基于激光雷达和摄像头信息融合的车辆检测算法
2020-01-15,,
,,
(长安大学电子与控制工程学院,陕西 西安 710064)
0 引言
无人驾驶汽车能够提高交通系统运行效率和安全性,已经成为未来世界交通发展的主流方向。在对无人车的研究中,车辆检测是保证无人驾驶汽车安全行驶的关键。目前对车辆检测的研究主要集中在利用图像数据进行检测。
目前基于视觉的目标检测方法主要以深度学习为主[1]。通常将基于深度学习的目标检测方法分为2类:两阶段和一阶段的方法。两阶段的目标检测方法又称为基于区域的目标检测方法,经典模型有R-CNN[2],Faster R-CNN[3],MS-CNN[4],SubCNN[5]等。两阶段的目标检测方法具有很高的检测精度,但是检测速度较慢,不能满足实时性的要求。为了提高检测速度,一阶段的目标检测方法孕育而生。其无需产生候选框,直接从图像得到预测结果。虽然检测精度有所降低,但是整个过程只需要一步,极大缩短了检测时间,实现了实时检测。其代表模型有SSD[6]和YOLO[7]。
然而摄像头却易受到光线、探测距离等因素的影响。无法稳定地应对复杂多变的交通环境下车辆检测任务,无法满足无人驾驶汽车稳定性的要求。而激光雷达具有探测距离远、不受光线影响并且能够准确获得目标距离信息等优点,能够弥补摄像头的缺点。
在此,提出了一个实时鲁棒性融合方法,将激光雷达点云和图像进行融合处理,提高了目标检测的精度,而且具有很强的抗干扰性。
1 融合检测方法
整个系统由3部分组成,分别为深度补全、车辆检测和决策级融合。系统整体结构如图1所示。
首先通过摄像头与激光雷达联合标定,将激光雷达三维点云转换为稀疏二维深度图,再通过深度补全将其补全为密集深度图,使激光点云数据和图像具有相同的分辨率,并且在空间、时间上彼此对齐。而后将彩色图像和激光雷达密集深度图分别输入YOLOv3检测框架,得到各自检测车辆的边界框和置信度。最后通过边界框融合和改进的DS证据理论得到最终检测结果。

图1 系统整体结构
1.1 深度补全
在深度补全之前,需要先进行预处理操作,将三维激光点云转换为二维稀疏深度图。在预处理过程中,要将激光雷达和摄像头进行精确校准和联合标定,从而可以精确地将每个三维激光雷达点云帧投影到二维彩色图像平面上,形成稀疏的深度图。传感器之间的坐标转换关系如图2所示。
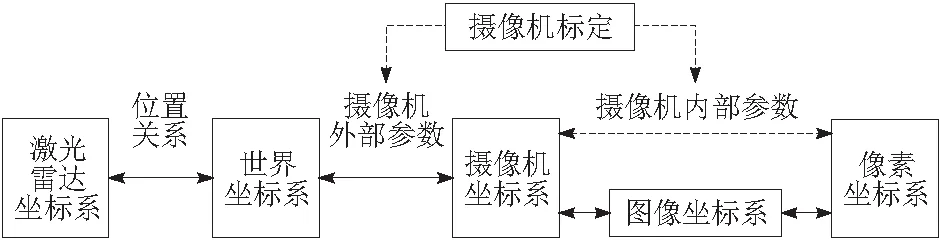
图2 图像与激光雷达转换关系
