零售商数据资产外部价值分析
2020-02-06李卫华
李卫华


[摘 要] 零售商每天都在产生大量的POS小票数据和会员数据,这些数据不仅具有应用价值,也具有经济价值,具有外部变现的可能性,它与尼尔森、凯度等同类研究数据相比有深度和细颗粒度的优势,对于供应商而言,零售商数据有助于弥补供应商数据的结构缺陷,有助于更全面的用户画像,有助于小众商品市场分析、新品推广以及自有会员的管理和评估。
[关键词] 零售商;数据资产;经济价值;外部变现
[中图分类号] F340[文献标识码] A[文章编号] 1009-6043(2020)01-0112-05
Abstract: Retailers have a lot of POS receipts and member data every day. These data not only have application value, but also have economic value, and have the possibility of external cash. Compared with similar data such as nelson and kay degree, these date have the advantage of deep and fine granularity. For supplier, retailer data can help make up for the supplier data structure defects, help users' portrait of a more comprehensive, help small commodity market analysis, management and assessment of the new product promotion and its own members.
Key words: retailers, data assets, economic value, external cash
一、研究背景
(一)理論背景
近年来,在大数据浪潮中,“数据即是资产”的观念已成为共识,社会对数据价值的重视程度与日俱增。什么样的数据能够成为资产,或者说什么样的数据有资格成为资产?首先需要了解什么是财务意义上资产。资产是指由企业过去经营交易或各事项形成的,由企业拥有或控制的,预期会给企业带来经济利益的资源。
类比资产的定义,零售商数据资产是零售商拥有或控制,能带来未来经济利益的数据资源。因此,并不是所有的数据都是资产,只有可控制、可计量、可变现的数据才可能成为资产。其中,实现数据资产的可变现属性,体现数据价值的过程,即称为“数据资产化”。
数据具有“应用+经济”的双重价值。数据助力企业自身的运营,用于服务企业经营决策、业务流程,从而提升企业业绩,这是一种挖掘数据价值的方式,称之为应用价值。从经济价值的眼光来看,它应该可以通过外部变现来获取价值。
(二)行业背景
零售商作为供应商商品交易的平台,每天都会产生大量的小票数据和会员数据,这些数据不仅具有应用价值,同时也可以考虑到它的经济价值,以便将这些数据变成数据产品,提供给需要的企业,主要是品牌供应商,实现数字资产的外部变现。
在比较初级的零供合作模式下,零售商关注的是整个品类的生意,而供应商关注的是自己品牌的表现。一个品牌的成长如果只是蚕食了产品生意而没有帮助整体品类的增长,在零售商看来是失败的,对该品牌的资源投入(海报、陈列等)是零收益甚至负收益的。因此,零售商在向供应商分享数据时尤为谨慎。
