基于深度学习集成的高速铁路信号设备故障诊断方法
2020-02-01李新琴张鹏翔史天运
李新琴,张鹏翔,史天运,李 平
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2.中国铁道科学研究院集团有限公司 标准计量研究所,北京 100081;3.中国铁道科学研究院集团有限公司,北京 100081)
高速铁路信号设备是保障列车高速运行的重要基础设施[1],信号设备的维修质量直接影响高速铁路行车安全与运输效率。信号设备故障依据现场维修人员的经验与知识进行诊断与处理,易造成维修判断失误与维修时间延误,严重时将导致设备故障性行车事故。高速铁路信号设备故障数据以文本的形式记载了故障发生时的故障现象,基于文本数据挖掘技术分析故障现象,并结合专家对该故障现象的诊断结果,研究信号设备故障诊断模型,辅助维修人员依据故障现象快速定位故障位置及原因,将对进一步提升高速铁路安全保障水平具有重要的意义。
高速铁路信号设备种类较多,设备运行的机理复杂性不同,造成各类信号设备产生的故障数目存在不均衡现象,这种现象会对故障诊断算法的学习过程造成重大干扰。因此,基于文本挖掘技术研究不平衡样本的信号设备故障诊断方法,需要解决两个问题,一是不平衡样本的处理,二是故障诊断与分类模型的构建。
解决样本不均衡主要包括两种方法:一种是针对样本数据,采用数据增强、欠采样或过采样、以及应用SMOTE(Synthetic Minority Oversampling Technique)[2],ADASYN(Adaptive Synthetic Sampling)[3]等数据生成方法对样本进行合成;另一种是针对分类学习算法进行不同类别的参数调整。样本合成算法能够根据总体样本的分布情况,适度合成少类别样本,并且能够保证样本数据不重复。目前采用数据合成方法解决样本不平衡的研究较多,文献[4]提出了采用SVM-SOMTE方法对信号设备故障少类别样本进行自动合成,从而解决信号设备故障样本不均衡问题。
基于文本数据的故障诊断模型,是通过学习故障文本数据特征实现故障文本分类,通过文本分类实现故障诊断,所以信号设备故障诊断模型包括文本特征提取和文本分类模型。文本特征提取方法主要包括词袋模型BOW(Bag of Word)[5]、TF-IDF(Term Frequency-Inverse Document Frequency)词频-逆向文件频率[6]以及基于深度学习的Word2Vec[7]等。TF-IDF根据文本中词汇出现的频率判断词语是否具有区分该文本的能力,信号设备各类别故障文本都具有各自的专业词汇,具有TF-IDF算法特征,文献[4]采用TF-IDF实现信号设备故障文本的特征提取。另外,主题模型TM(Topic Model)特征提取方法能够对样本中的语义结构进行聚类和统计,也是一种目前常用的特征提取方法,文献[8]采用主题模型对信号追踪表进行特征提取。