人工智能计算与数据服务平台的研究与应用
2020-01-15王彦棡王珏曹荣强
王彦棡,王珏,曹荣强*
1.中国科学院计算机网络信息中心,人工智能技术与应用发展部,北京 100190 2.中国科学院大学,北京 100049
引言
世界各国在人工智能领域展开激烈竞争,人工智能已经成为国家战略。深度学习(Deep Learning,DL)是人工智能(Artificial Intelligence,AI)的重要研究方向,其概念最早由多伦多大学的G.E.Hinton等[1]于2006年提出,也是人工智能技术发展迅速的领域之一,帮助计算机理解大量图像、声音和文本形式的数据。无论是极大地扩展人工智能算法的规模以充分利用高性能计算(High Performance Computing,HPC)的AI-on-HPC模式,还是将人工智能的深度学习等功能加入到现有高性能计算工作流程的HPC-on-AI模式,都深刻揭示了人工智能与计算之间的相互依赖和相互促进的关系[2]。
人工智能的迅速发展依赖于大规模的计算资源,包括高性能计算资源[3]和GPU等专用计算资源[4]。大规模的人工智能训练任务必须依赖于海量的计算资源。GPU计算资源的稀缺性、运行和维护困难等问题,导致很多用户难于及时获取简单易用的足量计算资源。另外,很多研发人员也难于找到合适的计算平台测试和发布他们的应用软件。因此,本文重点讨论如何在异构和海量计算与存储资源的基础上,建设人工智能计算与数据服务平台,从而解决计算基础设施、通用平台和多学科领域应用服务的问题。
人工智能计算与数据服务平台的目标是研发和建设计算资源、存储资源和应用软件为一体的服务平台,综合运用虚拟化技术融合多种类型的异构资源并形成人工智能RaaS层基础服务;利用微服务和RESTful API接口等相关技术,结合人工智能技术在数据和计算方面的特征,形成人工智能PaaS层服务;综合分析人工智能模型、算法和应用的不同特征,形成人工智能SaaS层服务。
本文的后续内容安排如下:第1节介绍人工智能计算与数据服务平台的典型应用场景和用户类型;第2节讨论平台的功能服务,包括基本功能、特色功能以及非功能性的需求;在此基础上,第3节讨论中国科学院人工智能计算及数据应用服务平台(简称“中科院人工智能平台”)的架构和服务,包括平台软件架构、计算基础设施和多个服务;第4节介绍中科院人工智能平台的服务方式;最后,总结本文工作并指明下一步的工作计划。
1 应用场景和用户类型
近几年随着IT技术的快速发展特别是计算能力的快速增长,人工智能技术深刻影响着各个行业的发展,包括科研、教育、工程和国民经济的众多行业[5-6]。受此影响,人工智能技术有着很多的典型应用场景,也有很多的用户类型。本文仅讨论科研和教育领域的应用场景和用户类型,不包括其它行业领域。
1.1 应用场景
在设计人工智能计算与数据服务平台或者其它计算平台时,首要的工作是深入分析和讨论典型的应用场景和服务类型。虽然每一个具体的应用场景并不会使用平台的所有功能和特征,每个用户也会有不同的需求或工作流,但是这些场景和用户都使用了平台提供的一站式人工智能服务。
1.1.1 普通计算任务
在平台已经部署的人工智能应用软件的基础上,用户通过批处理作业的方式完成模型训练和数据处理功能,如文献[7]能在GPU集群上完成10亿参数网络训练任务。在计算过程中,用户只需要指定应用、数据和计算资源等方面的若干参数,平台负责将这些作业匹配到合适的计算资源。在作业完成后,平台协助用户取回计算结果。
1.1.2 应用模型或算法测试
在平台已经部署的人工智能应用框架如Tensor-Flow[8]的基础上,用户部署模型或算法到平台,然后利用平台提供的资源,测试模型或算法的基本功能、性能、扩展性等多方面的指标。在测试过程中,用户首先需要在平台上部署模型或算法,然后通过测试验证这些算法是否有效,验证的过程类似上一小节的作业处理过程。
1.1.3 开发库和框架测试
