多粒度认知计算
——一种大数据智能计算的新模型
2020-01-15王国胤于洪
王国胤,于洪
重庆邮电大学,计算智能重庆市重点实验室,重庆 400065
1 大数据智能计算——大数据的价值实现之路
众所周知,蒸汽机、电力和内燃机等技术促使人类社会从农业时代进入到了工业时代,计算机、信息网络等技术的发展又带领人类社会进入了信息时代。当前,随着人工智能技术的发展,人类社会正逐步从信息时代进入智能时代。
当前人工智能发展的特点是:基础理论研究突破引领科技发展方向,学术界和产业界深度融合。例如,2018年度图灵奖授予给了此次人工智能热潮引领者“深度学习三巨头”:Yann LeCun(杨乐昆),纽约大学教授,Facebook副总裁;Geoffrey Hinton(杰弗里·辛顿),谷歌副总裁,多伦多大学名誉教授;Yoshua Bengio(约书亚·本吉奥),蒙特利尔大学教授。这正好反映了当前人工智能发展的特点。人工智能大发展的三大支撑包括大数据资源、深度学习算法和高性能计算能力。正是这三方面的快速发展使得人工智能技术的应用快速普及。
新一轮科技革命和产业变革正在孕育,人工智能是核心推动力量;世界主要发达国家纷纷加强谋划部署,力图在新一轮国际科技竞争中掌握主动权。截至2018年12月,全球至少18个国家提出AI计划(来源:CIFAR)。我国国务院在2016年发布了《中国制造2025》;2017年,国家发改委和科技部等四部门联合发布《“互联网+”人工智能三年行动实施方案》,人工智能列入政府工作报告,国务院发布《新一代人工智能发展规划》,人工智能写入十九大报告;2018年,中共中央政治局集体学习人工智能发展现状和趋势,中国人工智能学会向国家学位委员会和教育部再次建议设立“智能科学与技术”一级学科。
一方面,在我国强有力的战略引领和政策支持下,科技部、教育部、发展改革委、工业和信息化部等部门相继出台多项举措,北京、上海、天津、重庆、广东等近20个省市出台了人工智能规划和行动计划,纷纷加大研发投入,设立研发机构,制定人才引进、财税优惠等配套政策,带动企业加快智能化步伐,产学研协同推进人工智能发展的格局正在形成。
另外一方面,我国各行各业数据资源快速增长,尤其是一些特定应用领域数据规模庞大。例如,我国互联网数据资源快速增长,拥有全球最多的7.5亿网民数和7.2亿手机用户数,网民使用网络购物的比例超过55%,手机支付用户规模达到5.27亿人。一些特定应用领域数据规模庞大,例如:医疗门诊总量每年达到81.8亿人次,每年有3亿人次做计算机断层扫描(CT),10亿人次做数字化成像(DR);年度快递业务量超过400亿件;每年国内旅游人数超过50亿人次。