文本分类模型可以分为单个分类模型以及集成分类模型,单个分类器模型包括决策树DT(Decision Tree)、支持向量机SVM(Support Vector Machine)以及基于深度学习的循环神经网络RNN(Recurrent Neural Network)[9]、卷积神经网络CNN(Convolutional Neural Network)[10-11]等,集成分类模型是一种思想策略,是将多个单分类模型的学习结果有效组合,从而提高整体分类性能,较为成熟的集成分类模型包括Bagging[12]和Boosting[13],也可应用集成学习思想,设计集成分类模型,文献[4]通过Voting的方式进行多分类器集成学习,实现信号设备故障分类。
本文深入研究高速铁路信号设备故障文本数据,结合专家经验,将信号道岔故障诊断结果归纳为两级故障诊断层级结构;针对故障类别不平衡性,采用ADASYN自适应综合过采样方法合成少类别样本;故障诊断模型采用TF-IDF进行文本特征提取,将能够有效学习文本序列的循环神经网络RNN的两大变体双向门控循环单元BiGRU(Bi-direction Gated Recurrent Unit)和双向长短时记忆BiLSTM(Bi-directional Long Short-Term Memory)神经网络进行集成,提高信号设备故障分类性能,最后应用高速铁路2009—2018年信号道岔设备故障数据进行试验,验证基于深度学习集成的故障诊断模型的有效性与正确性。
1 高速铁路信号设备故障数据分析
铁路电务信号设备中,道岔是实现股道转换的重要设备,由于其在车站铺设数量较多,设备构造复杂,并且设备的健康状态直接影响行车安全,是股道设备维护的重点。通过对高速铁路道岔故障数据总结,结合铁路信号专家的经验知识,将高速铁路信号道岔设备故障归结为两级,见图1,第一级为道岔故障的设备统称,较为笼统的定位故障设备,第二级将道岔设备统称下的设备细致划分,将故障发生的原因定位到具体的设备或其他因素,各一级故障类别下包含的二级类别个数在一级类别名称下括号中表示。根据专家编制的信号道岔设备故障层次等级,共包含7类一级故障以及62类二级故障。
1.1 信号道岔故障数据
高速铁路信号故障数据来源于铁路电务相关系统以及人员整理的故障信息,数据记载了故障发生的详细信息,并以Excel格式存储,其中故障现象列以文本的形式记载了现场设备发生故障时的现象,表1列举了信号道岔故障现象部分样例数据,一级故障与二级故障为专家根据故障现象的语句描述,并结合自身经验,以标签的形式给出的故障诊断结果。
1.2 数据的不平衡性
将高速铁路自开通以来共发生3 188起道岔设备故障数据作为样本数据,对各类别故障数据进行统计,见图2,一级类别下二级故障类别用该柱状图中的不同颜色区域表示。从图2中可以看出,一级转辙机故障与原因不明类别不平衡比例为161∶1,二级故障类别中,例如一级转辙机故障中包含接点组故障占比大于1/2,其余11类故障类别占比不足1/2,一级故障类别与二级故障类别都存在明显的类别样本数量不均衡现象,这种样本不均衡现象将会导致比例大的样本造成过拟合,即故障诊断模型的诊断结果偏向于样本数据较多的诊断结果,这在研究高可靠性的信号设备故障诊断方法中是不能忽视的缺陷。
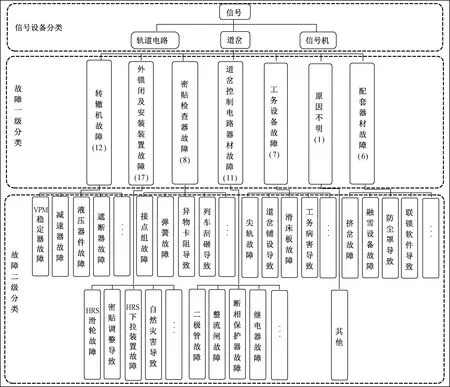
图1 高速铁路信号道岔设备故障等级划分

