基于大数据思维的输电线路缺陷评估分析及应用
2020-01-18张莎李玉兵高伟潘虹
张莎 李玉兵 高伟 潘虹
[摘 要] 针对当前电网可靠性问题,以输电线路缺陷数据为研究核心,分析缺陷发生的各种规律,找出引发缺陷的关键因素;通过数据实际反映线路缺陷与杆塔信息间的逻辑关系,实现多角度、多维度数据分析。通过筛选关联性高解释能力强的杆塔信息做缺陷预测,及时发现设备隐患,分析设备存在的问题,辅助管理人员决策。
[关键词] 多维度数据分析;随机森林分类模型;输变电设备;缺陷评估
中图分类号:F407.61 文献标识码:A
一、输电线路设备缺陷评估分析现状
输电线路设备是电网内重要设备,各级输电线路多数处在野外,所以其遭受自然、人为破坏的影响比较大,缺陷的出现会造成各级线路处于危险当中,因此研究缺陷发生的线路、发生的部位、地段等,对指导线路运检和管理具有很现实的意义[1]。以某市供电公司330kV及110kV输电线路为例,其普遍采用人工巡检的方式,该方式有显著的不足:
一是工作效率低。据输电线路人员定额标准测算,每人平均工作效率为4公里/日,在没有大规模应用机巡作业之前,输电运维缺员严重。二是巡检质量不高。受地形、观察视角、技能、经验等因素影响,工人依靠肉眼或望远镜等简单工具容易对隐患判断失误。三是作业风险高。工人经常需要翻山越岭、登塔走线,不仅劳动强度大,而且工作条件艰苦,且工作中存在野生动物伤人、高空坠落、中暑、冻伤等人身安全风险[2]。
二、输电线路缺陷评估分析设计思路
针对目前输电线路巡检管理存在的一些现状,为有效对输电线路设备的缺陷进行有效管理,需要我们运用新的技术来开展工作。根据分析结果,可以准确判别缺陷类别、缺陷严重程度、设备的状态等信息。及时发现设备隐患,分析设备存在的问题,辅助管理人员决策,从而进一步完善输电线路设备管理体系。
三、输电线路设备缺陷评估数据分析
数据挖掘是从大量的、不完全的、有噪声的、模糊的和随机的实际应用数据中发现隐含的、规律的信息和知识的技术,是统计学、数据库技术和人工智能技术的综合。结合项目需求,项目组对某市供电公司的输电线路设备历史缺陷数据进行了如下分析:
(一)数据集构建
原始数据来源见下图: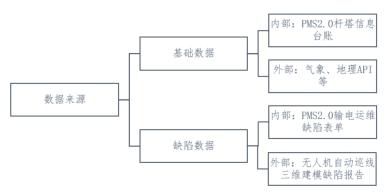
其中基础数据规模约30 Mb,缺陷数据规模约2Mb。
基础数据的质量问题重点来自于缺失值,通过对数据整体做非空频次分析,利用唯一值判断等手段评估缺失率超过90%的多列数据挖掘意义不大,予以舍弃;缺陷数据的质量问题重点来自于编码不一致,存在大量主观描述、同义近义词数据,通过查阅输电运检规程予以统一。
数据预处理分为数据清洗、数据转换、数据整合三个步骤:
1.数据清洗。通过确定缺失值范围,去除不需要的字段,连续变量使用平均值或中值填充,其余根據输电业务知识推测填充。2.数据转换。对数据做了统一化、标准化、离散化处理。3.数据整合。基于已完成清洗、转换工作的基础数据和缺陷数据,基于所属线路和杆塔编号两个关联变量,整合完成宽表。
(二)多维相关性分析
1.通过缺陷大类和电压等级的Pareto分析,确定分析的重点在于330kV和110kV线路的本体缺陷。2.通过本体缺陷的分布分析,得知本体缺陷多发于乡镇及农牧区的戈壁滩平原;且在本体缺陷中占比最高的是杆塔缺陷和金具缺陷。3.通过杆塔外部缺陷的鸟害缺陷数据分析,发现该地区输电线路鸟害有季节性、反复性、区域性三个明显特征。4.通过缺陷分类和所属线路的偏差分析,得到宗龙线、永夹线无论是一般还是危急缺陷异常值高,急需安排B、C类检修的分析结论。
(三)随机森林模型预测分析
通过K折交叉验证法,项目组选取准确率最高的模型:随机森林(RandomForest)作为本研究的建模工具。
随机森林从本质上属于机器学习的一个很重要的分支,叫做集成学习。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类做出的预测。
随机森林最主要的两个参数是n_estimators和max_ features以及max_depth。
