城镇居民餐饮消费偏好空间及菜系差异的PSM 分析
2020-01-02俞越马佳欣周睿玲北京工商大学经济学院
■俞越 马佳欣 周睿玲(北京工商大学经济学院)
一、引言
自古以来,中国人民重视一日三餐,中国菜更是以独具特色和种类之丰富而名扬海外。随着经济进步,人民的消费水平也日渐增高,在餐饮方面的消费投入更多,对于餐饮服务的要求也更为精细。中国餐饮服务市场稳步快速增长是有目共睹的,行业总规模从2013 到2018 年提升1.32 万亿,到2022 年将还将保持高速增长,且细分市场不断地增加。同时餐饮业的O2O 市场也有较好前景。影响对于一家店铺的评分的项目很多,例如不同的经营时长,不同的菜系分类,不同地理位置,这些都对顾客的评价都会产生影响。
通过对于相关论文的阅读,陈燕(2016)[1]利用层次分析法,得到影响餐饮消费者购买行为的四大因素:个人、商家、网络、其它。进而细分为14 个子因素,得出结论即企业选址应该确定餐饮企业城市定位,环境定位如周边居民收入定位,注重维护企业声誉,注重特色,注重和消费者间网络沟通;关于餐饮消费行为特征分析,岳子静[2]基于美团网数据,探究用户的菜系偏好以及各菜系的传播与发展情况;吴丽云[3]以大众点评网为例,分析了餐饮消费者的网络评论内容,发现不同消费水平的消费者消费偏好有明显差异,餐饮消费者最关注的前五位要素是:食物、环境、服务、价格和便利性;任彬[4]从性别、地区、时间三个维度对微博用户的饮食习惯特色进行了交叉分析,展示了饮食表达特色的分析结果。在消费行为的研究方面,庄岩[5]从农村居民旅游消费行为和旅游消费结构对农村居民的旅游消费进行了研究;蔡晓梅[6]从饮食消费频率、时段分布和消费持续时长三方面分析了广州居民在外饮食消费行为的时间特征;在饮食消费行为的空间分布上, 提出了不同类型饮食消费行为的圈层分布图和高低档次饮食消费行为的空间带状图。
这些研究从城市差异、消费者饮食偏好差异、餐饮店铺环境差异做了分析,还对饮食消费时段分布等做了分析,给予读者分析问题的多种视角,对于一些干扰情况,比如确定是否是因为某一个变量造成了被解释变量有一定差距,还未非常明白地确认,对这些因素进行排除相互干扰的工作也还未做,本文意在通过PSM 模型减少干扰度,进一步探索不同菜系之间、不同消费水平之间的打分差异,并利用半径匹配法、最近邻匹配法、核匹配法三种方法检验匹配效果,发现顾客的菜系偏好,为店铺决策带来更多结论。