随着品类管理在零售行业推广应用的出现,零售商也越来越开放,他们愿意让更多的供应商参与到生意中来,因为在供应商那里有着更多数据分析的资源和人才,也有着零售商之外的整体市场信息,这能帮助他们挖掘更多的数据价值。所以很多零售商在重点品类中选择领先的供应商作为他们的品类冠军,一起来建设品类,管理品类生意。
新零售时代,零售行业的数字化转型越来越普及,腾讯、阿里等零售赋能平台的出现,以及市场上出现了一些专注于零售大数据挖掘的公司。这些公司的数量不多,他们的服务需要直接调用零售商底层最核心的数据——小票数据和会员数据,与零售商是战略性合作关系,而不是简单的数据分析服务商。这类第三方企业以更公平的视角,更专业的能力为零售商和供应商之间搭建起一个平台,在平台上,大家用同一种顾客语言对话,实现品牌和品类双赢,零售商数据资产向供应商外部变现的通道逐渐通畅。
二、零售商数据与其他同类研究数据的区别
当我们介绍零售大数据时,供应商的顾客洞察、市场营销或品牌团队经常会问到的一个问题是:“我有尼尔森(Nielsen)的零售研究数据,我有凯度(Kantar)的消费者样本数据来报告我整体市场的销售和份额。为什么还需要看某一个或某几个零售商的数据呢?”零售商数据和尼尔森或凯度数据是两个不同体系的数据,研究方法和用途也不尽相同。简单而言,尼尔森和凯度报告的是整体市场的表现,追求的是数据的覆盖广度和整体市场代表性。零售商数据报告的是顾客洞察,追求的是深度和细颗粒度。
从方法角度出发,尼尔森的零售研究和凯度消费者样本都不是大数据,两者都是基于采样的方法。尼尔森基于店的采样,它根据店铺业态、省市区域和营业额大小将全国几百万家店铺分成各种小类,并在每个小类里抽取部分店作为样本店。最终样本店数量在1~2万家左右。之后定期(一般一周或一月)在这些店铺收集销售数据,并按比例放大得到全国或某个区域的市场数据。而凯度是基于消费者的采样,它在全国各区域(一、二线城市为主)招募4万个家庭,让样本家庭自主收集并定期报告购物信息,之后通过按比例放大的方式得到各类产品的销售及顾客渗透率等市场信息。零售商数据是非采样数据,它来自所有在零售商内购物的小票和会员信息,每一天、每一个小时、每一分钟、甚至每一秒的数据都被详细记录,是真正的全量数据。
从数据源类型看,尼尔森只在店铺收集每一个产品一段时间内的销售,并不细化到顾客和购物篮。凯度数据只收集样本消费者购买的产品信息,数据质量完全依赖样本消费者的质量,但一些冲动性消费,如口渴街边买罐可乐很可能无法被顾客完整地记录。而零售商数据是除了细到每位顾客每张小票的真实行为外,还能细致到每一笔交易的支付方式、促销参与、店内堆头、库存信息等等,丰富度非传统市场研究公司可比。
从数据可读性看,采样方式的数据会受到诸多限制。最主要的就是制约于按比例放大过程中的统计学误差。一般来说,当一个产品的铺货率低于20%(有售卖该产品的店铺总销售占全部市场销售的比例不足20%),或一个产品的顾客渗透率低于20%(购买过该产品的消费者数占所有消费者数的比例不足20%),尼尔森的销售数据或凯度的消费者数据会承受很大的统计学误差,也就是说报告中的数据的随机性会比较大,销售趋势的波动可能会很剧烈。数据的稳定性会是一个很大的挑战。而零售商数据由于非采样,所有数据都是可靠可读的。特别对于一些低渗透率或低铺货率的产品,如新品上市、小众产品、单品级别的分析,零售商数据就具有了得天独厚的优势。
三、零售商数据对供应商的价值分析
(一)零售商数据有助于弥补供应商数据的构成缺陷
1.零售商數据有助于供应商从全品类的角度考虑问题
