,本文引入时间博弈进行博弈的动态性刻画,并利用时间博弈隐蔽对抗的特性构建MTD 攻防模型,基于Markov 决策过程表征MTD 状态的随机迁移特性,通过攻防双方对攻击面的控制时间量化攻防收益。
2 移动目标攻防集合策略构建
2.1 移动目标攻击策略
移动目标攻击体系已经逐步发展并不断完善,常见的移动目标攻击技术如表1 所示。
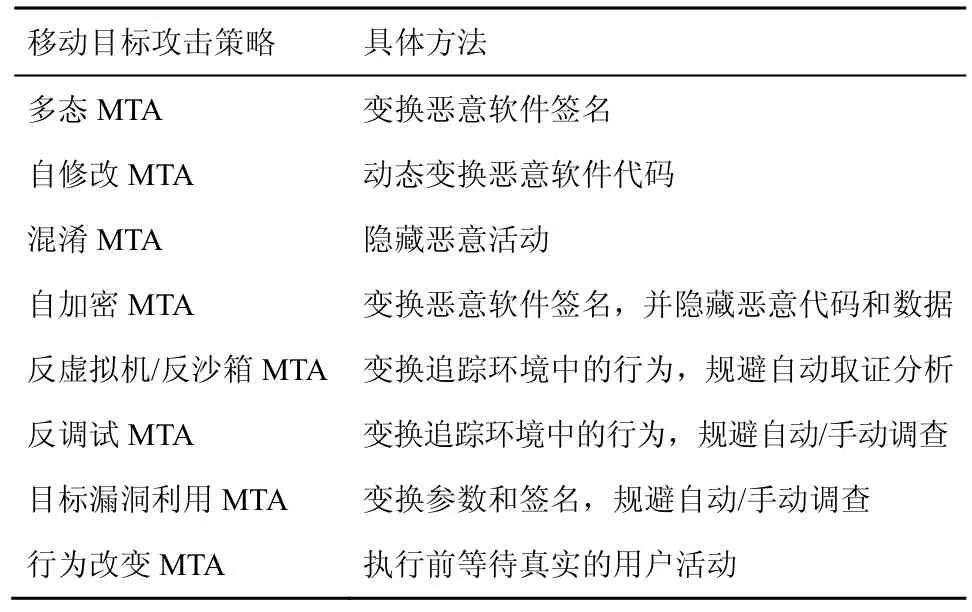
表1 移动目标攻击技术分类
多态MTA 可以有效规避防御者入侵检测系统的特征检测。一方面,多态MTA 使用多个加密密钥生成相同恶意软件的不同实例,由于新实例具有新的未知静态签名,使基于签名的反恶意软件防御无效。另一方面,多态MTA 有效载荷(代码和数据)是加密的,可以绕过防御者的深层静态分析。多态MTA 通过更改内存中的代码使防御者的攻击检测过程复杂化。
与多态MTA 类似,自修改MTA 可以有效规避文件和内存的自动扫描,而混淆MTA 则可以有效逃避手动检查代码。混淆MTA 所创建的具有混淆性的代码通常难以被传统检测手段发现,它可以创建带有模糊字符串的有效负载、虚拟代码和复杂的函数调用图,并随机生成恶意软件实例。自加密MTD 则通过变换恶意软件签名来隐藏恶意代码和数据。
反虚拟机/反沙箱MTA 是另一种移动目标攻击方法,恶意软件分析通常利用虚拟机或沙箱环境检测恶意软件的运行活动,如果检测到虚拟机或沙箱,则反虚拟机/反沙箱MTA 会改变其行为并避免任何恶意活动。一旦在真实系统上执行并被标记为良性之后,它就会开始其恶意行为。
反调试MTA 可以避免调试和运行时的检测分析。如果反调试MTA 在运行时检测到调试工具,则会更改其执行流程保持良性操作。如果它未被调试工具检测到,则会启动恶意行为。
目标漏洞利用MTA 可以更改统一资源定位符(URL,uniform resource locator)模式、主机服务器、加密密钥和文件名,还可以通过限制来自相同IP地址的漏洞访问次数来规避蜜罐防御。
行为改变MTA 通常在真实用户交互后发动攻击,因而它可以确保在真实机器上执行攻击。
这些有效的移动目标攻击方法为攻击者赢得了不对称的攻击优势,使传统防御技术处于被动不利的局面。攻击者明确自己的攻击对象、攻击时间、攻击目标和攻击方式,而防御者则处于不确定状态,只能利用大量的成本、时间和资源来规避攻击者可能发起的任何攻击探测和入侵活动。因此,防御者和攻击者之间不存在理论上的对称性。
2.2 移动目标防御策略
