深度学习在医学影像分析中的应用综述
2020-01-15俞益洲马杰超石德君周振
俞益洲,马杰超,石德君,周振
深睿医疗人工智能研究院,北京 100080
引言
在现代医学的临床诊断中,除了望闻问切之外还有实验室检验、病理组织检查、影像学检查等方式。医学影像既是医疗的重要基础支撑,也是临床数据中最重要的诊断依据之一。但是,面对日益增加的医疗需求和随之而来的大量影像数据,传统影像科医师需要对每张片子进行仔细筛查和甄别,这一过于机械和重复性过程不仅耗费了大量的精力,而且容易导致疲乏,医生不免产生判断上的失误[1-2]。因此,引入人工智能(Artificial Intelligence,AI)技术辅助医生进行病灶定位和识别从而提升其检出率显得尤为重要。
近年来,计算机视觉和AI发展迅速,医学影像(Medical Imaging)和计算机辅助诊断(Computerassisted Diagnosis,CAD)成为了医学和计算机视觉的新兴交叉学科[3]。医疗影像庞大的数据量以及本身客观、可量化的特点,非常符合深度学习(Deep Learning,DL)[4]的应用场景,也使医学影像成为AI最有潜力的落地领域。目前在医疗领域,已有不少CAD在协助医生进行诊断,减少医生的工作量,为病人提供更优质的诊断、治疗以及预后指导。大量研究证实,基于AI的医学影像CAD可有效提高医生诊断的效率和准确率,尤其对于各种常见的癌症诊断,比如肺癌、乳腺癌等。据报道现阶段在胸部X光片中肺结核的识别准确率在90%-93%之间[5],胸部CT肺结节检出率在89%以上[6],这种迹象表明“医疗+AI”的结合已是大势所趋。
总的来说,以DL为核心的AI技术从价值层面有以下几项优势:第一,AI可帮助医生提升工作效率,尤其是影像中微小病变的检出。DL可帮助医生进行初筛,以“人机结合”的模式把医生从超负荷的工作中解放出来。第二,AI在临床应用中可大幅提高诊断的精度。医生可能会因为长时间阅片产生疲劳感,影响对病灶的判断,导致漏诊、误诊的风险。第三,AI技术可以缓解当前医疗资源分布不均衡带来的大量患者涌向医疗资源富集地区的问题。与此同时,AI辅助阅片相比医生单独阅片更具有一致性,且其标准化的流程可保证诊断结果的客观性与稳定性。
自2012年起,DL在医学影像领域积累了大量的研究和应用实例。近几年,已有国内外研究者对此进行了系统综述[7-9],从技术和应用等角度描绘了DL对于医学影像分析的贡献。然而,DL和医学影像研究近几年发展迅速,每年都会涌现出很多新方法和新应用,整个领域出现了以往综述涵盖不到的内容,比如已经进入临床验证阶段的肺结节辅助诊断系统在近几年出现了非常多的研究[6,50-53,55-56]。因此,本文试图在以往综述的基础上,梳理当前DL在医学影像分析中的研究进展,力图让读者了解这一领域最新的研究成果和动态。
本文将按如下结构分点论述,首先,我们将从几个视觉任务出发简要介绍DL技术,包括分类、检测、分割和其他任务。然后,选取多个常见病,较细致地阐述DL在特定疾病领域中开展的医学影像分析研究。接着,整体分析和总结DL在这些应用领域中的预测表现(特别是与传统方法以及人类专家的对比),呈现研究趋势以及存在的问题。最后,指出DL在医学影像领域的未来发展方向以及进入临床应用的前景。
