文档图像识别技术回顾与展望
2020-01-15刘成林
刘成林
1.中国科学院自动化研究所,模式识别国家重点实验室,北京 100190 2.中国科学院大学,人工智能学院,北京 100049 3.中国科学院脑科学与智能技术卓越创新中心,北京 100190
引言
文字是人类社会交流和通信中必不可少的信息载体,在社会生活和互联网上大量存在,其中现实空间中的文字都以图像形式存在(通过扫描或拍照变成图像),互联网上以图像或电子文本(计算机内码)形式存在。把图像中的文字检测识别出来,转化为电子文本,是计算机文字处理和语言理解的需要。这个过程称为文档图像识别,简称文档识别或文字识别,或称为光学字符识别(OCR)。
在当今大数据时代,文档识别技术有巨大的应用需求,因为数量巨大的图像中的文字需要识别转化为电子文本。应用场景(文档图像来源)主要有如下几种:
(1)纸质文档电子化:纸质文档在现实生活中大量存在,包括过去出版的各种书籍(包括年代久远的古籍,基本为手写字体)、杂志、报纸等,绝大部分是数字出版和网络化时代之前就有的,没有对应的电子版,需要通过自动识别电子化。
(2)档案、信件、笔记等,这也属于纸质文档,但不是公开出版物,而且文档版式和字体有一些不同特点。
(3)票据、卡片、证件等,在金融、保险、财务、法务等行业中大量存在,过去靠人工录入电子化的方式代价极大,劳动力资源趋紧之后难以为继。
(4)车牌、标识、标牌等,现实社会中大量存在,自动识别技术对智能交通、地图信息采集、社会管理等非常重要。
(5)网络场景图像和合成文档图像:互联网(包括移动互联网,社交媒体如微信、微博等)上有大量用户上载的自然场景图像(其中相当一部分有文字)和合成文档图像(如合成文本图像、自然图像中嵌入文字等),文字检测识别是信息检索和语义分析的必要步骤。
(6)联机手写文档:在数码版、触摸屏(如手机触屏)上书写或用数码笔在纸上书写时产生的笔划轨迹数据。跟文档图像相比,笔划轨迹对文字识别能提供更多的特征,但联机手写文档中笔迹潦草、图文混合等也是挑战性问题。
从文档图像到输出电子文本或文档结构表示,文档识别过程包括几个主要步骤:(1)图像预处理:通过滤波、去噪、形状矫正等改善图像质量,使得文字或图形更容易提取;(2)版面分析:分割图像中不同段落、图形区域并分析它们之间的位置关系,表格分析、场景图像中文本检测可以看作是特殊的版面分析问题;(3)文本识别:将文本段落或文本行转化为电子文本,一般是以一个文本行作为对象进行识别(同时进行字符切分和识别,因为字符切分和识别难以分开进行);(4)后处理或语义分析:利用语言上下文信息(如领域相关的语言模型或词典)或几何关系修正文本识别结果,或从文档提取语义信息(如命名实体、关系、事件等),语言模型和词典经常被直接用在文本识别中,利用语法语义知识来减少文本识别的歧义。