防止移动目标攻击的最佳方法是使用基于移动目标防御的新安全解决方案。2009 年,美国国家赛博跨越式发展年会首先提出了移动目标防御这一概念,提出移动目标防御通过持续变换系统呈现给攻击方的攻击面,从而有效增加攻击方探测目标节点脆弱性的代价[10]。2012 年,美国白宫国防安全委员会在赛博空间安全研究进展报告[11]中明确了移动目标的概念,即移动目标是可在多个维度上通过移动来降低攻击方优势并增加系统弹性的技术手段。2014 年,《可改变游戏规则的赛博空间安全研究与发展建议》中则将移动目标防御定义为一种创建、分析、评估和部署多样化、持续时变的机制和策略,以增加攻击实施的复杂度与成本,限制和降低系统脆弱性曝光度和被攻击的概率,提高系统弹性的防御手段[12]。
移动目标防御是一种新的主动防御思想,它通过移动或伪装攻击者探测的资源以扰乱应用程序存储器。当恶意软件获得对移动目标防御保护系统的访问权限时,它无法找到所需的易受攻击的资源以造成损害。就其本质而言,移动目标防御与攻击无关,因此可以有效抵御已知和未知攻击的多种变化。之前的研究[13]已经总结概述了它的基本理论框架,如图1 所示。
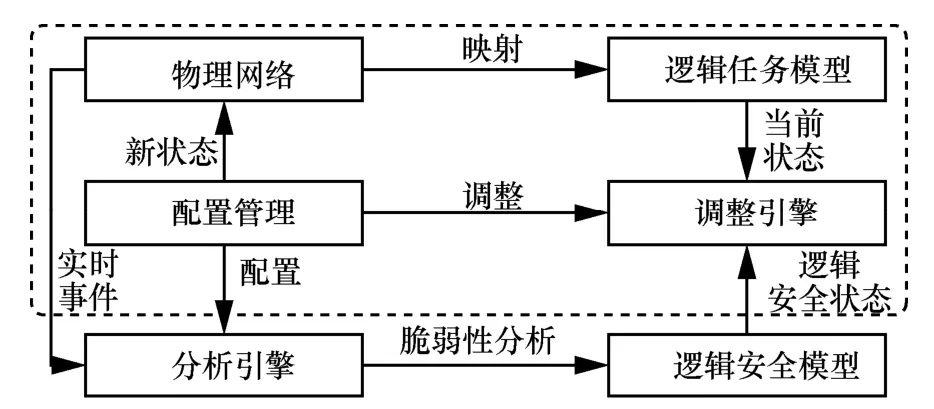
图1 MTD 理论框架
将物理网络映射到逻辑任务模型,由调整引擎获取逻辑任务模型的当前状态,并由配置管理调整产生新状态进行适应,分析引擎获取物理网络的实时事件,利用传统防御中入侵检测、防火墙等检测机制进行脆弱性分析,由逻辑安全模型产生逻辑安全状态发送给调整引擎,形成一个闭合自反馈的动态调整系统。
移动目标防御技术研究是针对系统不同要素、安全威胁和应用场景设计的可行防御策略,分为系统层MTD 和网络层MTD 这2 个层面,其中,系统层MTD 包括硬件MTD 和软件MTD,网络层MTD 包括MAC、IP、协议、路径、操作系统、指纹以及端口MTD,具体如表2 所示。本文所采用的移动目标防御策略为网络层MTD。
3 移动目标防御模型构建
3.1 移动目标防御时间博弈过程分析
2013 年,针对APT,美国RSA 实验室的Dijk[14]首次提出了时间博弈,与现有的大多数博弈模型不同,时间博弈由防御者和攻击者这2 个局中人以及公共资源构成,它允许局中人在任意时刻采取行动来控制资源。然而,在局中人实际移动之前,不会显示资源控制权,因此隐蔽性是时间博弈的最大特点。每个局中人的目标是最大化控制资源时间,同时最小化移动成本。在移动目标攻防过程中,根据时间博弈基本理论,网络攻防系统中的局中人共同争夺对公共资源(攻击面)的控制权,尽可能地最大化自身的收益,图2 显示了随着时间变化,移动目标攻击者(灰色)和移动目标防御者(黑色)之间的公共资源控制权的切换。