在全球信息化快速发展的背景下,大数据已逐渐成为世界各国重要的基础性战略资源,运用大数据推动社会经济发展正成为趋势。随着几十年的信息化建设,人类已经进入高速发展的信息时代,数据采集能力超广、数据存储能力超大、数据传输能力超快并且数据计算能力超强。数据与产业、经济、社会发展紧密结合。
在如此巨量的大数据中,我们看见了什么?是数据与信息,信息爆炸,还是知识与智能?显然,我们希望数据带给我们价值。为了从数据中获取价值,人们首先将各种方式收集到的数据转化成计算机能处理的信息形式,然后通过一些技术方法手段,从信息中挖掘出对人们生产有益的知识,并最终形成决策。图1给出了从数据到决策的处理流程示意图。通常来说,这个过程包括数据(感知)→信息→知识(认知、智能、智慧)→决策(行动)等等。
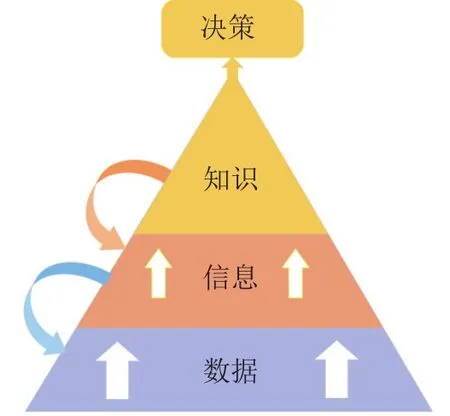
图1 从数据到决策的处理流程示意图Fig.1 Processing flow diagram from data to decision
大数据作为一种重要的信息资产,可望为人们提供全面的、精准的、实时的商业洞察和决策指导。从数据到知识,从知识到决策,是当前大数据智能的计算范式[1],研究大数据的意义就是不断提高“从数据到决策的能力”,实现由数据优势向决策优势的转化。事实上,我们只有从数据中得到了有益的决策,数据才产生了价值。
社会高度信息化,从而大数据产生,这个时候通过大数据智能计算来实现智能化将是必由之路,也是真正利用好信息化成果(大数据)的必然,不能仅仅停留在数据中心的建设上。大数据智能计算是实现大数据价值的实现之路。
简单地说,大数据智能就是借助人工智能等技术手段从大数据中挖掘/发现有价值的知识,并形成智能决策,从而在产业、经济、社会生活中产生大的价值。
2 大数据智能计算面临的主要挑战
在分析大数据智能计算面临的主要挑战和问题之前,让我们先来回顾一下从数据到知识到决策的技术方法发展历程。
1763年,Thomas Bayes的论文在他去世后发表,他提出的 Bayes 理论将当前概率与先验概率联系起来,帮助理解基于概率估计的复杂现况,成为了数据挖掘和概率论的基础。1805年,Adrien-Marie Legendre和高斯Carl Friedrich Gauss使用回归(最小二乘法)确定了天体(彗星和行星)绕行太阳的轨道。回归分析是数据挖掘的重要工具之一,其主要目标就是估计变量之间的关系。1936年,Alan Turing发表论文“On computable numbers on computable numbers,with an application to the etscheidungs problem”,提出了通用机,计算机时代即将到来,它让海量数据的收集和处理成为可能。