基于自然语言处理的临床合理用药知识图谱构建
2020-01-06王忠民王永庆郭建军刘
王忠民王永庆郭建军刘 云
随着科学的进步与时代的发展,知识的爆炸式增长对医师工作提出了严峻挑战。药物的多样性和患者不同的病理特点使药物治疗复杂化,多种因素都会对用药种类和剂量产生影响,单靠医师的个人判断力往往不够。传统合理用药系统中药学知识库主要依靠专业人员手工构建,人力成本较高,但知识库准确度不高,无法满足院内电子处方审核的要求[1-3]。
药品说明书是药品说明的重要来源之一,也是医师、药师、护士对患者治疗用药时的科学依据。由于药品说明书是由没有计算机背景知识领域内专家制定编写的,其文本都是无结构的自然语言形式的自有文本,因此增加了机器理解的难度。药品说明书中的医疗实体识别和关系抽取是一个复杂的问题,尤其是药物的用法、用量、适应症和相互作用[4-5]。知识图谱由于包含了丰富的语义信息,故可以将海量知识以更直观的方式展示在用户面前。目前已有一些学者对基于国内外药品说明书所有药物实体关系(包含给药途径、重复用药、药物相互作用、适应症、不良反应、禁忌症、老年用药、儿童用药、妊娠用药等)构建的“药物-诊断-临床”诊疗数据形成的知识图谱进行了研究[6-7]。如上海曙光医院构建的中医药知识图谱[8]、本体医疗知识库 SNOMED-CT[9],IBM Watson Health等应用近2年也开始进入人们视线。现有技术中虽然已有药品知识图谱的构建方法,但大量知识图谱都是依靠人工或正则表达式规则提取结构化数据构建。人工方法提取的结构化知识虽然比较精确,但是人力消耗大、花费时间较多,并且人工长时间操作因容易引起疲劳而造成误差;基于正则表达式规则的方法依靠机器,虽然比较节省时间,但是正则方法只适合简单的规则,针对中文的复杂情况,正则表达式的误差会比较高。
