一种混合粒子群优化遗传算法的高分影像特征优化方法
2020-01-09唐晓娜张和生
唐晓娜,张和生
(太原理工大学,太原 030024)
0 引言
随着高分遥感卫星的相继问世,高分辨率遥感影像因其所具有的高度细节化的地表覆盖信息特征为地物目标分类提供了充分的依据[1]。传统基于中低分辨率遥感数据的方法已经不适用于处理高分遥感影像。近年来研究人员多采用面向对象方法来处理高分辨率遥感数据。面向对象分类突破了传统方法以像元为对象的局限性,实现了多细节、多信息的目标对象提取[2]。但面向对象方法增加了对象特征维度,故在分类前需进行特征优化。随机森林对于多维特征的数据集分类有很高的效率,应用于土地利用分类也取得了较高精度的结果。当特征维数过高时,过多的特征会使得运算变得复杂,处理效率降低,甚至会导致分类精度的降低,因此在分类前需要对特征空间进行优化降维,选取对分类作用最大的特征[3]。
在现有研究中,与RF算法结合的特征选择方法概括为过滤式(Filter)和封装式(Wrapper)2种。Zhang等[4]将2类算法结合进行特征选择并取得较好效果。Seyyedi[5]借鉴过滤和封装相结合的思想提出了一种FSLA方法用于高维空间特征选择,可以选出较原始数据集维度更低且分类性能较好的特征子集;肖艳针[6]对面向对象分类中存在的特征维数过高的问题,提出了一种结合Relief F算法和遗传算法的混合特征选择方法,并利用多分类器组合方法对PolSAR影像分类,取得较好效果。
Filter特征选择方法中,Relief F是处理多类别问题较成功的算法之一,通过计算特征权重来提取重要特征。Wrapper特征选择方法选取基于随机森林的新二进制粒子群优化遗传封装算法(GANBPSO)。综上,本文基于高分二号数据,将Relief F算法和基于随机森林的新二进制粒子群优化遗传封装算法结合,提出了混合粒子群优化遗传算法随机森林Filter-Wrapper组合式特征选择方案来筛选重要特征变量构建优化数据集,并将其应用于面向对象城市用地分类中,通过与其他特征选择方法结果对比,验证此方案的有效性。
1 特征选择算法的原理
1.1 Relief F算法原理
Relief F算法是一种过滤式(filter)多类别特征选择算法,通过计算权重表征特征重要程度[7]。Relief F算法在处理多类问题时,每次从训练样本集中随机取出一个样本R,然后从和R同类的样本集中找出R的k个近邻样本(near hits),从每个R的不同类的样本集中均找出k个近邻样本(near misses),然后更新每个特征的权重,如下式所示:
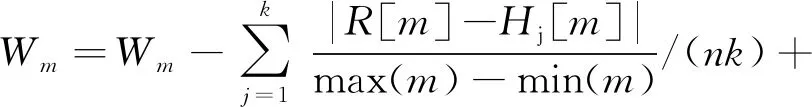
(1)
式中:c为异类样本的类别;R[m]为个体R特征m的值;Hj[m]为第j个最邻近同类样本Hj[m]特征m的值;P[c]为异类样本类别为c的概率;class(R)为个体R的类别;P(class(R))为样本类别与R相同的概率;T(c)t[m]是第j个最邻近c类样本特征m的值。
特征变量权重越大,表明此特征使得样本类间差距越大,识别不同类效果越明显。
1.2 遗传算法原理
遗传算法(genetic algorithms,GA)利用生物启发算子,随机产生一定数量的初始个体构成原始种群,通过选择、交叉、变异形成新种群,利用适应度函数对个体评估,并逐步淘汰适应度函数值低的解,增加适应度函数高的解,将适应度高的个体遗传到下一代,直到满足终止条件,输出最优解[8]。
1.3 新的二进制粒子群算法原理
新的离散二进制粒子群算法(novel binary particle swarm optimization algorithm,NBPSO)在d维搜索空间初始化由二进制编码组成的粒子群,用位置、速度和适应度函数得到的适应度值表示该粒子特征,通过上一时刻粒子的运动方向和状态更新粒子位置和速度[9]。位置和速度更新公式如下:
(2)
(3)
(4)
(5)
1.4 随机森林算法原理
随机森林是以多个分类回归树(classification and regression trees,CART)为基础分类器的集成分类器[10],主要分为样本训练与分类两部分。训练过程首先采用自助(bootstrap)重采样技术从总体数据集N中有放回地重复选取n个样本生成新的训练样本,每个样本集的大小一致;然后根据自助样本集生成n个CART分类决策树组成随机森林,在生成决策树的过程中,从每个决策树的每个节点中随机选取m个特征(m小于总特征数M),基于基尼系数最小原则计算节点最佳分裂方式;最后新样本的分类结果按分类树投票多少形成的分数决定。并用未抽到的用例(样本)作预测,评估其误差。在袋装算法(bootstrap aggregating,Bagging)的每轮随机采样中,约有36.8%的数据未被选中来参加训练集模型的拟合,称为袋外误差(out of bag error,OOB)。OOB误差可以检验模型的泛化能力,OOB误差越小,代表分类精度越高。