n_estimators:表示森林里树的个数。理论上是越大越好,但是计算时间也相应增长。所以,并不是取得越大就会越好,预测效果最好的将会出现在合理的个数。
max_depth:决策树最大深度。
max_features:每个决策树的随机选择的特征数目。每个决策树在随机选择的max_features特征里找到某个“最佳”特征,使得模型在该特征的某个值上分裂之后得到的收益最大化。max_features越少,方差就会减少,但同时偏差就会增加。对于分类问题,max_features=sqrt(n_features)。
由于本研究使用的模型为随机森林,主要的可调超参数为多个,故用网格搜索法确定最优参数。主要评价指标为拟合效果,次要评价指标为训练时间。
n_estimators取值为[1,2,3,4,5,6,7,8,9,10,15,20,30]
引入网格搜索,实验结果如下:
最佳的弱学习器迭代次数= {n_estimators: 30}
拟合结果= 0.7558819171324392
网格搜索经历时间:0.978 S
接着项目组选取对决策树最大深度max_depth和内部节点再划分所需最小样本数min_samples_split进行网格搜索。
实验结果如下:
决策树最大深度 {max_depth: 7}
拟合结果 0.791231732776618
网格搜索经历时间:0.792 S
引入以上两个最佳参数后,看看现在模型的袋外分数,实验结果如下:
{max_features: 5}
拟合结果0.8225469728601252
最后用搜索到的最佳参数(n_estimators=30,max_ depth= 7,max_features=5)结合最终的模型拟合,得到袋外分数oob_score_= 0.868,模型此时已经接近最优了。
通过网格搜索进行参数调优,验证模型的质量分别从耗时、准确率、误差和ROC曲线方面比较判断,验证了改进的系统分类模型无论在耗时上还是在分类的精确率上都有所提高,促使本机器学习模型能够变成得到较高精度的缺陷预测模型。
四、输电线路设备缺陷评估成果应用
本项目的多维分析内容在输电线路设备缺陷数据结构化后,可作为智能监测分析平台的应用参考,结合输电运维指标体系,形成一套完整的输电运维驾驶舱系统。
本项目使用的交叉验证法-随机森林分类模型在训练样本不断充实、基础数据不断完善的趋势下,可以有诸多的应用扩展。例如通过对时间序列再次建模,可以对未来1-2个检修基准周期内任意线路的任意杆塔做缺陷预测,从而达到故障预警辅助运维人员决策的目的;
五、输电线路设备缺陷评估成果成效
项目应用预期成效主要体现在以下三个方面:
(一)资金方面合理高效使用
通过对缺陷和隐患的分析,评估线路运行状态,为线路规划设计、施工验收、大修技改项目储备等各环节提供依据。
(二)管理更高效智能
目前基层班组普遍缺员严重,通过数据分析情况评价线路风险及状态,自动告警,为辅助决策提供依据。更合理使用人力资源,避免人力资源的浪费以及该巡视的地方没有巡视到情况的发生。
(三)线路运检更加科学
通过数据的分析和模型预测应用,可以发现设备缺陷和隐患的具体位置,自动告警,为辅助决策。从多个维度分析各类缺陷的发生规律,建立分类模型进行缺陷预测,更有助于有的放矢,大大减少资源浪费,增强输电运检单兵战斗力。
六、结语
通过建立智能监测分析平台,输电线路缺陷数据将由非结构化转向结构化,过程管控也由人工化转为科学化,不仅降低了电力企业的成本预算,还提高了电力巡检工作的效率,这让供电公司输电运检智能化业务能力支撑能力明显增强。
通过对杆塔台账数据和无人机自动巡视缺陷报告数据资源的梳理和整合,使供电公司输电运维检修方案决策第一次实现“用數据说话”,有助于公司未来更好地运用大数据,实现电力大数据的价值挖掘,激发企业的创新模式,实现公司管理水平的全面飞跃。
参考文献:
[1]李志鹏.基于大数据分析的输电线路管理系统及故障诊断研究[D].武汉:湖北工业大学,2015.
[2]李龙.输电线路的状态检修技术的探讨初探[J].山东工业技术,2018(22):209.