在预处理工作完成之后,再将稀疏深度图通过深度补全转换为密集深度图,使其和相机具有相同的分辨率。深度补全方法可以分为2种:通过图像引导的深度补全和无需图像引导的深度补全。由于摄像头能够采集到清晰的高分辨率图像,可以帮助区分物体边界和连续平滑表面,所以图像对于指导深度补全是很有效的。因此本文提出了一种通过图像引导的深度补全方法。
本文的深度补全方法主要基于2个假设:认为距离相近的像素点有着相似的深度值;认为相似的颜色区域具有相似的深度值。
对于所有深度未知的像素点,深度值Dp为
(1)
归一化因子Wp为
(2)
G为高斯函数;p和q是像素点的坐标;I为图像的像素值;D为与图像对应的深度值;Ω为高斯函数的核;σI,σD分别是颜色、距离的高斯函数的σ值。
1.2 车辆检测
本文选用YOLOv3进行车辆检测,YOLOv3在2个训练集(彩色图像和密集深度图)上分别进行训练,最终得到2个训练好的模型。
YOLO全名You Only Look Once,是一个最先进的实时目标检测系统。发展至今,已经经过了3个版本的迭代。YOLO的前两代模型YOLOv1和YOLOv2运行速度极快,能够达到以45帧/s的速率处理图像,缺点是精确度比较低。YOLOv3的出现弥补了前两代对小目标的检测能力差的问题,而且保持了它的速度优势。YOLOv3在COCO数据集上得到mAP值为57.9%,比SSD和RetinaNet的mAP值略高,但是运行速度比它们快2~4倍,比Fast R-CNN快100倍,比R-CNN快1 000倍。
1.3 决策级融合
本部分依据深度图像和彩色图像在YOLOv3中的检测结果,将得到的边界框信息和相应的置信度进行融合,从而得到最终的检测结果。
首先将边界框进行融合,通过判断深度图像目标边界框和彩色图像目标边界框交并比(IOU)的大小,选择不同的融合策略:当交并比小于0.5时,认为是2个独立的检测目标,不进行融合;交并比在0.5~0.8之间时,2组边界模型没有完全重合,将重叠区域作为最终目标区域;交并比在0.8~1之间时,2组边界模型基本上完全重合,此时认为所有的模型边界都是有效的,将边界框的扩展区域作为新的检测区域。融合示例如图3所示,其中点划线区域表示深度图像检测到的边界框,实线区域表示彩色图像检测到的边界框,阴影区域为融合后最终的检测结果。
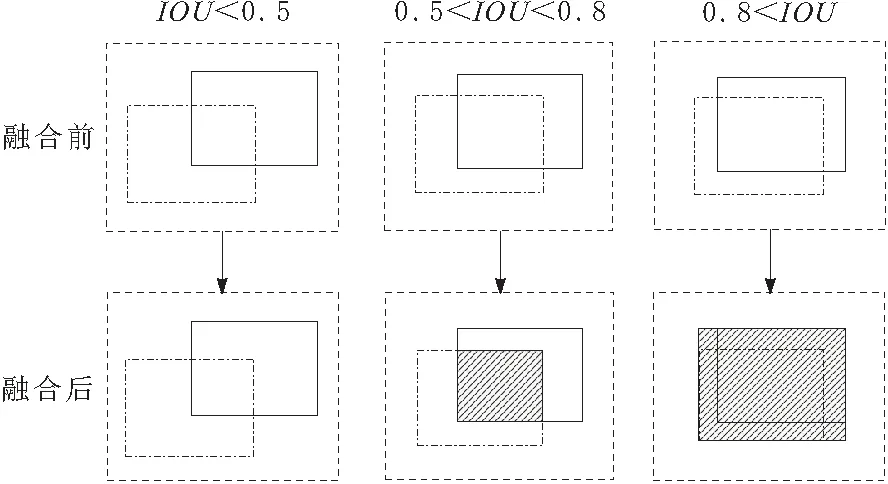
图3 边界框分类融合示意
融合后边界框的置信度,以原始边界框相应的置信度为基准,通过改进的D-S证据理论进行计算。D-S证据理论[8]是一种非精确推理理论,是多传感器信息融合最常用的方法之一,十分适用于决策级信息融合。算法具体流程如下。