1943年,Warren McCullon 和Walter Pitts 发表论文“A logical calculus of the ideas immanent in nervous activity”,提出神经网络的概念模型,阐述了网络中神经元的概念,每一个神经元做三件事:接受输入,处理输入和生成输出。1965年,Lawrence J.Fogel 成立了 Decision Science Inc.,这是第一家专门将进化计算应用于解决现实世界问题的公司。1975年,John Henry Holland出版《Adaptation in Natural and Artificial Systems》,成为遗传算法的开创性著作。1992年,Berhard E.Boser,Isabelle M.Guyon和Vladimir N.Vapnik提出改进支持向量机,充分考虑到非线性分类问题。2006年,Geoffrey E.Hinton等人提出深度学习的概念。
1970年,数据库管理系统趋于成熟,存储和查询巨量数据(高达千万亿字节)成为可能。数据仓库的出现,促使用户的思维方式从面向事务处理转变到注重数据分析。不过,从这些多维模型的数据仓库中提取复杂深度信息的能力有限。1989年,Gregory Piatetsky-Shapiro 在IJCAI 1989提出了术语“数据库中的知识发现”(Knowledge Discovery in Database,KDD)。1998年成立了ACM SIGKDD,相继地有PAKDD,IEEE ICDM,ECML PKDD,CCDM等一系列关于数据挖掘的国际会议诞生。2015年,DJ Patil成为白宫第一位首席数据科学家和制定数据策略的副首席技术官。图2简单地描绘了知识发现30年来的探索发展历程。

图2 知识发现30年探索之路Fig.2 30 Years’ exploration of knowledge discovery
当今社会处于一个信息技术高速发展的时期,数据信息的交互、共享与开放程度持续加快,使得来自各行业领域的数据信息呈爆炸式增长。大数据的如下特点也让大数据智能面临着新的挑战,比如:数据体量巨大:千、万亿个样本,动态增长;数据维度超高:十、百亿维特征,组合爆炸;数据分布更广:分布在不同服务器,“独立同分布”不再适用;不确定性加剧:不完整、不一致、随机性、动态演化、认知模糊等等。
现有的帮助人类探索世界的计算技术是一种基于数据的计算模式,是一种“数据计算”的模式。但是,我们人类认知世界是不是也是这样的呢?答案显然是“不”。
以目前应用最为广泛的基于深度学习的人脸识别为例:在计算机世界里,计算机(人脸识别系统)从处理图片的像素点开始,学习大量人脸图片的各种特征信息,从而来实现人脸的识别。而我们人是怎么认识人(脸)的?虽然我们不知道答案,但我们显然不会去计算你看见的一张脸的眼距、嘴唇大小等等。那么,我们就有个疑问:深度学习实现了人脑认知吗?我们不这么认为。最近基于深度学习的反人脸识别就是一个重要的反证[2],他们的研究工作将原本可检测到的人脸识别率从接近100%降到了0.5%!也就是说,深度学习的识别计算机理≠人类大脑的识别认知机理。
