基于GA-ELM混合模型的急性心肌梗死定位算法研究
2020-01-14张行进李润川张宏坡王宗敏
张行进 李润川 张宏坡 逯 鹏 王宗敏,3*
1(解放军信息工程大学数学工程与先进计算国家重点实验室 河南 郑州 450001)2(郑州大学互联网医疗与健康服务河南省协同创新中心 河南 郑州 450000)3(郑州大学产业技术研究院 河南 郑州 450000)
0 引 言
心血管疾病是严重威胁人类健康的疾病之一,随着社会经济的发展和国民生活方式的改变,以及人口老龄化和城镇化进程的加速,我国心血管病的发病人数快速持续增长。急性心肌梗死[1]指营养心肌的冠状动脉发生病变,冠状动脉血供急剧减少或完全中断,使相应心肌严重而持久的缺血缺氧所引起的心肌细胞损伤甚至坏死。心肌梗死具有极高的死亡率和致残率。对于急性心肌梗死患者,若能在2小时内打通堵塞血管,恢复心肌供血,绝大多数心肌都可以免于坏死。心肌梗死的症状很多,但也有许多患者仅出现轻微症状或根本没有症状,容易因误诊而错过最佳救治时机,所以为了辅助医生快速准确地做出临床诊断,构建精准的心肌梗死定位算法至关重要。
本文提出了一种结合遗传算法和极限学习机的GA-ELM混合算法,用于心肌梗死的定位,可行性高、识别率高、速度快、具有可扩展性。
1 相关工作
针对心肌梗死的计算机自动分析诊断,国内外的研究者提出了各种不同的解决方法。他们通常在对采集到的心电信号进行去噪预处理[2],其次确定R波峰的位置[3-4],然后用类似的方法定位Q波起点[5],S波终点[6],P波和T波的峰值点、起点和终点[7],最后获得心电波形的电压幅值和时间间隔值作为特征。依据这些特征,医生根据对应的诊断规则实现心肌梗死的检测和定位。但由于心电波形的多样性和复杂性以及种族个体的差异性,完全依赖于医生的临床经验,具有一定的局限性。
国内外研究者提出了各种针对急性心肌梗死的自动检测和定位算法。Sopic等[8]采用随机森林分层分类方法,实现了心肌梗死的检测。为了应用于实时分析系统,研究者逐层增加特征数量,以减少分类所需要的时间。Acharya等[9]使用标准II导联的心电数据,采用卷积神经网络(Convolutional Neural Networks,CNN)方法实现了心肌梗死的检测。Lui等[10]使用PTB心电数据库上标准I导联的数据,采用卷积递归神经网络实现了心肌梗死的检测。