基于webmagic 爬取技术的西藏主流媒体热点新闻的获取
2020-01-08王国庆高红梅黄法锦白玛旺久西藏大学信息科学技术学院西藏拉萨850000
王国庆 高红梅 黄法锦 白玛旺久 西藏大学信息科学技术学院 (西藏 拉萨850000)
1 研究背景
通过调查研究发现,在西藏自治区外,大部分人对西藏的物质文化和人民生活一知半解。造成此种现象的原因在于获取西藏信息的渠道太少,人们对西藏的看法与实际情况存在偏差。但随着互联网的迅猛发展,爬虫技术的日益成熟,通过对西藏主流媒体的爬取来获取所需要的新闻,不仅能改变外界对于西藏的认知和看法,而且有助于向区外展示和发扬西藏文化,能够让人们更加清楚的了解和认识到西藏人民多姿多彩的物质文化生活。
2 相关技术
2.1 Maven 工具
Maven 是一个针对Java 开发项目的管理工具,能够管理项目所依赖的jar 包。它以Jelly 作为自己的脚本语言。包含了一个项目对象模型(POM),一组标准集合,一个项目生命周期,一个依赖管理系统和用来定义在生命周期阶段中插件目标的逻辑。
2.2 WebMagic 总体框架
WebMagic 是一个简单灵活的Java 爬虫框架, WebMagic 主要包括两个包,分别是核心包和扩展包。其中核心包(webmagic-core)包含爬虫基本模块和基本抽取器,而扩展包(webmagic-extension)则提供一些方便编写爬虫的工具。同时内置了一些常用组件,便于爬虫开发。
WebMagic 是 由Downloader、PageProcessor、Scheduler、Pipeline 四个组件构成的。而Spider 则将四大组件组织起来。
用 于 数 据 流 转 的 对 象:(1)Request: Request 是URL 地址 的 封 装 层,实 现 了pageprocessor 和Downloader 交 互,是pageprocessor 控制Downloader 的唯一途径。(2)Page:Page 代表Downloader下载的界面,可以是HTML、JSON或其他文本格式等。(3)Resultitems:Resultitems 负责存储由pageprocessor 处理的结果以供Pipeline 使用。
WebMagic 总体架构如图1 所示。
4 案例实现
4.1 具体操作流程
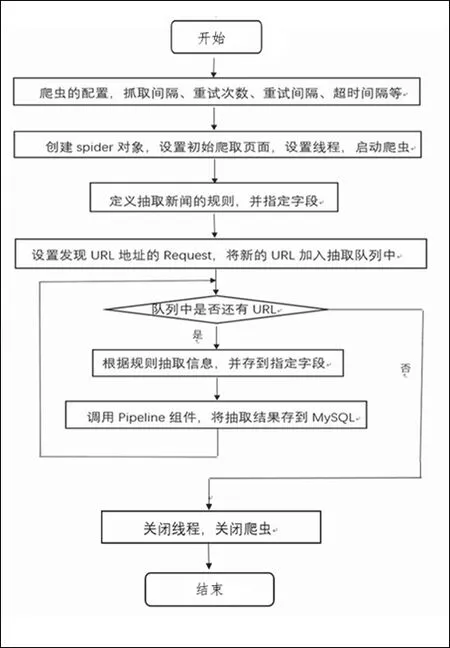
图2 信息爬取操作流程
4.2 爬虫准备工作
如果使用WebMagic 框架来进行爬虫的构建,首先需要借助Maven 来创建WebMagic 项目,其次则是在项目的pom.xml 配置文件中添加对象的依赖。
4.3 网页的下载
对于通用的网页,Downloader 组件可通过URL 地址直接获取网页信息,具体则是通过超链接得到对应的网页,然后按照所需要的数据字段进行抽取,将获得的字段为空的数据舍弃,将所获得的完整的数据存储到MySQL 数据库中。循环重试机制会把下载失败的URL 再次放在队尾进行重试,直到超过所设置的重试次数为止,循环重试机制和设置重试次数可以有效解决因为某些网络原因而漏抓页面的问题。
4.4 信息的抽取
PageProcessor 组件负责解析页面,抽取有用的信息,以及发现新的链接。它可以根据用户的需求来定制所需要的PageProcessor。其定制的功能主要分为三大部分:
(1)对爬虫的配置,包括:配置带爬取网站的编码、Http 头、超时时间、重试策略、代理等信息。
(2)爬虫最为重要的部分则是页面元素的抽取,对于已经下载的页面,主要采取三种抽取方式,分别为CSS 选择器、Xpath 和正则表达式。代码实现:
