融入结构化信息的端到端中文指代消解
2020-01-16付健,孔芳
付 健,孔 芳
(苏州大学 计算机科学与技术学院,江苏 苏州 251006)
0 概述
指代消解是自然语言理解中的一项关键任务,准确无歧义的指代消解能够促进对篇章语义的整体理解,对于信息抽取、自动摘要生成、问答系统以及机器翻译等自然语言应用起到基础支撑作用。
国内外学者针对指代消解任务开展了大量的研究,早期主要通过专家构建的领域知识形成消解规则进行指代消解。近年来,得益于自然语言处理(Natural Language Processing,NLP)系列会议的召开及其公布的标注良好的指代消解语料,指代消解的研究重点逐渐转向数据驱动方法。与指代消解任务相关的代表性会议及语料包括:MUC会议,其在1995年和1998年分别发布了英文指代消解语料MUC-6[1]和MUC-7[2];ACE[3]会议,其先后发布了指代消解语料ACE2003、ACE2004和ACE2005,并在ACE2005中开始提供中文指代消解语料;CoNLL会议,其2011年和2012年Shared Task的主题是指代消解,并分别以OntoNotes 4.0[4]和OntoNotes 5.0[5]为基础构建了训练/测试集分明的评测语料。
基于数据驱动的方法主要分为有监督和无监督的方法,主流基于有监督的指代消解方法首先对原始文本进行预处理,包括分句、分词、词性标注、命名实体识别以及语义角色标注等。在此基础上,抽取待消解项并对其采用不同实例生成策略构建训练实例,从上下文中提取相应的特征集。最终使用不同的学习模型训练分类器,并通过最近优先、最好优先等聚类方法对分类结果进行处理,得到文本中的指代链,完成指代消解任务。
传统的有监督的指代消解方法主要有决策树[6]、支持向量机[7]、条件随机场[8]等。近几年,伴随着神经网络研究的展开,单词可以表示为传递语义依赖关系的向量[9-10],单词之间的依赖关系可以被RNN等结构捕获,加之神经网络优异的数据拟合和分类能力,越来越多的学者开始将神经网络方法应用于指代消解研究。文献[11]通过预训练待消解项识别和先行词排序这2个独立的子任务,来学习不同的特征表示。文献[12]通过RNN学习实体水平的信息并进行候选先行词聚类,证明指代消解任务可以从神经网络学习到的关于实体聚类的全局特征中获益。文献[13]利用强化学习技术训练Mention-Ranking模型进行指代消解,在CoNLL 2012[5]的中文数据集上获得较好性能。文献[14]提出一种端到端的实体指代消解模型。该模型使用双向LSTM与Head-finding Attention机制来表示短语并计算其在上下文中的凸显度,并基于此进行表述的识别,然后使用一个Mention-Ranking模型来完成指代链的构建。
