基于网络评价数据的产品感性意象无偏差设计方法
2020-01-16张云鹍牛亚峰阳明庆
林 丽 张云鹍 牛亚峰 阳明庆
(1贵州大学现代制造技术教育部重点实验室, 贵阳550025) (2贵州大学机械工程学院, 贵阳550025)(3东南大学机械工程学院, 南京211189)
随着生产力的提高,消费者选购产品已倾向于综合考虑产品各方面特性是否满足自身诉求.鉴于产品所引发的情感体验可增强产品购买、拥有及使用意愿[1],产品不仅要求可靠性好、质量高,更应通过感性意象设计,引发良好的情感体验,从而满足用户精神需求并提高消费者满意度[2].
为此,学者们从不同视角提出了感性意象设计方法,其中以感性工学方法最为成熟,可将消费者对产品的感受及感性意象融入新产品的开发中[3].Wang等[4]以数码相机外形为研究对象,使用分类树将产品特征细分结果与产品风格相关联,提出了实现产品差异化的特征组合方法;Shieh等[5]以花瓶外形为研究对象,将花瓶轮廓曲线参数化,使用支持向量回归建立形态参数与情感反应之间的关系,构建了基于多目标进化算法的混合感性工学模型,用于指导新设计;Hsiao等[6]对咖啡机特征进行分解并计算了各个特征对感性意象的贡献度,结合遗传算法构建了产品感性意象设计辅助程序.通过感性工学技术使产品设计深切关注用户深层次的感性诉求,是当前产品个性化与情感化设计趋势下的研究热点.
在产品感性意象设计过程中,第一个至关重要的阶段就是获取感性知识[7].用户感性意象偏好作为唯一的用户端知识,是设计输入的重要信息.现有研究大多基于各种语义量表获取用户的感性意象偏好及数据.这种方法具有实施灵活、简单易行、问卷结果易处理的优点,但也存在以下不足: ① 设计调查需被试者参与,样本量少;被试者多与研究人员有一定联系,易因便利样本导致数据代表性差.②设计调查问卷再用率低,发出和回收时耗时耗力.③ 基于语义量表的调查易因用户的认知差异导致意象提取误差[8].鉴于此,学者们将网络用户评价大数据引入到感性意象相关研究中:Hsiao等[9]以跨境物流服务设计为对象,基于感性工学技术和文本挖掘技术,从在线评论中获取感性意象词汇,研究了感性意象与物流服务要素间的关系;李少波等[10]以手机为研究对象,从在线评论数据中获取感性意象,基于BP神经网络建立了产品感性意象与产品属性参数的映射,实现对用户心理评价的预测;Chiu等[11]提出一种从客户产品评论中提取感性观点的方法,并且将他们分类为7对感性属性,协助产品设计师从情感角度理解客户和做出决定. 此外,Jiao等[7]提出了一种从在线产品评论中提取用户感性知识的方法,整合自然语言处理技术和感性工学,明确用户的情感需求,实现用户感性需求的无偏差定位.
目前,网络评价数据作为蕴含巨大用户知识的宝藏,包含了精准而真实的用户感性意象诉求.为此,本文提出基于用户网络评价数据的产品感性意象无偏差设计,在网络评价大数据中挖掘用户的感性信息,以更快捷的方式获取意象,并充分借助计算机技术,脱离传统感性意象设计中的案例推理,建立更短周期、更高效的感性设计模式.并且,将大数据中用户最真实的评价信息引入到感性意象设计中,能够有效规避消费者调查中所表现的喜好与真实喜好的偏差问题,使得创新设计所传递的意象就是用户真实诉求的再现.因此,将网络评价大数据与感性工学相结合,并借助计算机技术,仅凭借感性意象的文本描述,无需借助实例样本的推理,即可建立最懂用户的、高效的感性意象无偏差设计方法.
1 基于网络评价数据的产品感性意象无偏差设计方法
本文方法主要针对有形工业产品,流程如下:
① 产品样本获取与预处理;
② 感性意象词提取与参数化;
③ 产品设计特征参数化;
④ 感性意象与设计特征间映射关系构建;
⑤ 基于映射关系的产品创新设计.
整体流程步骤如图1所示.