在平台计算资源或数据资源所提供的操作系统、编译工具和基础开发库的基础上,用户部署开发库和框架到指定类型的服务器或者机群,测试这些开发库和框架的基本功能、性能和扩展性等指标。在测试过程中,除了部署开发库和框架之外,用户还需要在此基础上部署模型或算法,进一步提交计算任务,最终完成测试工作。
1.1.4 定制化的工作流
在应用模型已经确定的前提下,人工智能应用的过程通常包括数据预处理、参数选择和迭代训练等关键步骤以及应用部署和数据传输等辅助过程,这些活动组成了工作流[9-10]。在不同的应用场景下,用户需要不同的工作流。这些工作流包含多种类型的任务,每个类型的任务依赖于不同的应用和数据,也会产生多种格式的输出结果。工作流技术能够很好地简化应用场景的复杂性,因此,平台必须支持若干固定或者个性化定制的工作流。
1.2 用户类型
人工智能计算与数据平台的潜在用户包括计算与存储资源的运行管理人员、平台研发和运行人员以及最重要的终端用户。本文仅讨论平台的最终用户,包括初学者、研究人员和软件研发人员等三类,不包括计算基础设施和平台方面的相关人员。
1.2.1 初学者
人工智能技术涵盖计算机、数学和具体应用场景等多个学科领域。在理论学习的基础上,初学者包括研究生和培训学员能够利用平台提供的基础资源、海量数据、大量应用开发框架,通过简单易用的方式访问平台,完成学习目标,从而提升人工智能技术水平。
1.2.2 研究人员
人工智能技术作为重点和热门研究领域,还存在着很多问题需要解决,当前有很多的专家学者和研究生投入了大量精力和时间,开展了从计算基础设施、开发库、框架到应用算法与模型、具体应用场景等多个方面的研究工作,如粒子物理[11]、计算化学[12]和生物信息[13]等。人工智能平台将为研究人员提供一站式和简单易用的工作环境,从而让他们将精力聚焦于具体的科学问题而不用关心平台方面的问题。
1.2.3 软件开发人员
人工智能应用软件在开发或升级完成后,软件开发人员将该软件部署到若干服务器或机群之上,利用软件即服务SaaS(Software as a Service)的方式面向目标用户提供开发服务或者计算服务。因此,人工智能平台将为软件开发人员提供简单易用的部署工具,满足不同软件所需要的定制化运行环境,同时协助软件有效利用海量的计算资源。
2 人工智能平台功能需求
人工智能计算与数据服务平台能够有效整合计算资源、数据资源和应用资源,为人工智能领域的用户提供集成工作环境,支持算法设计、训练和服务的完整过程。为了实现上述功能,平台必须实现多种功能与服务,这些功能与服务借助多种形式的服务终端,满足用户的不同需求。本文将这些功能和服务划分为基本功能、特色功能、非功能性需求等三类。
2.1 基本功能
基本功能是平台必须的组成部分,若缺少这些功能,那么就不能称之为一个平台。传统的计算社区或网关一般提供作业管理和数据管理两项基本功能[14]。本文考虑到人工智能领域的应用软件和开发框架更新速度快、应用场景复杂多变等因素,应用管理也视为平台的基本功能。
2.1.1 作业管理
作业管理是人工智能计算与数据服务平台的核心功能,负责管理批处理形式的作业,提供类似于计算机群Slurm资源与作业管理系统[15]的接口。其中,作业提交功能负责将用户指定的各类参数和数据组合为作业管理系统认可的作业,并将作业提交到作业管理系统。作业管理功能负责作业的生命周期管理。作业数据管理功能负责提供简单的作业输入数据上传和作业输出数据下载功能。
2.1.2 数据管理
数据管理提供类似文件系统的功能,比如文件传输、文件夹创建和浏览等功能,为用户提供更好的用户体验。其中,文本文件及常见格式文档的查看功能可以允许用户方便地浏览远程文件。文件和文件夹的创建、重命名、移动、复制和删除等功能协助用户合理存储大量文件数据。文件打包和压缩功能可以协助用户方便管理和传输大量小体积的文件数据。
2.1.3 应用管理
人工智能应用和开发框架的数量特别多且更新速度快,因此,平台应提供应用部署、应用发现和共享等相关功能,从而扩展应用软件和开发框架的数量。其中,应用部署功能能够协助用户将人工智能应用软件或开发框架部署到指定的服务器或机群。应用发现和共享功能能够协助用户发现平台上新增加的应用软件或开发框架软件,包括平台运行人员和其它用户部署的软件,用户通过指定操作之后可以在允许的权限范围内使用这些软件。