相比于英文,中文实体指代消解的研究起步较晚,目前基于深度学习等技术的研究较少。文献[15]利用DBN自动挖掘深层的语义特征,在代词的消解上取得较好的效果。文献[16]探索DBN多层神经网络模型在维吾尔语人称代词指代消解中的应用。文献[17]利用深度学习机制无监督地提取深层语义信息,采用栈式自编码算法进行维吾尔语名词短语的指代消解。
文献[14]模型的最大优势是不需要额外词法及句法分析的结果,在OntoNotes英文语料上的实验结果也表明,在无任何额外信息支撑的情况下,该模型英文指代消解的性能较优。然而中文的行文与英文存在差异,其词法、句法信息不可忽略。本文结合中文行文特点,在文献[14]模型的基础上提出一种中文指代消解模型。通过设计文档句法树压缩算法减小文档句法树的高度,在删除冗余信息的同时,保留核心子树的相关信息。经对比分析词性、文档句法压缩树叶节点深度以及成分句法的结构化嵌入信息对中文指代消解的贡献,将三者结合融入端到端实体指代消解模型。
1 端到端指代消解模型
本文以文献[14]基于神经网络的端到端指代消解模型为基准模型。该模型采用Mention-Ranking,由于简单易实现,在指代消解领域得到了广泛的应用,其具体构成如图1所示。从图1中可以看到,该基准模型的构成与传统框架类似,包括了表述识别和先行词识别2个部分。

图1 端到端的实体指代消解模型Fig.1 End to end entity coreference resolution model
1.1 表述识别
在表述识别阶段,首先结合字、词以及上下文信息,借助Attention机制来表征每一个可能的表述候选,即短语,再通过相应的打分机制对短语在上下文中的凸显性进行打分,根据得分对短语集合进行排序,最终选取一定比例的短语作为待消解的表述集合。
图1虚线框中的部分为表述识别的具体流程,其步骤为:

3)将上述两层输出作为短语表示层输入,利用Head-finding Attention机制来学习短语的中心表示,具体如式(1)~式(3)所示。
(1)
(2)
(3)
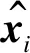
(4)
其中,φ(i)编码短语的宽度特征信息。
4)得到带Attention信息的短语表示后,使用两层前馈神经网络作为打分器,利用式(5)在短语得分层中对短语的表示进行打分,得到得分sm作为短语修剪层的输入。
(5)