表1 高速铁路信号道岔故障部分样例数据

图2 高速铁路信号道岔设备故障类别实际分布情况
2 高速铁路信号道岔设备故障诊断模型
高速铁路信号故障诊断通过对基于深度学习集成的故障诊断模型的训练与调优,形成评价指标可交付的道岔故障诊断模型,将高速铁路发生的道岔故障现象输入到故障诊断模型,模型自动输出引起故障的类型与致因,从而实现道岔设备故障的智能诊断,整个过程见图3。

图3 高速铁路道岔设备故障智能诊断过程
故障诊断模型中,如图3模型训练部分,采用ADASYN解决样本不均衡问题,采用TF-IDF实现文本数据特征提取与向量化;设计组合加权方法将BiGRU与BiLSTM神经网络进行集成,并采用K折交叉验证方法训练模型,提高道岔故障诊断模型的泛化能力。
2.1 基于ADASYN的少类别样本生成
ADASYN自适应综合过采样方法是根据少量样本的分布情况,自适应地合成少类样本,并且在容易分类的地方合成较少样本,在难分类的地方合成较多的样本,合成算法的关键是寻找一个概率分布ri,把ri作为每个少类别样本应该合成多少样本的判定准则。
高速铁路信号道岔故障每个一级故障类别下包含的二级类别个数的比例是12∶17∶8∶11∶7∶1∶7,所以采用ADASYN合成二级故障少类别样本,同时能够解决一级故障类别的不均衡性。采用ADASYN自适应生成道岔二级少类别样本的流程为:
Step1计算少类别的不平衡度d=ms/ml,ms和ml分别表示少类别和多类别样本数目,d∈(0,1]。
Step2计算需要合成的少类别样本的总数目,G=(ml-ms)×β,β∈[0,1],表示加入合成的样本后,整个样本所期望的不平衡度,β=1意味着加入合成样本后样本类别完全平衡。
Step3对少类别的每一个样本xi,找出它们在n维空间的K近邻,计算比率ri=Δi/K(i=1,2,…,m),m为样本总数,Δi为xi的K近邻中的多类别样本的数目,因此ri∈(0,1]。


Step6根据以上步骤,计算每个少类别样本xi合成gi个样本。
2.2 高速铁路信号设备故障文本特征表示
TF-IDF是一种基于加权思想的文本特征表示方法,其核心思想[13]是如果一个词在某个文档中出现的频率高,而在其他文档中出现的频率低,说明该词在该文档中具有较高的辨识度,并分配其较高的权重。信号设备故障文本的特征提取首先要实现中文分词,由于高速铁路信号设备故障文本数据中包含转辙机、红光带、密贴器等专业词语,本文通过构建铁路信号专业词库,并将词库加载到Jieba分词工具实现故障文本的准确分词。
TF-IDF中词频(TF)指的是给定词语在该文档中出现的频率,对于给定词语ti,在某个文档dj中的重要程度可表示为
( 1 )
式中:ni,j为文档dj中第i个词语出现的次数;∑knk,j为文档dj中每个词语出现的次数总和。
逆向文件频率IDF是一个词语普遍重要程度的度量,其计算公式如下,IDF越大,则说明该词语具有很好的类别区分能力。
( 2 )
式中:|D|为样本文件总数;|j:ti∈dj|为包含该词语的文件数目。如果该词语不在样本中,就会导致分母为零,因此,分母加1是为了避免分母为0的情况。
Wi,j=TFi,j×IDFi,词语的权重wi,j是由文档内的词语频率与该词语在整个文档集合的低文件频率相乘得到。

2.3 深度学习集成故障诊断模型
集成学习是组合多个弱监督学习模型,得到一个更好更全面的监督学习模型。高速铁路道岔故障诊断模型采用BiGRU和BiLSTM两个神经网络作为弱监督学习模型,将特征提取的特征向量分别输入到BiGRU和BiLSTM神经网络的嵌入层中,两个神经网络通过学习分别在Softmax层输出对特征向量的分类预测概率,通过组合加权集成方法对两个神经网络的预测结果整合计算,最后输出深度学习集成模型对输入数据的分类结果,见图4。

图4 深度学习集成故障诊断网络结构
GRU和LSTM是RNN神经网络的变体,通过在神经元中设计门控单元来有效计算与控制信息的输入和输出,见图5,这种门控单元的设计解决了文本序列长依赖问题。由于sigmoid函数的输出是0~1,1可以表示信息被保留,0表示信息被丢弃,所以GRU和LSTM通过sigmoid函数来处理输入信息,tanh函数处理输出信息。

ft=σ(Wf·[ht-1xt]+bf)
( 3 )
it=σ(Wi·[ht-1xt]+bi)
( 4 )
( 5 )
( 6 )
ot=σ(Wo·[ht-1,xt]+bo)
( 7 )
ht=ot*tanh(Ct)
( 8 )
式中:*为哈达玛积运算符,表示对矩阵相同位置元素进行相乘运算。

