多匹配器自动聚合的知识图谱融合系统构建
2020-01-06
作为一种新型、实用的知识组织工具,知识图谱旨在描述真实世界中的各种实体、概念及其关系,已广泛应用于互联网搜素引擎、电子商务等方面。它在实现海量信息资源的深度挖掘、广泛融合、理解利用方面发挥了重要作用。知识图谱本质是一种基于图数据结构的语义网络,由节点和边组成,节点表示现实世界的实体,边表示实体与实体之间的语义关系。
随着各领域图谱数量的不断增加,解决概念体系异构、消除知识实体之间的互操作障碍已成为图谱应用面临的关键问题。图谱匹配技术旨在建立概念体系和知识实体之间的语义关系,架起异构图谱间的桥梁。由于图谱异构类型的复杂性和多样性,以及单匹配技术的局限性,知识图谱融合系统需要组合多种匹配方法才能具有较好的通用性和较为理想的映射结果。如何有效聚合不同匹配器得出的相似度值是图谱融合亟待解决的问题,是制约多匹配器融合算法自动化的瓶颈。
本文首先通过调研、比较分析几个典型的知识融合系统,总结知识图谱融合框架,并将其作为系统设计的参考模型;然后重点研究多匹配器的自动优化、聚合器的自适应聚合参数调节等核心组件的设计,减少在映射参数设置上的人工干预,提高融合系统的自动化程度。在这些工作的基础上构建一种基于多匹配器自适应聚合的知识图谱融合系统原型,并进行初步实验。
1 知识图谱融合研究现状
知识图谱融合的任务是对不同来源、不同结构的知识或知识片段进行融合。通过对多个相关知识图谱的对齐、关联和合并,从而对已有知识进行补充、更新和去重,使其成为一个有机整体,以提供更全面知识的共享[1]。知识融合需要解决概念体系的融合和知识实体的融合两个问题。
概念体系的融合是两个或多个异构概念体系的融合,是对概念、属性、关系等知识描述体系进行映射和融合,可以解决知识体系之间的异构性,也称为本体对齐[2]。知识实体级别的融合即实体对齐,是对两个不同知识图谱中的实体(实体本身、属性等)进行融合。实体对齐的核心是计算两个知识图谱中节点或边之间的语义关系,主要通过实体名称及属性相似度映射的方式。目前知识融合普遍的做法是通过相似度计算(如基于字符串、词典、词向量、结构信息以及混合方法等),对于大于指定相似度阈值的候选对,会提示用户进行干预或编辑确认,从而实现知识图谱的融合。如YAGO将Wikipedia中的类别标签与WordNet的同义词集进行关联,同时将Wikipedia中的条目挂接到WordNet的概念体系下,使WordNet能提供较高层的概念体系,使Wikipedia可提供具体的实例信息[3]。
AgreementMakerLight(AML)[4]是一种可扩展的自动化知识融合框架,主要针对大规模的生物医学领域知识的对齐问题,是AgreementMaker[5]的升级版。AML实现了基于字符特征(编辑距离、最长公共字符串等)或利用背景知识库的多种匹配器,并根据映射效率的不同将其组合为主要匹配器和次要匹配器两类,用于不同需求的融合场景。最后通过过滤器剔出低于给定相似性阈值以及相互冲突的候选对,从而得到最终期望的对齐结果。
WikiMatch[6]是一个将Wikipedia作为外部背景知识库的融合系统,通过维基百科搜索引擎提取每个知识节点在维基中的片段、标签和注释,知识节点之间的相似度就转化为对应维基片段、标签和注释的相似度计算。由于维基百科文章存在多语言版本,并且这些文章彼此是相互链接的,因此WikiMatch解决了跨语言知识的融合问题。