5)短语修剪层根据上一次传递来的得分对全部的短语进行排序,取得分较高的一定数量的短语作为表述集合,保留其对应的得分与表示,然后交给更高层做后续处理。
1.2 先行词识别
先行词识别是在一定的搜索空间中寻找最佳的先行词,具体流程如图1中实线框所示。
1)在经过修剪得到表述集合后,按照这些表述在文中出现的先后次序,与传统Mention-Pair模型采用的策略类似,从后向前在一定的距离约束范围内进行表述的配对,得到配对的表示。假设取短语i与短语j构成对应的表述对,其对应的表示如式(6)所示。
(6)
2)在指代得分层,由表述i的得分、表述j的得分以及i、j之间的先行词得分,得到最终i、j之间的指代得分s(i,j):
(7)
其中,当表述i没有先行词,即j=ε时,指代得分为0。
3)表述i与其对应的候选先行词集合中的每一个候选j的指代得分经过Softmax层后,得到i与各个j之间存在指代链的置信度。根据此置信度排序,取置信度得分最高的j*作为表述i的最终先行词,由此得到每个表述及其对应的先行词,形成最终的指代消解结果。
2 句法特征
本文使用的句法特征皆取自成分句法树,具体包括词性标注信息、文档句法压缩树中叶节点的深度信息以及句法树的结构化嵌入信息。由于词性标注信息的获取较为简单,下面重点介绍文档句法压缩树中叶节点深度的计算方法和句法树的结构化嵌入算法。
2.1 文档句法压缩树中叶节点深度的计算
传统句法树是以句子为基本单位的,首先设置一个虚拟的根节点(DOC_ROOT),然后将文档中所有句子对应的成分按照句子在文档中的顺序分别链接到DOC_ROOT上,即可构成初始的文档句法树。但该文档句法树过于繁杂。实验结果表明,直接从这一文档句法树上提取节点的层次信息加入指代消解模型,会引入过多的噪音,对模型的性能产生不良影响。因此,结合指代消解任务的具体需求,兼顾中文自动句法分析性能较低等因素,本文提出文档句法压缩树算法,其主要目标是在确保指代消解所需的精确子树得以保留的同时,尽可能地减小整棵树的复杂度。
传统表述识别方法是在句法树中根据短语对应的节点标签来抽取可能的表述,抽取时设定了表述可能的节点标签集合。在句法压缩树中,本文将这类节点标签集合设为需要保存精确子树的可接受标签集合,其含义如表1所示。

表1 可接受标签列表Table 1 List of acceptable labels
以初始文档句法树和可接受标签列表作为输入,算法1给出文档句法树压缩的具体步骤。由于栈中子树的数量是有限的,每次迭代(步骤3~步骤8)均弹出一个栈顶元素,且没有入栈操作,故算法存在终止条件。另一方面,由于迭代处理子树的顺序为文档句法树后序遍历的顺序,在处理到某一子树或者节点时,其孩子节点所代表的树均已压缩完成,因此最终回溯到根节点,并执行完压缩,此时得到的是不可压缩或者“压缩完全”的文档树,本文称为文档压缩树。