我们来总结、观察一下目前已有的各种知识发现、机器学习、数据挖掘方法,他们实现的几乎都是一种细粒度到粗粒度的由数据到知识的单向变换过程(见图3),这是由计算机的数学理论基础(离散数学、集合论)决定的。
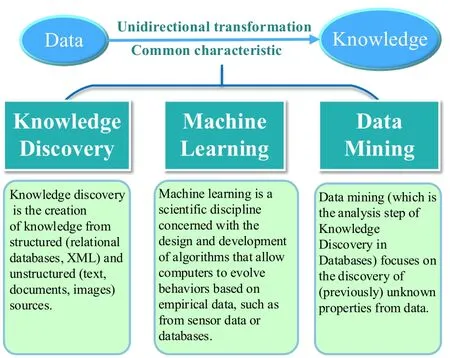
图3 细粒度到粗粒度的信息/知识变换过程[19]Fig.3 Information/Knowledge transformation process from fine to coarse granularity[19]
中科院生物物理所陈霖院士等通过实验发现:人类认知具有“大范围优先”的规律,视觉系统对全局拓扑特性尤为敏感,直接处理最细粒度的原始数据不符合人类的认知规律[3-5]。例如,图4显示的就是在心理学测试中,人们首先关注大粒度的字母,然后才是大H是由一系列的S组成。
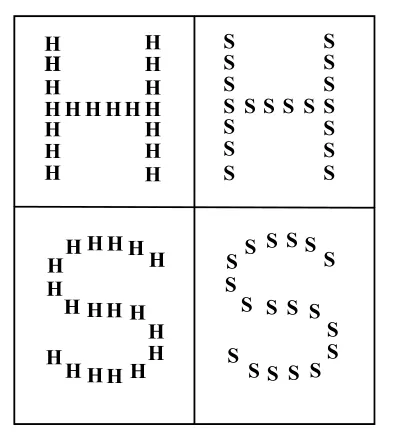
图4 人类认知具有“大范围优先”的规律[4-5]Fig.4 Human cognition has the mechanism of:global precedence”[4-5]
换句话说,人类认知是一种从上到下、从粗粒度到细粒度的过程,数据计算过程是一种从下到上、从细粒度到粗粒度的过程。图5给出了这两种过程的示意图。图的左边部分是我们人类认识物体,没有那么多的数字细节的漫画,我们能识别。图的右边部分,示意了人脸识别的计算机的数据计算过程。
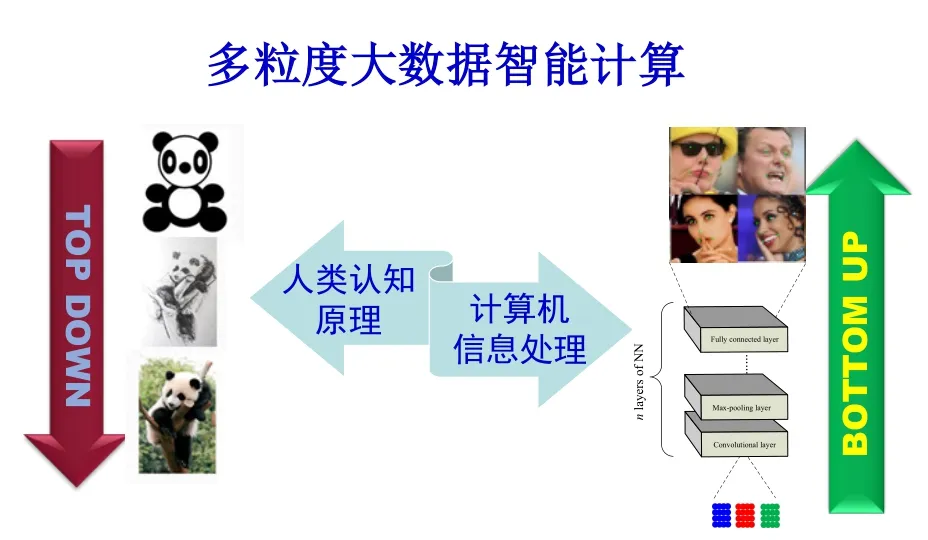
图5 融合人类认知原理与计算机信息处理空间变换过程的大数据智能计算Fig.5 Big data intelligent computing integrating human cognitive principle with computer information processing spatial transform process
可见,融合人类认知原理与计算机信息处理空间变换过程的大数据智能计算,是挑战,也是未来科研发展的必然方向。
从不同层次逐级认识世界是人类固有的一种认知机制[6],在认知计算中,被称为粒计算。粒度最初是物理学的一个概念,指的是实质粒子大小的平均度量。在这里,它被用来度量从不同层次结构空间中分析和处理数据的信息量[7]。多粒度认知是一种符合人类认知与问题求解要求的模式,我们认为多粒度大数据智能认知计算是解决人类认知模式与计算机数据计算模式之间矛盾的一种有效方法。