Chang等[11]首先使用隐马尔科夫模型(Hidden Markov Model,HMM)从V1~V4胸导联信号中提取特征,然后采用SVM和高斯混合模型(Gaussian Mixture Model,GMM),实现了心肌梗死的检测。Seenivasagam等[12]采用前馈神经网络(Feed-Forward Neural Network,FFNN)和SVM实现了心肌梗死的检测。Remya等[13]采用多分辨率方法提取Q波峰值和ST段抬高等特征,使用简单的自适应阈值(Simple Adaptive Threshold,SAT)方法实现了心肌梗死的定位。文献[14]使用SVM方法,实现了五类心梗和健康对照的定位。Safdarian等[15]提取T波积分和全积分作为特征,然后采用概率神经网络(Probabilistic Neural Network,PNN)完成心梗定位。文献[8-12]仅实现了二分类研究即是否存在心肌梗死的检测,并没有进行心梗部位的定位分析。文献[13-15]在前人的基础上,研究心肌梗死的定位,但仅使用了部分导联的心电数据来提取特征。虽然导联数据的减少,使算法的计算速度有所提升,但是不同导联下获取的心电图记录具有无可代替的临床价值,人为减少导联数据会导致有效信息的缺失,直接影响到心肌梗死定位的准确性。
2 实验数据
常见类型的心肌梗死病症可以根据常规心电图的波形特征改变来判断。其典型特征有:ST段斜型抬高,T波高耸;ST段弓背或水平型抬高;T波对称性倒置;对称性倒置T波由深变浅;T波恢复正常或长期无变化;加深而增宽的病理性Q波。在心肌梗死发作期间,患者可能经历许多严重症状,例如:剧烈而持久的胸骨后疼痛,呼吸短促,意识丧失,并伴有心电图进行性改变。
本文采用国际权威的公开心肌梗死临床PTB数据库作为验证。该数据集包含549条心电图记录,分别采集自290名受试者,其中男性209名,女性81名,男女比例约为2.6∶1。每条记录大约2分钟,包括同步测量的15个信号:临床常用的标准12导联以及3个Frank导联心电信号。心肌梗死临床数据库主要包括有心肌梗死、心率衰竭、房室束支传导阻滞患者和健康对照者等,受试者平均年龄约为57岁。PTB临床诊断类别及受试者人数统计情况如表1所示。
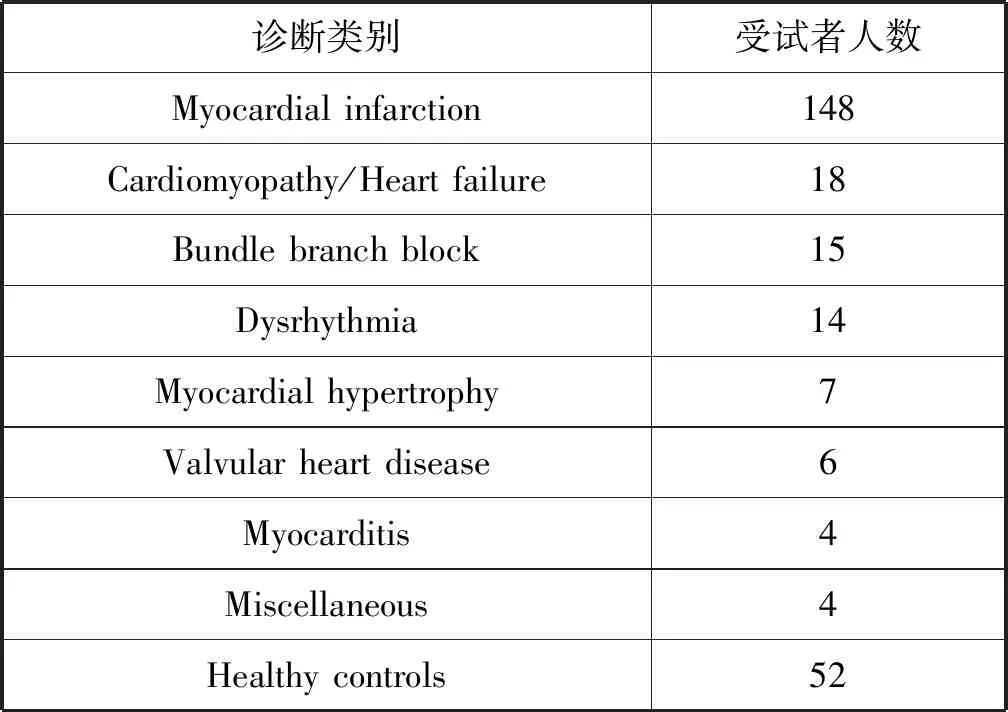
表1 PTB诊断类别及受试者人数统计表
3 数据处理