1 DL模型及其应用场景
医学影像分析是CAD最重要的组成部分之一,在AI技术引入之前,医学影像分析是通过传统方法构建模型,如边缘检测、纹理特征提取、形态学滤波(如HOG[10]和SIFT[11]),本质是人为定义逻辑,因此扩展能力有限。DL是以数据驱动的建模方法,模型能隐式地从大规模数据集中学习特定任务的特征和数据特性,本质上是一个优化问题的求解,其性能可随着数据量的增加而提升。而且,DL可以利用GPU大幅加快计算速率[12]。使用DL进行医学影像处理,通常包含:数据增强/复原、图像/病灶分类、目标检测、区域分割、图像配准以及图像生成等方向,以下针对最常见的分类、检测、分割、配准任务做进一步介绍。
1.1 分类任务
图像分类是DL进入医学影像领域最早的应用之一,可被分为整图分类或目标分类。整图分类通常是以整张影像及其类别标签作为输入,对DL模型进行端到端(End-to-End)的训练,学习其特定类别下的数据特征。典型著作是2017年斯坦福大学发表在《自然》上的皮肤癌分类[13]。目标分类在医学中常见的是对特定病变进行类别区分或者严重程度分级,比如肺结节的良恶性分类。相比于整图分类,该任务更为精细,需要病变的局部信息以及与周围或者上下层面信息的结合,所以该任务通常会与其他任务结合进行。比如通过检测模型获取位置信息,通过分割模型获取边缘信息,通过时间序列模型获取上下层面信息等。
1.2 检测任务
通常,一个检测任务包含识别与定位。识别指的是判断属于某个特定类的物体是否出现在图中;定位指的是确定该物体在图中的位置。发现医学影像中的病变是临床决策中的关键一环,也是医生们最耗时耗力的任务之一。DL辅助检测病变最初的尝试源于1995年,Lo等[14]使用4层卷积神经网络(Convolutional Neural Network,CNN)辅助检测X射线图像中的结节。
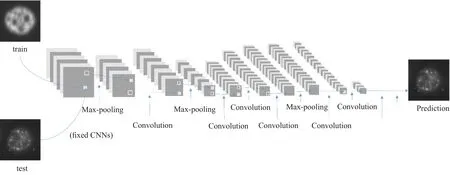
图1 分类模型结构Fig.1 The architecture of classification CNN model
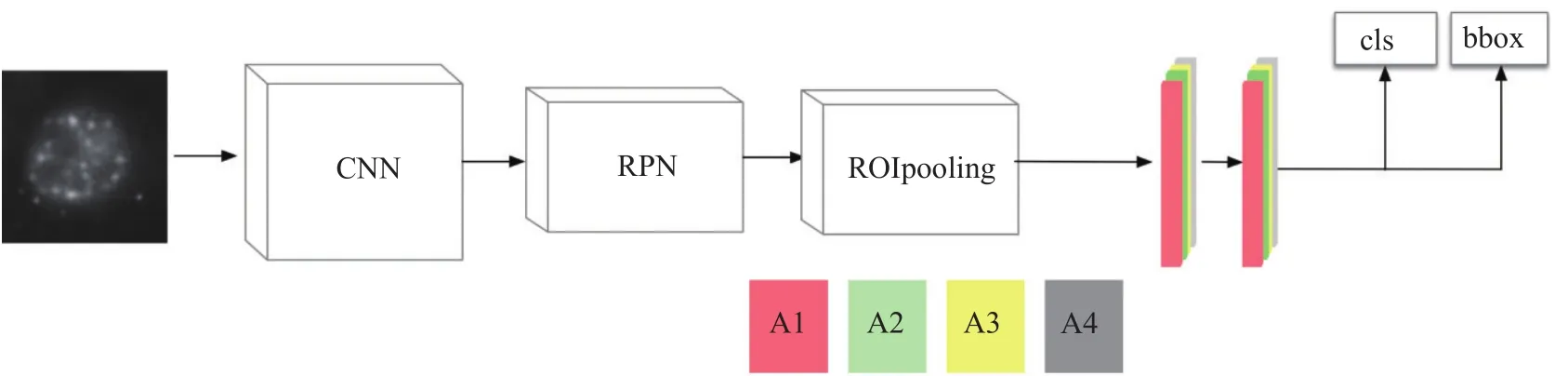
图2 检测模型结构Fig.2 The architecture of detection CNN model
当前DL在检测任务中常用的算法可以分为两个方向:一类是以Faster RCNN[15]为代表的双阶段(Two Stage)的方法,该算法思想分为生成候选框和识别框内物体两个步骤;另一类是以SSD[16],YOLO[17]为代表的单阶段(One Stage)的方法,该算法思想是直接预测目标的位置以及类别。由于医学影像相比自然图像具有一定特殊性,比如CT图像包含三维空间信息,MRI图像包含时间信息。研究者们在原框架上进行拓展使其更加适应于医学影像。Kong等[18]将在CNN算法上加入LSTM[19]算法来处理影像中的时间信息,用于检测心脏MRI的舒张末和收缩末;为了充分利用CT图像体素信息,Yan等[20]提出了一种利用3D信息的检测算法,进一步提高了病灶识别的准确率。
