集值和区间值的多元时间序列
2020-01-14李寿梅
钟 钰,李寿梅,章 磊
(北京工业大学应用数理学院,北京 100124)
时间序列分析的研究有着悠久的历史以及大量的学术成果, 并在很多领域中都有着广泛的应用, 例如Box等[1]、Tsay[2]、Brockwell等[3]的专著及其所引用的参考文献. 经典时间序列模型研究的对象通常是随着时间推移而形成的随机变量或随机向量序列, 通过建立时间序列模型来分析这些序列的动态规律.
然而, 随着技术的发展, 人们收集到的数据变得更加复杂, 经典的时间序列模型不再适用于一些较为复杂的数据. 例如, 在分析股票数据时通常选取每个交易日的收盘价作为研究对象. 然而,当今的技术使得股票数据刷新频率很高, 收盘价并不足以反映当天股票价格的变化. 比如说, 某一个交易日里某一支股票价格所有的观测值为x1,x2,…,xn,这里n的值很大,而收盘价只是集合{x1,x2,…,xn}中的一个元素. 为能更准确地研究股票数据,有一种方法是取每个交易日里股票价格的最高价和最低价,将其作为一个区间的2个端点,即研究对象是
Xt=[min{x1,x2,…,xn},max{x1,x2,…,xn}]
将区间Xt视为一个数据单元来研究问题. 可以看出,区间Xt不仅包含了收盘价的信息,而且还有当天股价变动的情况,这无疑是一个好的处理方法. 通过区间值或集值数据来描述一类复杂数据,是一种分析复杂数据的手段. 另一方面,由于系统的复杂性,使得到的数据是某个范围而不是一个确定的实数值. 比如让专家估计明年中国的经济增长率,专家们往往会给出3%~6%,3.5%~5.7%这样的数据,显然用区间来刻画这类数据更加贴切. 引入区间值和集值数据,不仅是对观测数据的一种处理方式,而且还是对收集到的数据一种客观并且准确的体现.
事实上,区间是集合的一个特例,区间值随机变量的相关性质都可以从集值随机变量的性质中推导. 自从20世纪中叶,以经济学诺贝尔奖获得者Aumann和Debreu为代表的一批研究者在研究市场均衡等经济问题时引入了集值映射的概念及方法,集值随机理论有了较为完善的发展. Aumann[4]通过集值随机变量的选择集给出了集值随机变量期望的定义,这里集值随机变量的期望是选择集中元素的期望构成的集合. Hiai等[5]定义了集值随机变量的条件期望. Lyashenko[6]讨论了欧式空间中集值随机变量的性质,提出了集值随机变量方差的定义,并给出了集值高斯随机变量的定义及表达定理. Vitale[7]研究了集合的Lp距离的性质. 需注意的是,相较于集合的Hausdorff距离,Lp距离具有非常好的数学性质,这使得集值和区间值的统计模型大多数都建立在Lp距离之上. Diamond[8]讨论了区间值仿射函数的最小二乘估计方法. Li等[9-10]研究了集值鞅的收敛性问题. Li等[11]的书中系统地总结了集值随机变量的空间、期望与条件期望,强大数定律与中心极限定理等理论. Gil等[12]推广了Lp距离. Yang等[13]通过Lp距离定义了集值随机变量的协方差和相关系数,并讨论了方差、协方差和相关系数的性质. 张文修等[14]的书中阐述了集值随机过程的一系列理论.
作为集合最简单的特例,区间值时间序列被广泛地讨论. 有一类文献是将区间的2个端点或中心半径看作2个实值随机变量,然后通过区间的2个端点或中心半径来给出区间值时间序列模型,例如Wang等[15]、González-Rivera等[16]、唐娜娜[17]等. 而另一类文献则是将区间值数据看成一个整体,使用集值随机理论来分析区间值数据,并建立区间值时间序列模型,例如王洵[18]、Wang等[19]、章磊[20]等.