特征优选过程中,RF算法除了要评估各特征组合的分类精度和各特征的重要性,还用于后续的城市用地信息提取。RF模型在R语言平台上构建,在每次分类前,对模型中的2个参数赋值:总决策树数目n和节点分类时选取的特征变量个数m,获得使OOB误差最小的参数组合进行后续分类。
2 混合粒子群优化遗传算法的特征选择方案构建
随着对地观测空间分辨率的提高,地物的细节得到极大的丰富,同类地物表现出更为复杂的光谱特征,纹理信息和形状信息的加入对于区分复杂的地类变得必要,总共选取光谱特征、纹理特征、形状特征、指数特征等共76 个特征参数。
首先利用Relief F算法对提取的76个特征进行初选,剔除类间距距离小于类内距离的特征,筛选出与目标类相关性较大的35个特征,对特征进行排序,利用RF算法计算交叉验证精度接近稳定时的变量组合作为初始化特征集。在NBPSO算法中加入GA算法的选择、交叉和变异算子步骤,利用离散二进制粒子群算法来重建变异算子,使得模型加快搜索速度,提高全局寻优能力[11]。优化的混合算法流程如下:
①随机产生由确定长度的二进制串组成的粒子种群并进行编码,初始化参数和粒子位置、速度。
②计算粒子的适应度值,采用权重的方法作为封装算法的适应度函数,公式如下:
G=q·OA+p·(1-N0/N)
(6)
式中:OA 表示当前特征子集的总分类精度;q+p=1,且q,p>0;N0表示当前特征子集的数量;N表示特征总数。
③粒子更新,执行改进的NBPSO算法,在NBPSO算法中加入GA算法的选择、交叉和变异算子步骤。对粒子的位置和速度进行更新,计算每个粒子的适应度值,较高值的前半部分粒子进入下一代的个体;后半部分进行交叉、变异操作。
④收敛判断,判断是否收敛,若不收敛,重新执行③;反之若收敛,更新粒子个体极值和全局极值位置,更新粒子位置和速度,达到最大迭代数,选取适应度最高的粒子作为最优特征集。
特征优选流程如图1所示,其中有2个参数直接影响算法搜索的性能,分别为最大迭代数(MaxIteration)和种群规模(PopSize)。综合多次实验,MaxIteration取值200,PopSize取值50。
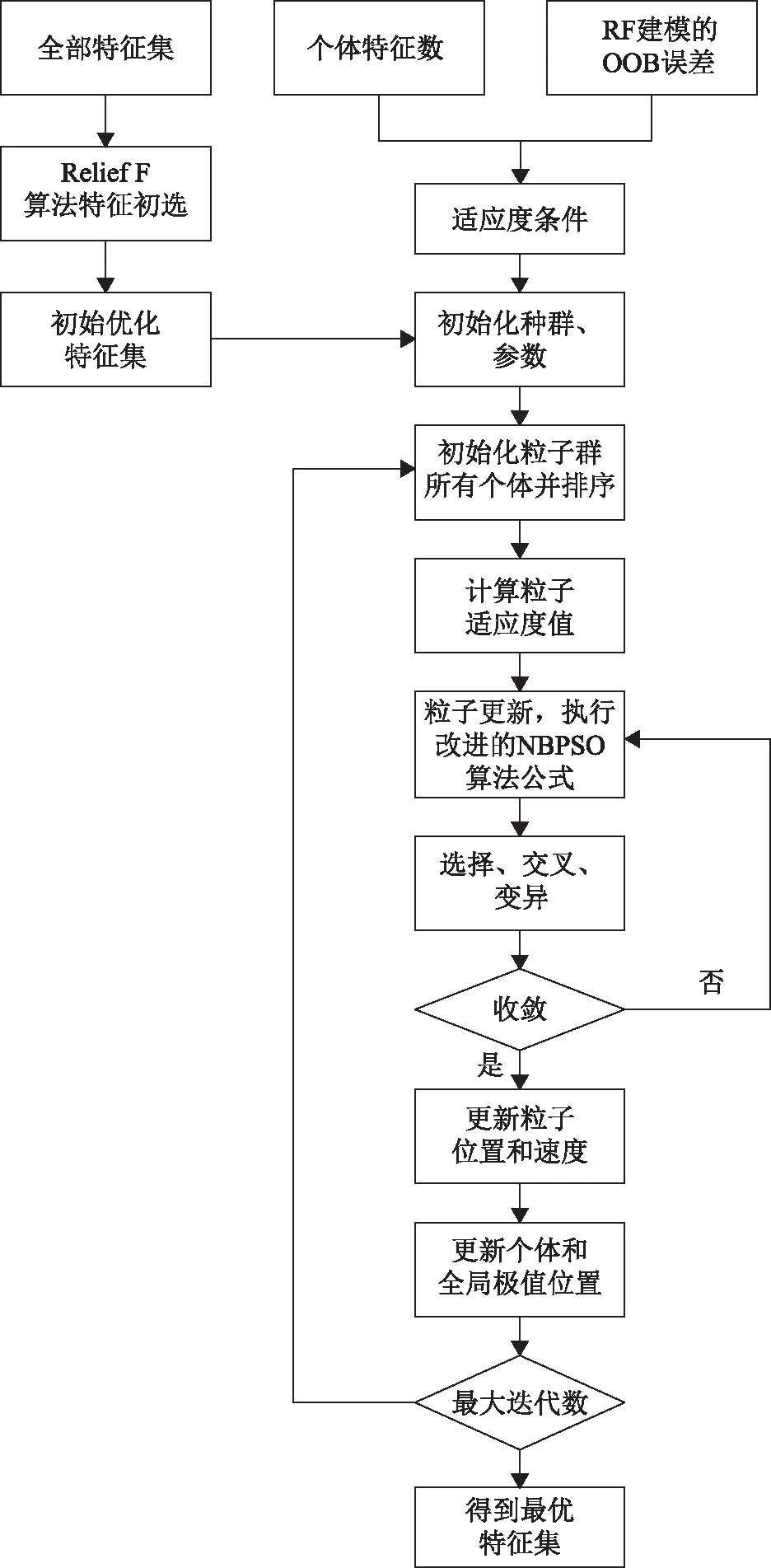
图1 特征选择流程图
3 实验与结果分析