由于心电信号的不稳定性、非线性和微弱性,振幅仅为几毫伏,频率范围在0.05 Hz到100 Hz之间,在信号采集过程中非常容易受到人体活动和仪器等各种因素的干扰,甚至会影响到ECG信号的特征提取和进一步分析诊断。因此有必要对采集到的ECG信号进行去噪预处理,以便获得高质量的心电信号,这些噪声主要包括基线漂移、工频干扰和肌电干扰。
由人体呼吸或者电极移动引起的基线漂移频率较低,与缓慢变化的正弦曲线相似。本文采用中值滤波算法去除基线漂移。首先设置一定长度的滑动窗口,利用中值滤波器来提取基线漂移,然后用原始心电信号减去提取出的这个基线部分,就得到去除基线漂移后的心电信号。中值滤波算法简单,速度快,准确率高,失真较小,对ST段有一定的保护作用,ST段是诊断心肌缺血等疾病的重要依据。因市电产生电磁波辐射而产生的工频干扰会导致心电信号采集的异常,大大降低心电信号的信噪比。PTB心电数据取自德国的一所医学大学,工频干扰的频率主要集中在50 Hz及其谐波。本文采用的是陷波滤波器,即带阻滤波器,其效果较好,处理速度快。由肌肉震颤引起的肌电干扰近似于白噪声,属于高频干扰,去除不规则的肌电干扰通常采用低通滤波方法。本文采用切比雪夫数字低通滤波器,从原始心电信号中去除肌电干扰信号成分。
经过去噪预处理后就得到了高质量的心电信号,再进行心搏分割。采用基于小波变换的检测算法定位R波峰,由于QRS复合波是心电信号中能量最大的部分,包含了一个心搏的大部分信息,而DB6小波在形态上与QRS复合波近似度很高,所以本文使用DB6小波作为母小波。经过小波变换后,得到一系列能量峰值点,以每个能量峰值点所在时刻为中心,在前后一定范围内寻找极大值点,该点就是R波峰值点所在位置。据统计,成年人每分钟心跳次数大约是60到100,考虑到心跳较缓的老人和心跳较快的儿童,如果以R的峰值点为基准向前向后提取若干采样点的值,基本上可以覆盖一个心搏波形的主要特征。本文以R波峰值点为基准,向前向后分别选择250 ms和400 ms的原始采样数据,将这些值组合为一个心搏的特征向量。
本文对PTB数据库进行去噪预处理,经过心搏分割后,去除样本数量太少的类型,最后提取出54 753个心搏,这些心搏分属于6个类别:前壁心肌梗死(anterior,AMI)、前外壁心肌梗死(antero-lateral,ALMI)、前间隔心肌梗死(antero-septal,ASMI)、下壁心肌梗死(inferior,IMI)、下外壁心肌梗死(infero-lateral,ILMI)和健康对照(healthy control,HC),各类心搏的样本数量如表2所示。