一种IGS站高程时间序列分析方法
2020-01-09张恒璟陆帝文汉江程鹏飞崔东东
张恒璟,陆帝,文汉江,程鹏飞,崔东东
(1.辽宁工程技术大学 测绘与地理科学学院,辽宁 阜新 123000;2.中国测绘科学研究院,北京 100036)
0 引言
对IGS站坐标时间序列的分析表明,在水平方向上时间序列主要表现出线性运动的特征,在高程方向则存在着复杂的周期性运动和非线性运动,这种运动特征在不同的IGS站上有着不同的表现[1-2]。对于IGS站高程时间序列的非平稳非线性信号,在使用周期拟合模型去除序列的非平稳性时,难免会使序列的分析结果出现错误。
在处理与分析非线性非平稳的信号时,希尔伯特-黄变换[3]通过使用自适应的方法避免了以往方法的缺点。经验模态分解方法(empirical mode decomposition,EMD)分解,会因为部分信号中断而导致混叠模态分量问题[4-5];整体经验模态分解方法(ensemble empirical mode decomposition,EEMD)通过引入大量的白噪声来协助分析时间序列,利用整体平均的思想很好地解决了混叠模态的问题[6-7]。然而,引入大量白噪声协助分析,使得求整体均值的过程繁琐,导致了计算困难和费时的问题;同时,引入大量噪声对原始序列存在一定的破坏,且引入的噪声经处理后会有残留。本文引入互补集合经验模态分解方法(complementary ensemble empirical mode decomposition,CEEMD),该方法通过引入独立分布的N对正、负辅助白噪声[8],减少EEMD方法在信号重构时导致的噪声残留量,提高信号重构的效果。
1 EEMD和CEEMD分解
1.1 EEMD分解
EEMD算法解决了EMD方法中的因信号中断导致的混叠模态分量问题。EEMD分解算法是通过将高斯白噪声均匀地添加到时间序列信号中去,在有限次添加白噪声之后进行EMD分解。参考文献[6-7]的分解过程如下;
(1)
②假设高斯白噪声的添加次数为M,对经过M次噪声添加并经EMD分解过后的IMF分量进行求整体均值,作为EEMD分解的IMF分量
(2)
③整体均值计算后得到各阶IMF分量及剩余量,原信号即可写为:
(3)
EEMD在进行整体平均时,默认每次经噪声添加再分解所得到的都是等幅度的IMF分量,但由于实际信号中存在着一定的间歇性高频分量,导致混叠高频分量信号,这样得到的EEMD分解结果中存在着未消除的之前添加的白噪声信号,噪声在分解结果中残留量较大,会降低序列信号的重构效果[9]。
1.2 CEEMD分解
CEEMD的分解过程与EEMD相比,改进之处在于在序列信号进行EMD分解前,向待处理的序列信号中加入正负相对的白噪声序列信号[10]。过程如下:
①在原始序列信号xt中添加n组幅值相同、相位角相差180°的白噪声,得到新的2组信号,即
(4)
式中:xt为原始信号;xn为白噪声;X1,X2为得到的新的信号。由此可得信号集合中的数量为2n组。
元代声律学家周德清在《中原音韵》中,对宫调的声情特色作出归纳,其中有“仙吕调清新绵邈,黄钟宫富贵缠绵”,与姜夔“清空峭拔”词风相偕,本词的宫调应合仙吕调。不论是否入乐,“燕”作去声时似乎更能将音韵延长,以达“绵邈”,且“燕子”轻灵之感亦增清新面貌。姜夔颇晓音律,对平仄音节应较为敏感。“燕”作平声时,与“雁”字连读,则似有不顺,略为拗口。尽管“燕地”渺远,有似开拓意境之嫌,但既思之意境,何不用“幽雁”“北雁”呢?
②对新得到的信号X1和X2分别使用EMD方法进行分解,将分解后得到的每组信号记为IMF1和IMF2。
③将CEEMD分解的最终结果记为Xi,Xi的值为每组IMF1和IMF2分量的均值,即:
(5)
CEEMD分解充分保留了EEMD的优点,解决了混叠模态的现象,相对于EEMD算法,CEEMD方法节省了信号处理时间,并且随着白噪声添加的数量增加,最后重构出的信号数据中噪声的残留量减小,最终的噪声残留量可以忽略不计,提高了信号重构的效果。
2 信号分析结果评价标准
IGS站高程时间序列信号分析效果可从以下两方面进行考虑:
一是重构后信号的信噪比(signal-to-noise ratio,SNR),这里采用的信噪比计算方法为:
(6)

