基于理论线性溶解能关系预测有机污染物在PDMS与水中的分配系数
2020-01-16朱腾义
朱腾义 姜 越
(扬州大学环境科学与工程学院, 扬州 225127)
疏水性有机污染物大多会汇聚在水体沉积物中[1],随着沉积物在环境介质的迁移、转化,其潜在毒性使有机污染物对整个生物圈都产生不可逆的影响.因此准确测定有机污染物的浓度有利于从整体上认识其在环境介质中的分布及归趋.而被动采样是一种用于检测水、沉积物、土壤、空气或其他环境媒介中有机污染物浓度的强有力工具[2-3].被动采样是以污染物在两相间扩散的化学势能梯度作为动力,用来测定污染物逸度的平衡采样技术[4].常见的被动采样器主要分为固相微萃取(solid phase microextraction,SPME)和半透膜(semipermeable membrane device,SPMD)[5]2种.SPME利用石英纤维表面不同性质的涂层吸附不同类型的化合物.在测定非极性污染物时最常用的涂层是聚二甲基硅氧烷(PDMS).有机污染物在PDMS与水相中的分配系数(KPDMS-W)是权衡被动采样器性能的重要指标[6].目前常用的实验测定KPDMS-W值方法有静态法和动态法2种.文献[7-9]利用静态法测定有机污染物的KPDMS-W值,其主要原理分为单点校正[7,10]和多点校正[11].静态法的主要缺点是只考虑了SPME光纤与水相之间的两相平衡,而忽略了化合物自身挥发或由于系统表面的吸附所引起的损失,从而造成了较大的测量误差.动态法[12-13]则对上述问题进行了优化,消除了部分误差.然而,对于疏水性较强的化合物,系统表面的吸附所带来的误差仍不能忽略.同时,采样器内化合物的运输取决于很多因素,包括采样器固相内部自由空隙体积的大小和固相碳链上节段迁移率等[2].目前有机污染物的KPDMS-W值均是通过繁琐的实验测得,费时且费力,因此,开发一种预测模型方法用来预测污染物的KPDMS-W值十分必要.
目前的预测方法主要有3种:① 分配系数法,即利用化合物的辛醇水分配系数间的关系式来计算KPDMS-W值;② 线性自由能关系(LFER)法;③ 理论线性溶解能关系(TLSER)法.由于化合物的辛醇水分配系数(Kow)常用于度量化合物的疏水性程度,因此利用待测物的KPDMS-W值与Kow值之间的关系来预测KPDMS-W值是一种主流的预测方法.该方法的优点是,当分子量较小时,HOCs(如PAHs)的Kow值在3.36~6.50范围内,Kow与KPDMS-W呈良好的正相关性.缺点是当分子量较大时HOCs(如PCBs)从水相向PDMS涂层的萃取过程主要是靠吸附而不是吸收,也就是说,Kow与KPDMS-W之间是非线性的.因此,针对疏水性较强的化合物,利用Kow值来预测化合物KPDMS-W值具有一定局限性.
另一种预测方法是利用计算机基于多参数线性自由能关系(pp-LFER)建立模型,优点是通过理论计算得到分子描述符,提升了对实验参数未知化学品的预测能力.它允许在完全脱离实验测定的条件下,预测所感兴趣的化合物的性质,实现了虚拟预测或计算机(in silico)预测技术.缺点为pp-LFER预测模型缺少溶质(化学品)相关的Abraham描述符(E、S、A、B、V).此外,由于缺少不同温度下实验数据的校准,pp-LFER模型对不同温度下分配系数的预测仍然存在缺陷.
TLSER是在 LSER的基础上通过理论计算代替LSER经验性描述符而建立起来的一种研究方法[14].这种研究方法可以弥补现有数据的缺失、减少实验测试费用和评估实验结果数据的不确定性,同时可以很好地定量化评价污染物对环境的影响,如陈景文等[15]应用TLSER预测了部分卤代芳烃的正辛醇/空气分配系数,朱腾义等[16]基于TLSER模型预测了部分有机污染物的LDPE膜/空气分配系数.多环芳烃(PAHs)和多氯联苯(PCBs)因其来源多样性广以及对水生生物的毒性强而受到了国内外很多学者的关注[17].本文以部分PAHs和PCBs的logKPDMS-W实测值为样本,利用TLSER建立模型,对部分有机污染物KPDMS-W值进行预测与表征.