2.2 特色功能
除了基本功能之外,用户期待人工智能计算与数据服务平台提供更多的功能,从而更好地满足人工智能技术在计算与数据处理过程的需求。
2.2.1 多种形式的终端服务
基于WEB页面的命令行能够平滑CLI的尖锐学习曲线,融合图形化界面简单易用和上手快的优点[16],面向科学计算用户提供简单易用和安全的命令行服务。因此,平台除提供WEB图形化的交互界面之外,还应当提供嵌入到WEB的定制化命令行服务,从而为用户提供多种形式的终端服务。
2.2.2 RESTFUL API和SDK
针对具体应用场景下的个性化需求,通用的Web页面和嵌入式命令行并不能很好地满足这些 需 求。REST(Representational State Transfer)是RoyFielding 提出的一种软件架构风格[17],可以降低软件开发的复杂性,提高系统的可伸缩性,天然具有良好的跨语言和跨平台的特性。与基于SOAP+WSDL+UDDI+WS-标准栈的大 Web 服务相比[18],基于 REST 风格的 Web 服务,形式更简单,设计更轻量,实现更便捷。RESTful API能够满足任意平台和语言环境的开发工作,SDK为主流开发语言提供进一步的封装从而减少研发人员的工作量。
2.2.3 异构计算资源和作业管理系统
当前的计算基础设施存在多种形式,既包括超级计算中心的超级计算机、集群式服务器,也包括商业公司和公共数据中心提供的云计算设施,甚至包括部分边缘计算设备,这些计算资源以物理机、虚拟机或者容器的形式存在。另外,这些计算资源上通常部署着Slurm、PPS Torque[19]、HTCondo[20]等多种类型的作业与资源调度系统。上述因素导致了平台必须支持多种异构计算资源和不同类型的作业与资源调度系统,聚合海量计算资源并提供统一和高效的访问接口,快速和动态匹配作业与计算资源,提升作业执行速度和资源利用效率。
2.2.4 多源异构数据
人工智能模型与算法的大规模训练过程需要海量的数据资源。由于相关业务系统建设数据管理系统的阶段性、技术架构以及经济和人为因素等因素影响,导致数据采用了不同的存储方式,包括简单文件数据库到复杂的网络数据库,从结构化数据库到NoSQL数据库,形成了异构数据源。由于存储技术的快速发展,数据存储系统既有常见的文件存储方式,也有近些年来新出现的块存储和对象存储[21]。因此,人工智能计算与数据服务平台应该支持多个来源、多种存储方式和多种数据格式的数据源,为人工智能模型或者算法访问这些数据提供接口和工具,从而实现多源异构数据服务。
2.2.5 工作流引擎
人工智能技术应用领域非常广泛,固定的工作流难于满足种类繁多的应用场景。深度学习的训练和推理都是一个复杂的过程,包括数据前处理、模型训练、数据后处理、可视化等一系列的过程以及分布式系统必须处理的数据传输和任务调度等问题[9-10]。另外,这些工作流通常产生大量的计算作业,这些计算作业之间存在复杂的依赖关系,也需要不同的应用软件和计算资源进行处理。因此,人工智能计算与数据服务平台应该提供高效率的工作流引擎,允许用户以图形化界面、配置文件甚至编程的方式创建工作流,实现大量计算作业在海量异构计算资源上的高效运行,从而将人工智能技术扩展到更多的应用场景。
2.2.6 远程交互界面与可视化
除了海量的批处理计算作业与数据处理过程之外,人工智能领域也存在很多交互性的活动,比如建立模型的调试阶段,用户重点关注模型合理性,每次作业执行的时间特别短。Jupyter是基于网页的交互式计算集成工具,可应用于计算的全过程,包括开发、文档编写、运行代码和展示结果[22]。通过安装和部署不同的kernel,Jupyter能够支持更多编程语言和功能。因此,人工智能数据与计算平台应该集成Jupyter或类似工具,支持交互式操作接口。另外,针对大规模输出数据的可视化问题,平台在后端计算资源完成计算过程,终端软件如WEB浏览器仅实现图片或视频数据的渲染,从而协助用户更好地理解计算结果。