1.1 基于文本挖掘技术的感性意象词提取及参数化
感性意象是人对物心理上的期待感受[12],可由网络评价中的形容词表征.由于同一产品有多种意象,因此,通过关键词提取算法分析词语在文档中的统计特征,依据数量阈值提取并量化重要性较强的N个形容词,则被提取的感性意象表述为
(1)
式中,Ki为样本i的感性意象;Wi为样本i中的意象词组成的向量;Ti为样本i中意象词的重要性参数组成的向量;Wij为样本i的第j个意象词;Tij为样本i的第j个意象词权重.针对产品评论文本的主题一般较为集中,再结合TextRank算法提取关键词,算法公式为
(2)
式中,T(Vi)为词语Vi的重要程度;d为阻尼系数;I(Vi)为指向词语Vi的集合;O(Vj)为词语Vj指向其他词语的集合;ωji、ωjk为两节点之间边的重要度.经过多次迭代循环,计算各个词语的权重.
式(1)中Wij为词语且彼此独立,无法直接参与计算.因此,在整体语义背景下,通过构建基于Distributed Representation思想的词向量,将所有文本中反映语义关系的词语转换为词向量,获得各词的参数化描述,进而通过降维以筛选词向量中的主要信息.假设降维后词向量维度为m,则式(1)可描述为
(3)
式中,S(Wij)为降维后的词语Wij的词向量;Sm(Wij)为降维后感性意象词在第m维上的值.由于多种意象可相互叠加,因此对意象形容词求和即是对其词向量的相应维度求和,从而得到样本感性意象在各维度上的值,即
(4)
式(4)中产品i的感性意象Ki用实数向量表示.在感性工学研究中,常以产品在各个词汇上的倾向作为感性意象参数[13-16],将参数的所有可能取值范围称为感性意象空间.本文通过式(4)实现感性意象参数化描述,词向量空间S即感性意象空间.
1.2 产品设计特征参数化
由于产品主要通过多种特征之间的共同作用向用户传递情感信息[17],产品的感性意象与形态比例之间具有相关性[18],且线比点和面更能表现产品的形态特征[19].因此,本文通过参数化曲线描绘产品的造型特征,以获得产品各部分比例及形态数据,并将参数按数值范围分组,将连续型变量转变为离散型变量,以提高对测量误差的容忍度.
1.3 感性意象与设计特征间映射关系构建
经过产品感性意象提取及参数化描述,产品i的感性意象已转换为感性意象空间S上的坐标参数Ki;产品的第k个设计特征经分析提取,转换为设计特征参数ak.采用最大信息系数(maximal information coefficient,MIC)计算感性意象空间各维度与产品外形特征参数的关联度,选择高数值维度作为映射关系构建自变量,则映射关系可表示为
f:Kik→ak
(5)
式中,Kik为在特征ak条件下筛选重组得到的产品i的感性意象参数.
因式(5)设计特征参数ak为离散型变量,式(5)的映射关系实质是低维变量的分类问题.其中,映射关系的构建采取随机森林分类算法,主要原因在于:①在设计特征的参数化过程中,人工描绘外形并提取参数容易产生异常数据.随机森林算法对离散点的敏感度较低,可以避免异常数据对结果造成的影响.②经过降维获得的感性意象空间中,不同维度之间关系不明确,对分类结果的贡献度也不同.随机森林算法对输入特征之间的关系不敏感,适合于本研究过程.③随机森林使用Bootstrap抽样算法构造训练数据集,基于多数表决原则计算输出,在样本量较少时不容易过拟合.
基于随机森林算法获得映射关系后,即可通过映射关系分析提取设计特征的取值范围.
2 案例验证
轿车外形设计较为复杂,许多设计特征互相影响,形成整体的风格.文献[20]指出,汽车的侧面对汽车外形设计研究具有重要的意义.因此本文选取三厢轿车的侧面轮廓作为设计对象,验证方法的可行性.
2.1 产品样本获取与预处理
使用scrapy网络爬虫,从太平洋汽车网上自动获取造型相似车型及用户评论信息.选择评论数较多的车型,查找对应的外形数据,以外形是否相同为标准区分车型,将评论数较多的三厢轿车作为分析样本,共计57个.
2.2 感性意象词提取及参数化
1) 使用python软件中jieba工具包,将车型名写入自定义词典并对文本进行分词,基于式(2)提取产品关键词和权重,部分结果如表1所示.
2) 使用python中word2vec工具包,以爬取到的所有外观评论数据为原始数据,设定词向量维度为100,训练文本词向量,部分输出及关联度如表2所示,实现感性意象关键词的参数化描述.