区间值时间序列可以看作集值时间序列的一个特例,区间值时间序列的相关理论可以通过集值时间序列推出,而对集值时间序列的讨论建立在集值随机过程理论的框架下. 张文修等[14]的专著中,系统地介绍了集值随机过程的一系列理论. Wang等[21]定义了严平稳的集值随机过程并讨论了它的一系列性质. 然而,虽然在严平稳性的条件下,集值随机过程有许多好的性质,但在实际应用中难以使用. 因此Wang等[19]通过集值随机变量的期望[4]和协方差[13]定义了集值时间序列的弱平稳性,并进一步讨论了弱平稳条件下集值时间序列统计量的估计及其渐近性质.
本文在Wang等[19]、章磊[20]研究的基础之上,进一步讨论了集值随机向量和集值多元时间序列的相关定义及性质. 首先,给出集值向量与集值随机向量的相关理论;然后,讨论集值多元时间序列;第三,给出集值多元时间序列在区间值情形下的应用;第四,给出区间值多元自回归模型的一个实证分析;最后,简要地给出结论.
1 集值向量与集值随机向量
1.1 集合与集值向量
A+B={a+b:a∈A,b∈B}
ΛA={λa:a∈A},∀λ∈
Vitale[7]通过支撑函数定义了K(d)中2个元素间的Lp距离,1≤p<∞. 集合A∈K(d)的支撑函数定义为
不失一般性,本文接下来取p=2. 进一步地,由Yang等[13]可知空间(K(d),L2)是完备可分的.
称由k个K(d)中的集合A1,A2,…,Ak构成的集值向量A=(A1,A2,…,Ak)T为k维集值向量. 记k维集值向量族为Kk(d). 需注意的是,集值向量A是kd中一个k维的超立方体. 由于假定了集值向量中每个元素都是Kk(d)中的集合,因此,可以推出关系式Kk(d)⊆K(kd)成立.
假定k≤m,任意的k维集值向量和m维集值向量A=(A1,A2,…,Ak)T,B=(B1,B2,…,Bm)T间的加法运算定义为
A+B=(A1+B1,…,Ak+Bk,Bk+1,…,Bm)T
进一步地,k维集值向量A与p×k的实值矩阵Λ=(λi,j)i=1,2,…,p,j=1,2,…,k间的矩阵乘法运算定义为
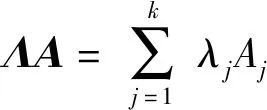
1.2 集值随机变量
令(Ω,A,P)是一个完备的概率空间. 称集值映射X(ω):Ω→K(d)为一个集值随机变量,如果对于任意开集C,都有X-1(C)∈A,式中X-1(C)={ω∈Ω:X(ω)∩C≠∅}.
记u[Ω,K(d)]为K(d)中的集值随机变量族. 2个集值随机变量X1、X2间的D2距离定义为
接下来可以通过Aumann[4]积分,给出集值随机变量X期望的定义
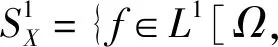
式中L1[Ω,d]为一阶矩存在的实值随机向量族.
注意到u[Ω,K(d)]并非是一个线性空间,这使得许多通过线性空间的特性讨论的统计问题无法平行地推广至集值的情形,例如并不能直接定义集值随机变量的方差和协方差,然而,可以通过D2距离来刻画集值随机变量的离散程度. Yang等[15]讨论了通过D2距离定义的集值随机变量方差的性质,并给出了集值随机变量协方差和相关系数的定义.
对于u[Ω,K(d)]中的元素,进一步地记
为所有D2距离存在的集值随机变量族. 集值随机变量X1,X2∈L2[Ω,K(d)]的方差、协方差和相关系数分别定义为
式中Var(X1)Var(X2)≠0.
为便于接下来的讨论,下面给出集值随机变量协方差的一些性质.
命题1集值随机变量X1、X2、X3的协方差具有下面几个性质:
1) Cov(C,X1)=0,式中C是一个常集合.
2) Cov(λX1,X2)=λCov(X1,X2),式中λ≥0是一个常数.
3) Cov(X1+X2,X3)=Cov(X1,X3)+Cov(X2,X3).
命题1的证明以及关于集值随机变量方差、协方差的更多性质见Yang等[13]、Wang等[19].