同零售商一样,各品牌供应商也需要管理它的顾客,将顾客分类进行精准营销。第一步最基础的就是建立起CRM会员库,甄别顾客,知道他/她是谁,他/她与品牌的交互关系。供应商能够招募会员并能同时获取购买行为的渠道主要有几个:自营店铺、自营线上商城、微商城等,对于大多数快消品品牌来说,这些渠道的销售贡献很有限。即使算上天猫、京东,销售占比大多也不足20%。况且这些渠道的行为数据仅限于自己品牌的销售,无法知道本品牌会员在整个品类,甚至其他品类的表现。
零售商数据很好地弥补了这些缺陷,零售商数据是第一手顾客数据,它的价值在于从顾客角度全面审视该品类发展和品牌生意,它能告诉你,谁购买了你的品牌,谁对品牌忠诚,谁在品牌间不断犹豫,你的忠诚顾客都有哪些特点,你的非忠诚顾客喜欢什么等等。所以说,它的顾客(或部分顾客)对供应商来说就是一个天然的CRM会员库。尤其是供应商得到的洞察不仅可用于该零售商,根据供应商对市场的知识,一些洞察完全可以映射到整个市场,并且可以回头在该零售商店里做尝试和验证。
举例而言:A顾客购买我的品牌10次,B顾客购买我的品牌5次。A顾客就比B顾客对我的品牌更忠诚么?不一定。如果A顾客还同时购买其他品牌10次,而B顾客不再购买其他品牌,那么尽管A顾客的价值比B顾客高,但从忠诚度角度看,B顾客更忠诚。对于A顾客,品牌需要加强情感粘性,可以通过促销等手段从其他品牌那里赢回另外10次购买中的几次。而对于B顾客,品牌要做的是了解如何提升购买频次(例如品类教育)或鼓励交叉购买等。所以供应商就可以利用零售商数据搭建一个简单实用的品牌顾客细分模型(见图1)。
根据顾客对品类的购买(频次、花费)和品类购买中品牌的份额将品牌顾客分为几大群体,供应商可以针对不同的顾客,采用“争取、维护、教育、观察”不同的营销策略。
2.利用零售商数据可以进行跨品类的全面顾客画像
零售商的顾客不仅购买某一品牌、某一品类的产品。供应商在进行顾客画像时,利用零售商数据可以更全面地描述顾客,甚至可以扩展到全品类。例如,福佳啤酒是一款进口高端白啤,品牌商想知道都是什么样的顾客在购买这个产品。传统的方式可以通过消费者调研,询问曾经购买过(宣称购买过)该品牌啤酒的顾客的年龄性别和一些生活方式和生活态度。年龄性别是常规的画像维度,但对于生活方式和态度就需要事先有假设,问卷中不能完全开放地让被访者回答,不然无法编码和分析。而有了零售商数据,它可以先不做任何假设,观察购买过福佳啤酒的顾客在其他产品的购买商哪些是远高于平均水平的(请注意,这些行为都是实际发生的,而不是顾客宣称的)。
案例中,我们看到福佳啤酒顾客会更多购买可口可乐、乐事薯片。这些都是更多是年轻顾客的选择;同时她们又更多购买卡士酸奶、维他柠檬水、益力多乳酸菌饮料,这是女性顾客或对健康关注的顾客选择;另外,卡士酸奶、洁柔纸巾、乐事薯片都是各自品类中的国际或高端品牌。由此,我们能分析出,福佳啤酒的购买者多为年轻白领女性。不仅如此,福佳啤酒还能直接与这些相关品牌进行联合促销等活动,或目标购买这些产品的顾客(不拒绝啤酒/购买过酒类)推荐福佳啤酒来进行招新。
同样的思路,某全国连锁的著名美容机构L进入M市开设首店。为了尽快将市场开拓起来,L公司的企划经理请求与C购物中心结成联盟单位。L与C在M市举办了一场由女性VIP参加的歌舞晚会,其费用由L全部承担,仅需要C的客服按照L的要求筛选出符合下列条件的女性会员:(1)25~45岁女性;(2)收入稳定;(3)在化妆品方面消费周期规律。C在自己的资料库里筛出1000人左右参加了这个晚会。L则在这个会议上吸纳了足以支撑其经营的会员人数。