二、倾向性得分匹配方法(PSM)
本文将繁华地区样本作为处理组、非繁华地区样本作为对照组,并运用PSM 方法展开分析,具体方法如下。
(一)匹配变量的筛选
匹配变量用logit 模型来回归以确定,根据AUC 的值可以判断出是否具有较好的拟合程度。一般而言,当我们利用Logit 模型求出选择的匹配变量,AUC 大于等于0.8 代表有较好的匹配效果。
(二)平均处理效应的衡量
在考察是否为老店、是否繁华以及什么菜系这些不同的角度带来店铺评价打分差异时的一个关键性问题是,对一个店铺而言只能分析其中一种变量,即为典型的反事实因果推断分析框架。Rosenbaum & Rubin(1983)[8]提出了倾向性得分匹配(Propensity Score)方法,通过找到与处理组(Treated Group)主要特征尽可能相似的控制组(Comparison Group),比较两者之间的差异效应,从而更加客观的评价不同身份带来的影响差异与效果。倾向性得分被定义为:
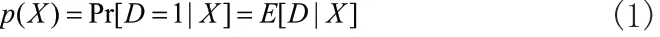
其中,X为自变量的多维向量,是一系列可能影响店铺评价打分的变量;D是指标变量,取值1 表示为处理组店铺,取值0 表示对照组店铺。理论上,如果我们可以获得倾向性得分的估计量(average treatment effect on the treated)则为处理组受到的平均处理效应 (Becker & Ichino, 2002),如下:
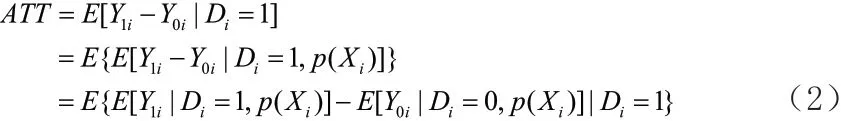
其中,Y1i和Y0i分别为处理组与对照组店铺潜在的被顾客评价打分所具有的潜在偏好因素。
三、变量与描述统计
本文的数据主要来源于北京大学开放研究数据平台的“大众点评网餐厅口碑数据”[17],其中包含3124 条大众点评网广州站美食分类下多种类型餐饮店店家评价和评论信息。
(一)变量选择