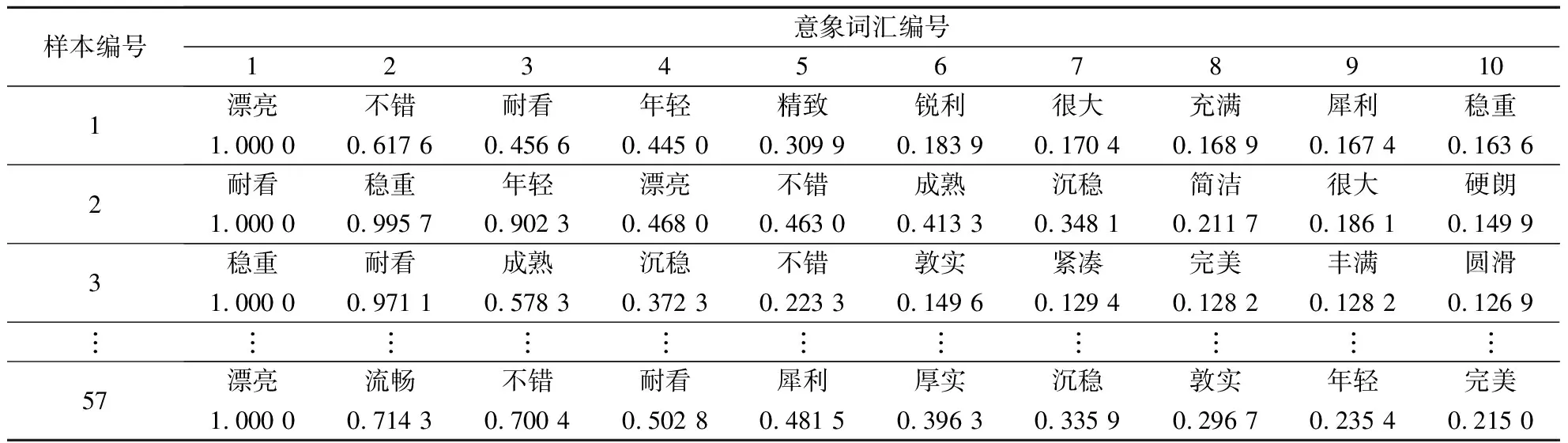
表1 部分代表意象词汇及其权重
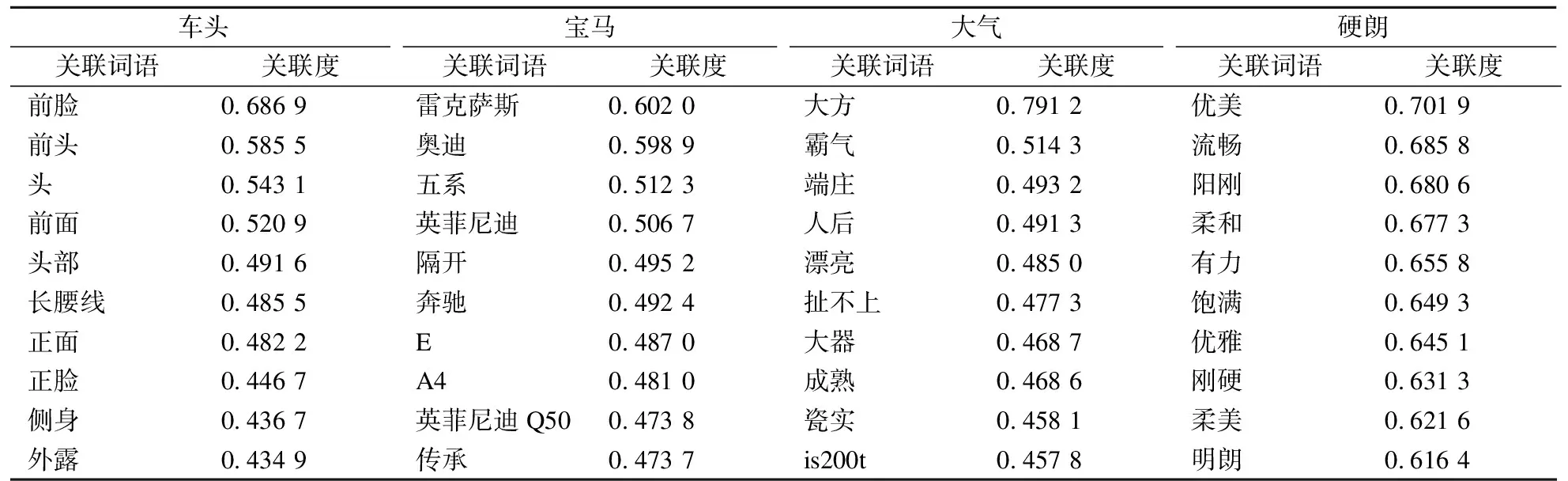
表2 词向量输出及关联度
3) 分别提取各感性意象词的词向量值,进行主成分分析,如图2所示.在维度19时,累计贡献度达到了0.755 9,维度19后可解释变异量趋于平缓,因此确定词向量降维后的维度为19.