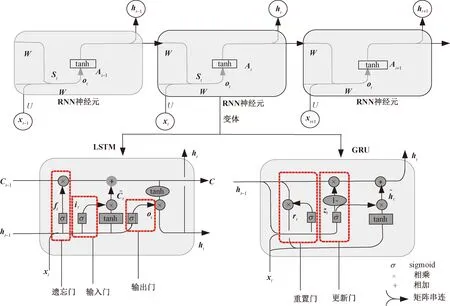
图5 RNN及其变体神经元结构单元
zt=σ(Wz·[ht-1xt])
( 9 )
rt=σ(Wr·[ht-1xt])
(10)
(11)
(12)
LSTM和GRU组合加权集成方法是将单个神经网络的整体分类性能与各类别的分类性能通过分配权重的方法进行结合。组合加权集成方法包括整体权重和类别权重,单个神经网络的整体分类性能越高,就分配其较高的整体权重,各类别权重根据式(13)、式(14)计算,神经网络在类别分类的错误比例越低,说明其在该类别上有较好的分类性能,就分配其较高的类别权重,然后将神经网络的整体权重与类别权重按照式(15)相加,重新计算神经网络在各类别上的预测值,这种组合加权集成方法可以避免集成方法中少数值和极端值的影响。
(13)
(14)
(15)