S-Match[7]是用于匹配轻量级知识库的开源融合框架,实现了多个语义匹配器,同时提供多种接口,能够添加自定义背景知识。S-Match的匹配器分为元素级匹配器和结构级匹配器两类。映射结果通过预定义的冗余结果过滤器进行过滤和选择。
SiGMa[8]是一种使用迭代传播的大规模知识库实体对齐系统,利用关系图中的结构信息及贪婪搜索方式计算实体属性之间的相似性,以解决大规模的知识对齐问题。SiGMa充分利用了实体属性定义的相似度和实体周围节点的信息。
2 知识图谱融合框架设计
笔者以上述4个知识融合系统为代表,详细剖析了这些系统的组成、融合过程及特点,提出了一种知识图谱融合系统框架(图1)。
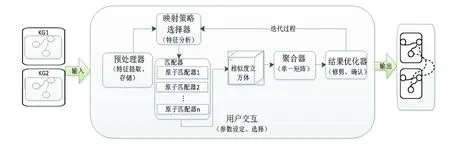
图1 知识图谱融合系统框架
知识图谱融合系统一般由6部分组成,各部分通过预先定义的接口完成数据传递。
预处理器:待匹配知识图谱导入系统后,进行知识节点(概念节点、实体节点)及特征属性的提取。
匹配策略选择器:通过用户交互或者特征分析,选择与组合合适的匹配策略,其实质是不同匹配器的选择与组合。
匹配器:是知识图谱融合系统的核心部分。本文将执行知识节点相似度计算的简单匹配器称为原子匹配器,将综合使用多种匹配算法的匹配器称为混合匹配器。
聚合器:通过某种数学方法或规则将多个匹配器计算的相似度结果值整合为单一相似度的过程。
结果优化器:根据预先设定的优化规则筛查不正确的映射关系或低于某一阈值的映射关系,进行最终结果的确认。
用户交互器:实现知识图谱的输入与输出,以及结果的确认和保存等多项功能。
3 多匹配器自动聚合算法设计
3.1 多匹配器设计
单个匹配技术自身的局限性以及图谱异构类型的复杂性和多样性,决定了不会存在某种匹配技术适用于所有异构的图谱资源,并能够有效解决各种映射问题。知识图谱融合系统需要组合多种匹配方法,才能具有较好的通用性和较为理想的映射结果。本文设计了Edit-WordNet、I-sub和Context(语境)3个单独运行的匹配器。
3.1.1 Edit-WordNet匹配器设计
基于计算编辑距离的相似度能够发现知识节点词形特征的相似性,而基于WordNet的相似度能够发掘其语义上的相似性。由于侧重点不同,本文设计的Edit-WordNet混合匹配器可以互补两者的优势。
定义1:编辑距离相似度算法的计算公式为:
(1)
式中,max(|s1|,|s2|)指较长词条的字母数目,LD(s1,s2)表示词条s1、s2之间的编辑距离。
定义2:基于WordNet相似度算法公式为:
Sim(s,t)=2×depth(c)/[depth(s)+depth(t)]=2×depth(c)/[2×depth(c)+n1+n2]
(2)
该公式是Wu Zhibiao和Palmer Martha[9]提出的算法,使用知识节点间的“IS-A”关系来寻找两个概念s和t的最近公共上位词c,最近公共上位词c是与概念词s和t间以最少的“IS-A”关系边相关联的公共上位词。公式2中,n1和n2分别表示概念词s、t与最近公共上位词c间的最短相对路径长度。Edit-WordNet算法的主要实现步骤如下。