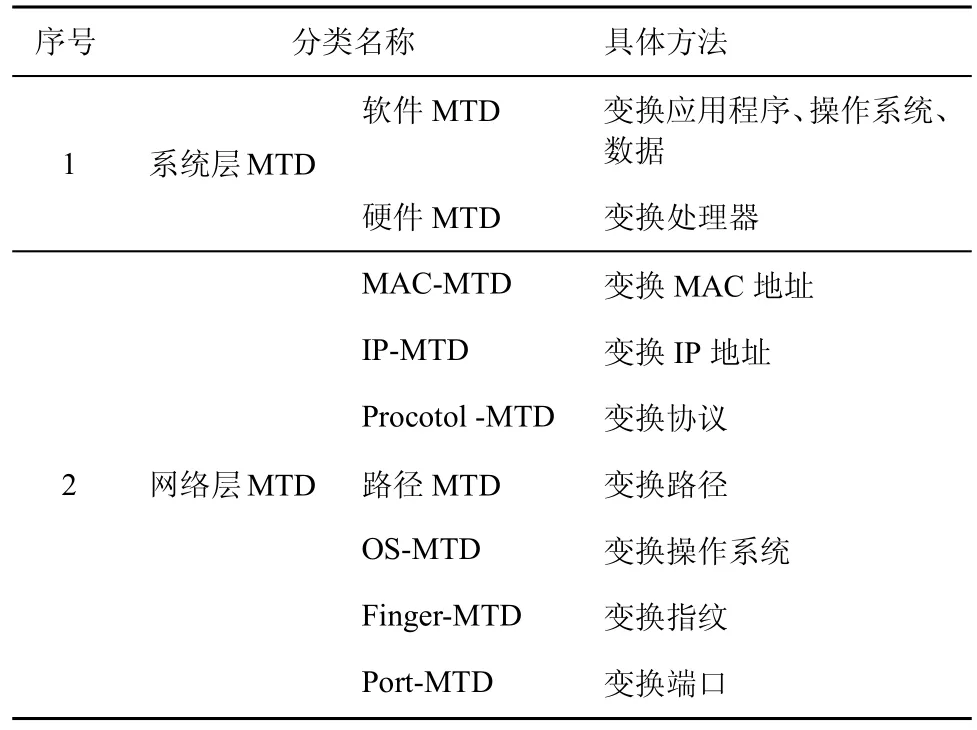
表2 移动目标防御策略集合分类

图2 移动目标防御时间博弈说明示例
移动目标攻防策略的实施都需要付出一定的成本,其中,移动目标攻击者的目标是破坏网络关键服务,并尽可能降低攻击成本。移动目标防御者的目标是增加安全防御预算,减缓或阻止攻击行为,以最大化移动目标攻击者的攻击成本。移动目标攻防双方都需要对系统攻击面进行控制,不同的是,攻击者是利用攻击面可用的脆弱性资源发起攻击,而防御者则是改变或减少攻击面脆弱性资源来提高攻击者的攻击难度,攻击面的控制权会随着局中人的行动发生变化。因此,利用时间博弈刻画单阶段移动目标防御过程更符合真实网络攻防场景。
本文首先利用时间博弈模型刻画单阶段移动目标防御过程,接着从全局视角出发,借鉴Markov 决策过程[15],将各博弈阶段之间的状态迁移描述为随机过程,将多阶段时间博弈与Markov 决策方法相结合,构建多阶段Markov 时间博弈并进行均衡求解。
3.2 Markov 时间博弈移动目标防御模型构建
首先,对单阶段时间博弈进行分析,如定义1所示。
定义1单阶段时间博弈模型(STG-MTD)。STG-MTD 表示为六元组(N,B,R,η,U,T),具体如下。
1)N={NMTA,NMTD}是攻防博弈的局中人集合,其中,NMTA代表移动目标攻击方,NMTD代表移动目标防御方。
2)B={PMTA,PMTD}是攻防博弈可行动作空间,其中,PMTA和PMTD分别代表移动目标攻击者和防御者的移动策略集。
3)R是移动目标攻防双方所竞争的公共资源,本文将网络中的攻击面视为公共资源。
4)η是博弈信念集合,ηMTAi表示移动目标攻击方选择MTA 策略PMTAi(0≤i≤m)的概率,满足表示移动目标防御方选择MTD策略PMTDj(0≤j≤l)的概率,满足。
5)U={UMTA,UMTD}是移动目标攻防双方的收益函数集合,它由所有局中人对攻击面的控制时间TN和策略实施所需成本CN共同决定,分别为UMTD(CMTDi,TMTDj)和UMTA(CMTAi,TMTAj),1≤i≤m,1≤j≤l。
6)T是博弈的总时间,T=TMTD+TMTA。
以单阶段时间博弈为基础,构建多阶段Markov时间博弈模型。
1)博弈模型定义
定义2Markov 时间博弈移动目标防御模型(MTG-MTD)。MTG-MTD 可以表示为十元组(N,K,R,S,f,B,η,U,β,T),具体如下。