1.3 集值随机向量
考虑完备的概率乘积空间
(Ω1,A1,P1)×…×(Ωk,Ak,Pk)
称向量X=(X1,X2,…,Xk)T为k维集值随机向量,如果X1,X2,…,Xk是K(d)中的集值随机变量. 记u[Ω1×Ω2×…×Ωk,Kk(d)]为k维集值随机向量族.
k维集值随机向量X的期望E[X]定义为
E[X]=(E[X1],E[X2],…,E[Xk])T
式中E[X1],E[X2],…,E[Xk]为X的不同分量在不同的概率测度P1,P2,…,Pk下的期望. 然而为了简化记号,并不对不同概率测度下的期望加以记号区分,下面的协方差阵和交叉协方差阵等记号也同样.
如果k维集值随机向量X1=(X1,1,X2,1,…,Xk,1)T,和X2=(X1,2,X2,2,…,Xk,2)T的每一个分量都有Xi,j∈L2[Ωi,j,K(d)],i=1,2,j=1,2,…,k,那么X1的协方差阵为
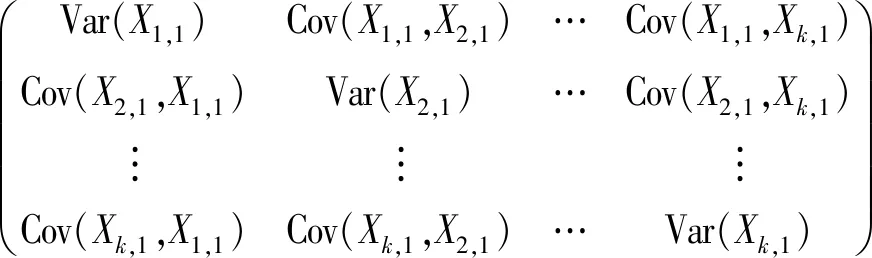
X1和X2的交叉协方差阵为
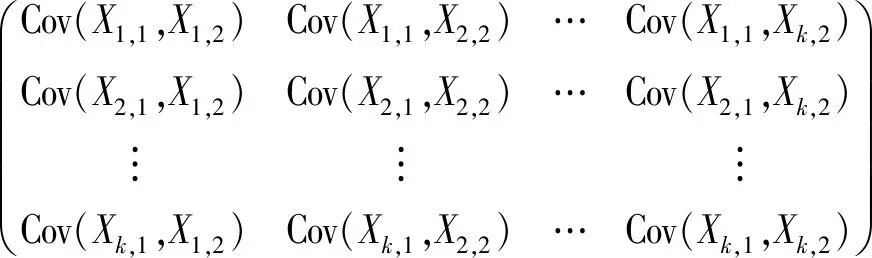
X1和X2的交叉相关阵为
命题2k维集值随机向量X1、X2、X3的交叉协方差阵具有下面几个性质:
1) Cov(X1,X2)=Cov(X2,X1)T.
2) Cov(C,X1)=0k×k,式中C=(c1,c2,…,ck)T是一个常集值向量,0k×k是k×k的零矩阵.
3) 下面关系式成立
Cov(X1+X2,X3)=
Cov(X1,X3)+Cov(X2,X3)
4) Cov(PX1,QX2)=PCov(X1,X2)QT,式中P=(pi,j)i=1,…,p,j=1,…,k,Q=(qi,j)i=1,…,p,j=1,…,k是2个所有元素都非负的实值矩阵.
证明:
1) 由下面的表达式

可证得1).
2) 由命题1,可以推出
Cov(C,X1)=(Cov(ci,Xj,1))i,j=1,…,k=(0)i,j=1,…,k
即为2).
3) 由命题1,可以推出
Cov(X1+X2,X3)=
(Cov(Xi,1+Xi,2,Xj,3))i,j=1,…,k=
(Cov(Xi,1Xi,3)+Cov(Xi,2Xj,3))i,j=1,…,k=
Cov(X1,X3)+Cov(X2,X3)
即为3).
4) 由命题1,可以推出
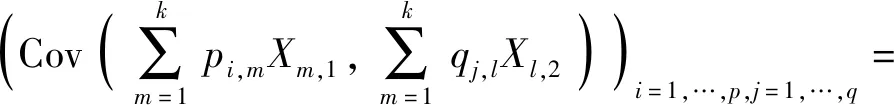
即为4).