文档图像作为一种非结构化数据,其分析识别面临一些技术难点:(1)复杂版面分析:对于图文混合、区域形状不规则、变形文档图像的版面分析,不管是基于规则的方法还是机器学习的方法,都难以完全正确分割;(2)场景文本检测:自然场景图像的背景复杂、光照和拍照视角变化、文本行方向和形状变化、字体风格和颜色变化等,都导致文本与背景的区分和文本准确定位提取非常困难;(3)文本识别:手写文本行识别由于文字类别多、书写风格因人而异、字符难以切分等问题,是传统的难题,多方向、多语言文本行混合等问题带来了新的困难;(4)表格和公式识别:这是文档分析中常见的问题,表格结构变化多样、表格线不清楚或无格线导致表格分析困难,公式(数学公式、物理化学公式)由于结构复杂且变化多样,正确识别公式中所有符号及其相互关系是很难的问题。
本文在介绍文档识别背景的基础上,简要回顾该领域研究历史,介绍一些代表性方法和最新进展,分析当前技术存在的问题,最后展望未来研究和应用趋势。
1 研究历史回顾
文字识别作为模式识别领域的一个研究方向,是在电子计算机出现之后,在20世纪50年代以后与模式识别、人工智能领域一起发展起来的。但是在电子计算机出现之前,早在20世纪20年代就出现了用光学模板匹配进行文字识别的专利。现有OCR技术都是基于电子计算机(包括智能手机、移动终端等)实现的。早期文字识别的对象主要是印刷体数字和英文字母,方法以统计模式识别和特征匹配为主。后来开始手写数字、字母和印刷体汉字、手写体汉字识别的研究,研究中形状归一化、特征提取、分类器等技术受到高度重视。80-90年代也提出了一些结构分析方法,并且字符切分、字符串识别和版面分析受到重视。在那之前,文字识别中假设文档版面比较简单规则,版面分割和字符切分是比较容易的,因此主要精力放在单字识别上面。90年代,文档识别领域的主要会议,国际手写识别前沿研讨会(IWFHR,后改名为ICFHR)、国际文档分析与识别会议(ICDAR)、国际文档分析系统研讨会(DAS)相继发起并周期性(均为两年一次)举办至今。21世纪以来,文档分析和识别的各个方面技术继续发展,性能持续提高;尤其是近年来,互联网大数据、GPU并行计算支撑深度学习(深度神经网络)快速发展,文档分析和识别中基于深度学习的方法带来性能快速提升,全面超越传统方法,甚至在手写字符识别等方面的精度超过人类水平。表1列出文档识别历史上主要方法、识别对象的发展演变及相关历史事件。
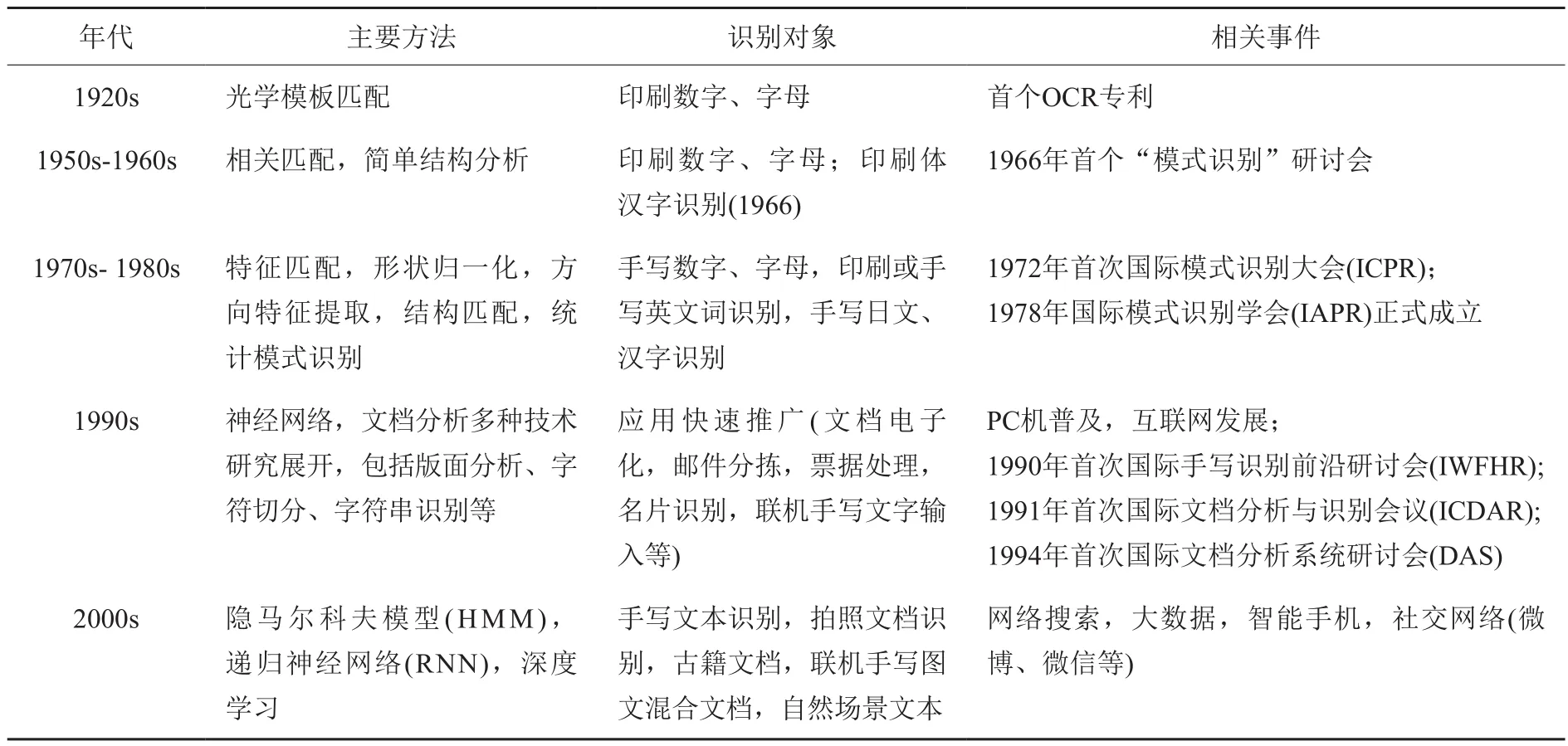
表1 文档识别方法、对象历史演变和相关事件Table 1 Summary of main document recognition methods and events
2 研究现状
下面对文档识别系统中主要方法进行回顾,然后介绍一些代表当前识别水平的实验结果。
2.1 主要方法
文档识别领域对图像预处理、版面分析、字符识别和文本行识别、图形符号识别、文档检索等技术环节都提出了大量的方法。下面简要综述预处理、版面分析、字符识别和文本行识别的主要方法。文档识别早期研究和应用情况可从文献[1]了解。