1 材料与方法
1.1 数据集
通过查阅文献[18-21]并整理得到本次1个数据集共109种化合物的KPDMS-W实测值,其中包含了84个PCBs和25个PAHs.所建模型的泛化能力可通过将化合物划分训练集和验证集进行体现,在109种疏水性有机污染物中随机选择80%的化合物作为训练集,剩余20%的化合物作为验证集进行预测检验.
1.2 分子结构描述符的计算
在计算分子结构描述符前,首先利用ChemBio 3D Ultra 12.0软件生成数据集中所有化合物的初始分子结构,其次,运行Minimize Energy将化合物最小能量化以模拟该化合物在自然界中最稳定状态,利用MOPAC 2016模块中的Mopac Interface PM7算法[22]对化合物结构进行优化并计算,从输出文件中提取5个量化描述符(α,εb,εa,q-,q+),最后运行PaDEL-Descriptor[23]软件得到各化合物的分子结构描述符,提取其中McGowan特征体积描述符.
1.3 TLSER模型的构建
TLSER模型是基于LSER理论,同时结合量子化学方法提出和发展起来的一种理论模型[14],其表达式如下:
KPDMS-W=k+aV+bα+cεb+dq-+eεa+fq+
式中,V为分子McGowan体积;α为分子极化率[16];εb表征氢键碱度;εa表征氢键酸度[24];q-为分子最负的原子净电荷;q+为分子最正的原子净电荷;a、b、c、d、e和f为多元线性回归系数[25];k为常数项.
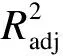