目前医学实体的抽取方法主要有基于医学词典及规则的方法[10]、基于医学数据源的统计学[11]和机器学习方法与深度学习方法3类[12-13]。机器学习方法以及深度学习方法通过使用统计学和机器学习方法,结合医学数据源的特点训练模型,进行实体识别。目前传统机器学习方法有隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场模型(Conditional Random Field,CRF)、支持向量机模型(Support Vector Machine,SVM)等,深度学习方法有BiLSTM、BiLSTM-CRF、BERT等[14-15]。在医学领域,命名实体识别的痛点在于数据质量的良莠不齐以及人工标注的专业性要求高。目前有关于如何降低对数据标注依赖的研究,其原理主要是利用海量未标注数据持续提升模型性能,从小样本中进行学习,自我探索逐步学习新知识,形成一个交互学习过程,但效果都不理想。
综上所述,药品说明书中的医疗实体和关系抽取是一个复杂的问题,尤其是药品的用法、用量、适应症和相互作用。随着人工智能技术的发展,知识图谱、医学命名实体识别、图像识别等方法已成为人工智能医学领域应用的基础技术。药品说明书由于其格式不一、种类繁多,如何采用智能化手段结构化药品说明书,自动抽取说明书中的药学实体和关系构建合理的用药知识图谱,并基于知识图谱提供临床用药决策支持成为了关键问题[16]。
1 材料与方法
1.1 材料来源
本文构建药品知识库的数据来源于我国国家食品药品监督管理总局、美国食品药品监督管理总局(Food and Drug Administration,FDA)及江苏省人民医院(以下简称“我院”)的院内药品库。借助python语言,开发爬虫程序,进行药品说明书的抓取,解析之后存储到本地数据库中。从国家食品药品监督管理总局获取了21 000条药品数据,从美国食品药品监督管理总局获取了18 645条药品数据,从我院院内药品库获取了1 827条数据。
1.2 方法
基于机器学习算法,由药学专家总结归纳出完整的药品实体和关系,构建基于药品说明书的合理用药知识图谱,提高合理用药知识图谱构建自动化程度和精度,保障患者用药安全。
具体流程见图1。
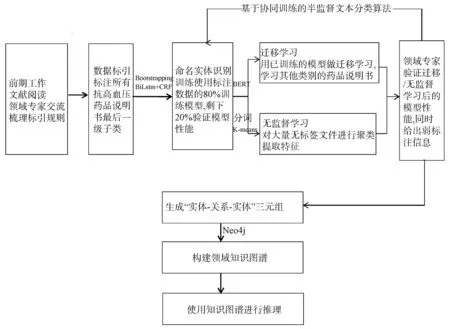
图1 基于深度学习构建药品知识库的流程