1.3 分割任务
图像分割任务主要是识别图像中感兴趣区域的体素信息以及外部轮廓。在医学领域主要应用为分割器官或病变,以便定量分析相关的临床参数,给后续诊疗做进一步的指导。例如,靶区勾画是临床手术图像导航和引导肿瘤放疗的关键任务。
在医学影像分割领域,一个突破性的研究是Ronneberger[21]在2015年提出的U-Net网络结构。该研究创新性地采用了一个对称的编码解码(Encoder-Decoder)结构,并通过跳层连接(Skip Connection)将上采样层与下采样层连接起来,用以融合高层的语义信息和底层的边缘信息。该模型后续被作为众多医学影像分割任务的参照基线(Baseline),在U型结构基础上后续还衍生出许多变种,如V-NET[22],3D UNET[23]等。
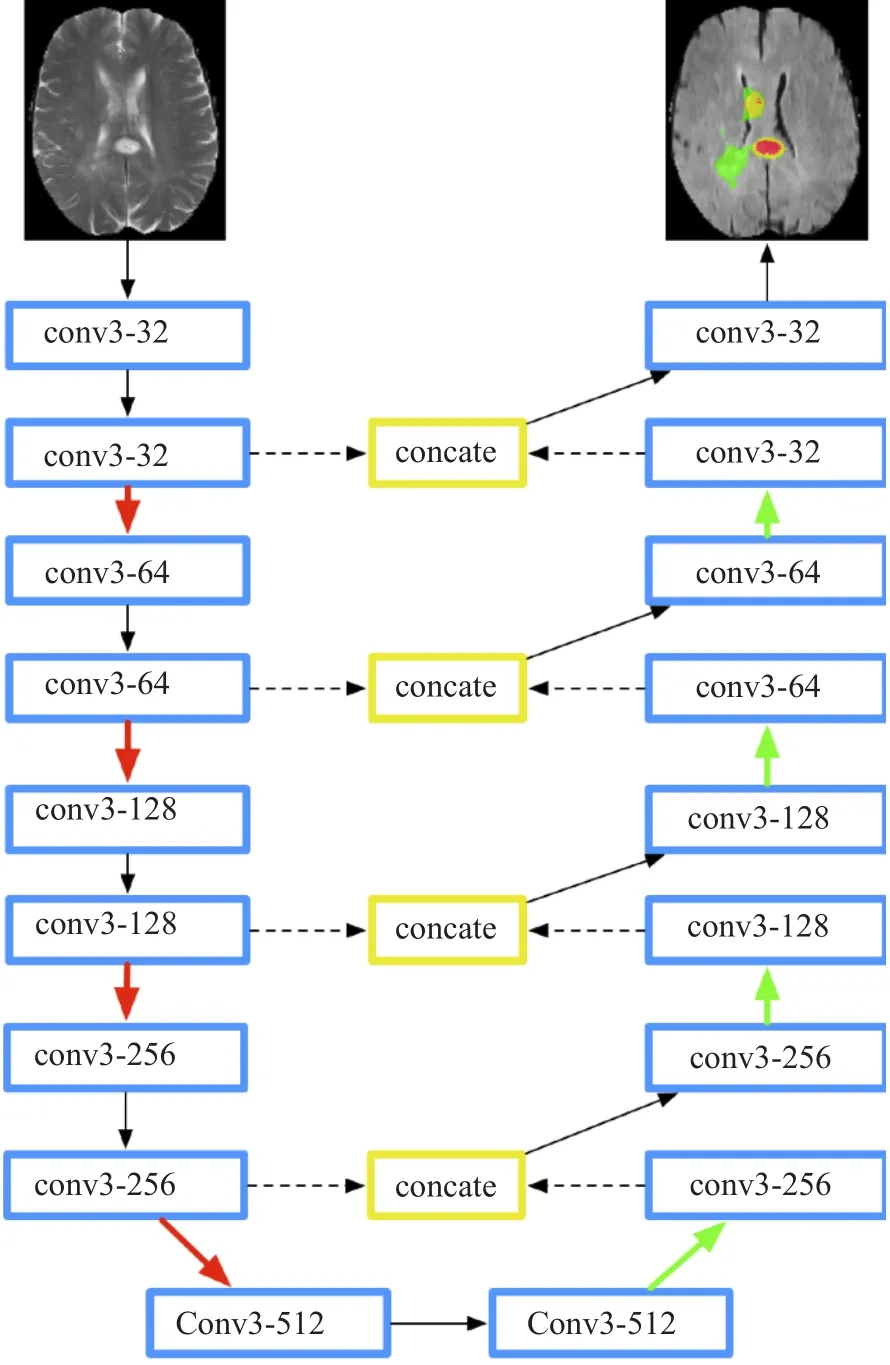
图3 分割模型结构Fig.3 The architecture of segmentation CNN model
1.4 图像配准

图4 有监督DL配准模型Fig.4 The architecture of a supervised deep learning model for registration
图像配准是医学影像分析的一个重要分支,目标是把多套图放到同一个坐标系下,实现图像内容之间的匹配,从而辅助影像学诊断——如融合PET与核磁定位肿瘤,以及治疗等[24]。传统研究者开发了大量的配准方法,包括刚性、非刚性和可变型变换。在DL兴起后,DL起初被用于增强传统方法的表现,即通过DL评估两幅图像的相似性,帮助迭代和基于灰度的方法完成配准[25]。为了实现更快的配准,之后研究者开始利用有监督DL(如图4)直接估计变换参数[26]。由于获取真实标注值成本高,最近的研究者开始利用非监督学习来估计变换参数[27]。和传统方法一样,DL配准方法面临的挑战仍然是量化图像的相似性,最近研究者试图利用信息论和生成对抗网络框架来应对这些挑战,并取得了一定成效[28]。
2 DL在医学影像诊断中的应用
在DL应用医学影像技术诊断中,医学影像特征的自动提取一直是算法的关键问题之一。本节从几种代表性疾病或异常出发,概述了DL对医学影像诊断领域的贡献。
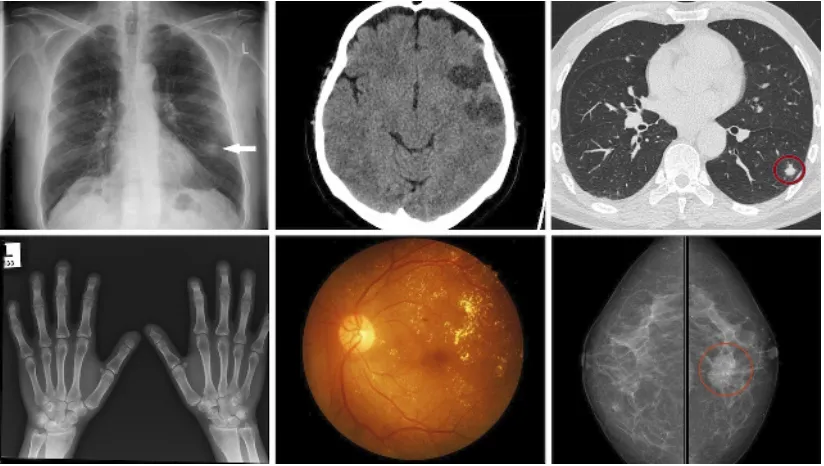
图5 DL在不同医学影像问题中的应用Fig.5 Medical image samples analyzed by deep learning
2.1 脑卒中(Stroke)
脑卒中的发病率已经超过心血管疾病,成为致死、致残率最高的疾病,并且发病率呈逐年上升的趋势[29]。脑卒中一般可分为缺血性和出血性两类,前者约占75%~90%,后者约占10%~25%[30]。目前,脑影像AI研究主要关注两方面:一是缺血性脑血管病急性期CT平扫的诊断,包括病灶的定位以及半暗带的体积预测;二是基于头颅CT血管造影的病灶检测或血管分割。