第一步:分别建立源图谱和目标图谱所有单词符号的上位(is-a)关系矩阵word_1[m][wordPOS.Length](m为源图谱知识节点数组KGSource[]长度)和word_2[n][wordPOS.Length]。其中,行是知识节点预处理后的单词符号,列为词性。上位关系矩阵用于保存单词符号在某一词性下(名词、动词)的所有synset节点到独立起始概念(没有上位概念的节点)的路径节点的信息,包括上位关系节点的名称、相对于该synset节点的相对路径长度、路径深度等。
第二步:计算单词符号之间的相似度:
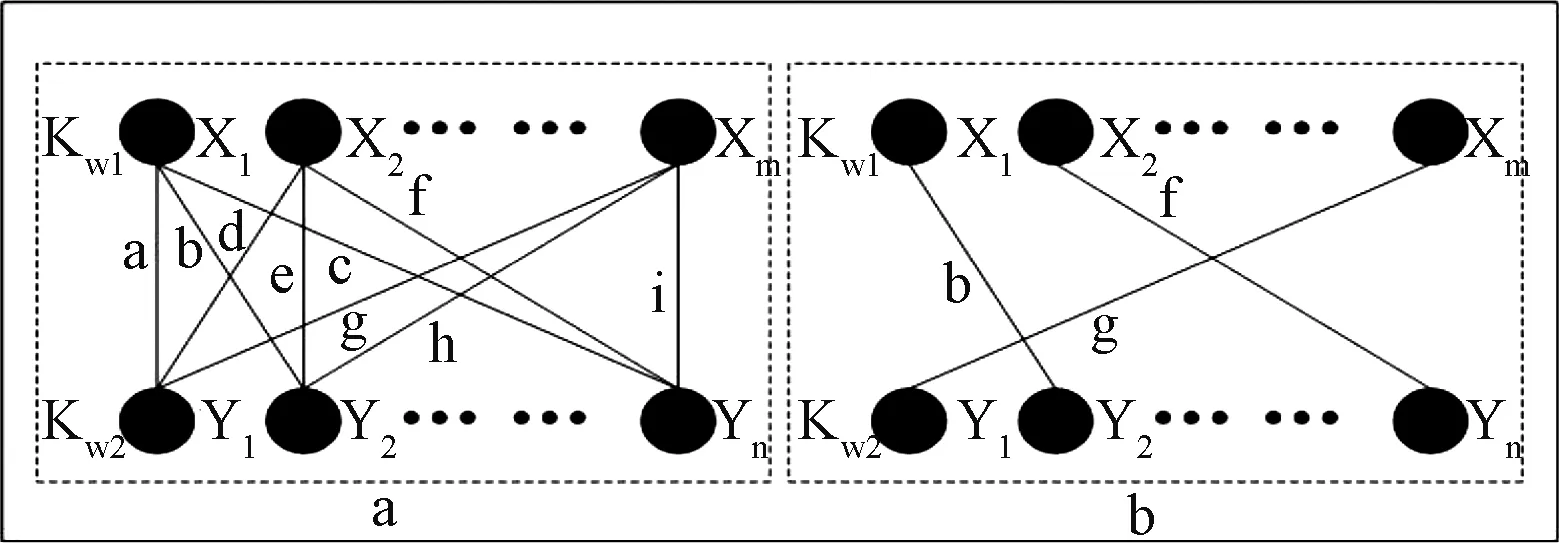
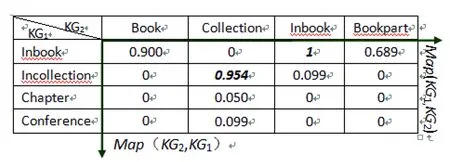
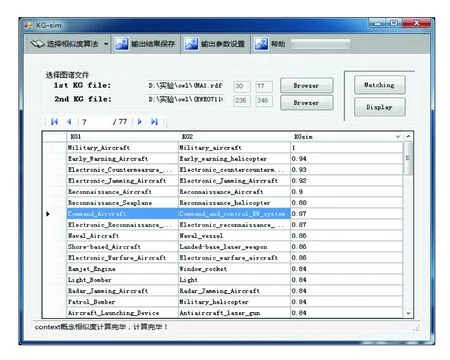
for(int i=0;i for(int j=0;j { float synDist=LDsim(KGSource[i],KGTarget[j]);//调用编辑距离相似度 ①令semDist=Math.Max(Sim(word_1[i][noun],word_2[j][noun]),……,Sim(word_1[i][adverb],word_2[j][adverb]))。其中Sim()的计算方法是根据上位关系矩阵中的节点名称和路径等信息,循环查找其最近的公共上位词,通过公式1计算相似度; ②simMatrix[i][j]=Math.Max(semDist,synDist); //对完整度的考虑 } 第三步:归一化相似度矩阵,通过公式SimWordNet=(sumSim_i+sumSim_j)/(m+n)得到最终相似度值。其中sumSim_i为行最大值之和,sumSim_j为列最大值之和。 3.1.2 I-sub匹配器设计 I-Sub算法是希腊雅典理工大学的Giorgos Stoilos等人从术语学的角度提出的术语映射方法。与同类算法比较,I-Sub具有更好的鲁棒性。这种方法计算的相似度由3部分组成: sim(s1,s2)=comm(s1,s2)-diff(s1,s2)+winkler(s1,s2) 其中,comm(s1,s2)代表两个字符串的相同点,diff(s1,s2)代表两个字符串的不同点,winkler(s1,s2)是由winkler提出的一种改善相似度结果的算法[10]。 3.1.3 Context(语境)匹配器设计 Context(语境)匹配器的主要思想是利用知识节点周围的多种描述数据为每一个节点建立一个语境的描述,然后通过向量空间模型方法计算语境之间的相似度,从而得到知识节点之间的相似度。 知识节点语境由结构面、属性面等分面语境构成。结构面语境由知识节点本身的定义信息(名称、标签、注释)及其所有上位概念、下位概念和同位概念信息构成,用ConS表示;属性面语境由概念属性的集合及其属性的注释、限制(定义域、值域)等信息构成,用ConA表示;实例面语境由概念的实例集合构成,由ConI表示。结合上述定义,知识节点cn的语境ConC(cn)可表示为{ConS(cn),ConA(cn),ConI(cn)}。图2所示的书目概念图谱,Book的语境可以粗略表示为:ConC(Book)={ConS(Book),ConA(Book),ConI(Book)}={ Book,book,monograph,collection,written,texts,Entry,Monography,Compilation,Conrerence,Minutes,heading,volume,issue,publishedBy}。 