3 多粒度认知计算——大数据智能计算的新模型
3.1 粒计算思维
随着人工智能和认知科学的不断发展,研究者们发现了人类智能的一个公认特点:在对现实世界问题的认知和处理时,人类往往采取从不同层次观察和分析问题的策略,从不同层面上观察和分析同一问题。从哲学的观点上来看,人类在对事物进行认知、度量、形成概念和推理时,粒度思想贯穿其中[8]。
粒计算思维广泛存在于人类生活中。图6给出了粒的思想在工业生产、社会组织、自然世界中的示例。
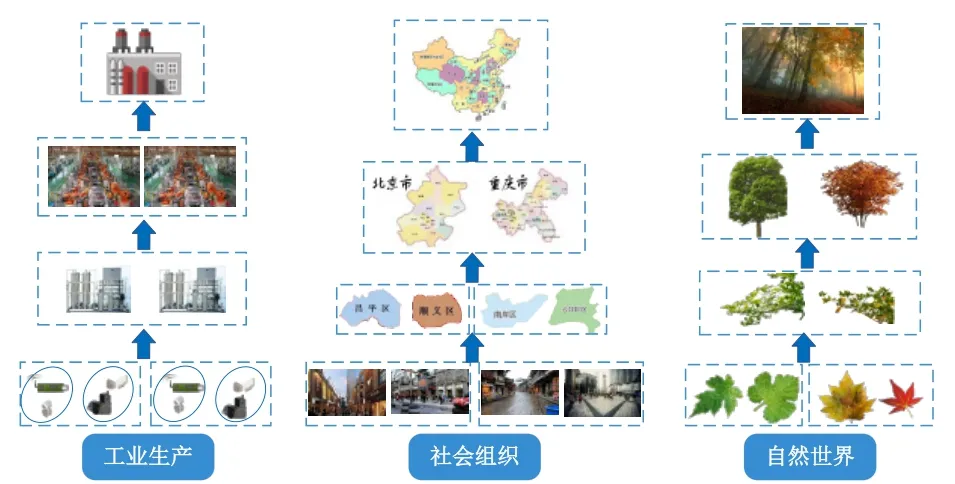
图6 粒计算思维举例Fig.6 Examples of granular computing thinking
3.2 多粒度认知计算模型方法
粒计算通常被认为是在解决复杂问题中,所使用的粒化理论、方法、技术和工具的总称。
1997年,Zadeh教授就指出粒计算是模糊信息粒化、粗糙集理论和区间计算的超集,是粒数学的子集[9]。粗糙集等理论提供了具体的粒计算模型,将粒与认知计算中的分类、学习紧密联系起来,使得粒计算成为一种快速增长的智能计算范例[10]。Bargiela和Pedrycz将粒计算视为用于分析和设计人工智能系统的一个概念和算法平台[11]。Jankowski用粗糙近似对语法、语义等信息粒进行建模[12]。全集和邻域系统的层次结构能够诱导出多粒度结构。
模仿人类在不同粒度层次上感受现实世界的能力,张铃和张钹提出了商空间理论,该理论能够为了满足特定问题的求解需要,对对象进行不同粒度层的抽象与转换[13]。形式概念分析能够从一组对象中自动推导出本体[14],概念格的粒结构是该理论中知识约简的重要手段[10,15]。姚一豫在上述研究成果基础上,将粒计算归纳为图7所示的相互补充、互为依赖的三角形关系[16,17]。基于定性概念和定量数据之间的关系,王国胤基于云模型提出了一种双向认知计算模型(BCC),用于表示和处理不确定概念的映射关系,将样本视为概念的外延,使用云模型的三个参数(期望、熵、超熵)来表示概念的内涵[18]。
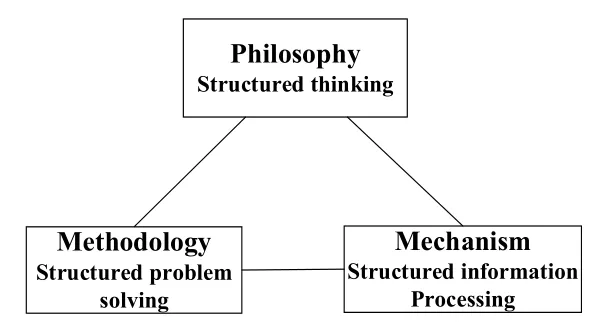
图7 粒计算的三角形结构[15]Fig.7 Triangular structure of granular computing[15]
3.3 数据驱动的粒认知计算(DGCC)
解决计算机“由细到粗”信息处理机制与人类“由粗到细”认知机制的矛盾,将是研究新型认知启发的智能计算模型需要解决的一个关键问题。我们提出的数据驱动的粒认知计算(Data-driven Granular Cognitive Computing,DGCC)[19-20]实际上是从数据出发,以人类认知事物的分层(多粒度)机制为基础的计算框架。如图8中的三角形结构所示。它结合了人类“大范围优先”的认知机制,即“由粗到细”认知过程,和机器学习系统“由细到粗”的信息处理机制。