为提高深度学习集成模型的泛化能力,采用K折交叉验证训练模型。K折交叉验证是将整个训练样本随机地分为K份,其中一份作为验证集,其他K-1份作为训练集,循环K次,直到所有的数据都被选择一遍为止。
3 试验验证与结果分析
本文采用高速铁路2009—2018年产生的信号道岔设备故障数据作为样本进行试验,其中,70%作为训练集和验证集,30%作为测试集,采用K折交叉验证方法随机地划分训练集和验证集比例,采用准确度、召回率和F1值作为算法评价和对比的指标。准确率、召回率和F1值的计算公式分别为
(16)
(17)
(18)
式中:C为样本总数;c为分类类别总数;TPi为被正确分到第i个类别上的正样本;TNi为被正确分到第i个类别上的负样本;FPi为被错误分到第i个类别上的正样本;FNi为被错误分到第i个类别上的负样本。
3.1 少类别样本生成试验
通过采用ADASYN对高速铁路信号道岔故障设备二级故障类别中70%的训练集和验证集进行少类别样本合成,共合成3 339条小类别样本,将合成样本加入训练集和验证集中,共5 371条训练集和验证集样本,其中原始样本与合成样本的占比为1∶1.5。经过样本合成后,道岔故障训练集和验证集样本分布情况见图6,从图6可以看出,二级故障类别基本到达到均衡,一级故障类别的不均衡性也有大幅减弱。
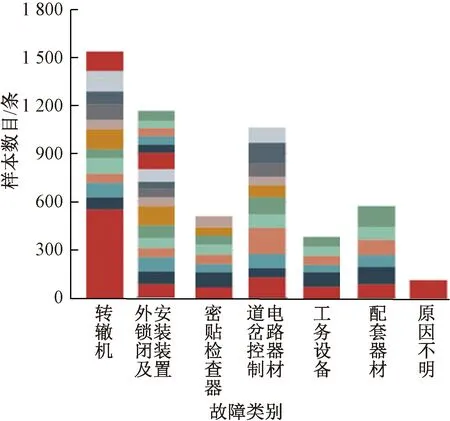
图6 合成样本后设备故障样本总体分布情况
3.2 基于深度学习集成故障诊断模型试验分析
3.2.1 BiGRU和BiLSTM整体权重分配
BiGRU和BiLSTM具有相同的网络参数,其中,嵌入层维度为100,隐藏层维度为512,K折交叉验证K=5,迭代次数为50,批处理大小为256。将ADASYN合成后的训练集和验证集经过TF-IDF特征提取和向量表示后输入到BiGRU和BiLSTM网络中进行训练,两个神经网络训练过程中loss函数值的变化见图7,从图7中可以看出,随着迭代次数的增加,BiGRU相比于BiLSTM的loss值低,说明其整体分类性能更好,两个神经网络中,一级分类相比于二级分类loss函数值低,说明神经网络一级分类相比于二级分类评价指标更高,两个神经网络都在迭代轮数为40~50之间,loss函数值都趋于平稳,说明迭代轮数为50可以使神经网络训练达到最佳的状态。
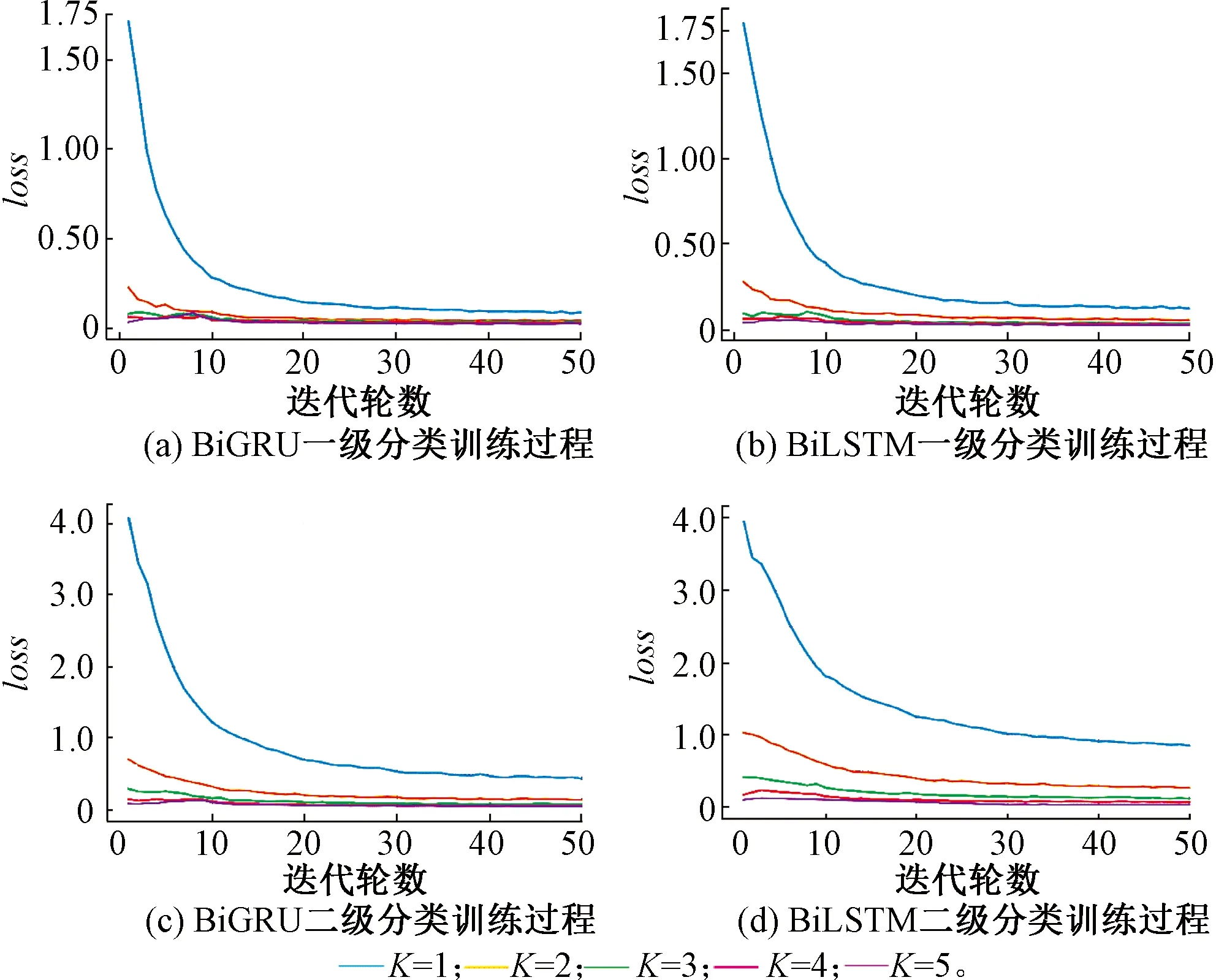
图7 BiGRU和BiLSTM神经网络K交叉训练中loss值变化