对一个示例文档生成初始的语法树,如图2所示。由于篇幅限制,此示例文档仅包含一句话,对于包含多句话的情况可类似处理。对图2的语法树进行压缩,结果如图3所示。对比图2和图3可以看出,该压缩算法极大地减小了文档树的高度,删除了大量的冗余信息,且核心子树的相关信息被很好地保留。因此,该算法得到的文档压缩树能较好地体现表述的层次结构关系。
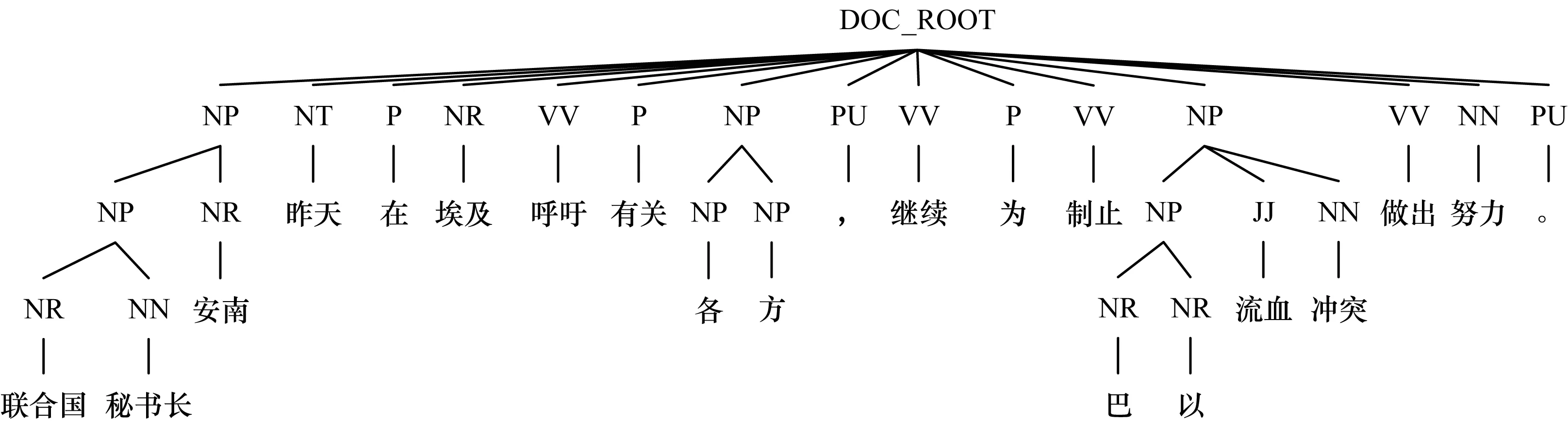
图3 文档压缩树Fig.3 Document compression tree
算法1文档句法树压缩算法
步骤1初始化文档句法树DOC_ROOT。
步骤2后序遍历文档句法树,并将遍历的结果保存在栈STACK中,栈顶保存后序遍历经过的第一个节点(如图2中的“NR-联合国”)。注意,原成分句法树中的单词节点与其父节点在文档句法树中合并为一个节点,节点的标签由词性标签表示,即图2中的“NR-联合国”表示一个节点(框1),且为文档句法树的叶子节点,节点标签为“NR”。
步骤3如果STACK为空,返回文档句法树,程序结束;否则,继续执行。
步骤4弹出栈顶元素,记为subtree;取其父节点,记为parent,注意父节点不一定存在。
步骤5如果subtree为叶子节点,跳至步骤3。
步骤6如果parent存在,并且以下2种情况之一存在:1)subtree只有一个孩子(如图2中方框2所示);2)subtree的标签不在可接受标签列表中,则parent上删除subtree子节点,并在删除位置插入subtree的所有直接孩子节点。对于情况1,此举可以在保留子树最“精确”信息的基础上减小树的整体高度;对于情况2,本文假设当子树标签不在可接受标签列表中时,子树表示的单词或者短语成为待消解项的可能性较小,其层次结构对模型的预测没有帮助,故删除该子树节点,并使孩子节点“上移”。
步骤7如果parent不存在,即subtree为文档树的根节点,并且subtree只有一个直接孩子节点,则删除subtree节点,并使其唯一的直接孩子成为新的文档句法树根节点,此举同样可以在保留子树最“精确”信息的基础上减小树的整体高度。
步骤8返回步骤3。