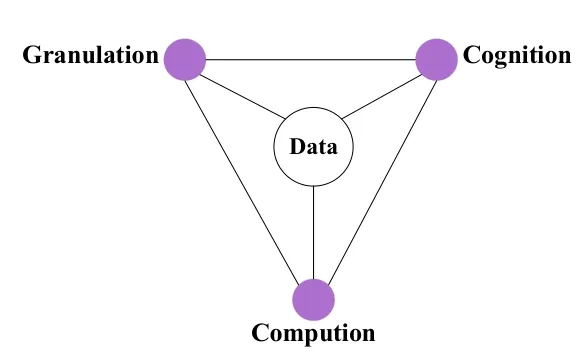
图8 DGCC的三角形结构[19-20]Fig.8 Trianglular structure of DGCC[19-20]
在这个结构中:计算强调数据科学,包括所有处理大数据的高效计算模型和方法;认知强调对大数据的智能理解,强调用户与信息系统的智能交互;粒化强调处理大数据的多粒度思维和建模;计算、认知和粒化以数据驱动的方式实现。
从认知计算来看,数据是知识的外延,知识是数据的内涵,两者之间是抽象与具象的关系;从粒计算来看,数据是知识在最细粒度上的表现,知识是数据在粗粒度上的描述,两者之间是粒度层次切换的关系,如图9所示。
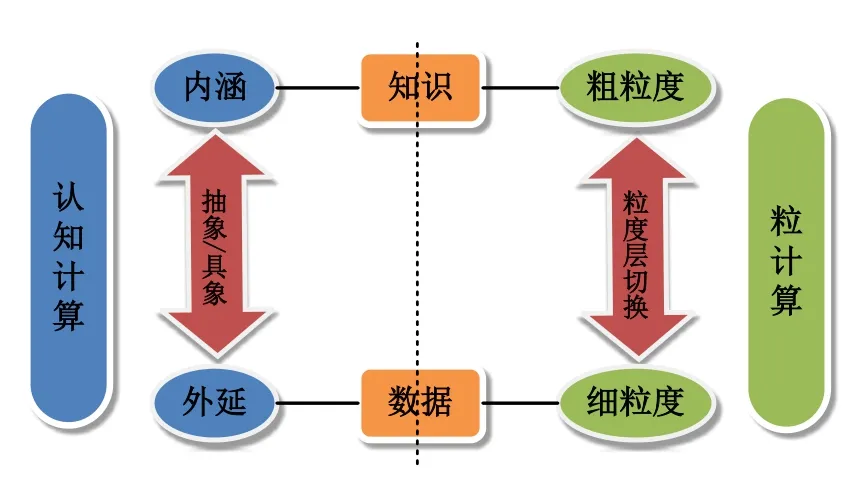
图9 数据与知识在DGCC中的关系[21]Fig.9 The relationship between data and knowledge in DGCC[21]
人机模型中知识与数据共同驱动的认知计算与DGCC中二者的双向认知计算有本质不同。在知识与数据共同驱动的人机模型中,知识来自人类的总结,知识和数据呈现一种平行结构,二者在认知过程中是互补关系。在DGCC中,知识与数据是一种层次结构,从低粒度层次向高粒度层次的变换由数据驱动,而从高粒度层次向低粒度层次的变换由知识驱动(如图10)。
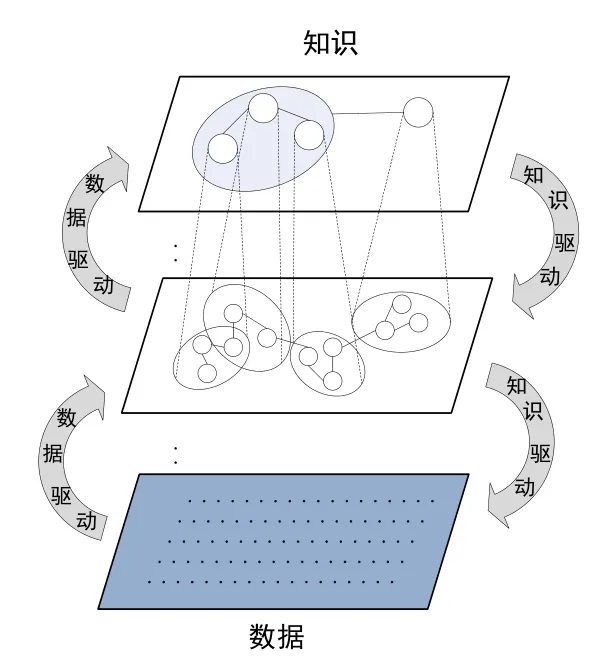
图10 DGCC中知识与数据的双向驱动[21]Fig.10 Bidirectional driven of knowledge and data in DGCC[21]
建立数据驱动的粒认知计算模型,实现数据与知识双向驱动和变换,有下述三个方面的科学问题需要研究[21]。
(1)多粒度空间的描述问题
在传统的多粒度认知计算模型中,数据、信息和知识是被区别对待的,数据在最底层,信息在中间层,知识在高层。而在数据驱动的粒认知计算中,将数据作为知识的一种编码格式,需要构造一个通用的多粒度结构对数据、信息和知识进行表达,形成一个分层的多粒度空间对三者进行编码。
一般来说,高粒度层上的概念(信息和知识)比低粒度层上的概念(信息和知识)更具有不确定性。在大数据环境下,由于低粒度层是对对象的局部进行描述,在低粒度层数据抽象为高粒度层信息的过程中,通常伴随着不确定性的增长。反之,在从高粒度层向低粒度层变换的问题求解过程中,解的不确定性也可能相应增加。
现实世界的系统往往是动态的。智能信息系统的数据、信息和知识也是动态的。因此,需要研究多粒度知识空间中的动态演化机制来处理动态数据、信息和知识。
(2)多粒度联合求解问题