餐厅的口碑得分是本研究的目标变量,主要包括等4 种口碑得分。分类变量主要包括是否老店(营业时长大于1000 天的被定义为老店,小于1000 天的为非老店)及各种菜系(包括川菜、粤菜、粥粉面、西餐、日本料理)。相关的匹配变量包括区域类别(分为白云区、海珠区、天河区、越秀区等4 个区域)、星级店铺评价人数,高质量店铺评价人数、推荐率、照片数、是否可团购等变量。
(二)描述性统计
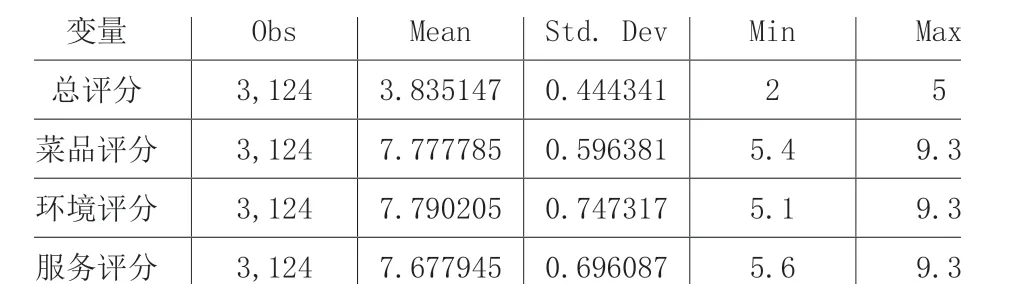
表1 对评分类指标进行统计分析
表1 对餐厅的观测值、均值、标准偏差、最大、最小值进行了分析。在3124 个观测值中,餐厅的平均评分等级为3.83,其标准偏差小于其余各变量(口味、环境、服务),说明评分等级相对较为集中。其中餐厅评级的最高等级为5 级,最小值为2 级。餐厅口味的评分均值为7.78,标准差大于餐厅评级这一变量。值得一提的是,口味打分、环境打分、服务打分的最大值都是9.3。餐厅服务的平均水平在7.79 分左右,其标准偏差在0.75 左右,数据的离散程度在4 个变量中是最大的,其最小值为5.1 分。餐厅服务质量评分的均值是7.68 左右,标准差仅次于“服务”这一变量的标准差,其最小值为5.6,是四个变量中最大的。
四、实证分析
(一)匹配变量选择
我们选取是否为繁华区为被解释变量(繁华地区为实验组,非繁华地区为对照组),区域类别(分为白云区、海珠区、天河区、越秀区等4 个区域)、星级店铺评价人数、高质量店铺评价人数、推荐率、照片数、是否可团购等变量做为解释变量,运用logit 模型展开匹配变量的选择,具体结果见表2。
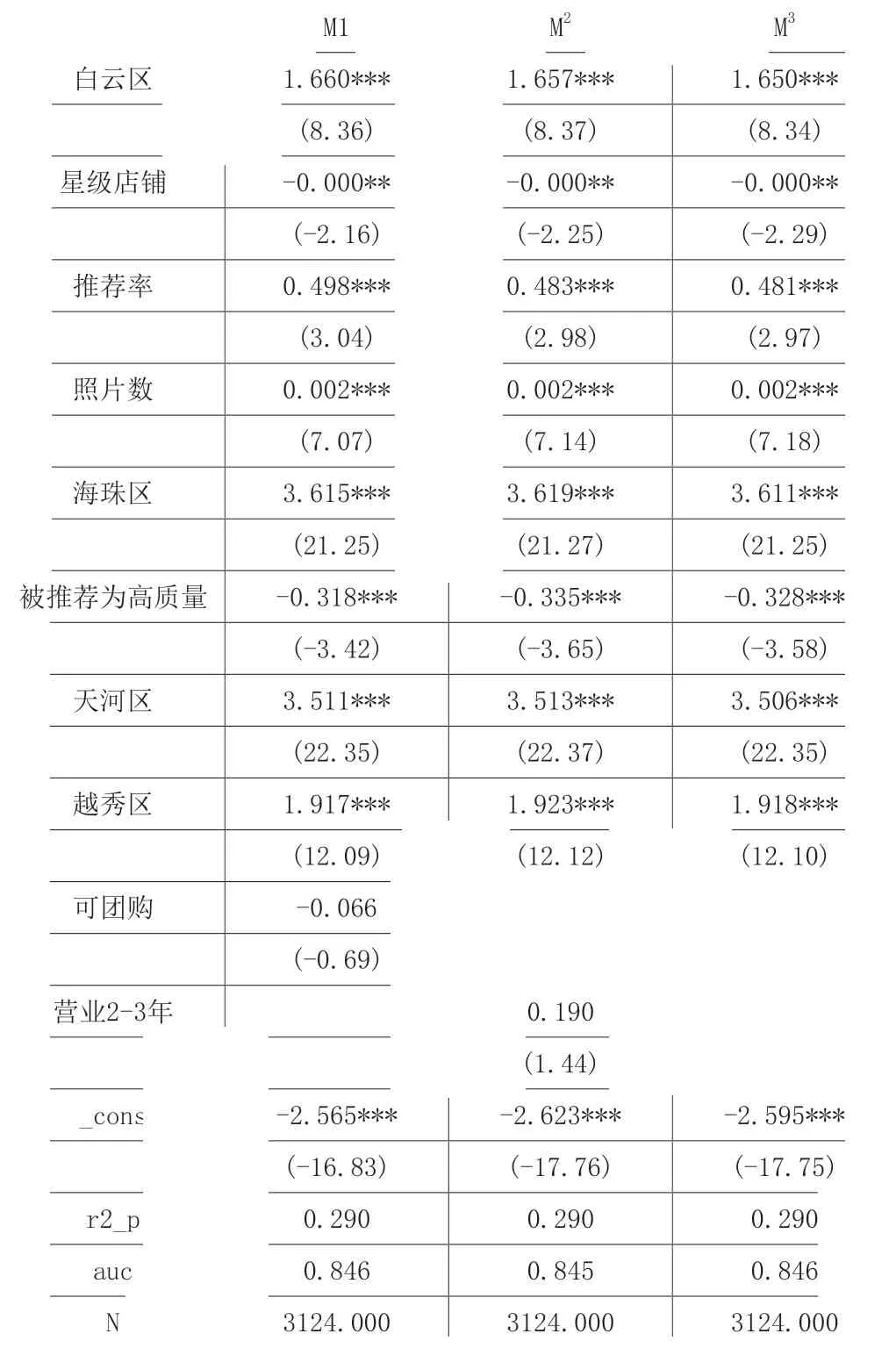
表2 匹配变量的筛选
根据Sturmer,Joshi,Glynn,Avorn,Rothman and Schneeweiss(2006)的研究[9],当AUC 达到0.8 时,匹配效果是比较良好的,从表中可见,模型1-3 的AUC 均达到了0.845 以上,匹配效果良好。另外,在模型1、模型2 中,可团购、营业时间为2-3 年均不显著,为此,本文选择模型3 作为最终的匹配结果。