①N={NMTA,NMTD}是攻防博弈的局中人集合,其中,NMTA代表移动目标攻击方,NMTD代表移动目标防御方。
②K是多阶段攻防博弈的阶段数,G(K)代表当前攻防博弈阶段,其中K={1,…,n},n∈ℕ。
③R是移动目标攻防双方竞争的公共资源,本文将网络中的攻击面视为公共资源。
④S={S1,S2,…,SK}是不同网络攻防阶段安全状态集合。
⑤f表示状态迁移概率,fij=f(Sj|Si)表示系统从状态Si迁移至状态Sj的概率,攻防双方的对抗行为是影响安全状态转换的关键因素,由于攻防双方的可行策略集和网络系统运行环境可能发生改变,因此状态转换具有一定随机性。
⑦η是博弈信念集合,在第k阶段,表示移动目标攻击方选择MTA策略(0≤i≤m)的概率,满足表示移动目标防御方选择MTD 策略(0≤j≤l)的概率,满足
⑨β是折现因子,表示博弈阶段k中的收益相较初始阶段的折现比例,0<β≤1 。
⑩T是单阶段博弈所需的总时间。
2)移动目标攻防收益量化
移动目标攻防收益量化是最优防御策略选取的基础,在文献[16]的研究基础上,本文从移动目标攻防双方对攻击面的控制出发,结合移动目标攻防策略特点,对移动目标攻防策略收益进行全面分析量化。
定义3防御成本(DC,defense cost)。DC 由移动目标防御者控制攻击面的时间成本TCASC和变换攻击面的时间成本THASC两部分组成,DC=TCASC+THASC。
定义4攻击成本(AC,attack cost)。AC 指移动目标攻击者发现系统漏洞并采取MTA 策略时所产生的时间成本。
定义5防御有效性(DE,defense effectiveness)。DE 是移动目标防御者实施MTD 策略对攻击面的控制时间。
定义6攻击有效性(AE,attack effectiveness)。AE 是移动目标攻击者实施MTA 策略对攻击面的控制时间。
定义7防御收益。防御收益指移动目标防御者控制攻击面获得的收益。
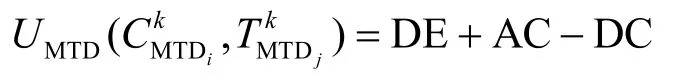
定义8攻击收益。攻击收益指移动目标攻击者控制攻击面获得的收益。

移动目标攻防收益矩阵M如下,和分别表示策略组合下的攻击收益值和防御收益值,满足定义7 和定义8。
令R为目标准则函数,用于判断移动目标攻防双方策略选取的优劣。常用的准则函数[17]主要有折现期望回报准则函数和平均回报准则函数。在移动目标攻防对抗过程中,由于网络系统信息的价值与时间相关,因此采用折现期望回报准则函数作为博弈双方的目标函数,其中,表示攻防双方分别采取策略PMTA和PMTD时相较于初始阶段的折现收益值,S为初始阶段状态,S′为未来阶段状态,US为初始阶段状态下的攻防收益值。