2 集值多元时间序列
2.1 集值多元时间序列
Wang等[19]在集值随机变量及其期望、方差、协方差等统计量的定义的基础上,定义了集值时间序列,并给出集值时间序列的平稳性、自协方差函数和自相关函数的定义. 在Wang等[19]的基础上,进一步给出集值多元时间序列的定义,并讨论其性质.
对于集值多元时间序列的研究,不能将其视为一个更高维空间中的集值时间序列. 记Ω=Ω1×Ω2×…×Ωk. 虽然一个u[Ω,Kk(d)]中的元素同时也是u[Ω,K(kd)]中的集值随机变量,但直接将其视为一个集值随机变量来做进一步的讨论,这样就忽略了集值随机向量的几何信息. 因此应对其特别对待,下面给出集值多元时间序列的定义.
定义1称由时间{t=1,2,…,T}生成的k维集值随机向量序列X1,X2,…,XT∈u[Ω,Kk(d)]为一个k维集值多元时间序列.
定义2如果对于∀t=1,2,…,T,一个k维集值多元时间序列X1,X2,…,XT,都有: 1) E[Xt]≡X0是一个常的集值向量, 2) Cov[Xt]=E[(Xt-X0)(Xt-X0)T]是k×k的常实值正定矩阵,那么称这个k维集值多元时间序列X1,X2,…,XT是弱平稳的.
由定义2可知,如果一个集值多元时间序列的前两阶矩不随时间变化而变化,那么这个序列就是弱平稳的. 由于严平稳性的定义过于严格,就使得在实际应用中很难找到满足严平稳定义的序列,因此在这里不再讨论集值多元时间序列严平稳性的定义. 进一步地,将弱平稳简称为平稳.
下面引入k维集值多元时间序列的交叉协方差阵的定义.
定义3滞后为l的k维集值多元时间序列的交叉协方差阵定义为
ΓlCov(Xt,Xt-l)
滞后为l的交叉相关阵定义为
命题3如果k维集值多元时间序列X1,X2,…,XT是平稳的,那么其交叉协方差阵和交叉相关阵具有下面几个性质:
3) 对于任意的λ1,λ2,…,λT∈k,T∈{1,2,…},都有
证明:
1)由平稳性可以推出

2) 由平稳性可知Dt=Dt-l,可推出2).
3) 由平稳性,可以由下面的计算
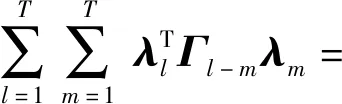
证得3).
2.2 平稳的集值多元时间序列统计量的估计
下面讨论集值多元时间序列期望向量,交叉协方差阵及交叉相关阵的估计. 假定X1,X2,…,XT是平稳的k维集值多元时间序列的观测值.
期望向量X0的矩估计为
0(1,0,2,0,…,k,0)T=
对于l=0,1,…,L,L≪T,滞后为l的交叉协方差阵的矩估计为
式中
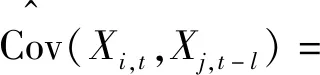
滞后为l的交叉相关阵的矩估计为
l=-1l-1
定理期望向量和交叉协方差阵的估计0和l具有下面的渐近性质:
2) 如果当l→∞时,Γl→0k×k,那么l是一个渐近无偏估计,即成立.
证明:
1) 对于任意的i=1,…,k,有
对于∀ε>0,T→∞,由Wang等[19]中定理1和定理6可知关系式
成立,由此可证得1)成立.
2) 只需证明
注意到关系式
(s(x,Xi,t)-s(x,i,0))(s(x,Xj,t-l)-s(x,j,0))=
(s(x,Xi,t)-s(x,Xi,0))(s(x,Xj,t-l)-s(x,Xj,0))+
(s(x,Xi,t)-s(x,Xi,0))(s(x,Xj,0)-s(x,j,0))+
(s(x,Xi,0)-s(x,i,0))(s(x,Xj,t-l)-s(x,Xj,0))+
(s(x,Xi,0)-s(x,i,0))(s(x,Xj,t-l)-s(x,j,0))
成立,进而由集值协方差的定义可以得出关系式
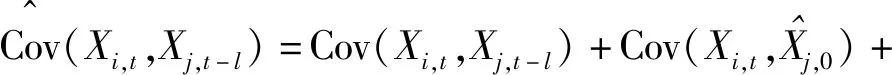
又当l→∞时,有Cov(Xi,t,Xj,t-l)=0,再结合期望向量估计0的表达式,可以推出
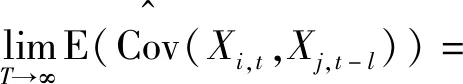
渐近无偏性2)得证.
