基于移动端的场景分类模型
2020-02-08黄凯凯余万里陆黎明
黄凯凯,余万里,陆黎明
(上海师范大学 信息与机电工程学院,上海 201400)
0 引 言
场景识别是计算机视觉中一个研究热点,有很多研究者提出各种识别模型。利用手工标注特征进行场景识别的方法:文献[1]提出方向金字塔匹配(OPM)算法在Indoor67和SUN397数据集上分别取得了63.48%和45.91%的分类准确率;文献[2]提出局部颜色对比描述符(LCCD)算法在Indoor67和SUN397数据集上分别取得了65.96%和49.68%的分类准确率。利用深度学习进行场景分类的识别的方法:文献[3]利用多神经网络结合多分辨率和类间相似性知识这种多模型集成的方法在Indoor67数据集上取得了84.80%的分类准确率;文献[4]利用FV(fisher vector)编码将神经网络的中层输出与全连接输出结合的方法在Indoor67和SUN397数据集上分别取得了83.75%和67.56%的分类准确率。
在移动端且有高实时性要求的系统中,大型深度学习模型[5-7]无法使用。虽然有适合运行于移动端的网络[8-11],但由于识别准确率太低,不能直接应用于场景识别任务。基于此,本文提出一种能够运行于移动设备上的端到端的深度学习模型进行场景识别。
1 相关工作
模型压缩。模型压缩与轻量模型是两个不同的概念,虽然两者的目标都是想要减少网络参数和计算量,但两者的实现方法不同。模型压缩有剪枝[12]、知识迁移[13-15]等方法。现今网络修剪方法主要有,通过评估神经元的重要性进行修剪[12]、保持神经元多样性,合并相似结构。知识迁移[13-15]主要是通过一个或多个预训练好的大模型,提取大模型中的某样先验知识,将这个大模型的先验知识加入到需要训练的小模型中,使小模型能够在大模型的监督下训练,从而使小模型能加速收敛,提高模型准确率。知识迁移主要差别在于知识,文献[13]提出将预训练好的模型的输出作为物体的“软标签”,与手工标注的one hot标签一起监督网络学习,而这里的知识就是“软标签”。文献[14]提出在特征图中,不同神经元所关注的图像区域是不同的,所以将预训练大模型某层的特征图与小模型进行特征匹配,使小模型的特征与预训练大模型特征更加接近,而这里的知识就是预训练大模型的卷积特征图。
卷积网络不同层特征。深度学习模型的一大优势就是可以自动提取图像特征,而且卷积网络不同层所提取的特征性质也有很大区别。卷积网络中层含有图像局部和细节信息,而卷积网络顶层含有图像全局信息。但提取的特征直观上很难让人理解,所以想要探究深度学习模型不同层的特征图有什么特点,直接查看各层特征图的参数是无法得出有效结论的。所以本文通过类激活图[16](CAM)的方法,直接把卷积不同层提取的特征可视化,在原图上显示特征重点关注的部分。图1是我们在MIT Indoor67数据集上做的CAM实验,从上下对应的对比图可以证实,中层特征包含图像局部信息,更关注图像背景、物体细节,而顶层特征包含图像全局信息,关注点集中于图中某样区分性很强的物体。所以通过卷积网络多层特征融合,能够更加全面的表示图片,能够更好完成场景识别任务。