1.4 模型的表征
(1)
(2)
(3)
(4)
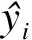
采用基于模型本身验证过程中计算得到的标准残差δ和leverage值定义的Williams图[17]表征预测模型的应用域.δ、H、hi及警戒值h*的计算公式如下:
(5)
H=X(XTX)-1XT
(6)
(7)
h*=3(m+1)/n
(8)
(9)
式中,X为n×mn×m的矩阵,表征了模型中训练集化合物的描述符空间;hi为第i个化合物的杠杆值;xii为第i个化合物分子结构描述符的行向量;SEM为均值标准误差.
2 结果与讨论
2.1 最优模型及表征
最优模型表达式为
logKPDMS-W=2.658V+51.89εb-3.11
(10)
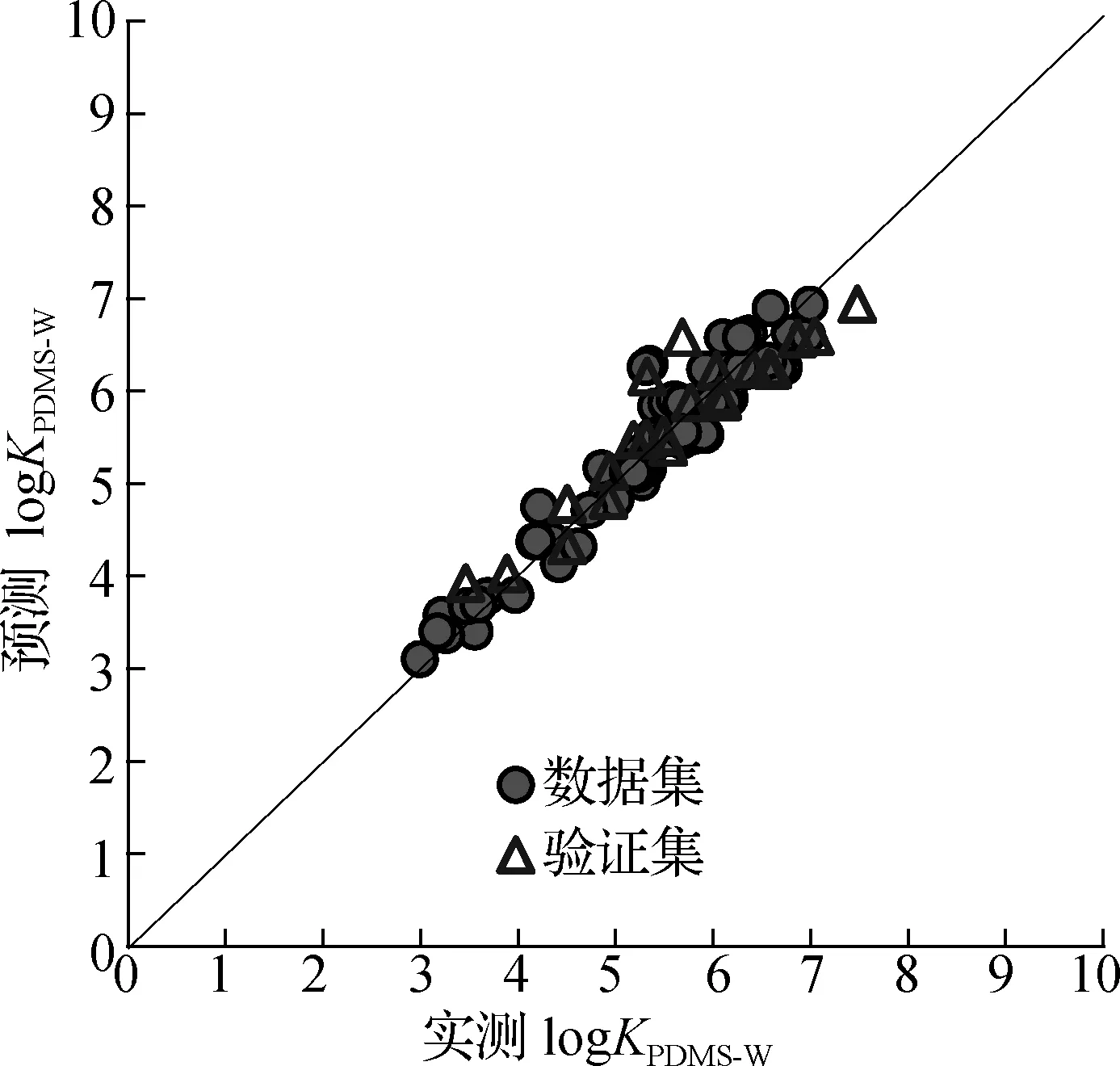
图1 logKPDMS-W实测值与预测值的拟合关系
2.2 应用域表征
如图2所示,本文TLSER模型采用Williams图来表征其应用域.若有机污染物的标准残差δ落在(-3.0,+3.0)以外,则认为该点是离群点.由图2可见,模型中除一个化合物为离群点外其余所有化合物都在应用域中,训练集和验证集中化合物的标准残差|δ|≤3,且这些化合物的杠杆值h均小于警戒值h*=0.103,可见训练集和验证集都具有较高的代表性.而仅有一个离群点可能是由于该化合物实验值本身存在误差而偏离了本模型应用域.因此TLSER模型能对应用域内其他有机污染物分配系数的logKPDMS-W值进行预测.