4) 共同降维所有样本的意象词向量,并通过式(4)计算各个样本的感性意象参数,57个样本的感性意象参数降维后的分布如图3所示.由图可知,各维度上感性意象参数的变化随着维度的增高而减小,即感性意象参数中的信息量随着维度的增加而减少,降维有效保留了意象词向量中的信息.由于降维后某维度上的感性意象参数实质上是样本在相应的共性因子上所包含的信息,同时各个共性因子对样本意象的贡献不明确,在构建映射关系时需要选择与特征间关系较强的感性意象空间维度参与分析.
2.3 汽车侧轮廓设计特征参数化
借鉴文献[21-22],将汽车轮廓简化,如图4所示,并按表3的内容计算相应的侧轮廓造型布局参数.由于车顶弧线的曲率会对车高参数产生影响,因此使用简化后的车头底部到车顶的距离表示车高H.根据特征参数数值大小并参考文献[21-22],在取值范围内三等分并参数化表示,见表4.
2.4 基于随机森林分类的映射关系构建及可靠性分析
实验采用python中sklearn包的RandomForestClassifier函数构建映射关系.首先分析最大信息系数值以选择构建映射关系的数据.计算各个产品特征参数与各个维度的感性意象参数间的MIC值,选择MIC值较高的3个维度的感性意象参数,参与映射关系的构建.所选择的感性意象参数与产品特征参数间的MIC值如图5所示.在映射关系构建过程中,预留出约36.8%的数据,以此作为袋外数据,用于验证映射关系的有效性.经验证,各个设计特征参数上的分类正确率如图6所示.由图可见,所有特征的分类正确率均高于随机分配正确率0.33,86.67%的特征参数的分类正确率在0.5~0.7之间;结合图5,部分MIC值较低的特征参数上的分类正确率较低,符合预期结果.映射关系总体上有效.
2.5 基于映射关系的产品创新设计
为了计算消费者喜好的感性意象参数,需要获取反映消费者喜好的文本.外观评分能够反映汽车造型是否满足消费者的喜好,相应的外观评论文本则是喜好的文本体现,因此,可通过分析评价分数最高的文本,来获取消费者的感性喜好.通过网络爬虫获取并筛选外观评分最高分所对应的评论文本,去除映射模型训练样本中存在的文本,共计500条.以该文本作为输入,应用本文方法得到关键形容词及其权重如表5所示,其参数如表6所示.预测的特征参数类别及其参数取值范围如表7所示.
基于表7中的设计参数,绘制出图7所示的侧面轮廓布局与外形:设定参数H=1,根据特征参数编号1、6、15的取值范围,可求得参数L、Hfd、Hbd的取值范围,进而结合设计师经验选择合理的参数值.同理可求得其余参数值.根据参数值绘出相应的侧面轮廓布局,见图7中的直线部分.在此轮廓基础上,设计师结合自身经验设计新的侧面轮廓,见图7曲线部分.