2.3 平稳的集值多元时间序列的最优线性预测
下面讨论给定平稳的k维集值多元时间序列观测值X1,X2,…,XT后,如何求得超前h步的最优线性预测问题,h=1,2,…. 首先,定义一个用于衡量预测质量的准则,那么使得这个准则达到最优的X1,X2,…,XT的某一个线性组合,即为最优线性预测.
那么称
T+h=A0+a1XT+…+aTX1
为最优线性预测,式中A0=(A1,0,A2,0,…,Ak,0)T为k维集值向量截距,a1,a2,…,aT为k×k的实值系数矩阵,如果T+h使得均方预测误差矩阵达到最小,即
3 区间值多元时间序列
3.1 区间与区间值随机变量
当d=1时,将1简写为,那么K()为中所有非空有界闭区间族,即
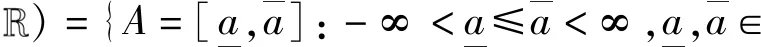
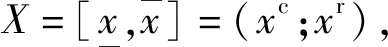
进一步地,区间值随机变量X的期望可以写为
u[Ω,K()]中区间值随机变量X1和X2间的D2距离可以写为
L2[Ω,K()]中的区间值随机变量X1、X2的方差和协方差可以写为
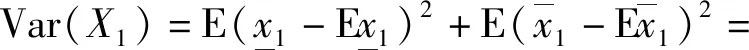
3.2 区间值向量与区间值随机向量

称向量X=(X1,X2,…,Xk)T为k维区间值随机向量,如果X1,X2,…,Xk是K()中的区间值随机变量. 记u[Ω1×Ω2×…×Ωk,Kk()]为k维区间值随机向量族.
k维区间值随机向量X的期望E[X]为
k维区间值随机向量的协方差阵,交叉协方差阵及交叉相关阵形式与k维集值随机向量的相同,在此不再给出.

3.3 平稳的区间值多元时间序列
平稳的k维区间值多元时间序列由时间生成的k维区间值随机向量序列X1,X2,…,XT组成,并且其前二阶矩不随时间变化而变化.
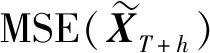
T+h=A0+a1XT+…+aTX1=
3.4 区间值多元自回归模型
p阶的k维区间值多元自回归模型,简记为IVAR(p)模型,其表达式为
Xt=Φ0+φ1Xt-1+φ2Xt-2+…+φpXt-p+Zt
记Γ0=Cov(Xt)为k维区间值多元时间序列的协方差矩阵,Zt的协方差阵为Σ. 由IVAR(p)模型的表达式可以推出IVAR(p)序列Xt的协方差阵为
Γ0=φ1Γ1+φ2Γ2+…+φpΓp+Σ
另一方面,对于∀l>0,由IVAR(p)模型的表达式可以推出关系式
Γl=φ1Γl-1+φ2Γl-2+…+φpΓl-p
成立. 然后分别取l=1,2,…,p,联立方程组,可以得到
4 数值模拟与实证分析
4.1 数值模拟
考虑一个一阶的2维区间值多元自回归模型
Xt=Φ0+φ1Xt-1+Zt,t=2,3,…,T
4.2 实证分析
本节分析2017- 06-16—2017- 08- 08北京市的空气指数数据,数据收集于网站http:∥beijingair.sinaapp.com. 数据由北京市12个空气监测站所收集到的空气指数、空气水平、主要污染物、PM 2.5、PM 10、CO、NO2、SO2的质量浓度组成,每个观测站收集到的数据都是每小时更新1次.
本文的研究对象是PM 2.5和PM 10的质量浓度,取每一天里这些空气监测站收集到的PM 2.5和PM 10质量浓度的最小值和最大值作为当天的区间值随机向量观测值的端点,并分别记每天的PM 2.5和PM 10的质量浓度为X1,t和X2,t. 为计算方便,将所有数据除以100. 图1给出了由PM 2.5和PM 10的质量浓度组成的区间值二元时间序列.