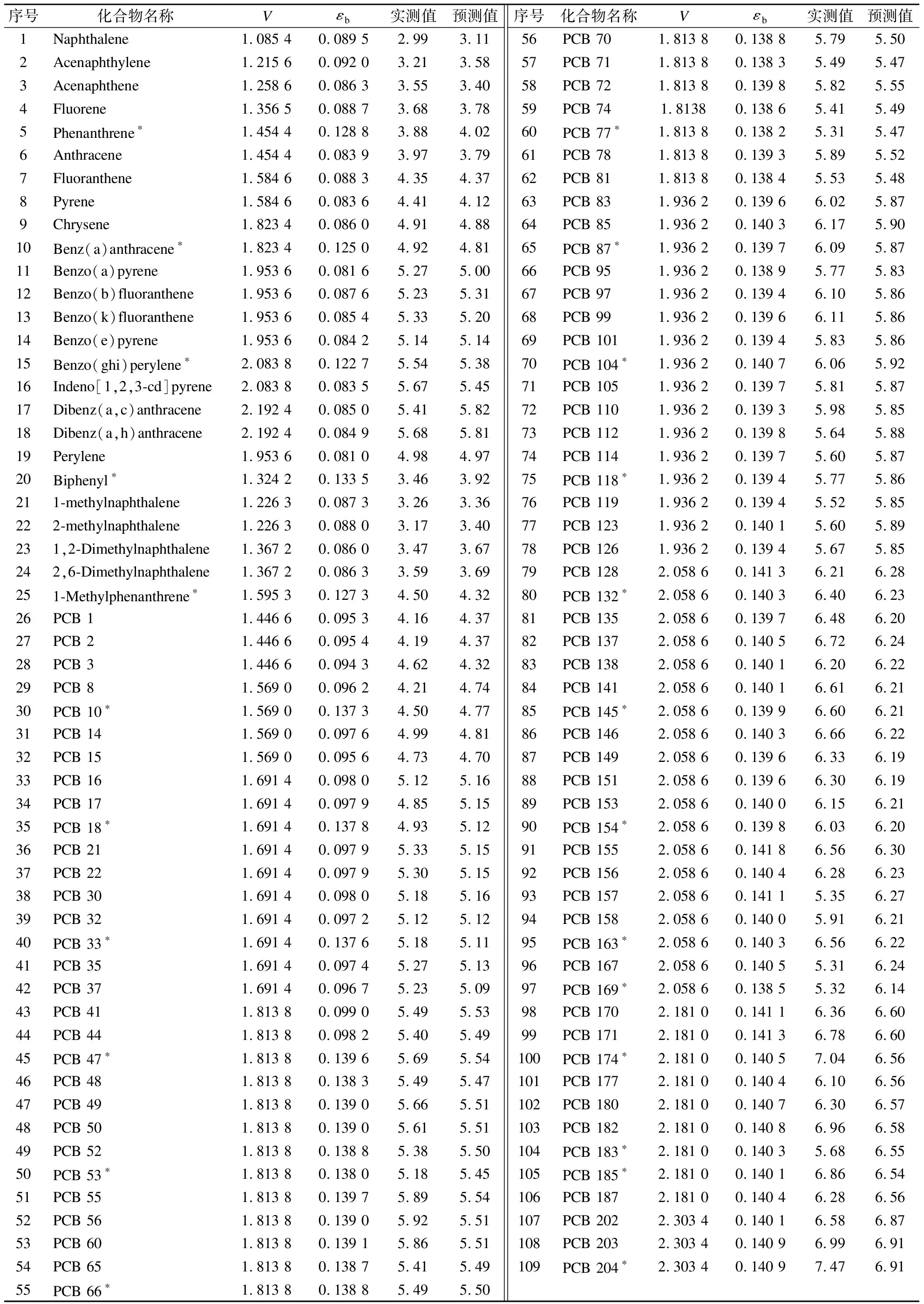
表1 数据集中化合物的logKPDMS-W值
注:*表示化合物为验证集.