如果使用PTB数据库提供的所有15个导联的数据,学习的信息会更全面,能够获得总体上更好的结果,但这不符合临床实际情况,临床通常仅有12导联可用。另外由于六个肢体导联的数据是由两个测量电压(例如Ⅰ和Ⅲ)经过线性组合而成,因此本文仅使用两个肢体导联的数据,以去除肢体导联之间的数据相关性,去掉冗余特征,降低特征维度,提高机器学习效率。因此,本实验只考虑临床应用中常用的且非冗余的8个导联的心电数据。
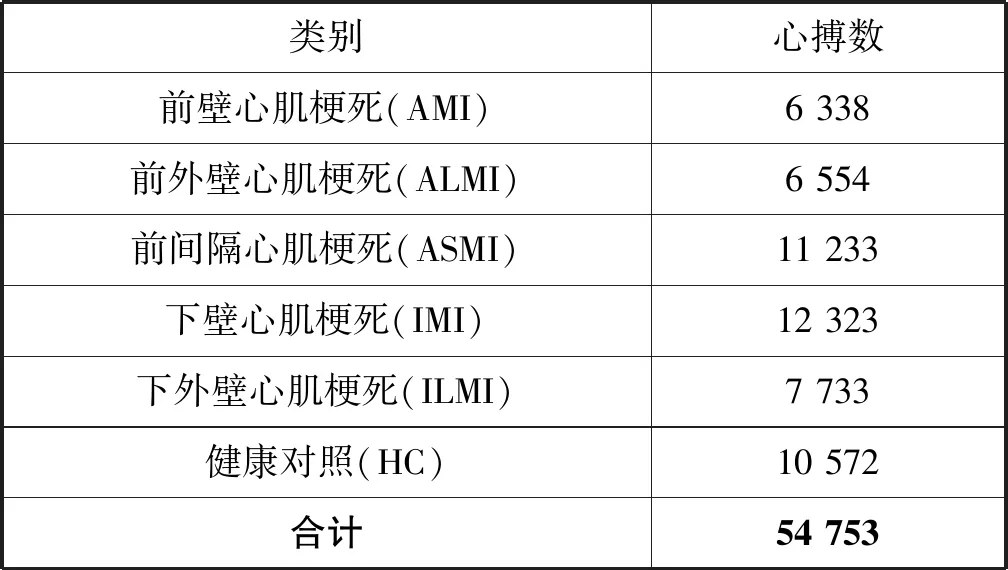
表2 各类别心肌梗死的心搏数
4 GA-ELM算法
神经网络有很强的非线性拟合能力,可映射任意复杂的非线性关系,而且学习规则简单,便于计算机实现。BP神经网络是目前应用最多的一种神经网络形式[16]。但BP神经网络也不是完美无缺的,其网络结构复杂,收敛速度慢,容易陷入局部极小化,可能出现过拟合现象。极限学习机(Extreme Learning Machine,ELM)[17]是一种单隐层前馈神经网络[15],与BP神经网络相比,ELM不需要设置大量的网络训练参数,所以训练速度非常快,对于异质的数据集其泛化能力很强,被广泛应用于分类、回归、聚类、特征学习等问题中[18]。
ELM随机选取网络输入权重以及隐层单元偏置,而且在训练过程中不需要调整。只需要设置好隐层节点数L,激活函数g(x)、输入权重wi和偏置bi,就能得到唯一的最优解。由于ELM具有速度快、参数设置容易、算法简单等优点,该方法在许多领域都得到了应用。
假设有N个任意不同的心搏样本(xi,ti),其中xi=[xi1,xi2,…,xin]T∈Rn是n维特征向量,ti=[ti1,ti2,…,tim]T∈Rm是one-hot编码的心肌梗死类别,只有一位为1。ELM算法对于一个有L个隐层节点的单隐层神经网络可以表示为:
(1)
式中:g(x)为激活函数,i指的是第i个隐层,wi=[wi1,wi2,…,win]T为输入权重,βi为输出权重,bi是偏置。wi·xj表示wi与xj的内积。
ELM模型对于输入权重和偏置是随机选取的,这就会导致网络隐层丧失调节能力,网络不稳定。另外,通过增加隐层神经元个数来提高训练精度,容易出现过拟合现象,从而降低模型的泛化能力。针对ELM的不足,本文首先采用遗传算法(Genetic Algorithm,GA)[19]对ELM中随机选取的参数寻找最优解,然后根据最优参数建立基于GA-ELM的心肌梗死定位模型。