图像预处理的目的是改进图像质量,以提高文字提取和识别的性能。一般来说,扫描纸张图像清晰度较高,早期的研究主要解决因文档放置不当、卷曲等带来的扫描图像旋转、变形、边缘噪声等问题。近年来,随着数码相机和智能手机应用普及,拍照纸张文档越来越多,文档图像变形、光照不均、视觉变形等问题越来越多,因而出现了一些针对拍照文档图像预处理的工作,如文献[2]。历史文档(古籍)因年代久远,纸张污损、笔迹褪色等因素导致图像噪声严重、笔迹对比度低,因此图像去噪、增强等研究受到重视。最近,基于深度学习的文本检测和识别方法对噪声、变形文档的适应能力越来越强,图像预处理变得没有过去那样重要了。
版面分析的目的是把图像中文本区域和图形、背景区域分开,分析不同区域之间的位置关系,并区分文本段落、文本行,区分手写文本和印刷文本等。对图像进行区域分割和几何关系分析的过程被称为几何版面分析,对图像区域进行更细致的逻辑(如阅读顺序、区域语义类别)分析的过程称为逻辑版面分析。版面分析是非常重要的一步,因为文本识别之前先要定位分割文本区域。复杂版面文档的分割非常困难。复杂性体现在:图文混合、非矩形文档区域、复杂背景(如文字与物体、图形重叠)、手写印刷混合等。另外,文档变形、光照视角变化、污损退化等也给版面分割带来困难。上世纪80年代以来,版面分析方面提出了很多方法[3-4],大体可分成两大类:自上而下的方法和自下而上的方法。自上而下的方法把文档图像从大到小进行划分,如最简单的投影和X-Y Cut方法[5]。这种方法对不规则文本区域和文档图像变形的处理能力较差。自下而上的方法从较小的图像元素(像素、连通成分)逐步合并成较大的文本或图形区域,对不规则版面有更强的适应能力,但相应地计算也比较复杂。早期的自下而上方法包括Smearing、纹理聚类、Document Spectrum(Docstrum)[6]、Voronoi Diagram 方 法[7]等。近年来,结合神经网络和概率图模型对连通成分分类的方法[8]在多种类型文档的版面分割中都取得了较好的效果。对于文本与背景难以区分(难以进行二值化)的图像,最新的趋势是采用全卷积神经网络(FCN)直接进行像素分类,如文献[9]。
自然场景文本检测[10]可以看作是一个特殊的版面分析问题。场景文本检测与识别有广泛的应用需求,加上图像背景复杂,光照、视角、字体、颜色、语种等变化多样带来的难点,过去十年吸引了大量的研究者。场景文本检测的方法也可分为自下而上的方法和自上而下的方法,两类方法各有优劣。自下而上的方法基于文字或连通成分检测,然后聚合成文本行,典型的如SegLink[11]。自上而下的方法用类似物体检测(Object Detection)直接检测文本行,给出文本行的边界,但针对任意方向文本行和长宽比,需要设计特殊的模型和学习方法,如直接回归方法[12]。最近对形状弯曲的所谓任意形状文本检测吸引了很多研究,典型的方法如TextSnake[13]、自适应区域表示[14]。