数据、信息和知识在同一个多粒度空间中进行编码,可以并行地解决问题。例如,一个公司每天都在不同粒度层上同时作决策。对于不同粒度层上独立或者相互依赖的决策,需要构造多粒度空间联合计算和决策机制。
通常,在高粒度层上花费较小的时间代价能够形成“较粗”的解,而在低粒度层上形成“更精确”的解则要花费较大的时间代价。因此,许多复杂问题可以首先在高粒度层上求出“较粗”的解,再在低粒度层上求出较精确解,这一有效的方法被称为变粒度渐进式计算。
在一些实际应用中,并不是所有数据在开始时就全部可用,此时,需要根据低粒度层上仅有的部分数据做出初步的局部决策,再根据更多的数据输入,在较高粒度层上形成改善的全局决策。
数据、信息和知识在同一个多粒度空间中进行编码,因此,可以进行并行和分布式的学习,而不需要逐层学习。
(3)人机认知机制融合问题
向上算子和向下算子是数据驱动的粒认知计算中的两种基本算子,分别模拟了人类“由粗到细”的认知机制和计算机“由细到粗”的信息处理机制,作为双向认知计算的一种推广,需要设计一种融合双向算子功能、便于多粒度空间层次转换的计算模型。
计算机的信息储存机制是机械的,信息在删除后不能使用。而人脑中存在着遗忘与回忆的机制,可以通过一类双向认知计算模型实现。在数据驱动的多粒度认知计算中,向上算子能够通过信息从低粒度层到高粒度层的转换来模拟人类的遗忘过程,向下算子能够通过信息从高粒度层到低粒度层的转换来模拟人类的联想回忆过程。
3.4 多粒度认知计算在流程工业知识自动化中的应用
我国是工业大国,正在向工业强国迈进。现有的决策方法与技术存在如下难点:基于数学模型的操作决策方法,难以应对新形势下机理复杂和多重不确定性的挑战;基于规则知识的操作决策方法,定性/定量知识共存、结构化/非结构化知识共存,动态学习困难;基于数据驱动的操作决策方法,面临多源异构数据解释、融合的难题。如何把反映共性规律的自上而下的机理经验知识与反映自下而上的数据在一个统一的框架下融合起来,实现“数据-知识”融合驱动的工业大数据智能决策模型方法是目前工业大数据智能决策面临的挑战问题[22]。
(1)面向层级组织结构的集团企业的多粒度层次评价
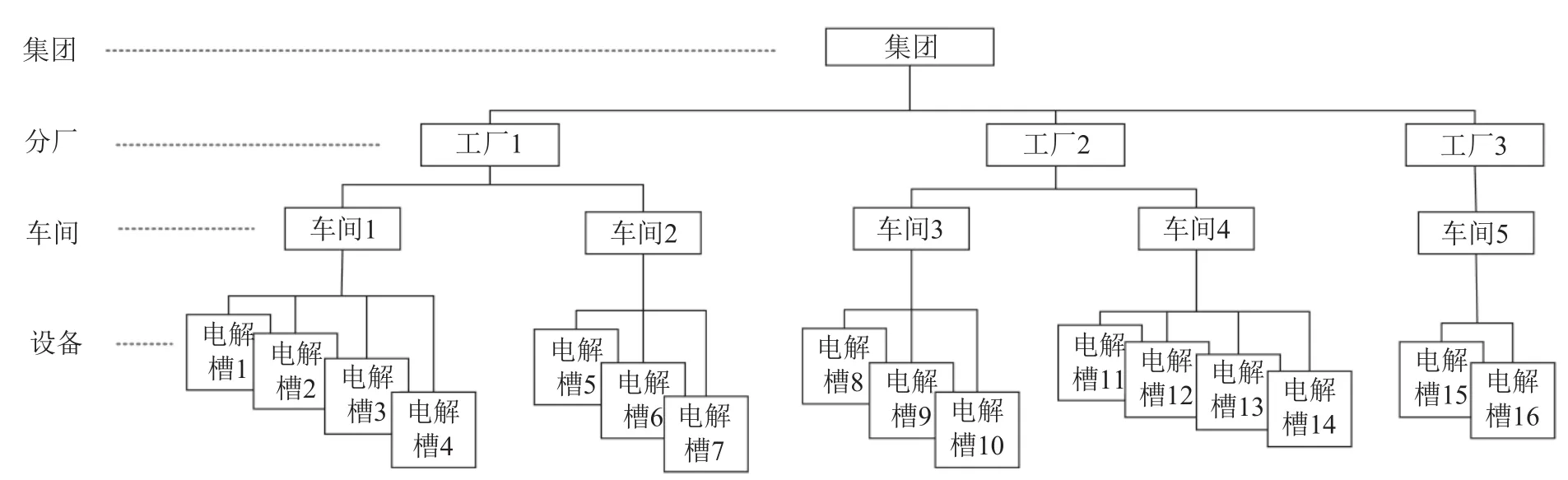
图11 一个铝电解集团组织结构示例Fig.11 An example of organizational structure of aluminium electrolysis Company
在铝电解等流程工业生产过程中,设备、车间、分厂、集团之间构成了层级组织机构关系。图11给出了一个铝电解集团企业的组织结构示意例图。这种结构实际上就是一种层次粒度结构。
因此,针对工业生产中存在的这种层级粒度关系,可以使用多粒度认知计算的方法来解决其中的一些问题。