page.putField("div",page.getHtml().css("div1.headline h1").all());
//以css 抽取方式抽取div 标签下class 为headline 中的h1标签。
page.putField("div2",page.getHtml().xpath("//div[@id=qds_boxb1]/ul/li/a"));//以Xpath 抽取方式抽取div 标签下的id 为qds_boxb1 下的a 标签。
Page.putField(key: "div3",page.getHtml().css(selector:"div#demo1 li").Regex(".*中国特色社会主义.*").all());
//css 和正则表达式抽取方式混合使用来抽取。
(3)获取链接则是第三个需要解决的问题,应采用适合的方法来筛选出所需要的链接并将其加入到待抓取的队列中。
page.addTargetRequests(page.getHtml().css("div.jdyw").links().all()); //获取class 为jdyw下的URL
page.putField("url",page.getHtml().css("div.tbig_title h1").all());
//获取URL 中class 为tbig_title下h1 标签中的内容。
4.5 URL 的管理与去重
数据的抓取过程中需要对已经抓取的、重复的URL 队列进行管理,Scheduler 组件负责管理待抓取的URL,以及一些去重的工作。URL 有二种去重方式,一是HashSet,使用Java 中的HashSet不能重复的特点去重,优点是容易理解,使用方便。缺点是占用内存大,性能较低。二是布隆过滤器,使用布隆过滤器也可以实现去重,优点是占用的内存要比使用HashSet 要小的多,也适合大量数据的去重操作。缺点是有误判的可能。除非项目有特殊需求,否则无需定制Scheduler。
4.6 抽取结果的处理
Pipeline 组件负责抽取结果的处理,包括计算、持久化到文件、数据库等。采用Pipeline 来处理抽取结果,有两个重要的原因:(1)页面抽取与后处理相分离,分离这两个阶段使得模块化结构更加明显,代码结构更加清晰。(2)Pipeline 的功能相对固定,更易做成通用组件。WebMagic 默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。Pipeline 定义了如何保存结果,如果要保存到指定的数据库,则需编写对应的Pipeline。
5 新闻数据分析与可视化
即进一步对已经保存在MySQL 中的新闻数据进行分析统计,整理分类,通过使用Dreamweaver 软件用PHP 语言来制作动态网页与MySQL 相连。将所爬取到的新闻信息通过网页的方式呈现给用户。所爬取到的新闻将会进行分类,用户通过对网页的访问,以及利用关键字进行检索,将会获取不同类别的新闻。
6 总结和展望
通过对以WebMagic 为框架构建爬虫,以Maven 技术管理Java 项目的研究,实现了对西藏主流媒体热点新闻的爬取和存储,在爬取过程中,可能会遇到内部网络不允许访问外网的情况,这时就需要设置代理IP。有些网络服务器反感爬虫,会对请求头做个简单判别,直接拒绝那些明显是由自动化程序发起的请求,为了避免自动化程序被拒绝,在请求时,可以修改请求头,让自动化程序更像一个浏览器。
此爬虫系统能够使用户更加全面的获知和了解西藏主流媒体上的热点新闻,促进了人们对于西藏地区物质文化与人民生活的了解,改善了人们心中对于西藏的认知和看法。