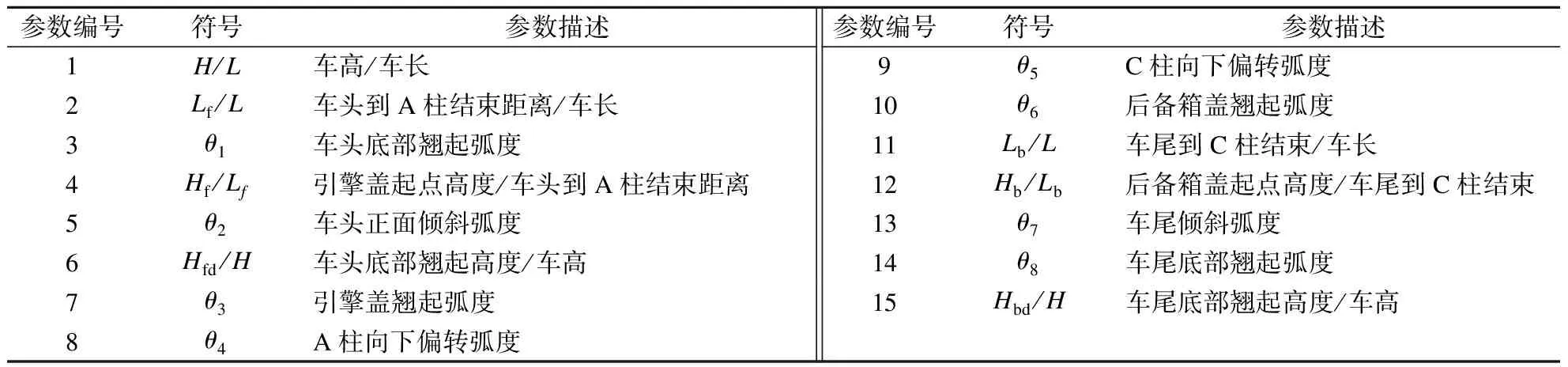
表3 特征参数编号及意义

表4 部分样本特征参数化结果
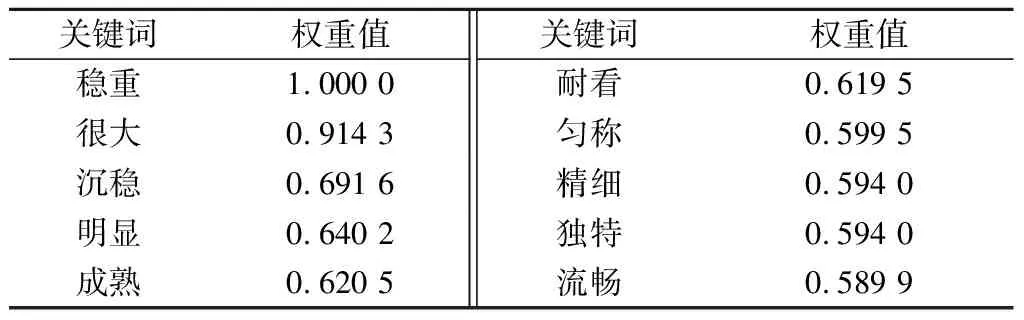
表5 感性需求关键词及其权重
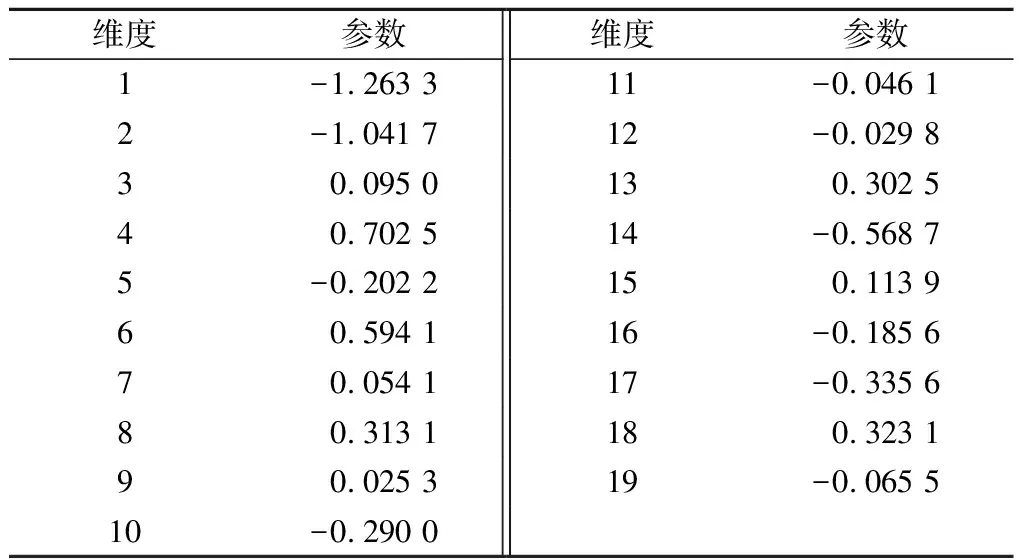
表6 感性需求意象参数
对图7中的新侧面轮廓外形进行观察分析,可见其驾驶舱空间占比较大,并使侧面外形更加厚重,有效满足了表5中权重大于0.9的意象,即 “稳重”和“很大”的感性需求,以及权重位于第3的“沉稳”的感性需求;此外,图中轮廓驾驶舱视野良好,车头长度较短,分别满足了表5中“明显”、“独特”等感性需求的关键词.