假设初始文档句法树为m叉树(m≥1),其节点数为n。步骤2中对其进行后序遍历所需要的时间复杂度为O(n),空间复杂度,即STACK的大小为O(n)。步骤4中弹出栈顶元素可在常数时间内完成,即时间复杂度为O(1)。步骤7中“删除subtree节点”的操作同样可在O(1)时间内完成。步骤6为算法的核心部分,耗时最多:在最好情况下,不需要对subtree及其相关节点进行调整,算法只需进行一次后续遍历即可返回;在最坏情况下,需要对STACK中的每一个非叶子节点(叶子节点不需要进行调整)删除其自身,并重新设置其所有孩子的父节点为parent,所需操作花费时间O(m),总耗时O(mn)。综上所述,算法的空间复杂度为O(n),最好情况时间复杂度为O(n),最坏情况时间复杂度为O(mn)。
2.2 结构嵌入
在NLP的任务中,各种字向量、词向量方法被广泛使用,并且性能均较好。近年来,有关结构化信息的向量化问题也得到研究者的关注。文献[18]针对成分句法和依存句法展开研究,提出一种成分句法树的结构化嵌入(Structural Embedding of Constituency Tree,SECT)方法,并将其应用于问答系统中答案的抽取。实验结果证明,该方法能较好地分辨句子的句法边界,抽取与句法相关的答案。本文将由SECT方法获得的向量信息应用于指代消解模型。
SECT方法的具体流程如下:
1)对于单词p,即句法树中的叶子节点,定义一个句法序列S(p),该序列保存叶子节点p到句法树根节点的路径。例如图2中的“NR-联合国”节点,其对应的S(p)为{NR,NP,NP,NP,IP,TOP}。在实验中,出于性能和内存利用率的考虑,需要设置一个窗口大小来限制S(p)的长度。当然,由于中文成分句法分析的性能相比于英文较低,特别是句法树中较高层次的歧义较大,因此借助窗口大小进行限制,在一定程度上将去除句法树中高层的歧义节点。
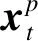
(8)
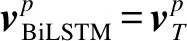
3 实验与结果分析
本文使用CoNLL2012数据集(语料规模如表2所示),并根据不同的设置对模型进行实验,并对实验结果进行讨论分析。
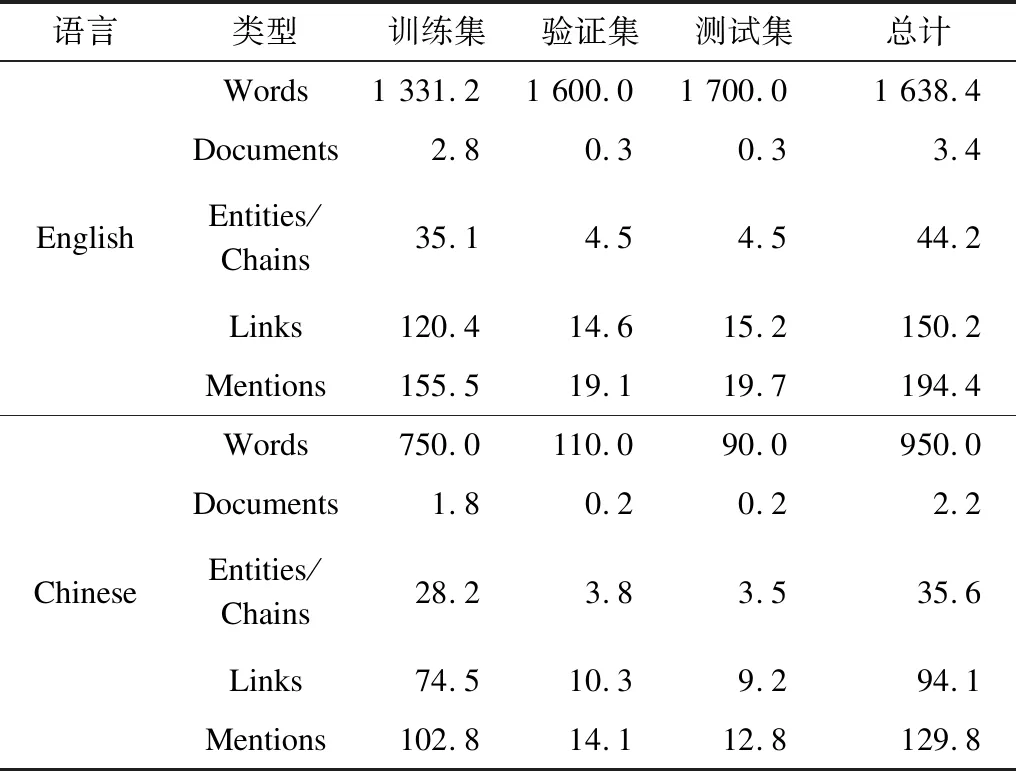
表2 CoNLL2012数据集语料规模Table 2 Corpus size of CoNLL2012 dataset KB
3.1 实验设置
本文主要关注中文端到端的指代消解,平台使用的相关参数包括:使用64维的Polyglot[19]中文字、词嵌入,通过仿射变换将其变换为100维;使用单层Character LSTM[20]进行字嵌入的表示,隐藏层维度为100维;每个特征编码得到的向量的维度为20维,其他实验设置与文献[14]中的实验设置相同;对于SECT,使用单层双向LSTM作为编码器,输出向量的维度为20维,与特征向量的维度相同,dropout[21]设置为0.2,词法序列的窗口大小设置为10。