移动目标攻击方通过侦察网络攻击面,发现并利用系统资源脆弱性,进而导致系统性能开销增大或系统功能不可用。移动目标防御方通过选取MTD策略从而增大或转换攻击面,进而在保证网络功能正常安全运行的前提下提高系统的安全性。
由以上定义可知,经过有限次博弈后,系统在不同状态间进行迁移,可用攻防博弈树表示。在TG-MTD 模型构建的基础上,第4 节给出了模型的均衡策略分析求解和具体的最优防御选取算法。
4 博弈均衡求解与防御策略选取算法设计
根据第2 节的分析,不同博弈阶段中攻防双方对攻击面的控制顺序动态变化。因此,本节首先提出时间博弈的子博弈精炼纳什均衡求解方法,然后分析多阶段攻防博弈的求解过程。
4.1 博弈均衡分析
在时间博弈阶段G(K),移动目标攻防策略分别为若为第k阶段的时间稳定策略,则对于任意攻防策略和满足
不同移动目标攻防策略的选取会影响每阶段博弈情况,根据Markov 决策准则,局中人必有一个 Markov 最优响应策略[18]。因此,如果为Markov 最优响应策略,那么使目标准则函数对任意阶段k均满足式(2)所示条件。
定理 1多阶段 Markov 攻防时间博弈MTG-MTD 存在混合策略下的纳什均衡。
证明MTG-MTD 博弈由多个独立且相似的单阶段不完全信息动态博弈构成。一方面,由于每个独立的单阶段不完全信息动态博弈均属于有限博弈,因此,必定存在混合策略下的纳什均衡[19]。另一方面,由多阶段Markov 时间博弈模型的定义,依据转移概率和收益函数可知,存在与MTG-MTD等价的有限Markov 博弈,且收益函数为凸函数。依据有限Markov 博弈的均衡策略存在性定理[20],存在混合策略下的纳什均衡。证毕。
4.2 博弈均衡求解
4.2.1 单阶段时间博弈均衡求解
首先,给出单阶段时间博弈均衡的求解过程和步骤,参照完全信息动态博弈的相关理论知识,移动目标攻防双方对攻击面的控制权争夺具有先后顺序,先行动的一方的各种信息会被另一方完全掌握,因而后行动的一方可以根据对方的信息进行相应调整以最大化自身利益。
针对本文完全信息动态移动目标攻防场景,引入泽尔腾的子博弈精炼纳什均衡思想方法[21],去除均衡中的不可置信威胁策略的纳什均衡,得出合理的预测结果。不失一般性,子博弈精炼纳什均衡的每个信息集上的均衡结果均为最优策略。