图1 卷积网络中层(上图)与顶层(下图)特征激活图
FLOPs(floating point operations)浮点运算数,用来衡量算法、模型的复杂度。在卷积神经网络中,卷积的方式各有不同,对应的计算复杂度也有很大差异。普通卷积核(如ResNet)浮点运算次数的计算公式[10]如下
FLOPs=HWK2CinCout
普通分组卷积核(如ResNeXt)浮点运算次数的计算公式[10]如下
其中,H,W,Cin分别为输入特征图的高,宽和通道数,K为卷积核的宽(假设是一个对称的卷积核),Cout是输出特征图的通道数,G是分组卷积的分组数。
2 场景识别模型
根据上述分析,场景识别在图像信息表示上有其特殊性,所以原有的ShuffleNet[10]网络无法满足该任务。根据场景识别的特性,对ShuffleNet[10]1x(g=8)这个版本的网络结构做出改动(如图2所示),使其不仅能够进行多特征融合,还可以在同一个网络中使用多分辨率输入进行训练,而且网络依然保持端到端,保证了网络在移动设备上高速运行的可能。
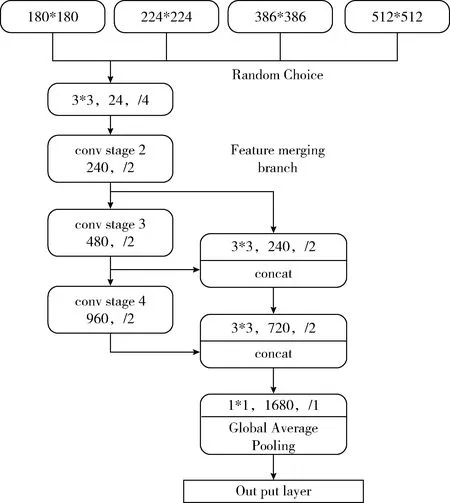
图2 基于移动端的场景识别网络结构
2.1 网络结构
ShuffleNet主要的卷积结构分别在3个Stage中。我们将Stage2、Stage3和Stage4输出的特征图进行融合,从而使其符合场景识别对图像的表示。通过对Stage的Output Size分析,每个Stage内部卷积的H(高)、W(宽)都是不变的,而在每个Stage与Stage之间也没有通过Pooling下采样,而是通过将卷积的Stride设为2来减小卷积尺寸。而进一步分析ShuffleNet的小结构单元,与ResNet的结构单元极其相似,也使用了一个跨层连接,而在跨层连接时,使用Avarage Pooling,并将Stride设为2来使跨层连接的卷积与主网络卷积尺寸相同,然后进行合并,而在ResNet中,是进行相加。借鉴ShuffleNet小结构单元,将Stage2跨层连接,首先与Stage3的输出进行合并,但由于Stage2与Stage3输出的卷积尺寸不同,通过在Stage2后加入一个卷积层(Conv1)来调节Stage2的卷积尺寸,使其与Stage3卷积尺寸一致,从而使Stage2与Stage3的输出能够合并。Conv1只改变卷积高与宽,不改变深度,具体卷积参数设为Padding=1,kernel_size=3,Stride=2,然后用同样的方式将Stage4的特征输出与Stage2、Stage3合并后的特征再次进行合并,这样就完成了卷积层多层特征融合。
2.2 同一网络多分辨率输入
同一张图片,在不同分辨率下所保持的信息量是不同的。低分辨率下,图片会损失很多细节信息,而在高分辨率下图片的信息更加丰富。虽然同样使用了多分辨率的策略去训练网络,但实现方法是完全不同的。Wang等[7]把不同分辨率使用不同的网络训练,通过多网络的方式将不同分辨率下获得分类结果集成。而我们是在同一个网络中使用多分辨率进行训练,通过随机输入3种不同分辨率{180*180*3,224*224*3,386*386*3,512*512*3}对网络进行训练。与多网络集成不同,这将不同信息的图片集成在同一个网络中,在分类层之前使用global average pooling,使最后网络的特征输出只与最后特征图的深度有关和特征图的H(高)、W(宽)无关。这不仅保证了端到端学习,而且有效防止过拟合。