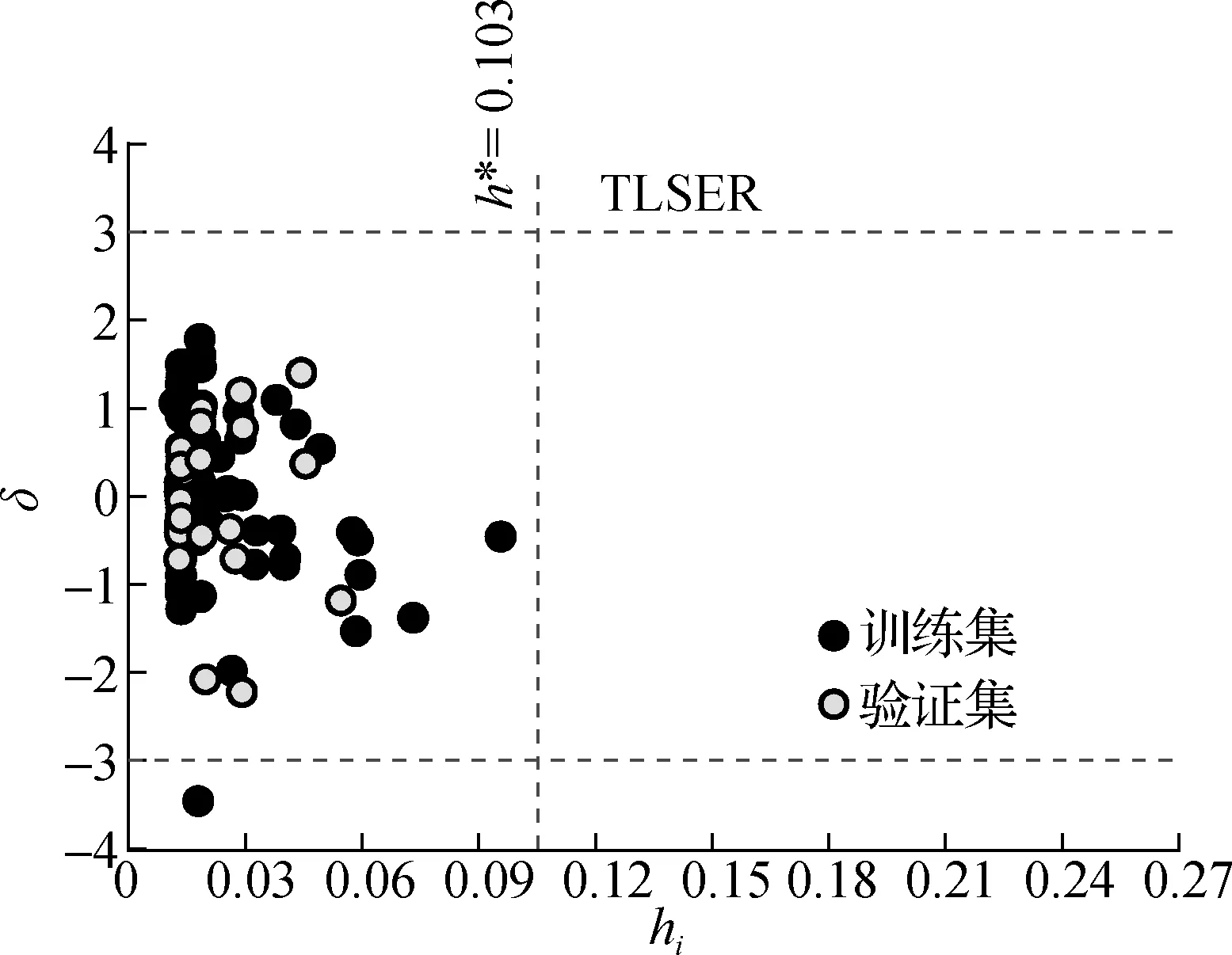
图2 TLSER模型的Williams图
2.3 机理分析
TLSER模型中包含2个分子描述符,即McGowan特征体积V和氢键碱度εb.氢键是由价键和静电2部分构成[29],εb表征分子提供质子或接受电子对的能力,在本模型中εb与logKPDMS-W值呈正相关.因此,当溶质分子作为氢键受体时,氢键碱度越小,与水的氢键相互作用越弱,logKPDMS-W值就越大,化合物分子也就更容易分配到被动采样材料相中.
McGowan特征体积V表征空穴形成作用,系数为正值.由于水分子排列高度有序且凝聚性强[30],而PDMS空间位阻较大使其凝聚性较弱,故化合物在PDMS中形成空穴的能量远小于其在水中形成空穴的能量.因此,化合物分子更容易通过空穴形成作用分配到采样材料相中.