出血性脑卒中的主要关注点在于出血量以及出血区域。Chilamkurthy等[31]使用改进的ResNet网络,对每一张断层扫面进行分类,包括脑实质出血、硬膜下出血和硬膜外出血等多种出血类别。病灶检测方面,Chang等[32]使用了基于Mask R-CNN的实例分割框架,首先使用外接矩形框对脑出血区域进行定位,再对该区域的病灶轮廓进行勾勒。
对于缺血性脑血管病,其中一个研究方向是基于MRI弥散加权图像(Diffusion Weighted Imaging,DWI)序列的缺血性脑血管病的病灶自动识别以及ASPECT评分。Zhang等[33]利用3D CNN进行DWI核磁序列的脑梗分割,并利用稠密连接方式,优化网络的训练过程。Liu等[34]在3D CNN基础之上,增加了2D卷积操作来充分利用断层内部的影像信息。
脑血管分割主要应用于三维核磁血管造影数据,CNN模型在传统方法(如区域生长和主动轮廓模型)的基础上取得了不小的进展[35],但仍旧面临类别不均衡等挑战,即血管体素在三维影像中的占比极小。同时,CNN模型难以描述血管的连通性特征,容易出现血管分割断裂与不连通等情况,以及难以处理三维血管之间以及病变血管的结构差异[36]。
2.2 糖尿病视网膜病变(Diabetic Retinopathy)
绝大部分糖尿病患者会出现视网膜病变,简称糖网[37]。糖网是视力损害和永久失明的主要原因,治疗不及时视力将受到不可逆损伤,早期筛查对于挽救糖网患者的视力至关重要[38]。目前,糖网筛查方法主要依赖于眼科医生阅片,存在人工阅片的共性问题。糖网自动筛查吸引了大量的研究,特别是近几年兴起的基于DL的方法[39]。糖网的自动筛查研究主要关注了以下几个任务,包括糖网图像分类、视网膜血管分割和硬性渗出的自动检测。
糖网识别方面,2015年Kaggle组织了一个相关比赛,几只获胜队伍使用的都是端到端CNN模型,而且识别准确率接近甚至超越了医师[9]。其中,Quellec等[40]以此数据集为基础进行了糖网分类模型的热力图可视化研究,探索了CNN模型在糖网筛查中实现高精度的原理。Takahashi等[41]则直接利用多幅眼底图像的拼接图作为输入数据,实现了糖网病的自动分级。
视网膜血管分割方面,Jiang等[42]提出一种基于全卷积神经网络(Fully Convolutional Network,FCN)的端到端模型来实现视网膜血管分割,在DRIVE等4个公开数据集上取得了96%左右的准确度,同时超过了传统算法和人工标注[43]。Xiao等[44]以分割为基础构建了一个多步骤的糖网筛查DL系统,首先定位眼底图像中的血管、视盘、黄斑等,然后分割病灶,最后对病灶进行分类。
硬性渗出检测方面,Prentašić等[45]利用CNN分类网络通过滑窗取块方式对眼底图片的每个像素做渗出/非渗出二分类,并通过与眼部解剖关键点信息进行融合,提高硬性渗出的识别准确率。
2.3 肺结节(Lung Nodule)
肺癌在中国乃至全球都是发病率及死亡率最高的恶性肿瘤[46]。早期肺癌在CT上表现是直径不超过30mm的肺内圆形或不规则形结节。由于其侵袭性和异质性,早期诊断和干预对病人的生存至关重要[47]。目前的肺结节影像AI技术研究主要包括肺结节的检出、肺结节分割和肺结节的良恶性分类等方面。研究者们主要通过设计新的网络结构和损失函数来实现模型在相应功能上的性能提升。