2.3 训 练
首先在原图的基础上随机裁剪,随机裁剪大小的比例是原图的0.08~1.0,然后将裁剪之后的图随机resize到{180*180*3,224*224*3,386*386*3,512*512*3},将随机resize之后的图再经过随机水平翻转之后输入到网络中进行训练。我们使用随机梯度下降算法进行优化,在单张1080ti显卡上训练,将batch size设为32,momentum设为0.9,weight decay 设为5e-4,learning rate根据准确率调整,当准确率在10轮之后依然不提高,就将learning rate 乘以0.2,learning rate最小值设为e-8。
3 知识迁移
深度学习模型输出层经过softmax激活之后,各神经元的输出就代表概率分布。在一个有N个神经元的输出层中,用P(y=i|x),i∈[0,N-1] 代表第i个类的概率输出,若P(y=j|x)=max(p(y=i|x),i∈[0,N-1]) 代表在0~N-1个类中第j个类输出值最大,那就代表此次分类的预测结果为第j个类。但并不能完全保证此次预测结果就一定是对的,可能目标类并不是第j个类,可能是top-K(输出值经过排序后前K个大的值所对应的类)个类中的其中一个类。对于当前输入,将输出层的top-K个类称为相似类,这K个类相对于剩下的N-K个类来说,目标类更可能在K个类中,而在N-K个类中的可能性应该是微乎其微的,因为当P(y=i|x),i∈[0,N-1] 值小到一定程度时,说明目标类不可能是其对应的i类。
针对上文讨论的场景识别普遍存在的类间相似性问题,本文提出一种相似类知识迁移的模型压缩方法对目标模型进行监督训练。
首先选用一个大型深度学习模型(下文统称为teacher模型)提取相似类知识,然后将teacher模型在当前运行的数据集上进行fine-tune,最后在训练目标模型(下文统称为student模型)时,将teacher模型的输出经过阀值筛选出相似类之后,作为先验知识来监督student模型训练。student模型损失函数如下
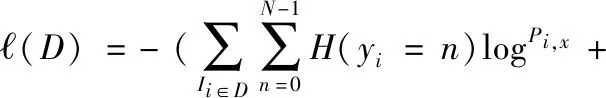
其中,D是训练数据集,Ii是第i张图片,N是模型输出向量的维度,yi是图片Ii的真实one hot标签向量,H(yi=n) 是向量yi索引位置为n上的值,Pi,x是图片Ii在student模型中没有经过softmax激活的预测输出,λ是真实标签造成的损失与相似类知识标签造成的损失的调节参数,fi,n是图片Ii在teacher模型中的输出值经过相似类筛选之后的值。fi,n具体计算过程如下
其中,F(xi,n) 是图片Ii在teacher模型中筛选后且没有经过softmax激活第n个节点的预测输出值,具体筛选方法如下