(二)利用零售商数据建立品牌会员库可操作性强,成本更低
1.可操作性强。许多品牌供应商建立自己CRM系统的可行性低。目前建立自己品牌CRM系统比较好的例如欧莱雅等,他们相对高单价,值得去投资招募品牌会员,有商场/商超专柜这样的接触渠道去招募和维护会员。而对于另一些低单价高频次产品的品牌,如可口可乐,首先他们接触会员的渠道就有限;其次这类的品牌忠诚度变化很大(大量品牌间摇摆者,他们可能接连几天买可乐,对可口很忠诚,但接下来几天可能就因为某个广告或促销,接连几天买百事)。特地建立品牌CRM去长期管理每个会员的投资回报也不高。即使他们能利用社交手段,例如微信公众号网罗一批粉丝,这些人是否真的是品牌忠诚用户(是否购买),并且能否能有效通过内容转化成购买也是一道未解难题。因此,拥有购买行为数据的零售商就成为这些品牌的天然CRM系统。他们可以很灵活地甄别情感忠诚(长期频繁购买)和动态行为忠诚(短期频繁购买)顾客,予以不同的营销影响。
2.成本更低。有时候品牌商不需要投资建立自己的CRM系统,完全可以花少量的费用与零售商合作,利用零售商数据按需抓取人群包,进行精准化营销。例如,某珠宝品牌商T公司进了一批高级大克拉钻石,由于货物的价值太高,不方便在卖场的柜台销售。但是,T公司由想在较短的时间內将它们出手。通过协商,C购物中心为他们提供了联合营销的便利。C购物中心的客服经理首先在顾客中选取购买力TOP500会员进行分析,在购买倾向上进行分类,找出明显有珠宝喜好的150人。由会员中心发出邀请,参与T公司举办了一个盛大的珠宝show及现场拍卖会。由于,会员锁定的准确,在拍卖行当场销售了三颗大克拉珍宝级钻石。
(三)零售商数据有助于小众商品/新品的市场分析
1.小众商品市场分析
在对比零售商数据和市场研究公司数据(如尼尔森,凯度)时,我们提到,零售商数据在跟踪新品和小众商品时有着得天独厚的优势。他们的共同点就是购买人数少,利用采样方法得到的数据统计学误差大,很难报告可靠的趋势。
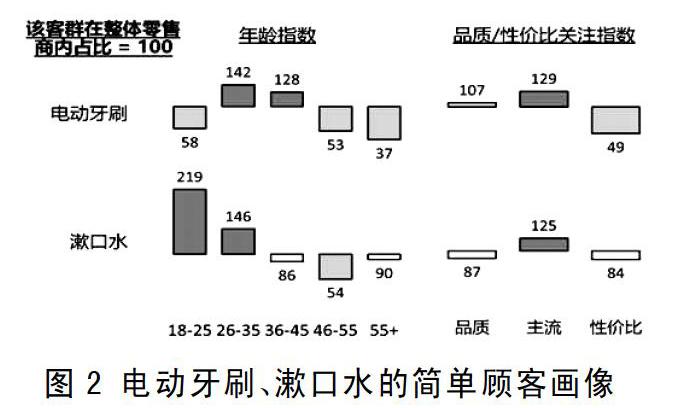
举个例子,电动牙刷是一个小众品类,顾客年渗透率(100个顾客中有几个在过去1年购买过该类产品)只有1%~2%。当凯度样本有4万个时,理论上能找到400~800个人购买过电动牙刷。如果再下钻到电动牙刷品牌,再到单品,每个产品的购买顾客数只有个位数,甚至找不到了。而我们看零售商数据时,仅某个区域的一个中型零售商内就能找到8000多顾客在过去一年购买过电动牙刷,当拥有多个零售商数据时,这个样本群就很客观了。即使做到单品层级也有足够的购买顾客。这时候,我们看各种产品的顾客画像时就能获得更可靠的数据。
我们就进一步看电动牙刷,同时比较另一个相关的小众品类漱口水。品牌商很关心的一个问题是,谁是我这个品类的主要客群?在凯度的消费者样本框无法提供足够样本时,零售商数据的威力就体现出来了。我们仅用某一零售商数据就可以容易观察到:
漱口水的顾客群体明显年轻于电动牙刷,而电动牙刷偏向关注生活品质的顾客,对于性价比关注的顾客在购买电动牙刷时会很谨慎,但漱口水品类面对的客群面就广很多。需要指出的是,由于我们这里看的是某一个或几个零售商的数据,这里存在着不同零售商本身面对的客群不同这一客观事实,因此在分析客群时,我们会以在该零售商整体顾客的占比作为100,计算指数。譬如,在某一零售商购买漱口水的顾客中,18~25岁的占10%;而在该零售商中,18~25岁的顾客占所有会员的5%,那么漱口水的18~25岁年龄指数就是200(=10%/5%*100)。