经过K=5次训练,采用30%真实样本对BiGRU和BiLSTM训练模型进行评价,评价结果如表2所示,由表2可以看出,采用ANASYN少类别合成方法后,两个神经网络在相同参数下,BiGRU网络的各项评价指标都高于BiLSTM网络,所以应给BiGRU网络分配较高的整体权重。以相同的网络结构以及参数对原始的样本进行训练,得到的试验结果如表2所示,可以看出,经过ADASYN对少类别样本进行合成后,两个神经网络的分类指标明显提升,性能较好的BiGRU网络一级评级指标提升接近15%,并且BiGRU网络的各项评价指标都高于BiLSTM网络,进一步得出BiGRU的性能优于BiLSTM,可以给BiGRU网络分配较高的整体权重。
3.2.2 BiGRU和BiLSTM各类别权重计算
为了更加全面的得出神经网络在各类别分类上的表现,采用ADASYN合成的少类别样本以及全部的真实样本,共6 327条样本输入到训练好的ADASYN+BiGRU和ADASYN+BiLSTM神经网络,两个神经网络在一级分类上的类别权重计算结果如表3所示,从表3中可以看出虽然BiGRU相比于BiLSTM整体评价指标较高,可以得到较高的整体权重,但是两个神经网络在各类别上的表现不相同,BiLSTM在密贴检查器、工务设备以及原因不明类别中具有较大的类别权重,说明BiLSTM网络在这三种类别分类中具有决策权。由于信号道岔设备故障二级分类类别较多,考虑到篇幅的原因,本文只列出一级分类类别权重计算结果。
3.2.3 深度学习集成模型分类
通过以上试验得出神经网络的各类别权重,并且BiGRU相比于BiLSTM应具有较高的整体权重,给BiGRU和BiLSTM赋予不同的整体权重,通过组合加权将两个深度学习神经网络进行集成,通过对两个网络的输出重新计算得出共同的分类预测结果,不同的整体权重分配下,深度学习集成模型的一级故障分类和二级故障分类的评价指标见图8(其中,G代表BiGRU,L代表BiLSTM),从图8中可以看出当BiGRU的整体权重为0.54,BiLSTM的整体权重为0.46时,深度学习集成模型的评价指标最高。
深度学习集成模型最终分类结果如表4所示,可以看出,深度学习集成模型的分类结果相比ADASYN+BiGRU神经网络一级故障分类综合评价指标有5%左右的提升,二级故障分类综合评价指标有9%左右的提升,相比ADASYN+BiLSTM神经网络一级故障分类综合评价指标有6%左右的提升,二级故障分类综合评价指标有10%左右的提升。