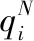
本文实验中λ=1,K=10。 网络加入这种相似性先验知识之后可以有效加速收敛速度与分类准确率,从表1中的A2可以看到加入相似性知识后网络分类准确率明显提高。因为CNN学习到的特征更加多元化,不至于像使用one hot标签一样,分类的概率分布会不断趋向于单一类,所以CNN学习到的特征也会变得单一,无法学到相似类的特征。文献[3]通过使用混淆矩阵的方式对相似类进行合并,从而解决场景识别中类间相似性问题,但求混淆矩阵的算法很复杂,而且此时深度学习模型也无法实现端到端。文献[13]也使用网络输出作为先验知识加入到student模型中,但它并没有使用相似类筛选。文献[13]提出的方法其实是本文提出的相似类知识的一个特例,即K为数据集分类数。在MIT Indoor67上对这两种方法做了对比,即在上文提出的网络结构相同的基础上,分别设置K=10与K=67。K=10时分类准确率为75.9%,K=67时分类准确率为73.1%。在本文提出的网络结构的基础上,加入本文相似类先验知识要比加入文献[13]中所提出的知识,在场景识别上能获得更高的分类准确率。

表1 ShuffleNet与本文提出方法的比较
4 实 验
我们主要是在两个常用的场景识别数据集MIT Indoor67和SUN397上进行实验,从而评估我们为场景识别改进的ShuffleNet网络、同一网络的多分辨率输入和相似类知识迁移,以及网络在测试集上的结果与其它实现方法在相同测试集上的结果进行对比。
MIT Indoor67数据集一共有15 620张图片,每一个类至少有100张图片,一共有67个不同的室内场景。我们的实验使用原论文的评估协议,即每一个类80张图作为训练集,每一个类20张图作为测试集。SUN397一共有108 754张图片,397个不同的场景,每一个类至少有100张图,我们同样根据原论文的评估协议,即每类50张图作为训练集和50张图作为测试集。最终在10个这种数据集下对测试集进行评估,取其平均。
在MIT Indoor67上分别评估:为场景识别问题改进的网络,单网络多分辨率输入,相似类知识迁移。这3种情况与原始的ShuffleNet网络分别进行对比,其结果在表1中。在评估为场景识别改进的移动网络中,采用单分辨率输入方式,先从图片中随机剪切一个区域,然后resize到224*224,不加入迁移知识。在评估单网络多分辨率输入中,使用原始ShuffleNet网络,在图像中随机剪切一个区域之后从{180,224,386,512}随机选择尺寸进行resize,不加入迁移知识。在评估相似类知识迁移中,预训练网络使用DenseNet162,移动网络使用原始ShuffleNet,采用单分辨率输入方式,先从图片中随机剪切一个区域,然后resize到224*224,预训练网络的输出中保留相似类个数的阈值threshold=10。以上4种方法中,在测试数据集上都采用将原图resize到338 * 338作为输入,然后直接预测结果。