文字识别研究早期主要关注单个字符图像的识别,尤其是手写汉字识别。因为字形复杂、类别数巨大(常用字5000类以上),单字识别本身就是一个比较难的问题,不像英文识别早在上世纪80年代就开始关注词识别问题了。手写汉字识别方面,上世纪80~90年代提出了一些有效的字形归一化、方向特征提取、统计分类和神经网络分类方法,笔划提取和结构匹配也取得了很大进展,但对于自由手写汉字识别的精度一直不高。直到2013年,在一个新数据集上采用传统特征提取和分类方法得到的识别率才达到92%[15]。在2013年以后,深度神经网络(主要是卷积神经网络CNN)逐渐占据主导地位[16],在2013年中文手写识别竞赛中就取得了优胜的成绩[17],目前性能已全面超越传统方法。深度神经网络结合传统方法也可能产生好的效果,如CNN结合方向特征提取,可在不需要样本增强的情况下得到更高识别精度[18]。
文档识别中更重要的问题是文本行识别。由于字符形状、大小、位置、间隔不规则,字符在识别之前难以准确切分,因此字符切分和识别必须同时进行,这也就是文本行识别的过程。上世纪80年代,对日文手写字符串识别、英文词识别、手写数字识别等提出了基于过切分和候选切分-识别网格[19]的方法。这种方法的好处是可以明确给出字符的切分边界,至今在中文手写文本行识别中仍具有优势[20]。结合深度学习分类器(主要是CNN),基于过切分的文本行识别方法可以得到优异的识别性能[21]。上世纪90年代,基于隐马尔科夫模型(HMM)的方法在英文手写词识别中开始流行[22-23]。这种方法的好处是可以在词标注(无需给出每个字的位置)的样本集上进行弱监督学习。后来,基于长短时记忆(LSTM)递归神经网络(RNN)的模型在英文和阿拉伯文手写识别中性能超越HMM[24],逐渐成为手写词识别和文本行识别的主导方法。结合CNN(用于图像特征学习)的RNN近年用于场景文本识别[25]和手写文本识别都取得了领先的性能。基于滑动窗CNN分类的方法在场景英文词识别[26]和中文文本行识别(因字符类别数大,RNN模型复杂、训练困难)中都比较有效。基于RNN的中文文本行识别方法也取得了新的进展并成功应用于联机手写文本行识别[27]。基于过切分、滑动窗和RNN的文本行识别方法都还在继续发展,在弱监督学习、小样本泛化、自适应等方面继续提高。
2.2 性能状况
学术界发表的论文中公布了很多在公开数据集上的测试结果。近年来,文档识别领域的会议,如国际文档分析与识别会议(ICDAR)、国际手写识别前沿会议(ICFHR)组织了一系列竞赛,评价不同方法的性能,其中也公布了一些新的数据集。竞赛的任务包括图像预处理(如二值化)、版面分析、场景文本检测与识别、多语言文本识别、后处理(如OCR结果校正)、公式识别、表格分析等。这里重点介绍一下手写文本识别方面的数据集和结果。