表2 K折交叉验证+BiGRU和BiLSTM神经网络试验结果

表3 信号道岔设备故障一级分类类别权重计算结果
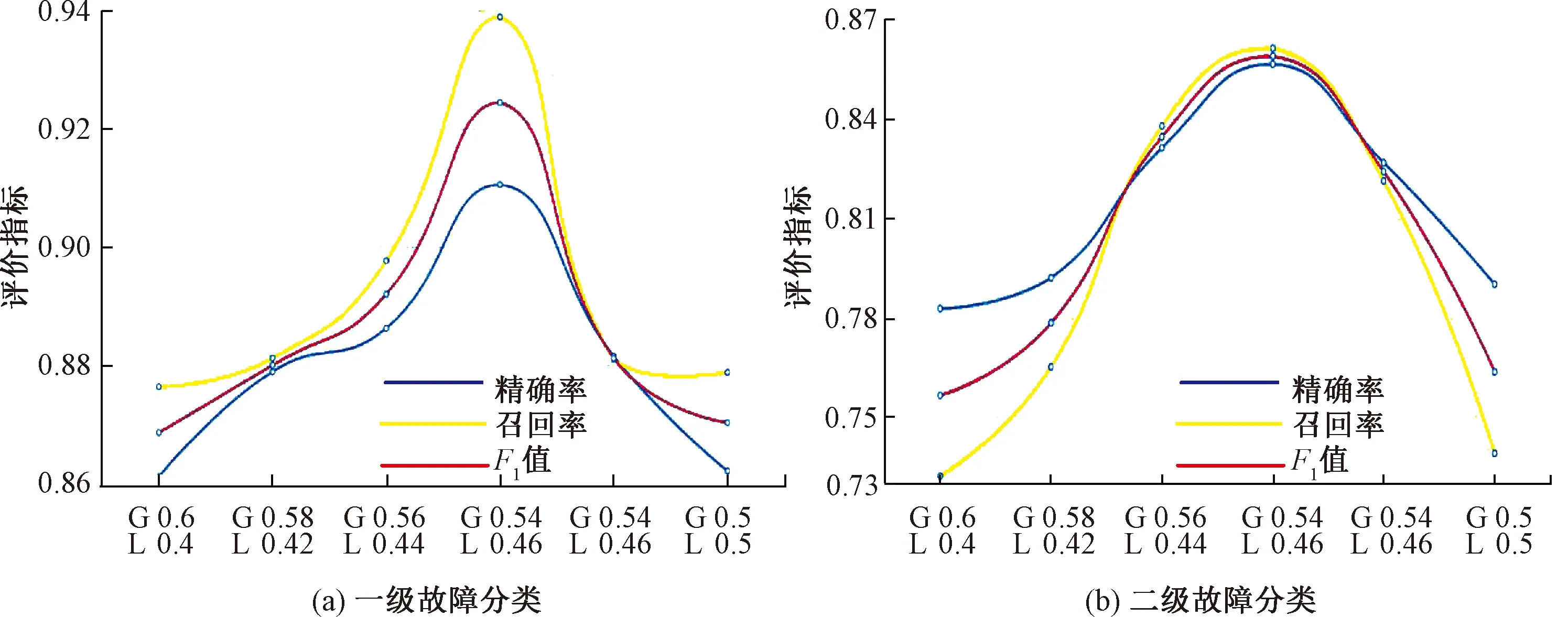
图8 不同整体权重分配下深度学习集成模型评价指标值

表4 深度学习集成模型分类试验结果
3.2.4 集成学习模型试验对比
集成学习模型Bagging代表算法是随机森林RF(Random Forest),Boosting的代表算法是梯度提升树GBDT(Gradient Boost Decision Tree),将ADASYN样本合成以及TF-IDF特征向量表示后的信号道岔设备故障样本数据输入到RF和Boosing进行试验,并采用30%的真实样本进行评价,基分类器个数设置为50,最终试验结果如表5所示,从表5中可以看出,本文设计的深度学习集成模型相比于成熟的集成学习算法RF和GBDT,其评价指标明显较高。

表5 集成学习模型分类实验结果
3.3 试验总结
根据以上试验分析,得出两个结论:(1)由表2和表5可以看出,基于BiGRU和BiLSTM的神经网络分类方法的分类效果优于成熟的集成学习分类方法RF和GBDT,本文将分类较好的神经网络通过组合加权集成是进一步提升分类性能的有效方法;(2)针对不平衡的信号设备故障文本数据,BiGRU和BiLSTM神经网络在原始数据集上分类性能较低,并且难以对少类别样本进行分类,经过ADASYN方法对不平衡数据集处理后神经网络的分类性能有所提升,通过组合加权将BiGRU和BiLSTM集成后,模型的各类评价指标进一步提升。说明本文提出的ADASYN+ TF-IDF+深度学习集成算法,在各方面的性能指标达到最优,可以实现基于不平衡数据的信号设备故障分类与诊断。
4 结束语
本文以高速铁路自开通以来十年的信号道岔故障文本数据研究故障诊断模型,针对故障数据的不平衡性,采用ADASYN数据合成方法合成少类别样本,采用TF-IDF对文本进行特征提取与向量转化,提出基于组合权重的深度学习集成方法,通过试验分析,证明深度学习集成是一种能够有效提升道岔故障诊断模型分类性能的方法,同时该方法也可为铁路文本分类与故障诊断提供一种新的思路。