移动目标攻防双方在不同策略组合下的收益矩阵可以用图3 的博弈树直观展示。假设博弈开始时刻由移动目标攻击者控制攻击面,随后移动目标防御者实施策略,争夺攻击面的控制权,单阶段博弈总时间为T。
4.2.2 多阶段Markov 时间博弈均衡求解
引入折现因子,将未来收益折算成基于初始阶段的折现收益,在此基础上,将博弈均衡策略的求解问题转化为非线性规划(NLP2,nonlinear programming second)最优值问题,求解多阶段均衡策略B*及其收益U*。

图3 网络攻防时间博弈树
对于K={1,…,n},n∈ℕ,有目标函数为
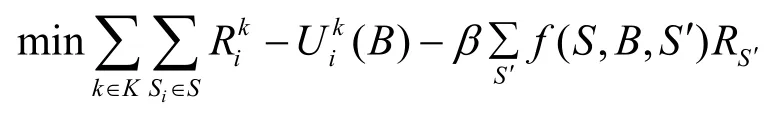
约束条件为
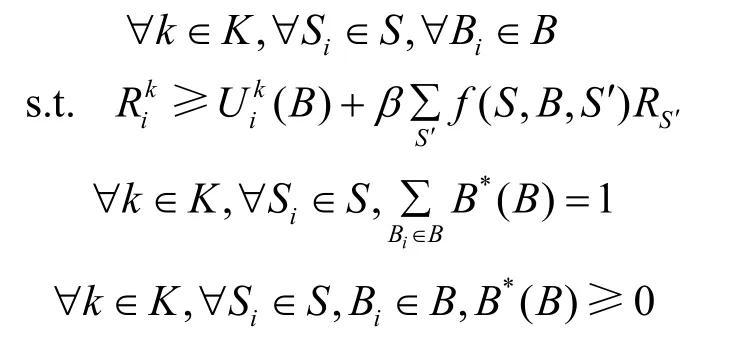
4.3 最优策略选取算法
基于移动目标攻防场景下多阶段Markov 时间博弈模型及其子博弈精炼纳什均衡的研究,给出多阶段Markov 时间博弈的最优主动防御策略选取算法。
算法1多阶段Markov 时间博弈的最优防御策略选取算法
输入多阶段Markov 时间博弈模型MTG-MTD
输出多阶段最优移动目标防御策略


算法的时间复杂度为O(k(m+n)2),空间复杂度为O(knm),表3 展示了本文提出的最优策略选取方法与其他最优策略选取方法的比较结果。在移动目标攻防对抗中,Manadhata 等[22]仅讨论了单阶段博弈。Clark 等[23]虽然将博弈模型扩展到多阶段,但仍不能揭示移动目标攻防对抗的多状态和多阶段过程。Lei 等[8]结合Markov 决策过程理论和动态博弈描述了多状态和多阶段特征。上述研究成果均采用历史数据与专家经验量化收益计算,本文针对MTD 攻防过程的动态连续特性,将时间因素加入收益度量能够提高收益计算的准确性。与上述方法相比,MTG-MTD 是基于Markov 时间博弈建立的,完美地展示了移动目标攻防过程的对立性、动态性及自适应性的特征。在最优策略选取方面,本文分析了时间因素对攻防成本和收益的影响,并将最优策略选取问题转化为非线性规划问题求解,在降低复杂度的同时大大增加了不同的应用场景下的通用性。
5 应用实例分析
5.1 应用实例
本节通过应用实例验证MTG-MTD 最优防御策略选取算法的有效性,利用软件定义网络(SDN,software defined network)的部分节点拓扑搭建了实验网络环境,系统结构如图4 所示。其中,LDAP服务器、FTP 服务器、Linux 数据库等控制服务器作为移动目标防御策略的应用目标,同时移动目标攻击者可以通过网络等途径访问控制服务器,它们的连通性通过表4 中的访问控制策略来确定,应用服务器作为控制服务器的应用提供者。移动目标攻击者具有对应用服务器的用户级访问权限,其目标是窃取存储在Linux 数据库服务器中的敏感信息。