利用互联网搜寻可靠、权威的医疗数据来源,按照疾病所属用药利用多线程技术分段爬取全部数据,保证涵盖全部药品大类内容,并在数据爬取过程中分析包括药物间相互作用、适应症、禁忌症、用法、用量等数据结构。
按照药理学分类对爬取的说明书进行分类整理,并随机抽取包含抗高血压类、抗生素类、抗肿瘤类等500份药品说明书用于人工标注。
通过已标注的数据,训练机器学习模型,使用已训练好的机器学习模型预测未标注的药品说明书。本文使用基于BERT的深度学习算法进行命名实体识别,BERT本质上是一个两段式的NLP模型。第一个阶段叫做“Pre-training”,跟WordEmbedding类似,利用现有无标记的语料训练一个语言模型;第二个阶段叫做“Fine-tuning”,利用预训练好的语言模型完成具体的NLP下游任务。Google已经投入了大规模的语料和昂贵的机器帮我们完成了Pre-training过程,因此在药品说明书命名实体识别任务中,我们只需要少量已标注的药品说明书数据就可以完成Fine-tuning。
使用 Neo4j 图形数据库存储一部分结构化的数据,便于进行算法设计,搭配分词、检索、排除、统计等算法提升用药正确率,最终形成可以推理的知识图谱合理用药数据库。
2 知识图谱构建
2.1 人工标注
知识图谱构建的核心是抽取实体和实体之间的关系。
本文基于开源标注工具brat进行人工标注,详见图2。其中,标注实体包括但不限于“不良反应-疾病”“贮藏-温度-光照-湿度”“用法用量-起始剂量-低值”“相互作用-其他”“注意事项-检验相关”“药物禁忌-人群”“不良反应-症状”“用法用量-疾病状态-低值”“相互作用-药品名称”“适应症-疾病类别”“相互作用-结果”“药品名称、药物禁忌-禁用”“相互作用-药品类别”“用法用量-给药频次-低值”“规格”“给药途径”“注意事项-人群”“注意事项-疾病相关”“用法用量-疾病名称”等。
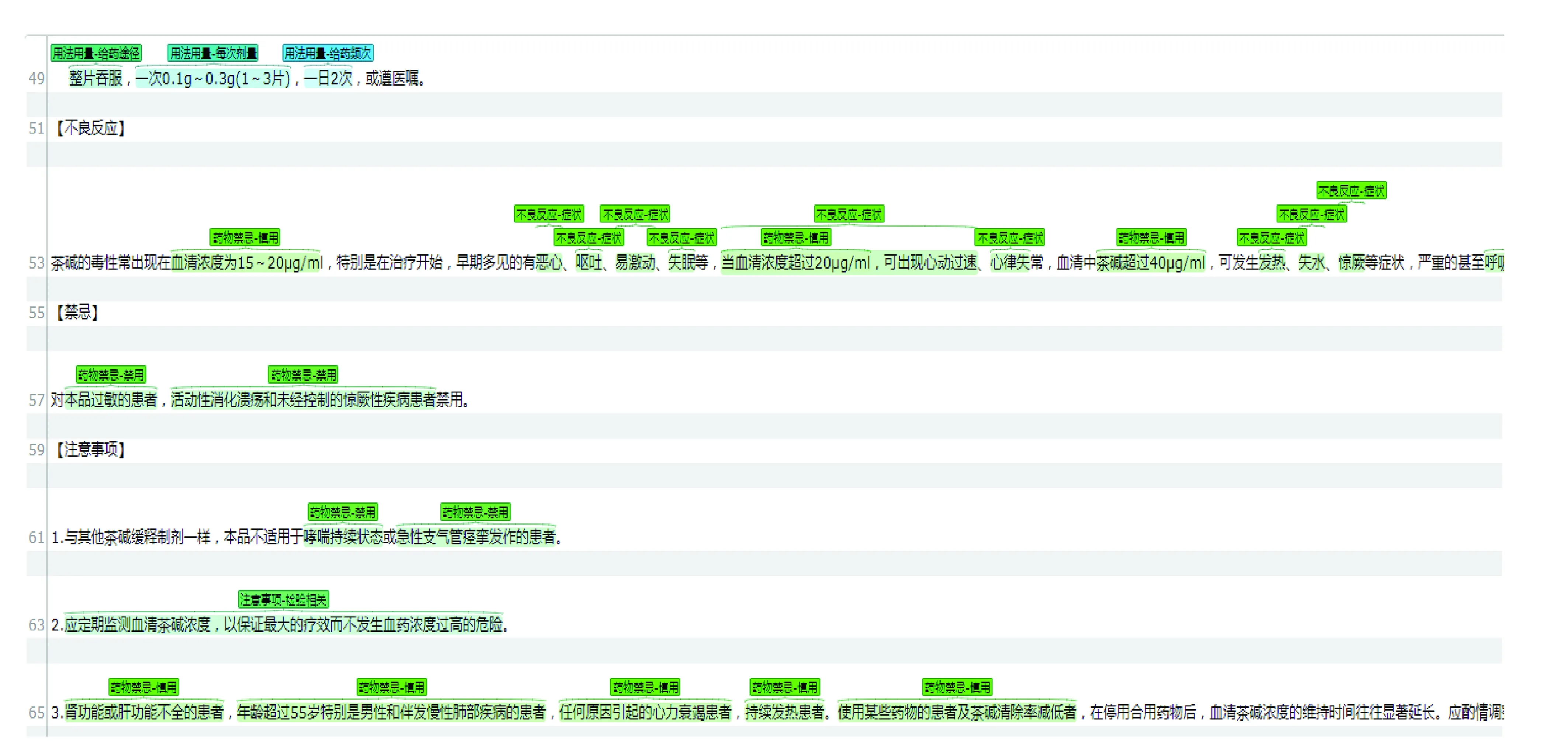
图2 brat标引工具
2.2 知识图谱生成