2.3 非功能性需求
非功能性需求虽然不会为人工智能与数据服务平台增加新的功能或特征,但能够增加平台的可用性和易用性,从而增强用户体验。
2.3.1 多账号源与联合认证
认证是人工智能平台的基本功能,也是支持多租户访问平台的前提条件。平台聚合的计算与存储资源通常都有专用的账号系统。平台的用户也拥有电子邮箱、社交账号和电商账号。因此,平台除支持自有账号信息外,也应该支持其它外部账号,支持LDAP、NIS和AD等多种格式的账号,支持Oauth2和OIDC等开源协议从而支持相关的第三方身份提供商。另外,人工智能平台也应该与其它相关的平台、计算或存储资源建立联合认证服务,进一步扩展用户来源,为用户提供扩展服务。
2.3.2 可靠性
可靠性是每个平台或者软件不可回避的话题,不仅取决于人工智能平台软件的架构和技术,而且也依赖于运行环境、部署和运维等多种因素。在研发过程中,研发人员应重点考虑流程意外中断带来的损害和补救措施,尽量降低甚至消除意外中断的负面影响。在部署平台系统时,运行人员应该对关键组件和服务实现心跳检测、双活或多活部署。在运行过程中,运行人员应该针对关键数据进行定期检查和备份,制定和演练灾难恢复方案。
3 人工智能计算及数据应用服务平台架构和实现
中科院人工智能平台依托于国家高性能计算环境提供的软硬件资源、统一的资源调度和管理服务以及广泛分布的云存储服务和高速互联网络,面向人工智能领域科研单位和企业用户的需求,为用户提供方便易用的计算和数据服务,实现人工智能领域的相关技术和科研成果的快速应用、推广和成果转化,有效支持人工智能技术的快速发展。
3.1 基本功能和架构
中科院人工智能计算及数据应用服务平台采用层次化的架构,硬件层面提供海量异构化的计算资源,软件层面负责屏蔽硬件资源的异构性和复杂性并向上层提供访问接口,如图1所示。下面详细描述每个层面的具体功能及不同模块之间的相互关系。
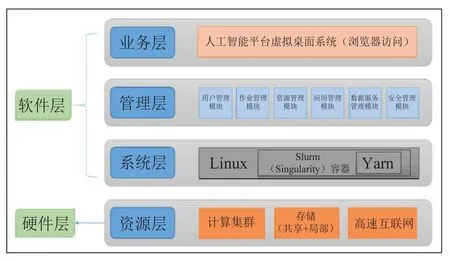
图1 人工智能计算及数据应用服务平台的层次化架构Fig.1 The layered architecture of artificial intelligence computing and data application service platform
(1)软件层
软件层向下聚合底层的异构计算基础设施,向上直接为用户提供简单易用的操作界面。其中,系统层对接计算资源机群的作业管理系统,将用户的作业自动提交到计算资源。系统层目前支持Slurm作业管理系统和Yarn(Apache Hadoop YARN)作业管理系统及两者相互结合的级联调度功能,如图2所示。Slurm是计算资源常用的作业管理系统之一,是一种可用于大型计算节点集群的高度可伸缩和容错的集群管理器和作业调度系统。Yarn是Hadoop的资源管理器之一,可为应用提供统一的资源管理和调度服务。在中科院人工智能计算及数据应用服务平台中,用户以作业的形式从Slurm申请计算资源,然后Yarn负责这些已分配资源的管理,从而支持基于容器的人工智能应用和大数据处理应用。
管理层提供PaaS服务的多个核心功能。用户管理提供基于中国科技云通行证的认证服务,一方面将中国科技云的海量科研和教育用户群体转化为平台的潜在用户,另一方面为用户提供了熟悉和简单易用的登录流程。应用管理负责协调和管理平台中的20余款常用的人工智能应用和开发框架,如图2的“应用软件”所示,包括TensorFlow、Caffe和Pytorch等主流人工智能软件。数据服务管理模块提供图形化的数据传输和文件管理功能,方便用户管理作业的输入和输出数据。作业管理模块负责以WEB图形化的方式接收用户作业并提供作业管理等功能。
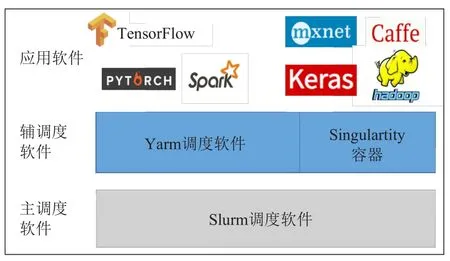
图2 基于容器的级联调度和应用部署图Fig.2 The archictecture cascade scheduler and applications deployment based on container.