移动目标攻击者的可能的攻击路径如下。
路径1:应用服务器→LDAP 服务器→Linux 数据库。
路径2:应用服务器→LDAP 服务器→FTP 服务器→Linux 数据库。

表3 不同策略选取方法对比分析
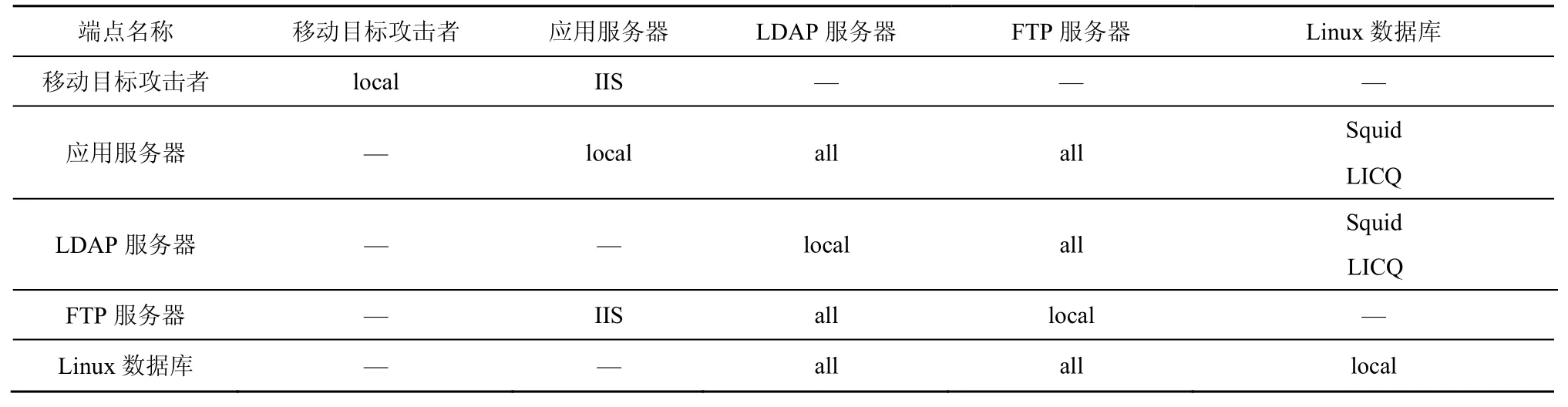
表4 访问控制策略

图4 实验系统结构示意
1)初始化参数
令S={S1,S2,S3,S4}表示网络阶段状态。其中,S1是移动目标攻击者利用应用服务器的漏洞,并获得其root 权限的阶段状态;S2和S3分别是移动目标攻击者利用LDAP服务器和FTP服务器的漏洞获得Linux 数据库访问权限的阶段状态;S4是攻击者通过利用Linux 数据库的漏洞获得root 权限的阶段状态。本实验中MTG-MTD 的折扣率为β=0.7。
2)构建策略空间,状态转移概率和收益矩阵
表5显示了每个网络状态下的移动目标攻防策略。PMTA={PMTA1,PMTA2,PMTA3,PMTA4,PMTA5,PMTA6,PMTA7,PMTA8}表示移动目标攻击者控制攻击面,相关MTA 策略集合如表1 所示。PMTD={PMTD1,PMTD2,PMTD3}表示移动目标防御者控制着攻击面,其中,PMTD1={IP(C 类),Port(64512),Timing(fixed)}表示MTD 在固定周期中变换IP 地址和端口号,括号中的内容表示相应变换元素的取值范围,IP(C 类)表示IP 的变换取值为C 类IP 地址空间,Port(64512)表示端口变换取值为64512,Timing(fixed)和Timing(random)分别表示MTD 固定变换时机和随机变换时机,PMTD2={IP(C 类),Port(64512),Timing(random)}表 示MTD 在随机周期中变换 IP 地址和端口号,PMTD3={Forwarding Path,Timing(fixed)}表示 MTD在固定周期内变换转发路径,括号中的内容表示相应变换元素的取值范围。同时,网络状态转移概率具体如表6 所示。依据3.2 节移动目标攻防收益的计算方法,表7 给出了移动目标攻防收益矩阵。
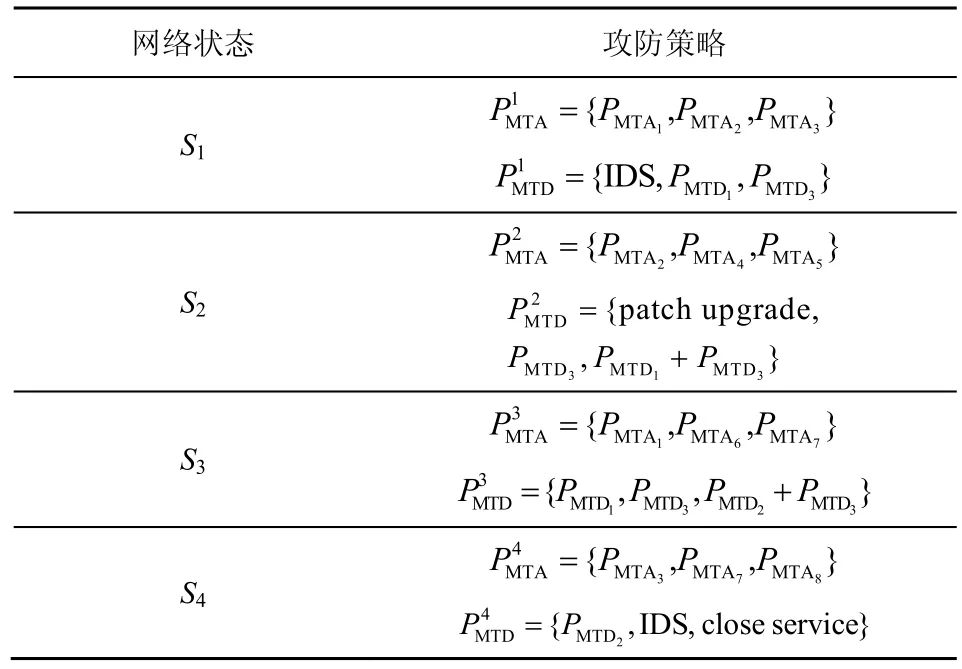