在这个分析中,大家也注意到一个叫品质/性价比关注指数,这也是完全根据顾客的历史购买行为来定义的。一般情况下,品牌商会通过家庭收入来做为判断顾客购买力的指标,家庭收入的数据手机通常是依赖问卷。作为家庭最敏感的信息之一,在很多情况下,关于收入的回答的可靠性是一个痛点。在我们的案例中,顾客不用回答任何问题。零售商里售卖上百个品类,每个品类内都有高端、中端、低端品项。我们观察每个顾客历史购买记录,在每类高中低端商品商的花费占比,来反映该顾客的购买偏好,高端产品占比高的可以假设是更关注生活品质的顾客,相反是关注性价比。如果更进一步,我们可以很容易甄别出对生活吃穿住行关注点不同的顾客群。
除此之外,基于购买行为的顾客标签可以非常丰富,仅举几例:是否有孩子,规律购买不同年龄的婴孩产品;是否关注健康,偏向购买健康品类或品类中健康商品(产品预设健康标签);是否需要照顾整个家庭,通常购买大包装的米面粮油产品;是否敢于尝试新品,新品购买的踊跃行为。这些丰富的标签都可以帮助品牌更生动地描述目标客群的画像,从而制订精准营销计划。
2.新品市场分析
创新是未来中国市场的主旋律,每年上市的新产品不计其数,品牌商也希望通过不断的上新来更好地满足现有顾客更细分的需求,以及满足更多顾客的需求来扩大销售潜力。一般情况下,品牌会预设目标顾客,新品的设计研发,以及市场营销支持都围绕目标顾客进行,但在上市之后,购买新品的顾客是否如品牌商预设期望一致呢?有时候,品牌会设定相关的几个目标顾客群,但究竟哪个目标群体在真实场景下更喜欢上市的新品呢?哈尔滨啤酒上市了一款白啤,这款白啤的生意究竟从何而来,应该目标怎样的顾客去营销呢?
我们观察一个指标:在哈尔滨白啤这个新品上市之前,顾客都在购买哪些啤酒。将新品顾客和整体顾客做一个对比,就能看到一些很有趣的现象。首先,购买哈尔滨白啤的顾客资源更多来本土品牌(相对中低端),这与哈尔滨啤酒本身的品牌定位是一致的。通常来说新品顾客通常更多先从自己母品牌来,这是母品牌晕轮效应。但这一白啤新品顾客明显更多从竞争对手青岛啤酒而来(之前更多的顾客购买的是青岛啤酒),它很好地吸引到了竞争对手的顾客,这对品牌来说是个很好的消息。再者,作为白啤产品,哈尔滨的这款新品并没有更多地吸引到之前购买白啤的顾客,而是聚集了很多以往购买名称中带有“小麦王”啤酒产品的顾客。这是为什么呢?我们对此做了一个的分析。首先,市场上白啤品牌大多为进口产品,价格较高,之前喝白啤的顾客偏向追求生活品质的高端人群。而本土品牌哈尔滨推出了白啤新品,从品牌定位和产品定价角度,它很难让那些原本的高端进口白啤顾客“降级”购买本土品牌(也与消费升级这一大趋势不符)。其次,白啤的特点就是加入更高比例的小麦,麦香柔和,更清爽,这和“小麦王”的卖点很相似,迎合了目前购买本土品牌小麦王啤酒的顾客需求(但还不具备进口白啤的购买力)。最后,青岛啤酒相比哈尔滨啤酒来说品牌形象更高端,哈尔滨白啤也被认为是在原本哈尔滨产品线上的创新升级。青岛啤酒本身没有白啤系列,喜欢青岛啤酒(这一“档次”),而又向往白啤的顾客,就不难理解很愿意尝试哈尔滨的白啤新品的行为了。基于这样的结果,品牌商很清楚知道应该针对怎样的顾客进行精准的沟通和营销。类似这样的分析是很容易运用零售商数据,在新品上市初期就可以完成的,而且不需要任何消费者调研的额外成本(产品渗透率低的时候,用户招募难度会很大,招募成本也会相应提高很多)。
(四)零售商数据可以赋能品牌供应商自有会员的管理和评估