本文采用高分二号(GF-2)卫星于2017年5月6号获取的山西省太原市万柏林区的部分区域的遥感影像进行实验,该影像全色影像分辨率为1 m,多光谱影像分辨率为4 m。其他数据为同年土地利用数据。参考文献中对城市生态用地的分类经验[12-13],将实验区域城市用地类型分为5类,分别为:植被、房屋建筑区、道路、水体和裸露地表。
利用ENVI5.3对GF-2数据进行预处理,结合RPC信息和DEM数据分别对多光谱和全色影像进行正射校正及几何配准,使用NNDiffuse Pan Sharpening方法进行图像融合,融合后的分辨率为1 m;利用FLAASH大气校正模型进行大气校正,最后根据需求在影像中裁剪出合适的研究区域。研究区示意图如图2所示。

图2 研究区示意图
结合2017年太原市土地利用数据与实际调查数据,总共选取750个样本点。将样本随机分为2组,其中2/3作为训练组,用于特征选择和RF分类建模,1/3作为测试组,利用模型将其分类,并于实际类别对比,评估RF分类准确率。经过多次对比实验,本研究中多尺度分割的分割尺度为30,光谱因子0.9,紧致度因子0.3;光谱差异分割的最大光谱差异尺度为50时,能取得较好的分割效果。
3.1 模型选取特征集
经过多次实验发现,对于全特征集合All_FS,当m为20时OOB误差接近最小值15.26%,n≥500时,分类总体OOB误差趋于稳定。故选取m=20,n=500作为RF建模的初始参数。在Matlab和R语言平台上对全特征集进行筛选,最终得到包含15个特征的最优特征集。在最优特征集中包括6个光谱特征、6个纹理特征和3个指数特征,形状特征由于影像分割后地块破碎使得各地类间形状差异较小未选入最优特征集合中。

表1 最优特征集
3.2 随机森林分类结果与精度
利用优选后的15 个特征,选取令OOB误差最小的参数组合m=4,n=500,建立RF模型对试验区进行土地利用分类,分类结果如图3所示。计算混淆矩阵,进行精度分析。由表2可知,PF_FS分类方案的总体精度为91.17%,Kappa系数为0.874,除道路外,其他4类的生产者精度都在90%之上。水体、裸露地表、植被的生产者精度较高,仅道路与房屋建筑区因光谱信息相似且交叉分布现象分类精度低于其他地类,但总体分类结果与实际地物信息相符。

图3 不同特征选择方案的高分遥感影像用地信息分类
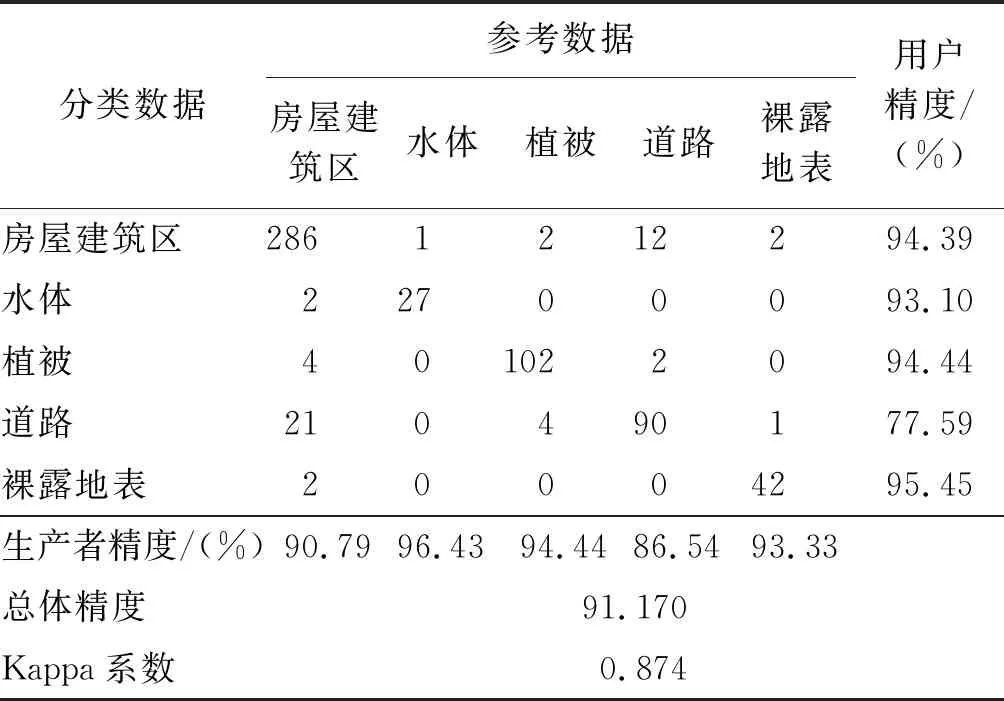