业务层面向用户和平台管理员提供简单易用的交互界面。该平台实现了WEB化的图标式页面,用户能够点击图标并进入作业提交、作业管理和数据传输等功能。管理员能够通过WEB图形化页面实现账号绑定和应用授权等管理功能。
从功能上看,该平台实现了2.1节讨论的基本功能,能够支持用户在平台上完成人工智能应用和模型的计算与数据处理任务。
(2)硬件层
平台还拥有人工智能专用计算机群。该专用计算机群包含丰富的CPU计算资源和GPU计算资源,配置48台曙光W780-G20 GPU服务器,每服务器包括2颗Intel CPU,总计算能力达到40Tflops。专用计算机群包含380块NVIDIA Tesla P100 GPU加速卡,双精度计算峰值1786TFlops,单精度峰值高达3534Tflops。在异构资源对接方面,平台利用国家高性能计算环境提供的统一服务实现了与其它异构资源的对接。
3.2 简单易用的Web服务
中科院人工智能平台采用了基于WEB的图标化桌面,每个应用软件或者服务都是一个桌面图示,用户双击该图标可使用指定的应用或者进入指定的服务。图标化桌面能够提供类似个人计算机的功能图标布局,用户几乎不需要学习就可以直接使用平台中提供的多种软件和服务,如图3所示。
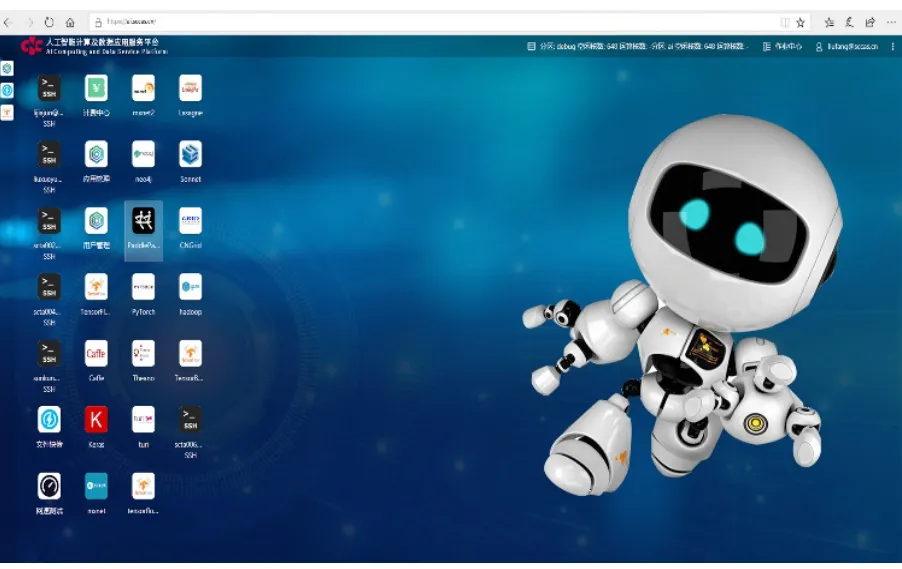
图3 基于WEB的图标化桌面Fig.3 The WEB-based iconized desktop
为增加用户体验,满足作业管理和应用部署调试等多种场景的需求,平台提供了基于WEB服务的图形化作业提交和管理页面、嵌入式命令行工具和Jupyter编辑调试工具等3种WEB服务。其中,嵌入式命令行工具在前端WEB页面上模拟一个命令行窗口,该窗口通过web socket连接到后端WEB服务;后端WEB服务调用SSH(Secure Shell)客户端连接远端的异构计算资源。另外,平台提供了基于Jupyter的软件在线编辑和调试系统,提供Python等编程语言的在线编辑和调试功能。平台基于WEB技术提供了图形化服务和命令式服务,满足用户多种场景下的需求。因此,平台支持了2.2.1节讨论的“多种形式的终端服务”特征。
3.3 资源对接服务
平台提供了直接访问专用计算机群的资源对接服务,包括用户认证、作业提交、作业管理等功能。该服务接收用户认证功能提供的中国科技云通行证的邮箱账号,然后资源对接服务通过查询账号映射关系将邮箱账号转换为专用计算机群的本地账号。资源服务通过本地账号登录专用计算机群。为增强服务的可靠性,资源对接服务可连接专用计算机群的两台登录服务器,实现大量任务之间的负载均衡,屏蔽单台登录服务器故障,提升单个操作的响应速度等可扩展、可靠性与性能等方面的指标。