很多品牌商已经建立了自有CRM系统,是不是零售商的会员数据就没有价值了呢?当然不是。通过零售商会员与品牌商会员系统打通,零售商的数据是能够丰富对品牌商自己管理会员的画像描述。同样两个都是品牌商会员系统中的忠诚消费者,可能通过零售商数据能够看到一个是关注健康的顧客,一个是关注享受的顾客(例如买食品看重口感多于营养),那么在推荐产品、使用话术、营销内容的出发点都可以不同而直击顾客内心。更直接的是,零售商的购物数据可以帮助品牌商来评估自有CRM的投入产出比。
有英国一家食品公司,主要的销售渠道是线下商超,几年前在网上建立了品牌互动网站,在网站上用户可以注册成为品牌会员,从而不断收到网站定期发送的产品目录,营养话题文章,线下活动介绍,网上抽奖活动等。在运营了几年之后,他们的CEO问了一个问题:“我们这几年投入建立和运维这样一个网站到底效果如何?”们这几拿出了一系列数字,包括注册会员数量、参与抽奖的活跃用户数量、会员的人口学统计画像(与品牌目标顾客对比)等来试图说明网站的意义。CEO追问道:“这些会员真的购买了我们的产品吗?因为我们的网站,他们真的有增加了对我们的产品购买么?如果从来都没有这个网站,他们不喜欢我们的产品么?”员工无法立刻回答这些问题。市场研究部门的总监提出可以做会员调研,通过问卷回答这些问题。但如果没有网站会员这些假设性的问题,顾客能给到准确的答案么?又如何很容易地量化这个效果呢?这时,零售商大数据的负责人提出了方案,何不将我们自己的会员与零售商会员匹配做分析呢?如果能知道我们网站注册的会员从每一个人的注册那天起,他们在线下的购买行为对比他们在注册会员之前的购买行为的变化情况不就能量化网站的效果了吗?就此,他们和英国最大的零售商之一合作,同时邀请零售商大数据公司为他们做了一个自有CRM效果评估项目。
第一步是匹配工作。首先,他们确定几个顾客key_id标签,即可以唯一或组合后唯一识别某一顾客的属性,例如:姓名、手机号码、电子邮箱。这些信息在注册品牌网站CRM和申请零售商会员时都会提供。接着,大数据公司利用这些key_id将品牌网站的会员和零售商会员卡顾客进行匹配。匹配过程中大数据公司收到的这些key_id都是品牌方和零售商双方加密过的(用同样的方式加密),匹配后哪些记录被匹配上也不回传给双方。这样确保大数据公司无法知道每条记录分别具体指向实际个体(姓名、手机号码、邮箱地址),而零售商也无法知道他的哪些顾客也在品牌网站上注册成会员,反之亦然,从而最大程度上保证了个人信息的安全和双方数据资产的不流失。最终,品牌会员中有近一半的人被成功匹配到零售商会员中。尽管没有百分百匹配,但也有几万之众,这样的样本数量足够得到可靠的结果。匹配的成功率取决于顾客个人信息的质量,双方生意覆盖的重合度,双方会员数量。但不管怎样,最终匹配上的人数最终决定了项目的可行性和结果可靠性。
第二步是在零售商会员体系中寻找对照组。这一步至关重要,对照组的质量直接影响评估结果的质量。我们当然可以直接观察匹配上的顾客在注册品牌会员前后的消费变化,但品牌表现也是在变化的,一些因素可能比是否注册品牌会员对销售的影响更大。如果品牌期间做了一次深度价格下调,整体销售会上涨,在这种情况下,仅仅看前后时间的购买变化可能始终看到是提升的,但这种提升并非由注册品牌会员这件事情驱动的,它的效果会被淹没在价格下调的影响中,依旧无法得到合理的评估结果。因此,需要寻找一个对照组,由他们的表现来模拟,如果那些品牌会员之前没有在网站上申请注册,之后的购买行为会如何。两者之间的差异更纯粹是由这个注册品牌会员的行为影响的。评判对照组好坏的最主要因素是鉴别观察期之前(这个案例中的观察期就是注册网站品牌会员之前)对照组和测试组(本案例中的品牌注册会员)的行为差异是否很小。由于每一个品牌会员网上注册的时间都不一样,因此需要针对每一个人分别寻找参照人进入对照组。