肺结节检出方面,研究方向仍旧以两模型级联为主,即由候选结节检测模型和假阳消除模型级联。ANODE09是早期的肺结节检测比赛,大多数参与者都使用手工特征作为方法基础[48],检出率不足70%。DL兴起之后,大量该领域的研究者将目光转向CNN。Setio等[49]提出的多视角CNN检测模型敏感性达到85.4%。Zhu等[50]基于Faster R-CNN提出了DeepLung模型,在LIDC上该检测模型得到了92%的敏感性,每份CT假阳结节8个。Ma等[51]提出了一种基于分组卷积网络的单级检测模型,并在LUNA16上取得了较高的得分。在最近LUNA16挑战中,表现最好的模型使用的都是DL,检出敏感性超过95%,每份CT假阳1个[52]。对比研究还发现DL模型在微小结节(小于5mm)的检出上要优于人类医师[53]。因此,基于DL的结节检出模型具有较高的召回率和准确率,基本能够做到实时准确定位结节所在位置。
在结节分割方面,研究者们通常使用FCN来构建模型。Wang等[54]提出了一种多视角的肺结节分割模型,在LIDC公开数据集上取得了77.67%的Dice得分。Nam等[55]提出了一种新的肺结节分割模型,该模型使用结节直径作为真实标签,在LUNA-16上取得了78.78%的Dice得分。Cao等[56]提出了一种双路分割网络模型从而提升了模型的鲁棒性,并在公开数据集LIDC上取得了82.74%的Dice得分。基于DL的结节分割模型可以有效地提升各类结节的分割准确度,有助于提升医生测量和对比结节大小的准确度。
肺结节的良恶性分类一直是研究者的关注要点,并在DL模型上进行了一系列尝试和改进。Shen等[57]提出了深度层级语义网络模型,该模型在LIDC数据集上分类准确率为84.2%。为了提升不同特征的融合能力,Shen等[58]又提出一个多切片的网路结构,利用多角度信息以提高分类精度。Wu等[59]提出了分割和分类联合训练网络来提升准确率并试着提升模型的可解释性。Mundher等[60]提出了一种能够融合全局和局部信息的网络结构来提升分类效果,在LIDC上该模型的AUC达到了95.62%。相对于传统的良恶性判断方式,基于DL的良恶性判断模型可以融合更多的特征和具有更好的泛化能力以及更高的准确性。
2.4 肺栓塞(Pulmonary Embolism)
肺栓塞是一种严重的致死性疾病,体循环的各种栓子脱落阻塞肺动脉及其分支导致肺动脉部分或完全阻塞,引起肺循环障碍。如果不积极治疗,肺栓塞的死亡率接近30%。但是,如果及时、正确地采取措施,这一比率可以降低到2%至11%[61]。
目前,肺栓塞的主要诊断方式是CT肺动脉造影(CTPA),放射科医生需要仔细地追踪动脉的每一个分支来对肺栓塞进行筛查。并且,一些成像问题,例如呼吸伪影、血管运动伪影、部分容积因素等都会影响肺栓塞的诊断。因此,CAD成为帮助放射科医生更准确地检测和诊断肺栓塞的重要工具。
对于肺栓塞的研究,Rucco等[62]介绍了一种基于机器学习Q分析的综合方法,取得了94%的肺栓塞识别率。Bi等[63]提出了一种基于候选生成器的肺栓塞自动检测方法。在测试临床病例上达到了81%的灵敏度。Chen 等[64]采用无监督学习对肺栓塞进行分类,模型的AUC达到97%。