二是重构信号的均方根误差(root mean square error,RMSE)。利用降噪后的时间序列Xi和原始时间序列xt定义RMSE为:
(7)
RMSE表现出了重构信号和原始信号的区别,RMSE值越小,则表明重构后的信号质量越好,精度越高。反之,RMSE值越大,重构效果越不理想。
3 实验分析
本文实验数据采用BJFS站2000—2018年和SHAO站2000—2013年的高程时间序列作为原始信号,数据来源于SOPAC网站,利用3倍中误差剔除数据中的粗差,同时剔除序列均值、同震与非地震跳变的影响。时间序列如图1、图2所示。

图1 BJFS站高程时间序列

图2 SHAO站高程时间序列
3.1 分界点n的判定
对得到的BJFS站和SHAO站的数据进行CEEMD分解,得到时间序列的IMF分量图,如图3、图4所示。
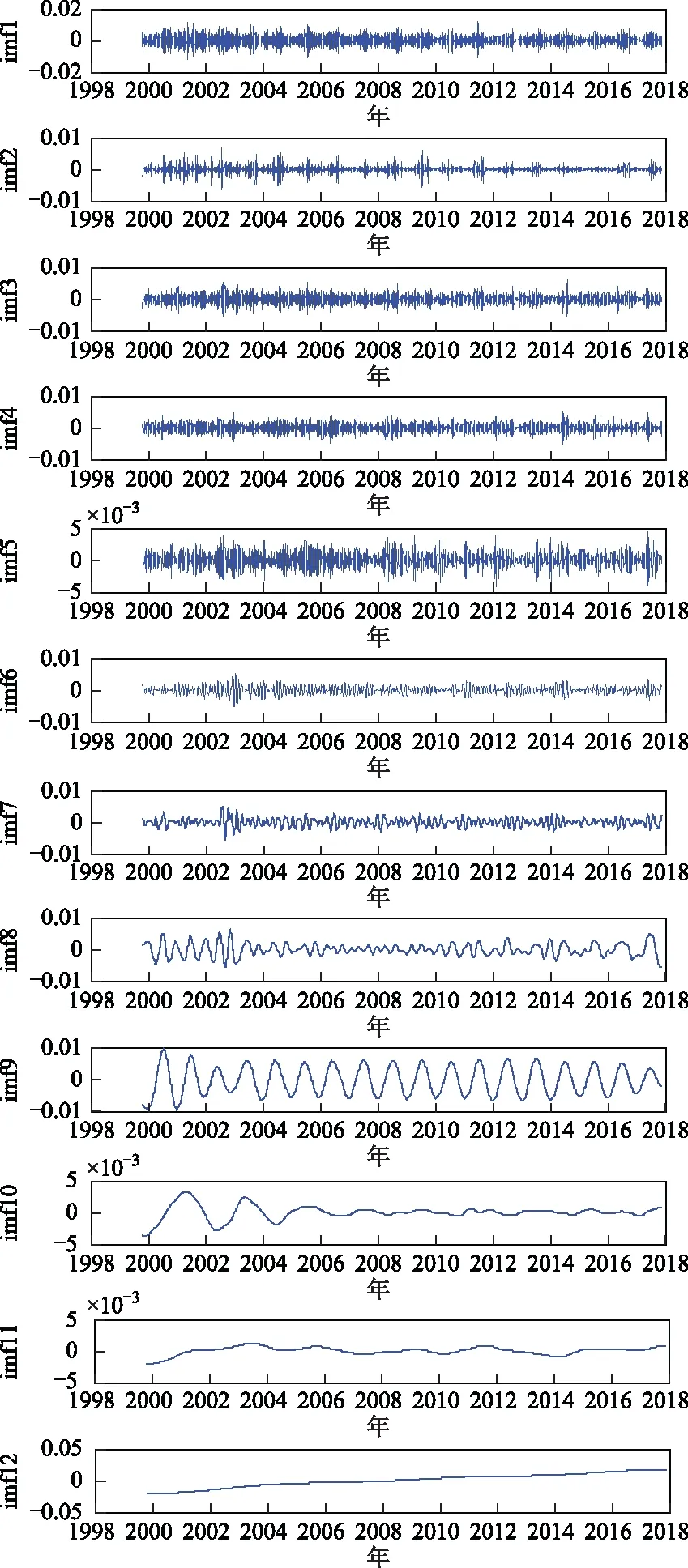
图3 BJFS站分解的IMF分量
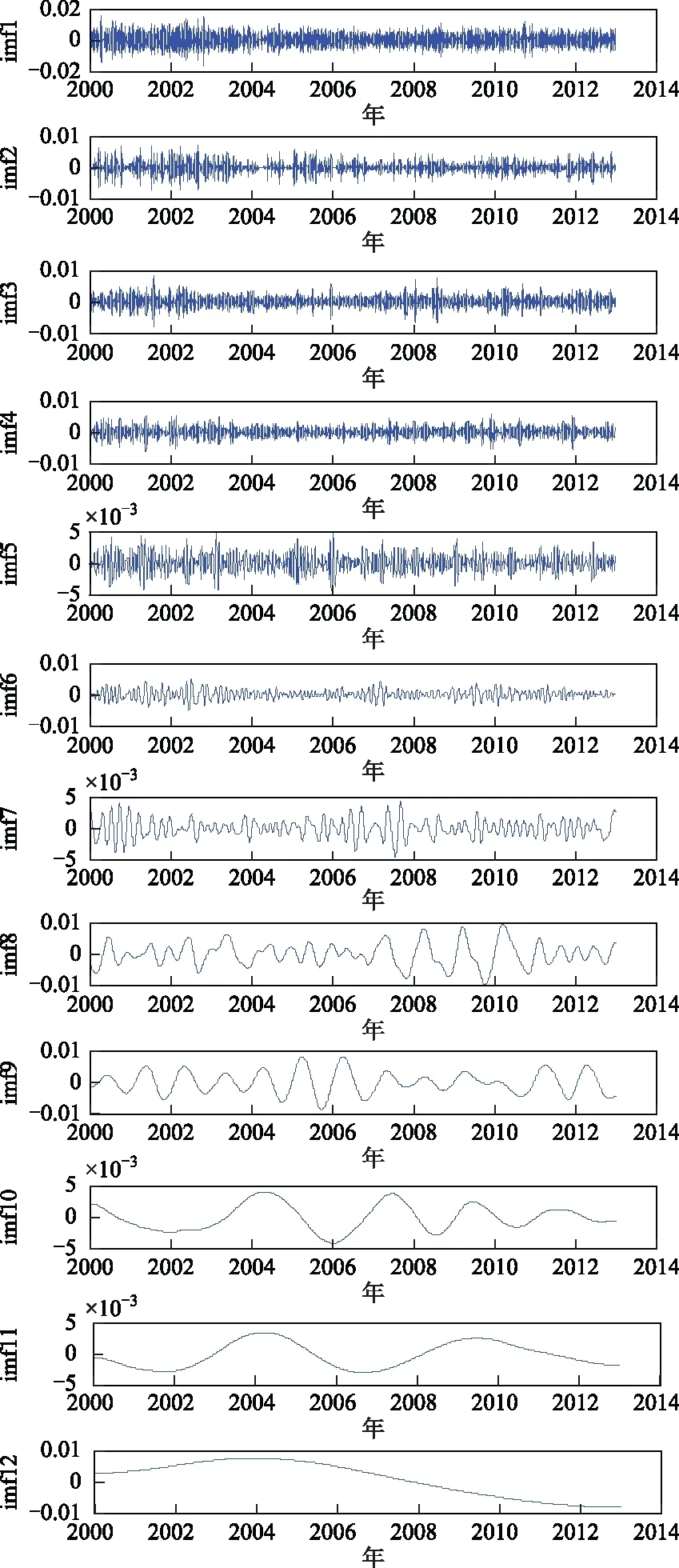
图4 SHAO站分解的IMF分量
IGS站高程时间序列信号经分解后为一系列从高频到低频排列的IMF分量[11],为使重构后的信号达到更好的效果,如何正确识别噪声与信号的分界点是关键[12]。Wu和Huang等提出了一种使用平均周期与能量密度乘积来判定噪声与信号分界点的方法,当某一IM-F分量的平均周期与能量密度的乘积发生显著变化时即为噪声与信号的分界点n[13-15],然后从该分界点的下一IMF分量进行信号重构[16]。
定义IMF分量平均周期与能量密度乘积为:
(8)