表2 Relief F-GANBPSO_RF分类方案混淆矩阵
图4为选取较有代表性的11个太原市实验区域土地利用现状样例点,并在表3中对样例点的土地利用现状与本文分类结果情况进行对比。
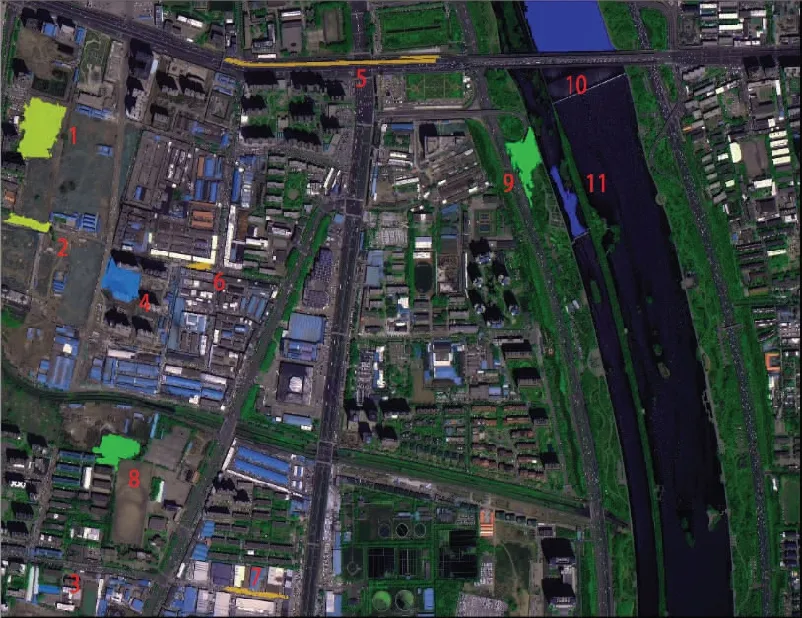
图4 样例点示意图

表3 土地利用现状与分类结果样例点对比
3.3 不同特征选择方案对比
为验证Relief F-GANBPSO_RF特征选择方案的有效性,将其与常用的GABPSO算法优化特征集、Relief F算法优化特征集、全部特征集的RF分类结果做对比,在4种特征选择分类方案中,各自选取使分类精度最高的参数和特征数量,分类结果如图3所示。这4种特征选择方案分类的精度和Kappa系数如表4所示,其中以本文方法为首的4种特征选择方法分别表示为Relief F-GANBPSO_RF、GABPSO_RF、Relief F_RF和ALL_RF。

表4 不同模型分类方法精度比较
由表4可知,在4种分类结果中,基于Relief F-GANBPSO_RF分类的总体精度和Kappa系数最高,分别为91.17%和0.874,利用GABPSO算法筛选的特征集获得的分类精度与本文方法差距最小,精度和Kappa系数只低于1.86%和0.036 8;而Relief F_RF分类精度和Kappa系数略低于GABPSO_RF分类效果,分别为87.72%和0.825 4。说明先利用Relief F算法对特征进行预筛选,再利用GABPSO封装算法对特征进一步优选能够在一定程度上提高分类精度,并且能获取更少的特征变量来提高运行时间和效率。本次实验中,全特征集参与分类得到的精度比其他3种方案降低了6.47%~9.92%,表明过多的特征变量有可能会导致分类精度的降低。因此综合上述结果及分析,Relief F-GANBPSO_RF特征选择方案能够一定程度提高高分辨率遥感影像的分类精度。
4 结束语
针对高分影像数据特征维数高、数据冗余等问题,本文以GF-2影像为数据源,提出了一种结合Relief F和GANBPSO封装算法的混合特征优选方法,随后采用随机森林算法对研究区城市用地进行分类,并结合实际调查数据及土地利用数据对分类结果进行分析。结果表明,本文特征提取方案的分类结果优于对比结果,验证了结合Relief F和GANBPSO封装算法的混合特征优选方法能够更有效地提取优化特征,在对高分辨率遥感数据多特征优化方面具有一定的可行性。