英文手写文档数据集最有代表性的是瑞士伯尔尼大学发布的IAM数据集[28],最早在1999年ICDAR上发布,包含657人书写的1539页文档,13 353个文本行,115 320个手写词。使用较广的法文手写数据集是RIMES[29],包含1300人书写的12 723页文档。英文和法文识别测试一般有两种方式:词识别(假设词已经分割出来)、文本行识别(整行识别,没有给出词的边界),都用词错误率(WER)和字错误率(CER)来衡量性能。一些最新结果见文献[30]。其中,IAM数据集上,行识别的情况下,WER最好为17.82%,CER最好为5.7%;RIMES数据集上,行识别WER最好为9.6%,CER最好为2.3%。
中文手写文档识别方面比较有代表性的数据集是中国科学院自动化研究所发布的CASIA-HWDB(脱机手写字符和文档数据集)和CASIA-OLHWDB(联机手写字符和文档数据集)[31]。这两个数据集是用数码笔在纸上书写同时得到联机笔划轨迹数据和脱机图像(纸张扫描得到)。数据库总共有1260人书写、总字数600多万字的联机和脱机手写汉字样本及手写文本数据。其中1020人的数据对学术界公开共享,联机和脱机数据集分别分为三个单字样本数据集DB1.0-1.2和三个手写文本数据集DB2.0-2.2。DB1.0-1.2包含约390万个手写单字样本(7356类,其中汉字7185类),DB2.0-2.2包含约5090个文档和135万个字符样本。一些单字样本和手写文本页面例子见图1和图2。

图1 CASIA-OLHWDB和CASIA-HWDB数据集中的手写单字样本示例(左:联机,右:脱机)Fig.1 Character samples in the CASIA-OLHWDB and CASIA-HWDB(left:online,right-offline)

图2 CASIA-HWDB数据集中手写文本图像示例Fig.2 Samples of handwritten text page in the CASIA-HWDB
利用CASIA-HWDB和CASIA-OLHWDB数据集,在2011年和2013年举行了两次中文手写识别竞赛,其中2013年的竞赛包括联机、脱机单字和文本识别[17]。竞赛上发布的竞赛测试集(称为ICDAR 2013测试集)被广泛用来作为测试标准。ICDAR 2013测试集为60个人书写的样本,单字样本224 000多个,3755类;手写文本3432行,91 000多个字。单字识别性能用识别正确率衡量,文本行识别性能用字符正确率(文本行中被正确识别字符的比例)衡量。一些代表性的脱机单字识别正确率和文本行识别字符正确率见表2和表3。联机手写识别的性能可参考文献[27]和[32]。
实际应用中因场景、文档质量不同,识别性能跟标准数据集上的结果会有较大差异。对于图像质量清晰、书写规范的文档(如作文),识别正确率会比较好。而对于版式变化多、书写随意的文档,识别正确率会明显降低,而且版面分割或文本检测错误会导致一些文本行漏识或错识。
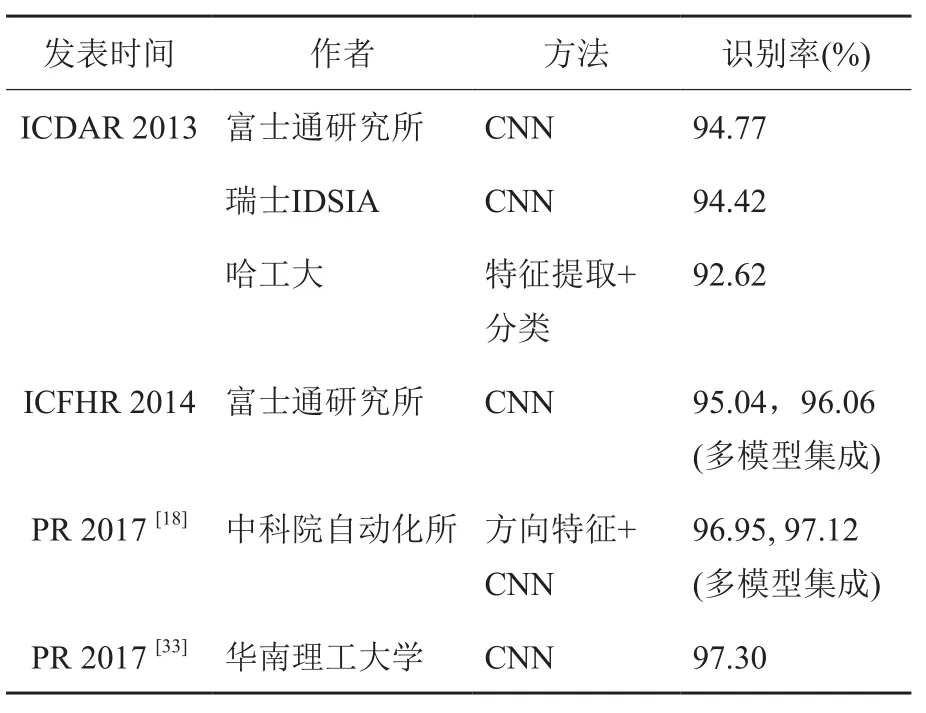
表2 ICDAR 2013竞赛测试集上脱机手写单字识别正确率Table 2 Character recognition accuracies on the test set of ICDAR 2013 Competition