图2 书目概念图谱片段 基于知识节点语境的相似度算法重点在于通过语境建立向量空间模型,通过计算向量之间的相似度(如向量的内积)计算知识节点之间的相似度。核心算法如下。 第一步:逐一计算每个关键词在每个知识节点语境中的权重值。 for(int i=0;i<关键词个数numTerms;i++) for(int j=0;j<概念语境的个数numDocs;j++) { 关键词i在语境j中出现的频率freq=termFreq[i][j]; 语境j中所有关键词出现次数最大值maxfreq=maxTermFreq[j]; 计算文档频率tf=freq/maxfreq; 语境空间中含有关键词i的语境数目df=docFreq[i]; 计算逆文档频率idf=Log(numDocs/df); 计算关键词i在语境j中的权重值termWeight[i][j]=tf×idf; } 第二步:计算每对知识节点基于语境的相似度值。 for(i=0;i for(j=m;l { 通过termWeight矩阵,生成权重向量vector(i),vector(j); sim(vector(i),vector(j))=(vector(i)·vector(j))/|vector(i)|×|vector(j)| } 单独匹配器在图谱映射的计算过程中,需考虑每一对知识节点之间的相似性。假设源KG1中含有m个元素,目标KG2中含有n个元素,则要进行m×n次相似度计算,形成一个m×n维的相似度矩阵。对于1∶1映射,现有的映射方法大多从相似度矩阵中依次挑选出一一对应的、具有高相似性的元素对作为候选映射。因此对于该m×n维的矩阵来说,存在大量毫无意义的相似度值只会增加后续(如相似度合并)运算的复杂程度,有必要对匹配基数为1∶1的映射采用优化策略,对相似度矩阵的规模进行调节。 受Similarity Flooding和AgreementMaker系统的启发,将这个问题转化为一个最优化分配问题。笔者利用带权二分图的思想将匹配器的计算过程做如下建模:定义源图谱1的所有元素为集合X={x1,x2,…,xm},目标图谱2的所有元素为集合Y={y1,y2,…,yn},然后把两个集合元素对之间所有可能的m×n个映射关系表示为边集E,各个元素对的相似度值为边集E的权重值wij,将其处理后生成一个带权的完全二分图,计算出该完全二分图的最大权匹配,其边集所对应的顶点元素对集合就是匹配器输出的最优候选映射对(图3)。可以采用如匈牙利方法和最短增强路径算法来解决算法设计问题,此处不再赘述。本文对上述3个匹配器进行了二分图的优化,并作为下文中聚合器的输入。 图3 二分图最大权优化示意 聚合器旨在组合多个匹配器的映射结果,如何有效聚合不同匹配器得出的相似度值是制约多匹配器匹配算法的瓶颈。从具体实现上来看,基于函数聚合相似度的方法简单易实现、易于理解、合并效率较高。然而在这些系统的具体权重值的设定方面,要么通过事前验算和模拟实验探索比较合理和满意的经验值参数,要么通过用户交互接口将权重设置权限交给用户。这些做法无法根据不同的映射任务而灵活调整权重,盲目的聚合往往会削弱有效匹配器的映射效能,严重影响映射的发现。自动聚合的关键是能够根据不同的融合场景自动设置各个匹配器的权重,而权重值的大小与其匹配质量正相关。 理论上讲,正确的等同关系映射应该是从KG1到KG2的映射与KG2到KG1的映射所产生的映射关系一致,即在这两个映射方向上计算的相似度值与其他候选元素对相比都是最高的(所在矩阵的行和列均为最大值)。