2.4 模型比较
将本文构建的TLSER模型与前人研究PAHs和PCBs的模型进行比较,结果见表2.由表可得,数据集中化合物数量的增多会引起模型预测能力的降低,且前人模型中描述符主要为Kow.前文提到,目前针对化学结构相似化合物的Kow值在小范围内与KPDMS-W值呈良好的正相关关系,而在大范围内并没有呈现良好的线性关系.因此,利用Kow作为描述符建立的模型,其预测能力不能满足目前对其他化合物KPDMS-W值的预测需求.本模型利用2个参数(V和εb)弥补了Kow作为描述符的部分局限性,对同种化合物(如文献[9]中的PCBs)有更高的拟合度,而且,数据集中化合物更加丰富,化合物的实测值跨度更大,应用域也更加广泛.同时,与文献[33-34]中2种模型相比,本模型针对PAHs和PCBs这2类化合物进行了研究,补充了针对2类化合物KPDMS-W值的模型预测方法.因此,本模型与前人预测模型相比,优点在于描述符数量少,数据集中化合物数量多且预测结果准确性高,具有良好的拟合优度和预测能力.
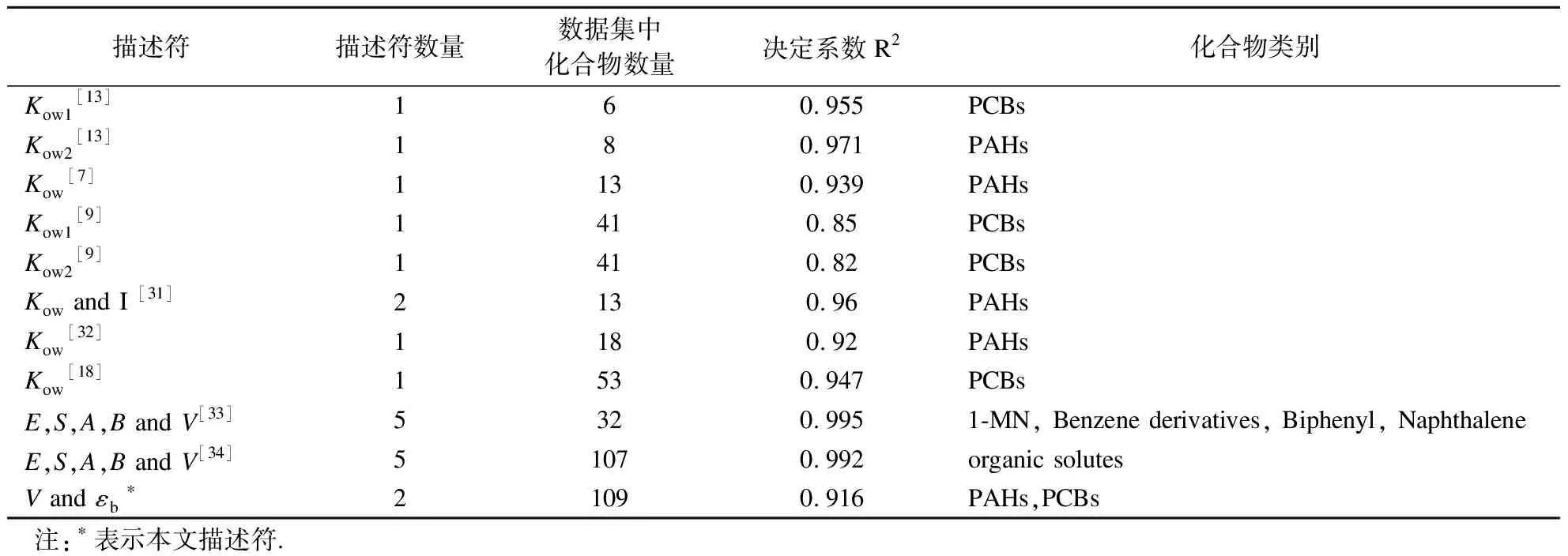
表2 模型比较
3 结论
1) 采用理论线性溶解能关系,构建了PCBs和PAHs两类共109种疏水性有机污染物PDMS膜水分配系数的预测模型.
3) 模型具有较少参数(V和εb)的同时包含更加丰富的数据集,化合物的实测值跨度大,应用域广泛,对PCBs和PAHs这2类化合物预测精度较高,可用于预测在应用域范围内其他与这2类化合物结构相似的有机污染物的KPDMS-W值.