将标注的数据划分为训练集、测试集、验证集。通过训练集训练模型和验证集验证训练过程中的性能,训练后通过测试集测试模型性能。以药品名称作为第一实体,药品说明书中的实体作为第二实体,其与药品名称对应的关系作为关系,最终得到“第一实体-关系-第二实体”的三元组数据。构建的知识图谱如图3所示,三元组分别为“氨茶碱片-主要成分-氨茶碱”“氨茶碱注射液-主要成分-氨茶碱”“氨茶碱片-适应症-慢性喘息性支气管炎”。以氨茶碱为例,它既作为自身的第一实体,也可能在别的说明书中以第二实体出现。其中氨茶碱片可以治疗支气管病,同时又与其他药品、人群或者诊断有禁忌作用,当医生开立该处方时会提醒其用药合理性。
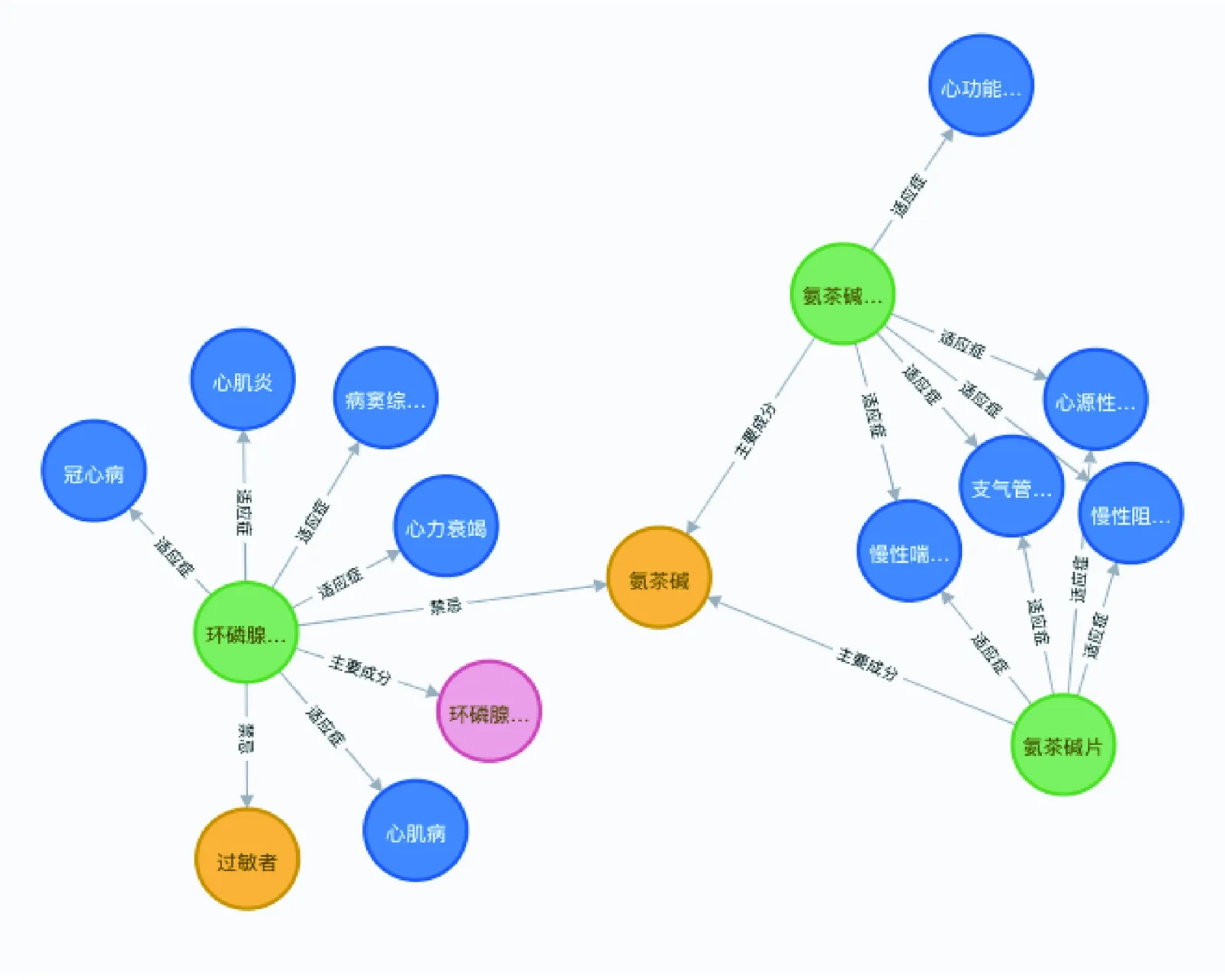
图3 生成的药物知识图谱示例
2.3 知识库存储
知识图谱是基于图的数据结构,通常用图数据库进行存储。Neo4j图形数据库以其对复杂关系独特的表达能力、关系型数据库无法比拟的查询速度及完整的事务性,使其广泛应用于人工智能医疗领域。本文通过对爬取的4万余份药品说明书进行预测,共得到“实体-关系-实体“三元组关系30余万条。部分三元组关系示例见图4。
3 结语
本文基于深度学习算法实现药品说明书命名实体识别,极大地节省了人力、物力和财力,实现了药品的结构化,构建了全说明书实体关系的合理用药知识图谱。
首先,基于半监督学习算法构建命名实体识别的规则。由领域专家制定标引规则是目前命名实体识别的主要手段。文中通过半监督学习算法,结合人工的手段,自动构建标引规则,对领域专家跨域研究提供了重要的技术支撑。
其次,利用小数据量训练集命名实体识别提高识别准确率。大数据量文本标注是当前命名实体识别的主要方法。文中通过深度学习算法,在样本量较小的情况下,提高命名实体识别的效率,对医疗领域自然语言处理具有推动作用。
第三,构建全说明书实体关系知识图谱。全药品说明书实体关系知识图谱的构建,对降低临床不合理用药、患者不良反应等具有重大的社会价值。
本文还存在一些不足,如仅对药品说明书进行命名实体识别。后续还应从医学文献、医学词典、医学指南和专家共识等数据中提取知识,同时不断提高模型预测的精度,为提高患者用药安全提供有力的技术保障。

图4 Neo4j三元组关系示例