通过对新侧面轮廓外形进行分析可知,本文方法得到的侧面布局和侧面轮廓外形能够有效满足消费者的感性意象需求.
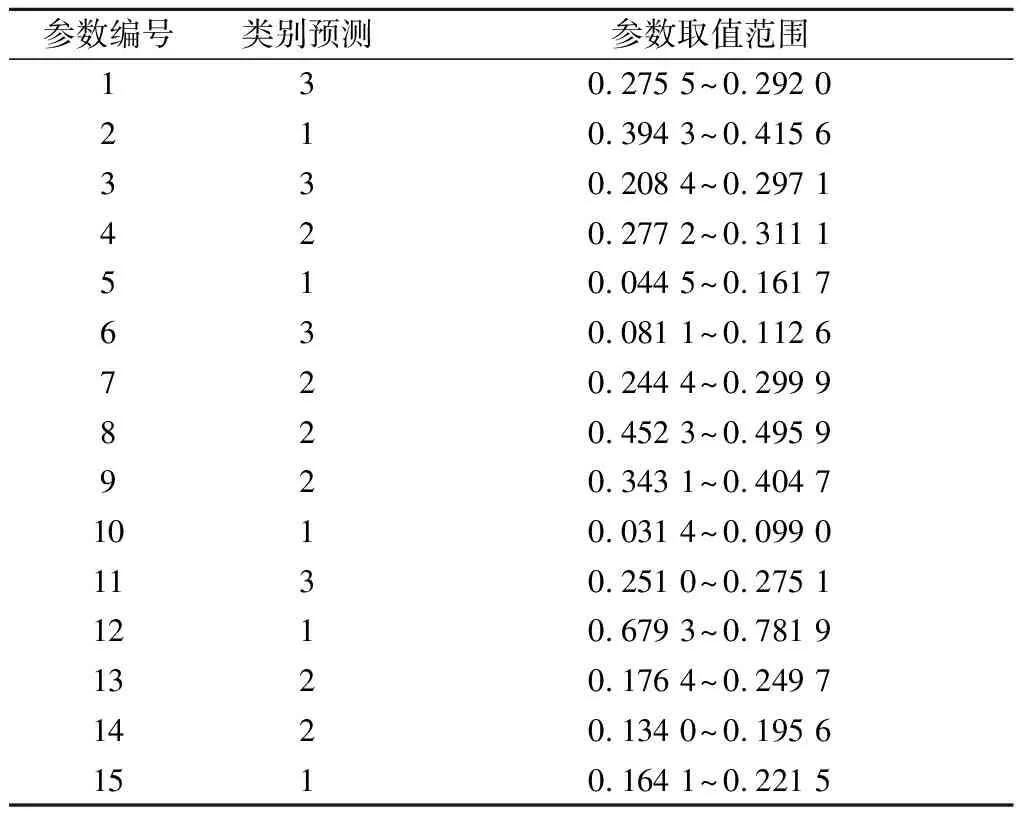
表7 特征参数预测类别及参数取值范围
3 结论
1) 将网络评价数据中真实用户信息引入产品感性意象设计,通过关键词提取、构建词向量及降维处理,将用户感性意象参数化,高效快捷地获取用户的感性意象信息与需求信息,避免了基于语义量表获取用户感性意象的方法所产生的缺陷.
2) 不再依赖案例推理,通过用户感性意象提取与参数化方法,结合感性意象与设计特征参数间映射关系,直接从用户的意象描述中生成设计方案,提高了设计效率,为感性意象智能设计奠定了前期基础.经实例验证,通过本文方法构建的映射关系中,正确率在0.5~0.7之间的有86.67%,生成的设计方案能够满足主要设计需求.
3) 由于本文对感性意象词汇提取仅考虑了词性及词语间关系,尚未考虑单个词汇与具体特征细节之间的关系;构建的词向量尚包含部分噪声信息,对映射关系的拟合产生了一定干扰.这些问题均有待进一步思考与解决,是将来研究的重点.