在设计过程中,资源对接服务分为作业提交模块、作业查询模块和简单的数据传输模块。作业提交模块负责接收作业描述参数,生成作业提交命令,在作业工作目录准备就绪的情况下执行作业提交命令。作业查询模块负责定时查询作业状态并更新到数据库。简单的数据传输模块负责将作业数据从平台的后端服务器传输到专用计算机群并创建作业工作目录。上述功能的实现依赖于专用计算机群的Linux操作系统、Slurm系统软件和SSH远程命令服务。此外,平台利用国家高性能计算环境提供的统一服务实现了与其它异构资源的对接,因此,平台支持了2.2.3节讨论的“异构计算资源和作业管理系统”特征。
3.4 应用软件服务
人工智能技术的应用范围非常广泛,应用软件数量多。应用软件依赖于众多的开发库,升级频繁。然而,高性能计算机群的系统升级过程缓慢,甚至在整个生命周期数年的时间仅升级基础组件和安全相关的组件,因此,很难满足人工智能领域框架和软件快速升级换代的需求。平台支持基于Singularity容器软件部署和运行服务,Singularity容器在创建过程中需要超级权限,启动和运行只需要普通权限[23-24]。因此,用户在个人计算机利用超级权限创建和管理Singularity容器,然后通过高速网络将定制容器上传到高性能计算机群,通过普通用户权限运行这些容器。该软件部署方式既保证了高性能计算机群的安全和稳定,也为深度学习用户提供了海量的GPU计算资源,还有Singularity容器很小的额外代价也保证了人工智能大量作业运算和数据处理的效率。
3.5 数据传输和管理服务
除了大量的计算资源之外,人工智能模型与算法的大规模训练过程需要海量的数据资源。平台和计算与存储资源之间有高速网络连接,传输速度可以达到数十MB到数百MB之间;但用户和计算平台之间的网络情况差异较大,而且速度也相对较慢,通常在几MB到几十MB之间。平台专门设计了数据传输服务,协助用户将大体积的文件传输到专用计算机群。用户使用WEB图形化页面或者命令行提交数据时,可以通过指定文件路径的方式使用这些上传或生成的数据文件。因此,平台支持了2.2.4节讨论的“多源异构数据”特征的部分功能,后期还要加强大文件传输、打包和压缩等功能。
4 人工智能计算及数据应用服务平台的服务方式
中科院人工智能平台于2018年初发布,面向科研和教育用户提供一站式的人工智能计算、应用和数据服务。平台支持Tensorflow、Caffe、PyTorch、Theano、MXNet、Keras、Lasagne等主流的深度学习框架和人工智能算法库软件。平台支持Singularity容器,用户可自定义容器并上传然后调用,同时提供包含常用框架软件的标准容器。平台现已开通用户账号200余个,支持了包括中科院研究所、大学和创业公司等三十余家单位的人工智能应用计算。中科院人工智能平台支持WEB图形化页面、嵌入式命令行工具和在线编辑调试工具等三种服务方式。
4.1 WEB图形化服务方式
WEB图形化服务是计算与数据平台常用的服务形式之一,具有学习门槛低、操作简单和易于使用的特点。在中科院人工智能平台上,用户能够通过WEB页面的点击、拖动和简单输入实现作业管理操作,包括提交作业、查看作业状态、上传输入文件和下载输出文件等功能。其中,作业提交页面如图4所示。