作为一种基于自然选择和遗传原理以自适应启发式方法搜索全局最优解。模拟生物种群内部染色体的随机信息交换机制,首先将需要优化的ELM参数采用二进制编码,设定进化代数Gen,定义适应度函数,初始化种群。然后计算适应度值并判断是否满足结束条件,若满足则结束,否则通过选择、交叉和变异运算更新种群中染色体的信息,迭代次数计数器加1,返回再次计算适应度值并判断是否结束。通过逐次迭代种群得到不断进化,最优解就是经过优化后的ELM参数。GA-ELM算法的流程如图1所示。

图1 GA-ELM算法流程图
种群中的每个个体都是一个二进制串,个体的维度即为需要优化的ELM参数的个数。
λ=[w11,w12,…,w1L,
w21,w22,…,w2L,
…,
wn1,wn2,…,wnL,
b1,b2,…,bL]
(2)
式中:λ表示种群中的一个个体;wij和bj分别表示输入权重和偏置。将二进制编码串解码得到输入权重和偏置,并送给ELM训练网络,对种群中每一个个体分别使用测试样本进行测试,适应度值fit定义为预测值与实际值的均方误差。
(3)
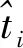
ELM学习的目标是使得输出误差最小,可以表示为:
(4)
式(1)中的N个方程可以用矩阵表示为Hβ=T。其中,H是隐层节点的输出,β为输出权重,T为期望输出。
H(w1,w2,…,wL,b1,b2,…,bL,x1,x2,…xN)=
(5)
(6)
通过GA算法已经得到最优的输入权重wi和隐层偏置bi,隐层的输出矩阵H也就可以被唯一确定。网络训练可以转化为求解一个线性系统Hβ=T,并且输出权重可以被确定为:
(7)
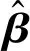
5 实验结果与分析
实验首先对ECG信号进行去噪预处理,然后确定R波的位置,将每条大约两分钟的心电信号分割为心搏序列。对每一个心搏,以R波峰为基准前后分别取250 ms和400 ms的采样数据,构成单导联心电向量,对8个导联分别采用相同的方式进行处理,将8个心电向量合成为一个多导联心电向量。将心电向量序列送入GA-ELM,首先利用GA确定ELM模型输入权值和偏置的最优解,然后用得到的最优参数训练ELM网络,最后使用训练好的网络来定位心肌梗死。在优化参数的过程中,预测准确率随进化代数变化的曲线如图2所示。
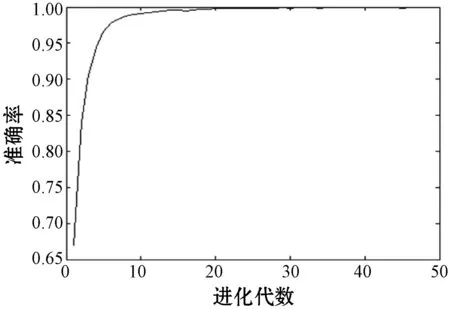