设Θ为一辨识框架,且满足:
m(φ)=0
(3)
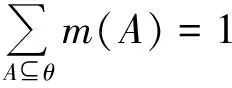
(4)
m∶2θ→[0,1],其中2θ为Θ的所有子集构成的集合,称m(A)为A的基本概率分配(BPA),也称mass函数。
假设在辨识框架Θ下有2个证据E1和E2:E1的基本概率赋值和焦元分别是m1和A1,A2,…,Ak;E2的基本概率赋值和焦元分别是m2和B1,B2,…,Bk。根据Dempster的组合规则,可以将上述证据进行融合。
m(A)=m1⊕m2=
(5)

但是当Dempster的组合规则被用来组合高冲突的证据时,可能会产生一个错误的结论。因此本文采用Murphy的改进方法以克服其局限性。该方法完全忽略了证据之间的冲突和联系,将各个证据的基本概率赋值求平均值,得到平均证据。然后利用D-S证据理论组合规则对平均证据进行合成。计算过程如下。
假设有n个证据,对证据进行平均,得到期望证据
(6)
然后将利用D-S证据理论对期望证据M迭代组合n-1次后的结果作为最终的合成结果。
2 实验
本文在KITTI数据集上对算法进行评估,KITTI数据集是目前世界最大的自动驾驶场景下计算机视觉评测数据集。采集车上装备有彩色相机和Velodyne HDL-64E激光雷达。实验测试平台配备有Intel Xeon E5-2670 CPU和 NVIDIA GeForce GTX 1080Ti GPU。
KITTI目标检测数据集包含有7 481帧训练数据和7 518帧测试数据。每一帧数据包含有彩色图片和与其同步的激光雷达数据。
2.1 深度补全实验
由于本文选用KITTI数据集,它提供了激光雷达和摄像机的标定数据,包括激光雷达坐标系到摄像机坐标系刚体变化矩阵Tr_velo_to_cam、摄像头内参矩阵P以及摄像头矫正矩阵R0_rect等参数。通过式(7)可以将激光雷达点云投影到相机平面上形成稀疏深度图。
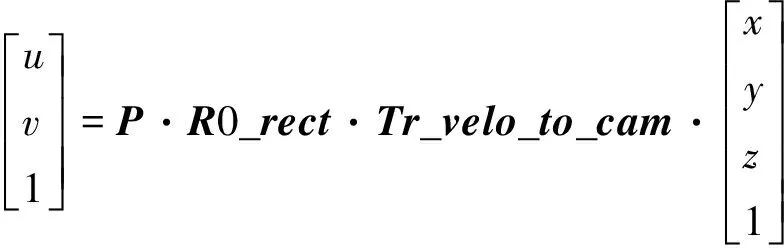
(7)
u和v为相机坐标;x,y,z为激光雷达三维坐标。
稀疏深度图转换结果如图4所示。在融合图中可以清楚地在柱子处看出激光和图像已经完美对齐。而在稀疏深度图中,很难直接得到有用的信息。
深度补全结果如图5所示。由图5可以看出补全图像的边缘轮廓更为清晰,很容易看到车体的基本轮廓。

图4 三维激光雷达转换为二维稀疏深度

图5 密集深度示意
2.2 车辆检测及融合实验