除了作业管理操作之外,用户可以访问平台的应用市场服务,根据计算和数据处理任务的需求,选择合适的应用并添加到图标化的WEB桌面。此后,用户像使用其它应用软件一样,点击新添加的应用图标并完成作业提交等过程。为了进一步降低用户学习门槛,应用市场所有应用软件遵循相似的作业提交流程,每个作业包括本身属性、应用、数据和计算等方面信息的格式相似,输入方式也基本相同,从而达到用户学习一次就能够使用所有软件的WEB应用服务的目标。
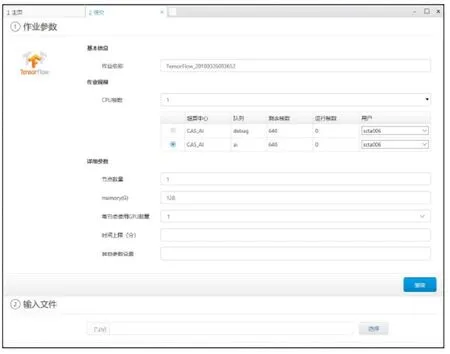
图4 基于WEB的作业提交Fig.4 The job submission interface on WEB
4.2 命令行服务方式
命令行具备占用资源少、操作速度快和通用性强等方面的优点,目前仍然是科学计算领域的重要交互界面。平台提供了基于WEB的嵌入式命令工具WEBCLI,如图5所示,融合图形化界面简单易用和上手快的优点,面向科学计算用户提供简单易用和安全的命令行服务。嵌入式命令工具不仅免去了用户安装和配置命令行终端软件的烦恼,而且用户通过平台的认证功能能够自动完成SSH登录过程,从而也不再需要记录复杂的凭证信息。
与常见的基于WEB的SSH工具相比,用户通过WEBCLI输入的命令不会直接发送到远端的计算资源,而是由WEB服务接收并完成安全、格式和语义转换等方面的处理后再转发到计算资源并执行命令,在增强易用性的同时也保证了安全性。基于嵌入式命令工具,用户几乎能够完成传统命令行终端工具下的所有操作,包括linux系统命令、Slurm作业系统和编译调试等相关命令。由于浏览器安全沙箱的限制,运行在浏览器的嵌入式命令工具能够操作服务器的文件,但并不能操作个人计算机的本地文件系统。
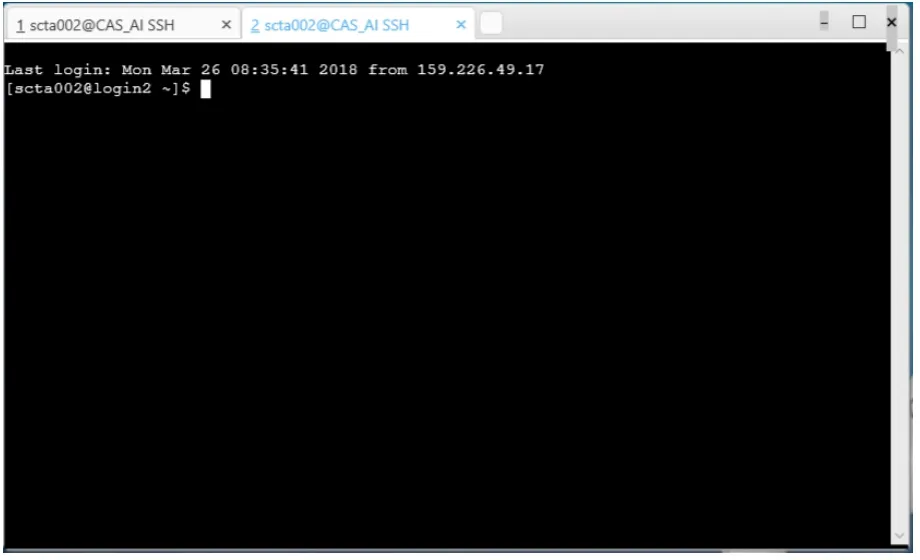
图5 基于WEB的嵌入式命令行Fig.5 The embedded command interface on WEB
4.3 在线编辑调试服务方式
人工智能技术发展迅速,用户经常需要部署新的软件或者基于开源框架创建新的模型和算法。因此,平台提供了基于Jupyter的在线调试和编译工具,如图6所示,允许用户通过交互模式在人工智能专用计算机群上调试代码。用户请求在线调试服务时,平台首先透明地帮助用户锁定一片GPU计算资源,然后平台通过WEB展示Jupyter的工作页面,从而为用户提供一个在线软件调试环境。
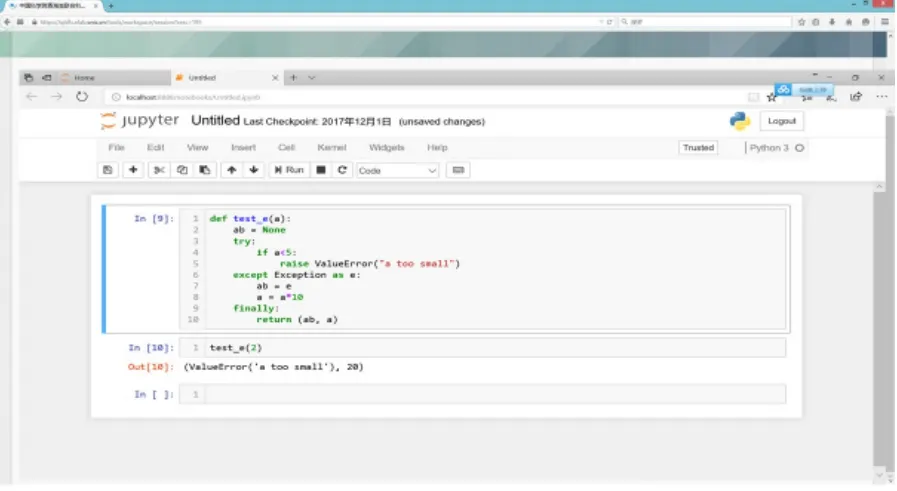
图6 基于Jupyter的编辑和调试工具Fig.6 The Jupyter-based editing and debugging tool