2.5 肺结核(Pulmonary Tuberculosis)
目前,全世界每年的新发肺结核病例有近1000万,其中有9%来自于中国,主要集中在经济落后、环境闭塞的地区[65]。肺结核传染性极高,往往是一人患病、全村感染,大面积筛查迫在眉睫。然而,这些地区医疗资源极度匮乏(CT普及率非常低),胸片成了唯一的初筛手段。巨大的检查量、单一病种、基层医师缺乏,都给胸片AI产品提供了巨大的用武之地。
近年来,基于胸部X光片的DL研究也得到国内外研究学者的广泛关注,研究方案大致可分为两类:基于传统有监督学习[66]和端到端DL[5]。Antani等[67]提出基于边缘图像特征提取的胸部多病种分类算法,首先对X线光片进行边缘的提取,然后提取纹理、形状等特征,最后利用多层感知机进行特征分类,给出X线光片的诊断结果。Jaeger等[68]提出X线光片的胸部多病种自动筛选算法,算法首先对X线光片的肺叶部分进行分割,对分割后的图像提取HOG、LBP等一系列特征,然后使用分类器对提取的特征进行训练得到胸部多病种分类模型。Hwang等[69]提出了第一个基于CNN的结核自动检测系统。为了克服深度神经网络训练的困难,采用迁移学习策略来提高系统的性能。Lakhani等[5]采用放射学增强的方法进一步提高了CNN模型模糊分类的准确性,得到了高达0.99的AUC。
2.6 乳腺疾病(Breast Diseases)
乳腺癌是全世界最常见的女性肿瘤并且是女性中致死率最高的癌种之一[70]。在我国,新诊断的乳腺癌病例占全球乳腺癌新发病例的12.2%,死亡率为9.6%。研究证实通过及早发现高危患者并适当治疗,可以降低乳腺癌死亡率[71]。数字化乳腺X 线检查(也称乳腺钼靶)由于其良好的对比度及分辨力,可分辨组织间细微结构密度的差别,且操作简单,价格相对低廉,诊断准确率较高,是国际上公认的乳腺癌早期机会性筛查及早期发现的有效措施。乳腺癌在乳腺钼靶的检查中主要有两种征兆:一是恶性软组织肿块的存在,二是微钙化的存在。
Kooi等[72]对比了传统特征提取方法和基于深度网络的肿块检测方法,证明CNN以低误报率和高召回率超越了传统CAD系统。Arevalo等[73]实现了基于CNN的肿块分类模型,实验结果也优于传统的特征提取方法。Fotin等[74]对比了CNN模型和基于人工特征的传统方法在数字乳腺断层合成显像中识别可疑或恶性软组织影的表现,结果DL模型的识别敏感度高出近7%。
钙化点(Micro-calcifications)是乳腺中微小的钙沉积点,是早期乳腺癌的重要征象,放射医师难以发现。传统方法利用钙化和正常组织在频率和亮度上的差异进行识别,比如使用小波变换[75]或者Hessian矩阵响应[76],其缺点是易受致密腺体的干扰且伴有大量假阳性。基于人工特征的有监督学习将钙化点识别敏感度提升到近90%[77]。DL模型则进一步提升了识别表现,Cai等[78]设计的CNN模型在高敏感度水平显著降低了假阳率。Zhang等[79]利用重构效果的差异,有效地将钙化点和背景区分开,极大提升了微小钙化的检出效果。
2.7 骨龄估计(Bone Age Assessment)