具体做法是:先拿出一个匹配上的顾客C1(该顾客既是品牌会员又是零售商会员),获取他/她注册品牌会员的具体日期。再从零售商会员但不是品牌商会员中,找1个对照人c1。该对找人c1人在一些维度上必须同时与顾客C1一致或高度相似,这些维度包括注册当日之前前一年和半年以及3个月内购买品牌金额、购买品牌次数、购买品类金额、购买品类次数、年龄、性别等。遍历每一个匹配上的顾客生成测试组{C1、C21配Cn},生成对照组{c1、c21对cn}。
第三步便是进行对比分析。这里用到一个叫虚拟日期的概念,即不管顾客是具体在哪一天注册成为品牌会员的,这天都是Day0。这样就把所有顾客的行为统一叠加在一个时间维度上。
从分析结果可以看到,测试组和对照组在注册日之前一年的销售曲线高度吻合,不可能也不需要完全一致,允许测试人和对找人购买节点有差异,例如一个1、3、5、7月每次花费10英镑的顾客的和一个2、4、6、8月每次花费10英镑的顾客行为可以认为是一样的,但总的趋势是一样的,即在某些大型活动(如大促销)期间销售变化趋势是相同的,在注册日之后可以明显看到两条曲线发生了分歧,测试组突然有了一个尖峰,这是因为顾客在注册成为品牌会员后会对品牌有更多关注,类似于“热恋期”,他们在零售商内也有了大幅购买增加。需要指出的是,这样的尖峰在零售商原本的数据里是很难看到的,原因有二:其一,我们是做了虚拟日期调整,将所有品牌注册会员的时间统一,注册后销售增长行为发生了叠加和放大,而在真实零售环境里,这些行为是打散在不同时间点上的;其二,品牌注册会员的数量(并且能匹配上的)占零售商会员数量的比例很小,这些顾客的行为对整体销售贡献有限。过了“热恋期”后,这些品牌会员的消费又回归平稳理性,但值得注意的是,他们销售的整体水平依然高于对照组,并且持续很长时间,这说明品牌的一系列CRM活动增强了品牌和顾客之间的情感绑定,获得了顾客的信任。这不仅带来了短期的销售突增,也得到了长期的效果。
第四步就是推算量化投资回报率(ROI)的分析。我们将分析中得到的两者销售之间的差值计算出来。但这个差值并非实际全部品牌网站CRM的效果。这里有两个因素要考虑:还有超过一半的品牌会员没有被匹配上零售商会员,他们也贡献了销售收益。因此仅用匹配会员计算的销售增长是低估效果的。所有会员也不是同一天注册的,他们在实际日历年上的贡献比例是不同的。因此,用虚拟日期计算的销售增长是高估效果的。
因此,在计算实际ROI时还需要对数据进行校正。最简单的方法就是将分析中计算得到的销售增量按匹配上的人数占所有品牌会员的比例扩大,并直接除以2,这是假设顾客注册会员的时间平均分布在一年的每一天,那么实际销售增长就是用虚拟日期算出的一半。这就是当时的校正做法。如果需要更为精准的话,可以对每一个品牌注册会员根据实际注册日期单独计算,对未匹配上零售商数据的品牌会员也一一在匹配上的会员中寻找最相似的进行模拟。计算出实际增益后,除以开发和维护品牌网站的费用,就得到了具体的ROI。最终的结果显示,该品牌会员系统还是获得了正向收益,通过更细致的分析和小规模试点,对活动机制进行了优化,例如定期沟通的周期从一周改成了一月,降低了成本而效果没有被显著影响,从而进一步提升了ROI。
[参考文献]
[1]刘国华,苏勇.新零售时代[M].北京:企业管理出版社,2018.
[2]张艺,龚鹏飞,雷婧.智慧新零售模式下电子商务发展探究[J].吉林广播电视大学学报,2019(7):53-54.
[责任编辑:潘洪志]