本文将彩色图像和密集深度图分别在YOLOv3中进行训练,并将彩色图像和密集深度图得到的结果进行融合。本文和KITTI数据集的评价方法保持一致,采用平均精度(AP)和IOU来评估检测性能。当IOU重叠阈值大于0.7时,认为检测成功。并且将整个数据按照边界框盒子的大小、截断程度和可见程度分为简单、中等以及困难3个不同的难度水平分别进行评估。表1展示它们的AP值。从表1中可以看出这3种图像都有着良好的检测精度,并且通过融合之后,提升了精确度。融合检测的结果和图像检测的结果相比,在简单、中等、复杂上AP值分别提高了2.46%,2.42%和1.56%。

表1 检测器性能评估 %
融合检测过程的示例如图6所示。图像从上至下为彩色图像的检测结果(实线)、密集深度图的检测结果(点划线)、前两者的融合过程、融合结果(双点划线)以及真实值(虚线)。由图6可以看出单独通过彩色图像和密集深度图都可以得到较好的检测结果,并且综合考虑了两者的检测优势,通过融合之后,最终得到了更为精确的结果。

图6 融合检测过程示意
为了进一步评估所提出算法的有效性,在KITTI数据集上和其他先进的车辆检测方法进行了比较,比较结果如表2所示。
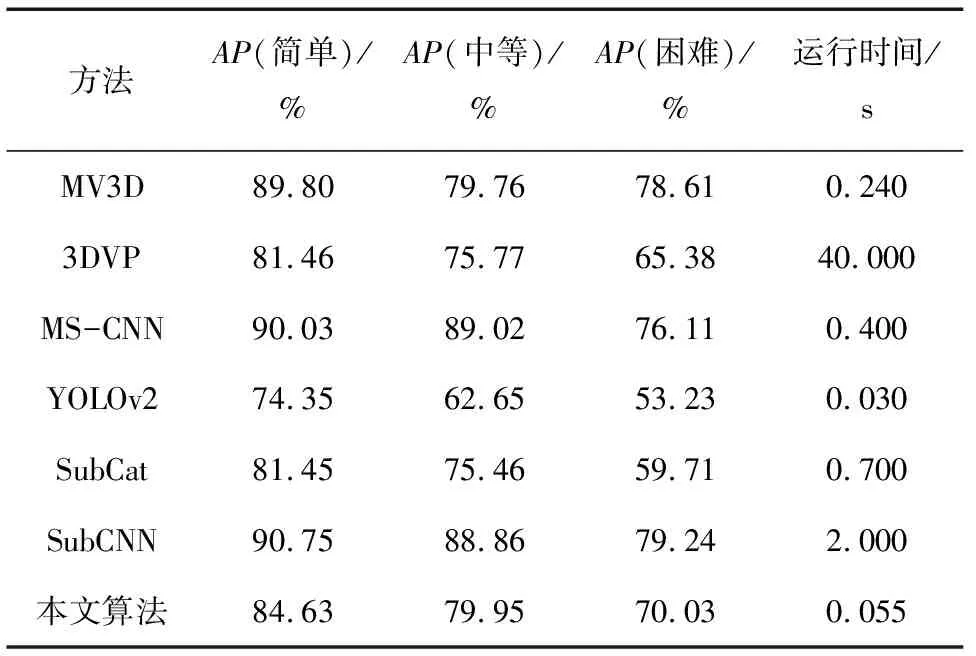
表2 本文算法和其他先进算法对比结果
在精度方面,以中等难度进行排名,本文算法在7种算法中排名第3,已经达到了很高的检测精度,完全满足实际应用的要求。
在速度方面,本文算法有着0.055 s的极快检测速度,仅比YOLOv2慢了0.025 s,但是平均检测精度却比它高出14.8%。和比它检测精度高的MS-CNN,SubCNN算法相比,分别快7倍和36倍。
综上所述,本文算法与其他模型相比,已经达到了先进的检测精度,并且拥有着很快的检测速度,另外还具有很强的抗干扰能力,因此完全能够胜任无人车车辆检测任务。
3 结束语
提出了一个实时鲁棒性融合框架,将激光雷达点云和图像通过深度补全、车辆检测和决策级融合3个步骤实现了快速稳定的车辆检测。实验结果表明,本文提出的深度补全算法对于提高激光雷达数据的分辨率以及后续的车辆检测是很有帮助的,并且相对于彩色图像的检测结果,本文所提出的决策级融合方案平均检测精度提高了2.15%。每帧数据的处理时间只需0.055 s,远小于人类驾驶员0.2 s的反应时间,完全满足实时性要求。与单传感器车辆检测相比,本文提出的融合方法不仅显著提高了车辆检测的检测率,更重要的是提高了整个系统的鲁棒性。而且本文的深度补全算法和决策级融合方法在机器人、机器视觉和传感器融合领域也有通用性。