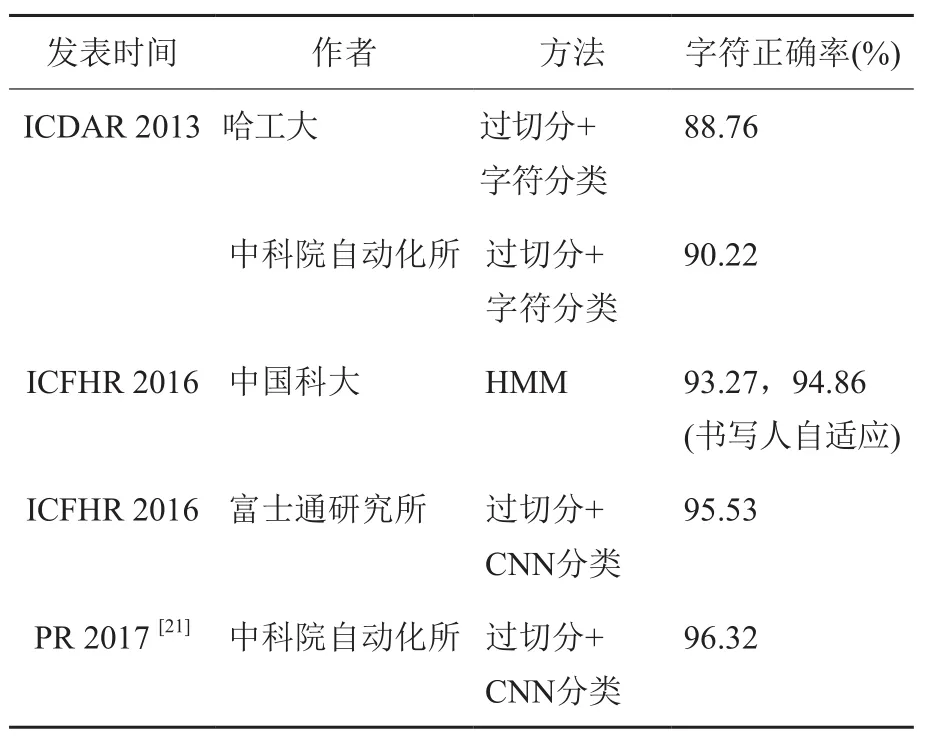
表3 ICDAR 2013竞赛测试集上脱机手写文本行识别字符正确率Table 3 Character-level accuracies of offline handwritten textline recognition on the test set of ICDAR 2013 Competition
3 存在问题与展望
可以看出,随着近年来深度学习方法的发展及在文档分析与识别中的应用研究深化,文档识别的性能不断提升。但在实际应用中发现,现有方法的性能还有很多不足,有些场合还不能满足应用的需求。主要问题:(1)复杂版面分析能力不足。版面样式变化特别多,用端到端深度学习方法难以解决任意版式文档的分割问题,而版式模板匹配的方法只能用于有限的版面样式。(2)识别精度和置信度不够。不仅自由书写和图像质量退化场合识别率会下降,而且即使对于识别率较高的场合也会因不能给出识别结果是否正确的置信度而标出置信度低的字符,不方便人工校对而导致用户认可度低。(3)小样本泛化能力不足。深度神经网络的泛化性能依赖大规模数据集训练。有些应用场合难以收集标注大量样本来训练识别模型,如保密或隐私保护程度高的场合(如银行票据),日常生活中不常见的文档(如古籍,而且中文古籍字类特别多)。这就要求在较少样本训练时仍能得到高识别率,而且能随着数据不断增加能增量式地学习。(4)图形符号识别性能不足。图文混合文档中存在的表格、公式、流程图、签名印章等还不能得到满意的识别性能。
文档识别领域跟整个人工智能领域一样,近年来在学术研究和工业应用方面都获得大量关注。这主要是因为在计算能力快速增长、智能手机和移动通讯快速普及的背景下,深度学习+大数据带动了文档识别性能的快速提升,文档识别的巨大需求逐步得到满足(过去不能用的现在可以用了)。但是在很多场合文档识别技术还不好用,系统开发需要大量人工调试,应用中对识别错误需要人工干预。由于应用需求持续存在,技术上的不足将推动学术和技术研究的进一步发展。未来将重点关注的研究问题包括:(1)复杂版面分析,包括区域分割和逻辑版面分析。表格分析是版面分析的一个特例。(2)字符结构分析,这在很多应用场合(如写字教育)有需求。(3)识别置信度估计和拒识,对难以识别、可能出错的字符标为拒识,是提高用户认可度的一个关键问题。(4)场景文本检测与识别,未来一段时间仍是研究热点。(5)多语言文本、印刷手写混合文本识别,这是一些应用场景的文档实际情况。(6)图文混合文档中图形符号识别,包括图表、公式、流程图、签名、印章等。在一些应用场景,这些元素的识别和数字化必不可少。
总的来说,文档识别领域过去60多年来在方法研究和应用上取得了巨大的成就。当前,文档大数据分析识别和数字化的需求持续存在,而现有技术还有很多不足。因此,未来在研究和应用上仍有很大的发展空间。
利益冲突声明
所有作者声明不存在利益冲突关系。