笔者将这种映射关系称为稳定映射(Stable Match,SM),因此可以将稳定映射的数量作为相似度聚合前粗略测度不同匹配器适用性大小的一个指标。也就是说,哪种匹配算法得到的稳定映射关系越多,就说明其适用性越好,在聚合的时候赋予的权重值就应当越高。 图4是一个基于I-sub算法的相似度矩阵。图中的加粗斜体数值表示2个映射方向均为最高的相似度值,因此产生了2个稳定映射关系(“Inbook”,“Inbook”)和(“Incollection”,“Collection”);而(“Inbook”,“Book”)不是稳定的,因为在KG1到KG2方向上不是最大值。 经过上述步骤,我们将匹配器i的权重值定义为: 式中,counti(CM)表示匹配器i产生的稳定映射关系的个数,Sum(count(CM))表示所有匹配器产生的稳定映射关系个数之和,由此得到的聚合器计算公式为: (3) 根据上述单独匹配器的设计及优化后的结果,将各个单独匹配器产生的最优候选映射对作为聚合器的输入,然后将3组最优候选映射的所有源图谱节点元素重新组合为集合X′,目标图谱元素组合为Y′,最后将最优候选映射对根据公式(3)进行多相似度值的结果聚合,生成一个新的m′×n′的相似度矩阵。该矩阵可以进一步通过二分图优化或通过阈值策略作为最终结果的输出。 根据算法设计和分析初步构建了实验原型系统。该系统运行界面如图5所示。为了验证算法的可行性,我们选用单位自建的飞机(KG1,77个知识节点)与电子对抗装备(KG2,346个知识节点)2个领域的知识片段进行了实验。由于系统采用1∶1的完全二分图最大权匹配输出,所以共产生了77对结果集。通过分析发现,等同和包含关系的映射对集中于阈值>0.85的范围内(见表1,其中仅第9、第10两个不相关),除了字形特征完全相同的所有映射对被发现外,通过Context或Edit-WordNet匹配器还发现了(Early_Warning_Aircraft,Early_warning_helicopter)等映射对。实验初步证明,该系统能够较为有效地发现相关知识节点。 图4基于双向映射计算稳定映射关系示例 图5 实验原型系统运行界面 表1 实验结果 本文的主要研究目的是设计一个自调节映射参数的知识图谱融合算法,实现多匹配器的自动优化、聚合参数的自动调节以及映射结果的自动输出,并在此基础上构建了一个工具原型和进行了初步实验。实验结果初步验证了融合算法在无人工干预的情况下能够有效发现语义相关的知识节点,为未来系统的构建奠定了基础。 由于受时间和条件的限制,本文研究仍存在以下一些问题,有待今后进一步探讨和解决。需进一步研究结果修正方法,即拟针对单独匹配器引入最小阈值参数,排除不可能的映射对,进一步提高算法的准确性。最小阈值将通过大量实验进行选择。 鉴于WordNet语义相似度算法的缺陷,如何对多义词进行语义消歧、取出元素synset的正确位序是未来WordNet语义相似度算法改进的重点。此外,图匹配理论和结构相似性传播理论是多数先进知识融合系统普遍采用的方法,今后将在后续版本中加以考虑。 实验结果有一定的局限性,下一步拟扩大实验数据范围,并采用多种性能评测标准进行测试,为系统的进一步优化与改进提供依据。
3.2 匹配器优化设计
3.3 自适应的聚合器设计
4 原型系统构建和初步实验

5 总结与展望