表1 BJFS站部分IMF分量平均周期与能量密度乘积

表2 SHAO站IMF分量平均周期与能量密度乘积
BJFS站:IMF1~IMF4的CONST均值为0.046 9,IMF1~IMF4与其均值偏差不超过84%,而IMF5的CONST值为0.128 5,大约是IMF1~IMF5均值的2倍,故可认为IMF1~IMF4为噪声模态分量,分界点为5。可认为IMF1~IMF4均为噪声分量,其余为信号分量。
SHAO站:IMF1~IMF3的CONST均值为0.070 3,IMF1~IMF3与其均值偏差不超过44%,而IMF4的CONST值为0.227 2,其与IMF1~IMF4的均值0.109 5偏差2倍以上,故可认为IMF1~IMF3为噪声模态分量,分界点为4。舍弃噪声分量IMF1~IMF3,对剩余的信号分量进行重构。
3.2 信号重构分析
对经过分界点n识别并去除噪声分量的余下信号分量进行重构,重构效果如图5和图6所示。
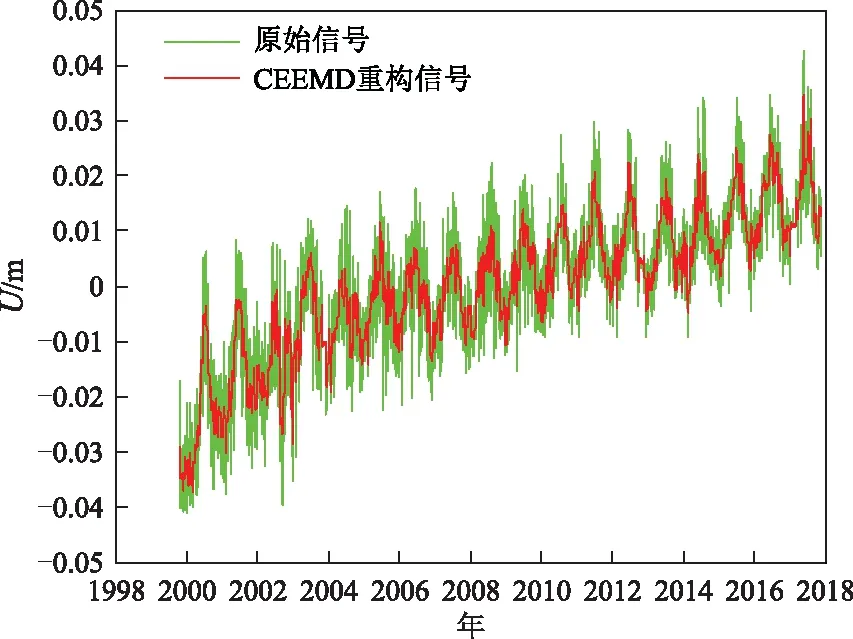
图5 BJFS站信号重构图
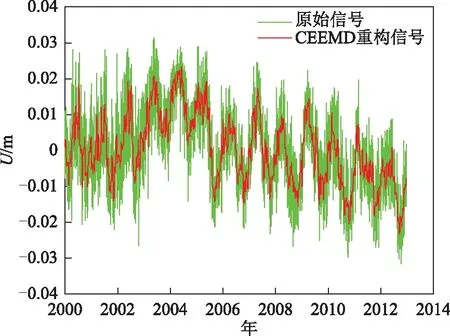
图6 SHAO站信号重构图
根据信噪比和均方根误差的重构评价指标如表3、表4所示。

表3 BJFS站信号重构评价指标

表4 SHAO站信号重构评价指标
分析表3、表4可见:
BJFS站:对使用CEEMD方法分解后的信号进行重构,其信噪比相比较于EEMD分解和EMD分解分别提高了17%和27%,均方根误差指标分别降低了41%、55%。
SHAO站:对使用CEEMD方法处理后的信号进行信号重构的信噪比比EEMD、EMD分别提高了19%、32%,均方根误差相比于EEMD、EMD分别降低了20%、37%。
4 结束语
采用CEEMD方法分解高程时间序列信号避免了EMD分解的混叠模态分量问题。相较于EEMD分解,CEEMD通过添加独立同分布的、正负相对的互补白噪声序列,提高了计算效率,减弱了EEMD由于添加大量白噪声对原始序列的破坏并减少了噪声的残留量。
使用CEEMD方法对时间序列进行处理,并进行噪声的识别和舍去,对剩余的信号分量进行重构,其重构效果相比较于EEMD、EMD方法在信噪比上有明显的提高,在均方根误差上有明显的降低。可以看出,CEEMD分解和重构效果优于EEMD和EMD,为后续对CORS站高程时间序列的研究提供了思路。但对于序列含有色噪声影响的问题还需作进一步的研究。