图2 预测准确率随进化代数变化曲线
为了评价本文提出的心肌梗死定位算法的性能,我们使用了4个指标:分类灵敏度(Sen)、特异性(Spe)、精度(Ppr)和准确率(Acc)。分类准确率评估所提出的方法在所有心搏上的整体性能。由于正异常心搏的数量不同,Sen、Spe和Ppr在评估分类器性能方面会出现较小的偏差。评价指标计算公式如下:
(8)
(9)
(10)
(11)
式中:TP是正确检测为MI的MI心搏的数量;TN是正确识别为HC的HC心搏的数量;FN是错误检测为HC的MI心搏的数量;FP是错误诊断为MI的HC心搏数量。
在搜寻最优参数的过程中,进化迭代次数设置为50。混淆矩阵如表3所示,该算法在心肌梗死定位上的总体准确率为98.42%,归一化后的混淆矩阵如图3所示。文献[9-10]使用卷积神经网络仅仅实现了有无心肌梗死的检测,得到的准确率分别为95.22%和95.30%。文献[15]仅使用T波积分和完整心搏积分这两个值作为特征,在心肌梗死的定位上得到76.67%的准确率。文献[13]使用简单的自适应阈值方法实现心肌梗死定位,准确率达到93.61%。文献[14]使用SVM方法实现心肌梗死的定位,得到的准确率为98.15%。表4是本文与其他文献算法在性能上的对比结果,在心肌梗死检测和定位准确率方面,本文比其他文献方法获得更好的性能。
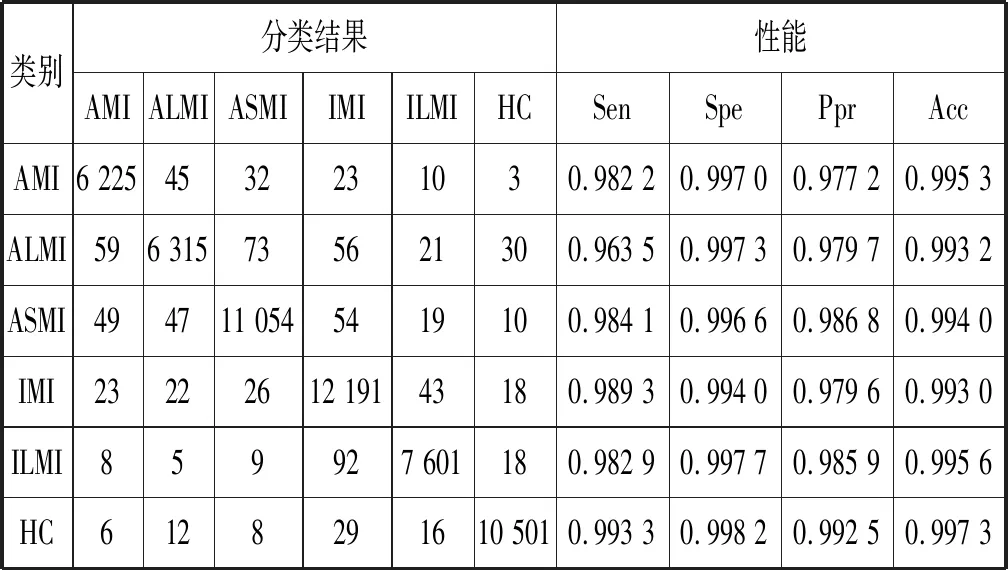
表3 混淆矩阵及分类性能
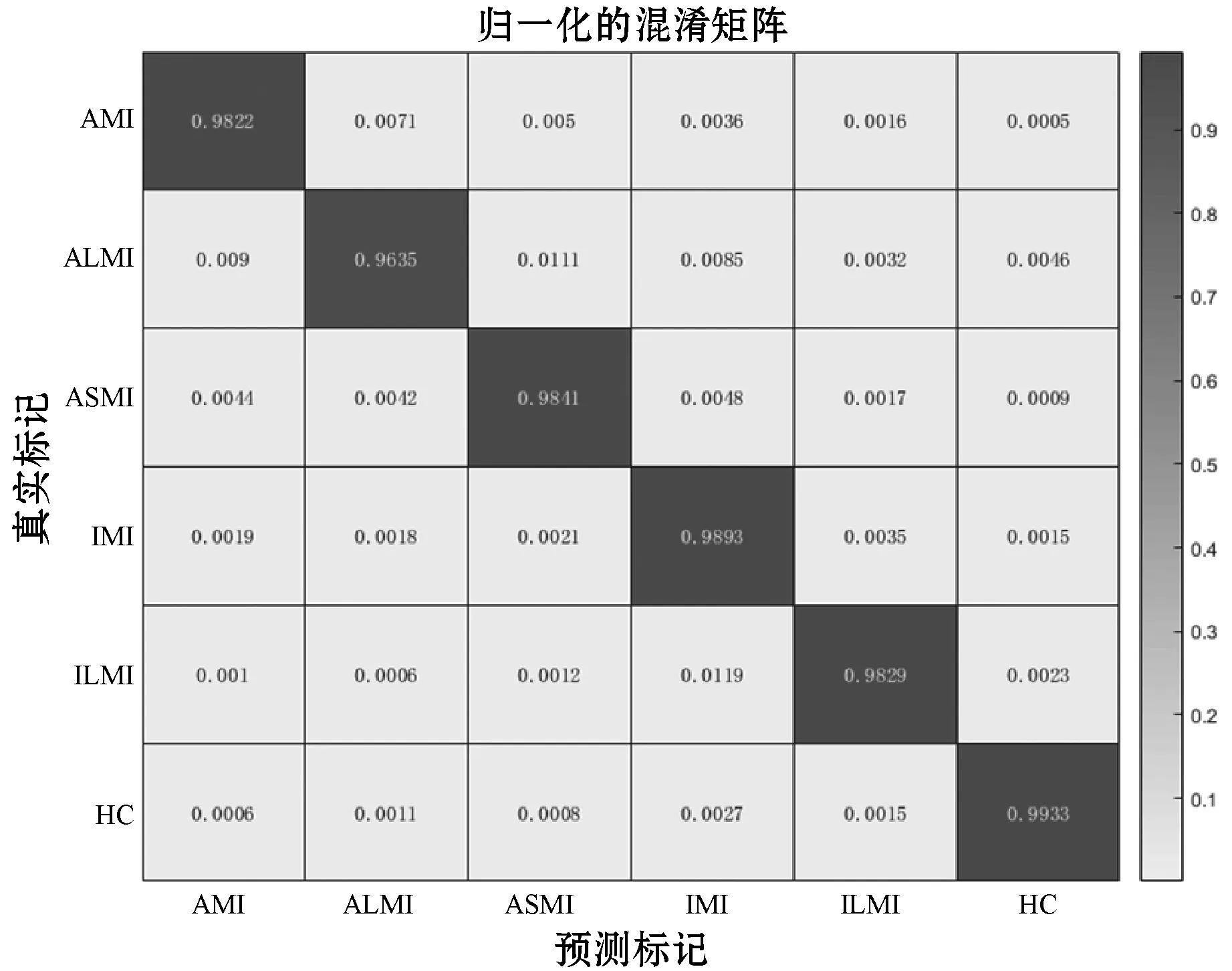
图3 定位结果归一化后的混淆矩阵

表4 与其他文献算法性能对比结果
本文提出的GA-ELM混合模型分析了多导联的心梗数据,信息更加全面。该方法不局限于医学专家所设计的手工特征,通过自动提取特征,能够充分挖掘出隐藏在数据内的有效信息,在心肌梗死疾病的定位上得到了优异的结果。
6 结 语
本文提出了一种基于GA-ELM混合模型的多导联心肌梗死定位算法。首先采用滤波器组对心电信号进行去噪预处理,然后采用DB6小波变换方法定位R波峰,接下来把每条心电记录分割成心搏序列,最终构建GA-ELM混合模型进行定位识别。该模型相比卷积神经网络(CNN)算法不需要设置大量的网络训练参数,结构更简单,训练速度更快。实验结果表明,本文构建的混合模型能够充分挖掘出多导联的ECG心梗信号中潜在的有用特征,得到了优异的结果,有较高的临床应用价值。