矮小和性早熟是我国小儿常见的两大内分泌问题[80],治疗不及时会严重影响患儿的生长发育。基于X光片的骨龄是生长发育评估的一项代表性指标,准确的骨龄诊断可反映个体的生长发育水平和成熟程度。然而,现有的骨龄X光片的判读方法难以兼顾效率和效果,而且依赖观察者主观判断,一致性差,导致骨龄结论不稳定,有损患者随访和治疗效果评估[81]。
近年来,多位国内外学者应用DL技术探索新的骨龄评估自动化方案,表明了DL技术在骨龄评估方面的巨大潜力。2017年RSNA举行了迄今最大规模的AI骨龄评估挑战赛(RSNA 2017 Bone Age Challenge)[82]。冠军团队Mark Cicoro和Alexander Bilbily将年龄预测处理成单纯的数值回归问题,预测结果的平均偏差降低到4.265个月。
目前基于评分法进行的AI骨龄评估研究报道较少。与基于图谱法的AI骨龄评估方法相比,基于评分法的模型能够智能定位目标骨,对每一枚骨化中心自动评级,可解释性更强。Joon Son等[83]人提出了基于TW3方法的DL骨龄评估方法,首先提取4块包含拇指、中指、小指的感兴趣区域,然后用目标检测的方法定位13块目标骨骺区域,最终通过分类网络得到骨骺发育水平级别评定。该工作取得了0.45年的平均绝对误差。
2.8 精神疾病(Psychiatry)
精神疾病发病率日益增加,如阿兹海默症(AD)全球患病率估计达到2400万,预计到2040年翻倍[84],社会负担不容忽视。精神疾病的诊疗中涉及大量的神经影像数据,也是DL很好的应用场景之一。目前,精神科的DL研究大部分都聚焦于诊断,并取得了喜人的结果。由于大规模公开神经影像数据集(如ADNI和AHDH-2000)的存在,AD和多动症(ADHD)诊断领域积累了大量的DL研究,模型分类准确率达到了90%以上[85]。其中一些研究还探索了模型预测精神疾病发展轨迹的应用,如从中度认知障碍到痴呆[86],这对发现早期疾病和预防疾病进展至关重要。对其他精神疾病,如精神分裂症、自闭症、帕金森病、抑郁、药物滥用和癫痫的诊断研究,相关研究尚处于缓慢积累阶段。此外,相比单模态数据,利用多模态数据可以提高预测模型的精度[87]。精神疾病的发病机制复杂,可能涉及神经系统多个水平的处理过程,多模态数据可提供有关发病机制的互补信息。但由于目前多模态数据量小,对模型精度的提升有限,未来大规模的多模态的数据有望充分展现出DL模型的性能。
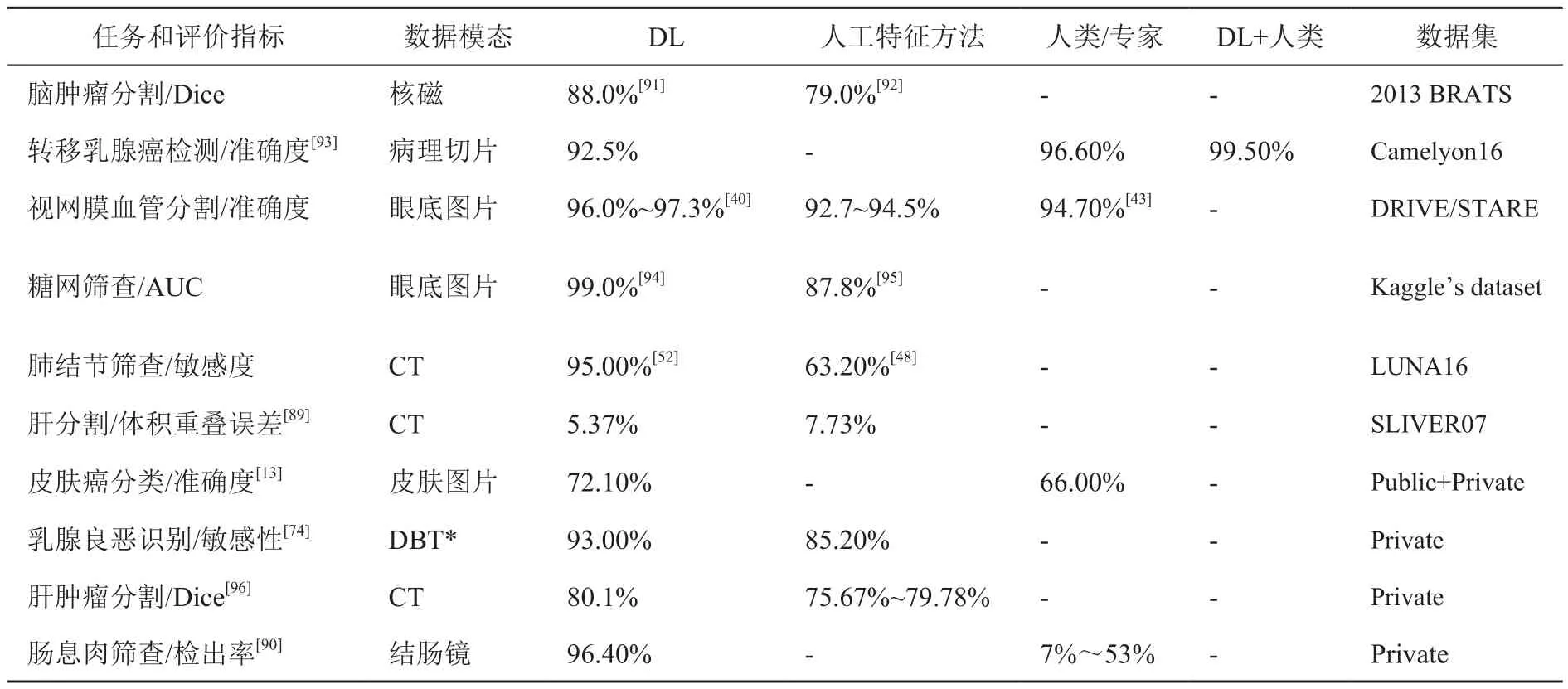
表1 在多种医学影像分析中DL与传统方法和人类的表现对比Table 1 The performance comparison of DL models with traditional methods and humans on multiple applications in medical imaging
除了以上提及的一系列疾病之外,还有很多疾病的预测和诊断都用到了DL中的方法,比如心血管疾病[88]、肝脏肿瘤[89]和结肠腺瘤[90]等。
3 讨论