为了对比中英文指代消解的差别,本文将额外句法信息使用类似的策略引入了英文指代消解。中英文测试中用到的词性、句法等信息均来源于CoNLL2012数据集中提供的自动成分句法分析的结果。
为了详细分析引入的词性、句法和文档压缩树向量对指代消解系统性能的影响,本文设计8个实验,分别用于测试每个引入特征对模型的贡献度,具体如表3所示。其中,Y(N)表示模型输入包含(不包含)该特征嵌入。
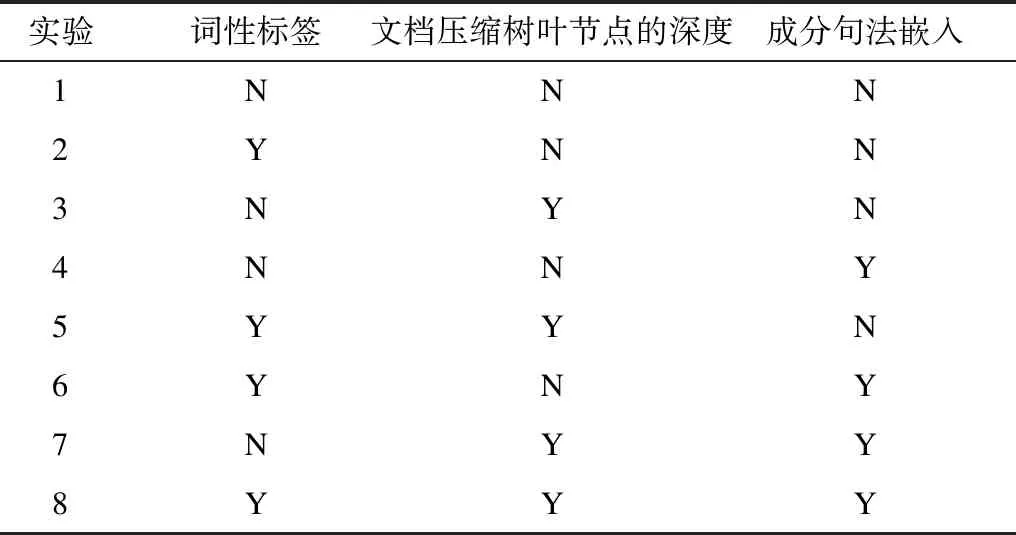
表3 实验设置Table 3 Experimental setup
从表3可以看出:实验1不包含任何额外信息,保持文献[14]平台的原貌,本文以此为基准平台;实验2~实验4验证单独引入3个信息对指代消解系统性能的贡献度;实验5~实验7给出3个信息两两组合后对指代消解系统性能的贡献,从中既可以看到特征的组合效果,也可以看出引入的特征间具有一定的重叠性;实验8融合3个信息,得到的是系统的最终性能。
3.2 结果分析
上述8个实验在中文数据集上的性能测试结果如表4所示。每个实验均使用不同的随机数种子运行5次,取其平均值作为最终的实验结果。评价指标由CoNLL2012- Shared Task采用的平均F1值,即MUC、B3和CEAFφ4标准的F1值的平均值、表述召回率与各自对基准平台的改变量以及平均训练耗时(不包括数据预处理的时间)构成。
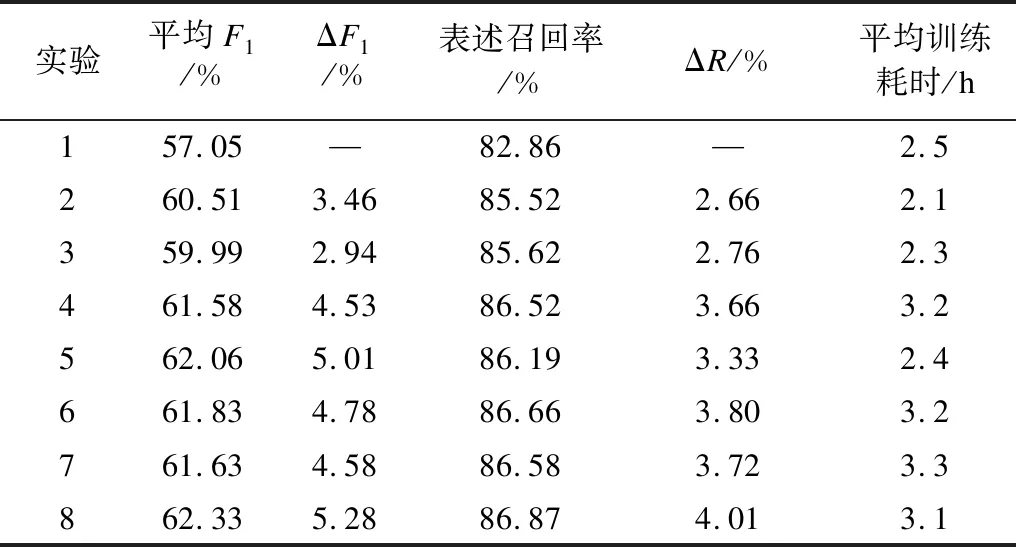
表4 中文指代消解实验结果Table 4 Experimental results of Chinese coreference resolution
从表4可以看出:
1)在实验2~实验4中,简单的词性嵌入信息能大幅提升指代系统中表述识别的召回率,最终对消解性能产生3.46%的正向贡献,并且使训练耗时缩短了0.4 h;SECT信息的融入使得表述召回率提升了3.66%,最终指代消解的性能提升了4.53%,但由于其本身的复杂性,使训练耗时增加了0.7 h;相比而言,文档压缩树叶节点深度信息的加入对整个指代消解性能的F1值贡献约为2.94%,低于词性和SECT信息的贡献。但相对于SECT信息,其训练耗时短,更加简单高效。