例如,在电解铝集团这类具有分层组织结构的大型企业集团公司中组织成员的评价问题中,普遍存在如下难题:不同粒度层次上的评价指标不同、上层评价需要关联下层评价结果、评价对象众多,严格排序法难以契合人类认知和实际应用需求。表1给出了各层评价指标的一个示例。其中,针对电解槽的评价指标,既有收益指标和消耗指标,也有非单调指标。下层的评价结果与上层的决策是有关联的。针对这些问题,我们基于多粒度认知计算方法提出了基于多准则三分类的多粒度层次评价模型[23]。
(2)工业铝电解中的过热度软测量
中国自2001年成为最大的电解铝生产国以来,铝工业取得了快速发展。但我国铝电解行业目前面临着全新的挑战,随着资源紧缺、能源消耗巨大、环保等问题出现,实现知识自动化是解决这些问题的一个有效途径。过热度是指铝电解中电解质温度与初晶温度之间的差值。将过热度保持在5℃到12℃之间有利于形成规整的槽堂内形,进而能够稳定生产,减少水平电流,提高电流效率,延长电解槽寿命。由于工业铝电解现场是一个强磁场、高温、高湿、含高浓度腐蚀气体、粉尘的环境,因此目前还难以在线获得过热度。
针对过热度软测量问题,我们提出了在线测量模型(见图12)以及基于时间粒的铝电解过热度预测模型等工作[24-26]。

表1 铝电解企业各层评价指标示例Table 1 Examples of evaluation criterion for each layer of aluminium electrolysis company
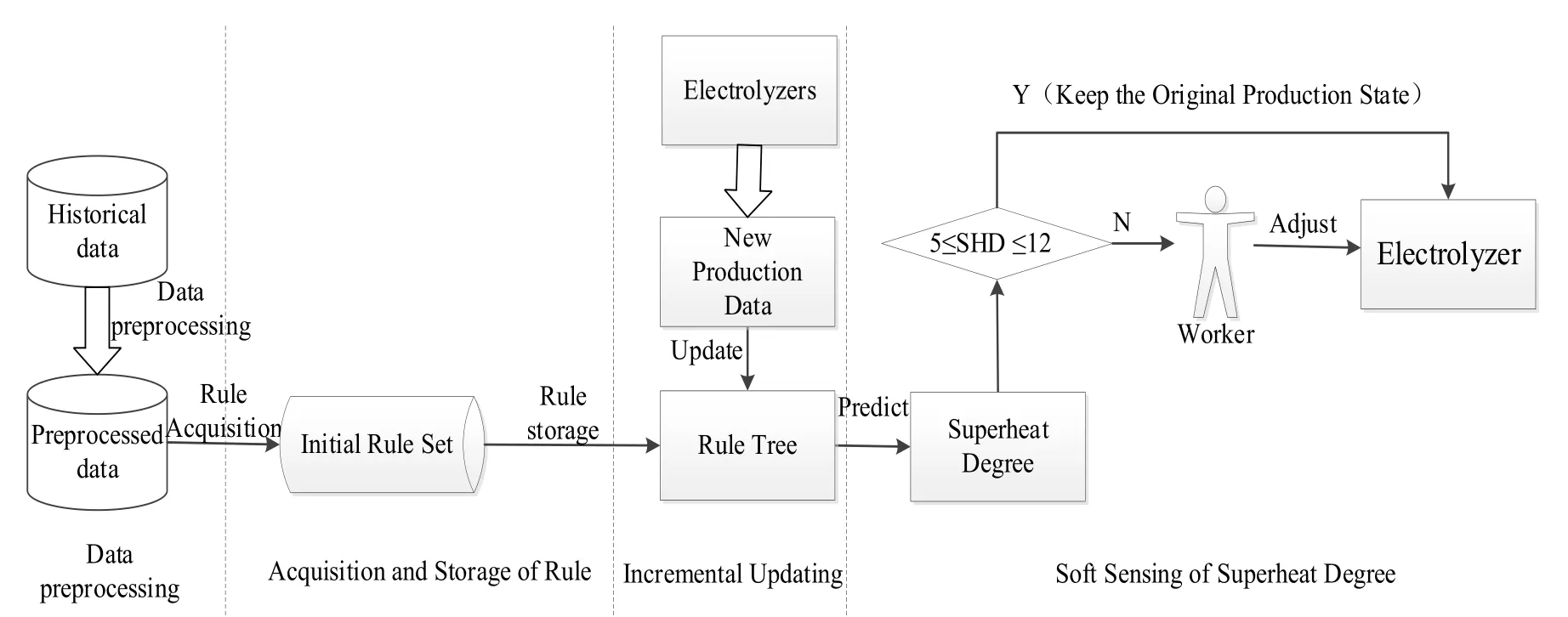
图12 铝电解过热度在线测量系统框架[24]Fig.12 Framework of on-line soft measuring on superheat degree in aluminum electrolysis[24]
4 结束语
在全球信息化快速发展的背景下,各行各业数据资源快速增长,尤其是一些特定应用领域数据规模庞大。大数据智能计算是实现大数据价值的必由之路,助推人类社会从信息化进入智能化。然而,当前大多数据智能计算模型所进行的数据计算机制,与人类大脑认知机制是不一致的,这导致了诸如机器学习的不可解释性,尤其是深度学习的不可解释性问题,以及反人脸识别问题等重大问题的出现。多粒度认知计算是一种结合人类“大范围优先”认知机制(由粗到细)与计算机系统信息计算处理机制(由细到粗)的大数据智能计算创新研究模型。本文简介了多粒度认知计算模型方法,并介绍了数据驱动的粒认知计算DGCC(Data-driven Granular Cognitive Computing)计算框架。同时,也介绍了多粒度认知计算在流程工业智能制造上的应用,提出了探索大数据智能计算的一种新理论模型。
利益冲突声明
王国胤、于洪声明不存在利益冲突关系。