通过以上总结可以发现,以DL为核心的AI结合医学影像大数据将CAD推向新的高度。借助DL在分类、检测、分割和配准等多个领域的突破性发展,AI在多种影像模态和多种疾病诊断中展现出巨大优势,包括精度高、速度快、结果稳定、可规模化等。几乎在各个方面DL都已经超越了传统的机器学习;在某些疾病上,AI的诊断表现已经比肩高年资临床医生,如肺结节检测和糖网识别,更多实例参见表1。借助算力强大的计算机,训练好的AI模型可实现秒级的结果生成,这对急性病症的诊断尤为重要,比如需要分秒必争的脑卒中诊断[33]。此外,AI预测效果稳定,不会疲劳,也不会出现观察者内或观察者间差异,可帮助减少漏诊、误诊等人为差错。最后,AI容易规模化,可以帮助有效应对日益增加的医疗需求,尤其是激增的医学影像读片任务。
AI同时还存在很多问题。首先,目前基于DL的AI属于监督学习,依赖大量的标注数据。正如计算机视觉领域的突破依赖大量数据(ImageNet有一百万的标注图片),要在医学影像领域得到更加鲁棒的DL模型,也需要大量的多样化数据集[97]。其次,图像数据的标注较难统一标准。比如,多种骨龄标准在临床上均有使用,基于单一的标准搭建的模型很难适应所有场景。另外,模型泛化能力欠佳。医学影像的采集参数存在医院间差异和个体差异,比如CT机型、重建卷积等。在某家医院数据集上训练出来的模型,在其他使用不同采集参数的医院中可能出现预测精度降低。这是模型过拟合的典型表现,可能源自数据量少,也可能由于数据类型太过单一。最后,DL模型的可解释性较差。少有研究探索了模型基于什么特征做预测。当模型预测结果与医生判断不一致时,医生得不到有效证据,从而调整判断[98-99]。最后,DL模型的选择没有标准。对于特定分类任务,选择什么样的模型,没有金标准。针对特定问题选取最优DL框架更像是一门艺术,而不是科学[100]。
AI的发展可能会有以下趋势:第一,继续设计新的网络结构和损失函数来实现模型在相应功能上的性能提升。第二,弱监督学习,使用现有大量医疗病历中不全、不准确、有歧义的标注数据,实现模型训练。第三,将临床先验知识纳入模型训练。第四,单病种识别到全病种识别。临床检查中,只需要解决一个定义明确问题的情况很少,如医师面对低剂量胸部CT,不仅要检出肺结节,而且还要检查是否存在肺气肿等其他异常征象。研究者开始提出是否可以搭建一个同时解决多个问题的网络,如同时解决异常检测、组织分割、性质分类等。有研究表明,用一个网络解决多个问题,并不会降低网络在特定任务中的表现[101]。此外,AI还有可能在一些医学机理尚未明晰的领域进行探索,比如基于大规模神经影像分析的DL模型将有望让精神疾病的诊断更加客观标准。
4 结论和展望
放射科本质上是数据驱动的学科,天然适合于大规模数据处理。DL有望切实提高病灶的检测、分类、量化和分割。利用这一强大工具,放射医师在解读影像中更加准确,错误更少,因此可花更多时间在患者身上。AI算法在放射科一系列任务中展示了强大的潜力,解决了很多医学上的难题,但在落地时依然会面临很多问题,包括大规模的临床验证、患者隐私保护以及法律问责等。然而,尽管困难重重,但是结合当前的医疗行业趋势以及DL的快速发展,可以预想DL在医疗方面的应用将会有更大的需求。
利益冲突声明
所有作者声明不存在利益冲突关系。