在MIT Indoor67和SUN397上将为场景识别改进的ShuffleNet网络、同一网络的多分辨率输入和相似类知识迁移这3种方法同时使用,并且为移动网络提供相似类知识迁移的预训练网络都使用DensNet162。MIT indoor67和SUN397都是使用原始论文中的评估协议选择训练数据集和测试数据集。每轮数据输入从{180,224,386,512}中随机选择尺寸进行resize,测试数据只做resized到338*338的简单处理。之所以测试数据不进行multi-crop处理,是因为在实际应用中,multi-crop之后再取预测结果的平均值会大幅降低预测速度,不符合移动设备应用的实际需求。
虽然场景识别研究方法[3-5,21,22]很多,但端到端的方法并不多,而且有些方法[3,21,22]使用的是多模型集成的方法,因此我们的方法在与其它方法对比时,会与对比网络在同一标准下进行对比。表2是与早期手工提取特征进行对比。表3是与各端到端的卷积网络进行对比,同时利用FLOPs计算公式[10]分别计算了各网络在输入图片长宽都为224时的FLOPs。表4是与多模型集成进行对比,我们使用多模型集成时,通过训练时调节相似类个数K,获得不同模型。从以上的对比表中可以看出以下几点:①即使是使用轻量卷积网络,其准确率要远高于传统手工标注场景识别特征的方法;②多模型集成是提高分类准确率非常简单却有效的方法,我们模型通过集成之后,与各个大型集成模型准确率相差很小;③使用与目标问题相似的预训练模型进行fine-tune,准确率可以获得大幅提高。例如表3中文献[4,20]方法都是在Place205或Place365数据集上预训练好的网络(VGGNet-16、GoogLeNet)再分别在数据集MIT Indoor67和SUN397上进行fine-tune,相对于使用在ImageNet上预训练的VGGNet-16再在MIT Indoor67和SUN397进行fine-tune,前者[20]准确率要比后者[5]高很多。本文使用的是在ImageNet上预训练的网络,但相比于文献[5]方法,不仅FLOPs只有它的1%,而且分类准确率比其高8.2%,显示了本文方法的有效性。
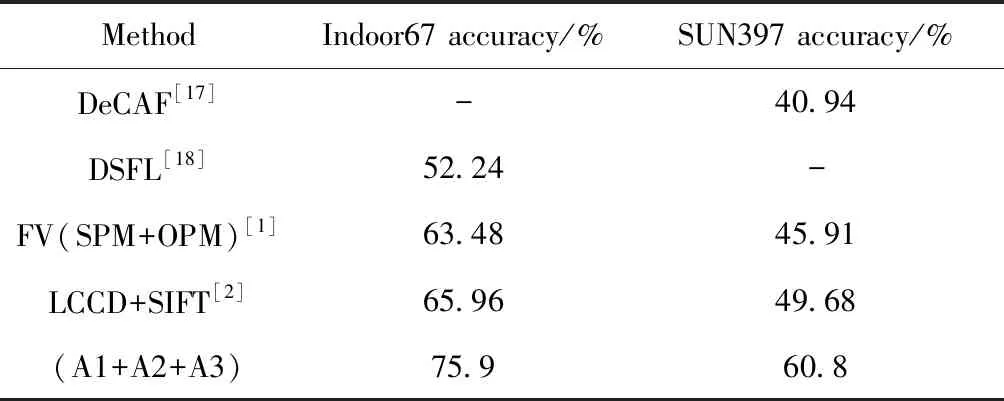
表2 手工标注特征的方法与本文提出方法的比较
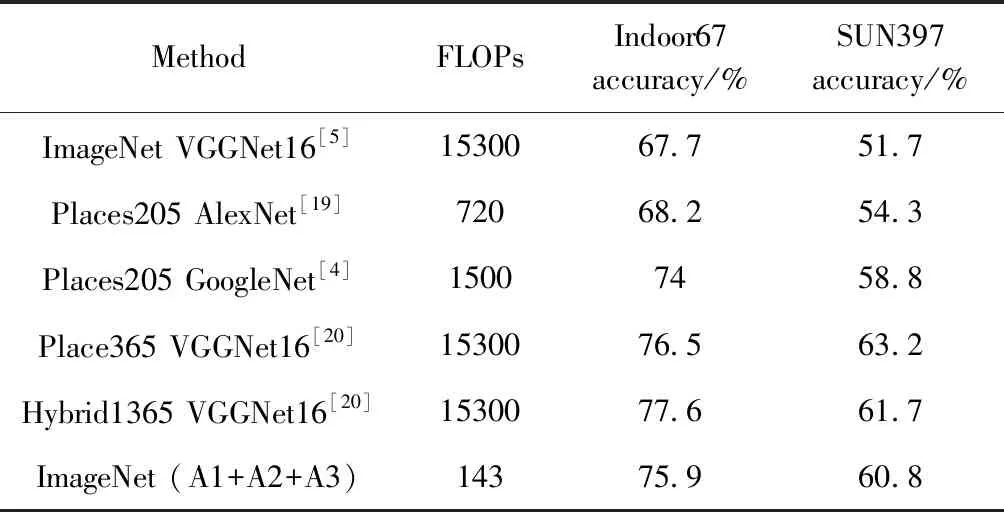
表3 端到端的场景分类方法与本文提出方法的比较

表4 多模型集成方法与本文提出方法的比较
5 结束语
本文研究了在移动设备上能够端到端高效运行的场景识别模型,困难主要来自两方面:一方面是需要能够在移动神经网络中能够有一种端到端高效运行且场景识别分类准确率高的网络。二是来自场景识别问题本身,即场景识别需要更加丰富的特征表示和场景识别存在类间相似性。针对这两方面的问题,本文分别提出了相应的解决方法,但由于硬件条件的限制,主要在MIT Indoor67和SUN397数据集上进行了实验。在单模型的对比中,虽然我们网络的FLOPs只有其它模型的1%,但分类准确率依然获得了明显优势。在多模型集成的对比中,通过调节相似类个数K来进行多模型集成的效果并不显著,分类准确率提高非常有限,仍然需要进一步研究。