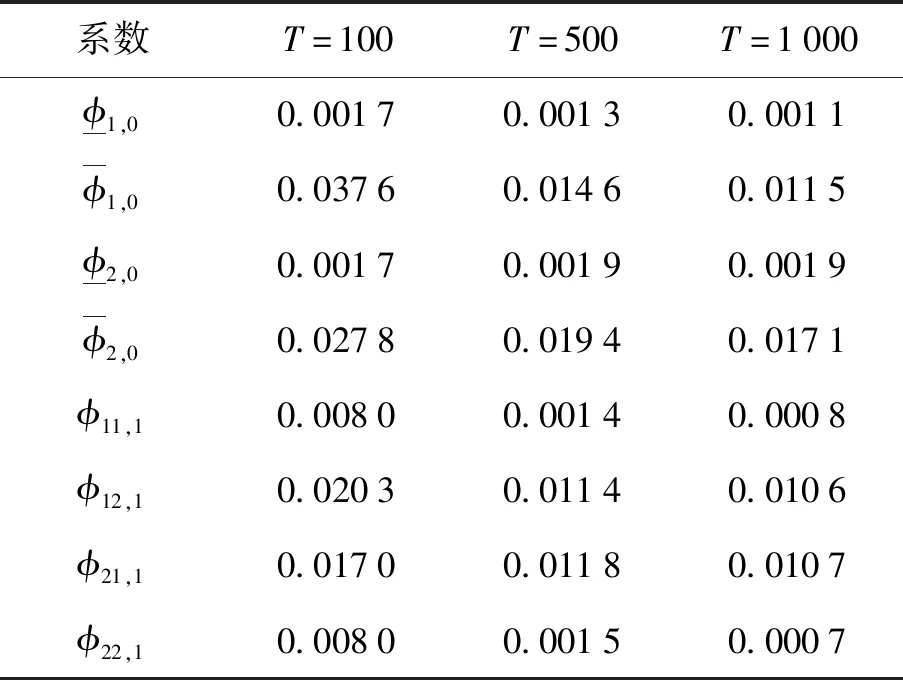
表1 系数估计的均方误差
通过计算,可以得出区间值多元时间序列{Xt=(X1,t,X2,t)T:t=1,2,…,54}的协方差矩阵和自协方差矩阵的估计
由上面的估计可以推出IVAR(1)模型系数的估计
1,0=[0.065 1,0.069 1],2,0=[0.482 0,0.736 4]
进一步地做了3步预测,如图2所示,实线段是真实的观测区间,虚线段是通过IVAR(1)模型得到的预测区间. 可以看出,预测区间明显地反映出了接下来的趋势. 进一步地,可以计算出T+1、T+2和T+3的均方预测误差为
5 结论
1) 对于实际中多元的复杂的时间序列数据,探讨多元集值时间序列基础理论,建立其时间序列模型是非常必要的. 由集值随机向量的定义可知,集值随机向量是一个具有特定几何特征的集值随机变量. 如果忽略这个向量形式而依旧将其视为集值随机变量来讨论相关的问题,将会导致信息的损失,这是一种非常粗糙的处理方式. 因此,从集值向量的定义出发,进一步定义了集值随机向量,并讨论了集值随机变量的期望向量、协方差阵、交叉协方差阵以及交叉相关阵的定义及性质.
2) 由于区间可以通过它的2个端点或中心半径来确定,因此对区间值多元时间序列的讨论是一个相对更为具体的问题. 相较而言集合则抽象得多,对集值多元时间序列的讨论本质上是对区间值多元时间序列的一个推广. 给出了集值多元时间序列及其平稳性的定义,并研究了在平稳的条件下,集值多元时间序列的期望向量、交叉协方差阵与交叉相关阵的性质,这些统计量的估计及估计的渐近性质,以及最优线性预测问题. 以上研究为对集值多元时间序列的进一步讨论打下了理论基础.
3) 讨论了区间值情形下的随机向量和多元时间序列,并进一步给出区间值多元自回归模型的表达形式及估计. 最后,通过一个实证分析展示了本文提出的模型及方法在实践中的应用.