表5 不同网络状态下的移动目标攻防策略
3)选取MTG-MTD 模型的最优策略
在选取最优策略之前,将最优策略选取问题等价转化为非线性规划问题。在此基础上,利用所提算法及交互式的线性和通用优化求解器(LINGO,linear interactive and general optimizer)求解最优策略。表8 给出了攻防双方及其相应收益的最优策略。

表6 网络系统状态转移概率

表7 移动目标攻防策略收益矩阵
约束条件为
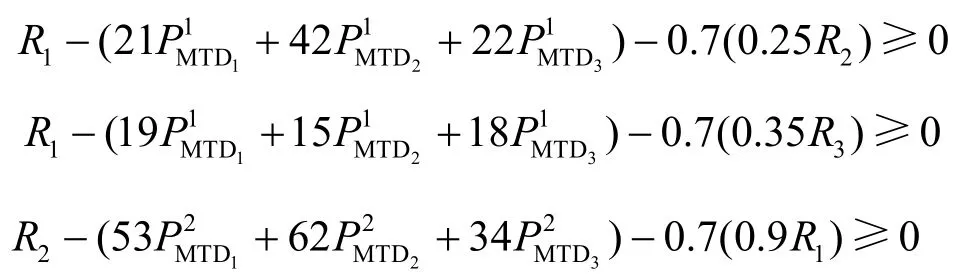
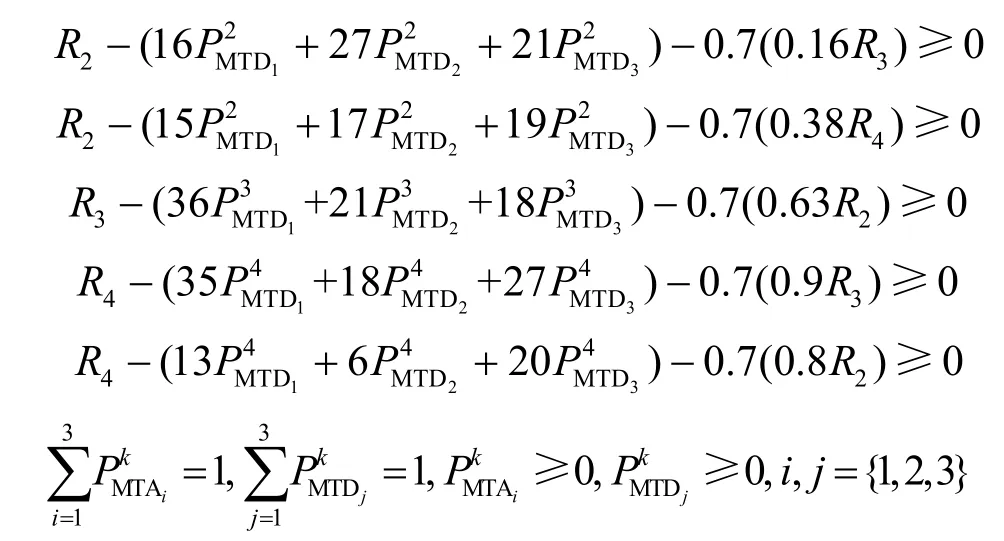
目标函数为
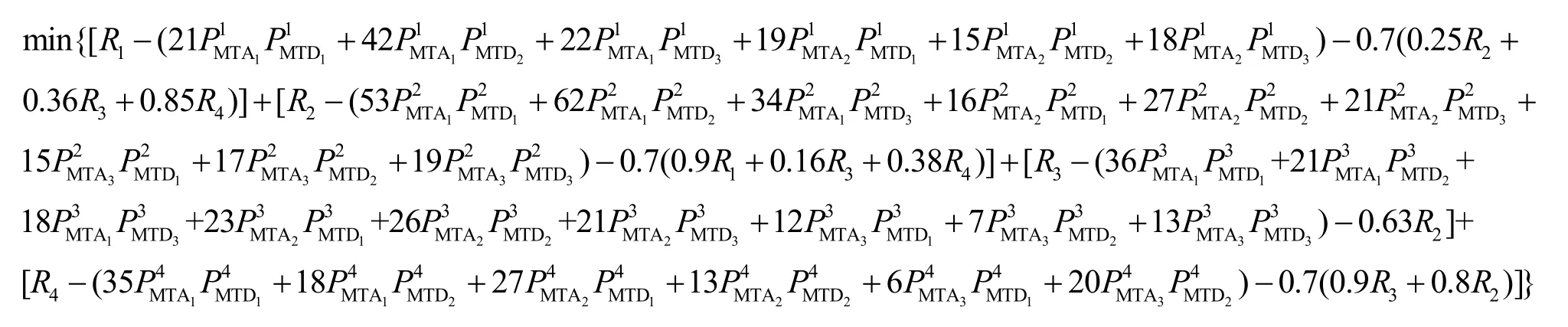

表8 移动目标攻防策略和收益
5.2 结果分析
通过对移动目标防御模型均衡和收益分析,可以得出以下移动目标攻防过程的一般规律。
1)由于防御实施效果的针对性,应该尽可能实施成本低且防御效果佳的MTD 策略,针对特定的移动目标攻击,应实施适当的移动目标防御。例如在状态S1,攻击者的主要攻击手段是利用自身的动态变换规避常规的入侵检测系统,因而IDS 对于上述攻击无效;相反地,实施移动目标防御可以有效抵御此类攻击。
2)由于攻击的持续性,要尽可能避免攻击者与目标系统建立通信控制连接,否则很难采取有效防御策略。例如在状态S4,当攻击者已经入侵目标系统,并且进行后续攻击开发时,IDS 等传统防御手段对于攻击防御无效,并且移动目标防御的效果也不理想,此时最佳策略为关闭服务。
由于单阶段博弈过程由时间博弈所刻画,使博弈场景更贴近有实际网络攻防过程,相较于矩阵博弈,本文所采用的时间博弈可以更好地刻画博弈动态性,同时利用Markov 决策过程刻画多阶段性,从而帮助网络安全管理人员更好地决策。
6 结束语
本文基于多阶段Markov 时间博弈模型研究了移动目标攻防策略选取问题,主要工作如下。在分析移动目标攻防过程的基础上,构建了Markov 时间博弈模型,具备分析多阶段-多状态攻防行为的能力;基于折扣总收益设计了移动目标防御博弈的目标准则函数,实现了对多阶段攻防博弈的量化分析;提出了基于非线性规划的多阶段博弈均衡计算方法,设计了多阶段最优防御策略选取算法。研究成果对于在多阶段移动目标攻防中实施网络防御决策具有指导意义,能够为开展网络空间攻防对抗研究提供理论模型支持。
当前网络攻防策略集合均与时间无关,需要将时间作为策略因素考虑,因此对于攻防策略行动问题时机的研究是下一步开展的主要研究方向。