2)在实验5~实验7中,引入的3个特征在两两组合后,较引入单独特征能进一步提升指代系统的表述识别的召回率和系统性能。这说明3个特征具有一定的组合效应。对比而言,词性信息与文档压缩树叶节点深度信息的组合作用最为明显。虽然在三者独立贡献中,文档压缩树叶节点深度信息最小,但与词性信息组合后指代消解的性能提升了5.01%,同时也加快了模型训练。而SECT信息的独立贡献约为4.53%,其与词性或文档压缩树叶节点深度信息的组合进一步提升的F1性能仅为0.25%或0.05%,这说明SECT信息中涵盖了部分的词性和文档压缩树叶节点深度信息,特别是句法树的结构信息,并且训练耗时也显著增加。
3)在实验8中,系统引入3个特征的组合,其性能提升了5.28%,且表述召回率提高4.01%。这表明即使在神经网络平台中,结构化相关信息仍然是不可忽略的。
为了验证采用文档压缩树的优势,本文使用原始的句法树替换掉实验3中的文档压缩树(实验3’),进行对比实验,结果如表5所示。
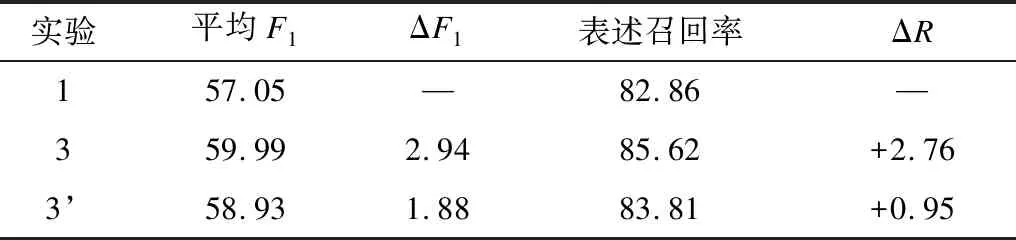
表5 原始句法树与文档压缩树的结果对比Table 5 Comparison of results between original tree syntax tree and document compression
从表5可以看出,使用原始句法树得到的系统的最终性能相较于本文文档压缩树的结果F1值降低了1.06%,召回率也下降了1.81%。实验结果表明,相比原始句法树,文档压缩树确实在保持核心子树的基础上有效地去除了噪音信息,能更好地帮助指代消解。
为了验证上述3个特征对英文指代消解性能的贡献,本文进行了与中文类似的实验,结果如表6所示。其中,实验1复现了文献[14]的方法,系统性能虽略低于其结果(平均F1值相差约为1.13%),但却大幅缩短了训练模型所用的时间。

表6 英文指代消解实验结果Table 6 Experimental results of English coreference resolution
从表6可以看出,无论是单独使用这3个特征中的一个,还是使用它们的两两组合,或是所有特征集合,得到的英文指代消解性能相较于基准平台在平均F1值与表述召回率上均有小幅度下降,这说明中英文在行文上的差异对指代现象有一定的影响。中文指代消解的研究既要借鉴英文指代消解的某些策略,也需要展开中文针对性的研究。
4 结束语
本文在文献[14]模型的基础上,构建一种中文指代消解模型。相比于英文指代消解,中文的词法、句法等信息不能忽略。因此,通过引入词性、文档压缩树叶节点深度以及SECT 3个特征向量,提升模型对中文实体指代消解的性能。在CoNLL2012中文数据集中的测试结果表明,本文模型较基准模型指代消解性能更好。下一步将加入更多特征,并对模型中的表述识别策略进行调整以减少运算量,提升模型的指代消解性能。