目前,中科院人工智能平台中已经提供了Python语言的在线调试功能。在交互模式下,用户能够选择Python脚本文件,在WEB页面上编辑Python源代码,然后在专用计算机群上执行代码而不需要经历作业排队过程。基于该服务方式,用户能够直接利用专用计算机群的应用运行时环境修改和调试应用程序,在测试通过后能够方便地通过批处理方式提交大规模的计算任务。
4.4 相关工作与讨论
平台化服务是计算领域特别是高性能计算、高通量计算和人工智能等领域的重要服务手段和发展趋势。在云计算和虚拟化技术的基础上,知名商业公司提供了人工智能平台服务。Amazon通过AWS平台提供了广泛、深入的机器学习和 AI 服务。微软公司通过Azure提供了以云和边缘计算为特点的人工智能框架和软件服务。阿里云致力提供安全、可靠的计算和数据处理能力,让计算和人工智能成为普惠技术。这些商业公司提供了开箱即用、模块化和资源弹性扩展的人工智能计算平台,重点面向普通用户提供商品化的计算与数据服务。本文提出的人工智能计算及数据应用服务平台重点面向科研人员、专家学者和软件开发人员提供一个开放和定制化的平台,从而满足他们前瞻和创新项目的计算与数据需求。
在科研和教育领域,也有计算平台提供人工智能服务。本文讨论的平台提供了基于Jupyter的在线编译工具,文献[25]将Jupyter软件部署到了XSEDE的计算资源如Comet超级计算机和Kubernetes容器化虚拟集群,从而满足大量用户的代码修改和应用后处理等方面的需求。另外,Comet超级计算机利用容器和虚拟集群的方式满足用户的各种需求,提供定制化的运行时环境从而满足多种软件的部署和运行需求[26]。本文讨论的平台已经利用容器面向用户提供计算服务,但仍然需要加强虚拟化技术的利用从而更好地满足用户不断变化的需求。WLCG是典性的高性能计算服务环境,文献[27]在此基础上提供了面向高能物理领域的机器学习服务,目标是处理LHC实验产生的EB级数据。本文讨论的平台依托于海量的高性能计算资源和专用的人工智能资源,因此平台能够支持海量和大规模的人工智能训练任务。
5 结论和展望
人工智能计算与数据服务平台的目标是建设和形成融合计算资源、存储资源和人工智能应用为一体的服务平台,面向用户提供一站式的人工智能计算与数据服务。本文在分析人工智能计算与数据平台的应用场景和用户分类的基础上,深入讨论了平台应当具备的基本功能、特色功能和非功能性需求。然后,本文以中科院人工智能平台为例,讨论了平台架构、关键服务以及WEB图形化页面、嵌入式命令行工具和在线编辑调试工具等三种服务方式。中科院人工智能平台实现了本文讨论的全部基本功能和部分特色功能,能够满足用户作业提交、应用建模和算法测试、开发库和框架测试等典型应用场景的基本需求。为了更好地满足用户需求,在下一阶段我们将继续完善现有的流程和服务,开展工作流引擎、RESTful API和SDK等方面的研发工作。
利益冲突声明
所有作者声明不存在利益冲突关系。