为了检验模型3 的匹配效果,我们还进一步做了匹配前后的核密度图,这里仅用半径匹配法为例来展示匹配效果,具体见图1。
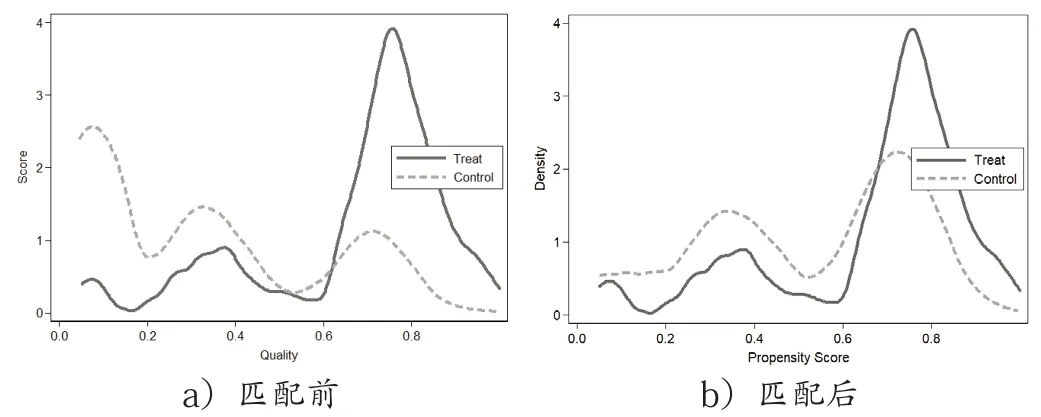
图1 匹配前后核密度图对比
从图中可以看出,在匹配前对照组和实验组的概率分布图还存在明显差异,而完成匹配后,对照组和实验组的概率分布已经很接近了,匹配效果良好。
(二)利用ATT 模型检验匹配结果
为了获取更稳健的结果,本文分别运用最近邻匹、半径匹配、核匹配等三种匹配方法估计不同繁华区域对餐饮企业口碑得分的平均处理效果(ATT),结果见表3。
首先,我们对全样本进行分析,从表3 可以看到,三种匹配方法下,处理组(繁华地区)和控制组(非繁华地区)的服务评分均呈现出显著的差异,繁华地区较非繁华地区高出0.101-0.126 分;而在菜品评分,环境打分方面,繁华地区与非繁华地区的ATT 不存在显著差异。
接着,我们进一步按营业天数分类,探讨繁华地区与非繁华地区在总评分、菜品打分、服务打分和环境打分等方面的ATT 差异,见表3。对于营业天数大于1000 天的店铺,不存在显著的差异。对于营业天数小于1000 天的店铺有显著的差异,尤其是对于服务的评分方面,繁华地区与非繁华地区相比高出0.068-0.167 分。
最后,我们还根据不同菜系分类,探讨繁华地区与非繁华地区在总评分、 等方面的ATT 差异,见表4。
由表4,所用方法顺序与表4 相同,菜品类型分别是川菜、日式料理、西餐、粤菜、粥粉面。对于不同菜品来说,是繁华地区与非繁华地区对四项评分类指标的打分没有显著影响。处理组(繁华地区)和控制组(非繁华地区)的总评分,以及服务评分均在日式料理呈现一定差异,这表明日式料理的服务评分可能与店铺地理位置有关系。西餐方面,繁华地区和非繁华地区在服务评分有一定的差异。粤菜的环境和服务评分,粥粉面的环境评分,都和店铺开设在繁华地区与否有很大关系。
五、结论与启示
由本文得到如下结论:(1)日式料理的服务评分可能与店铺地理位置有关系,开店地理位置需仔细考虑;(2)繁华地区和非繁华地区的服务评分均呈现出显著的差异;营业天数小于1000 天的店铺对于服务的评分方面有显著的差异。参考文献
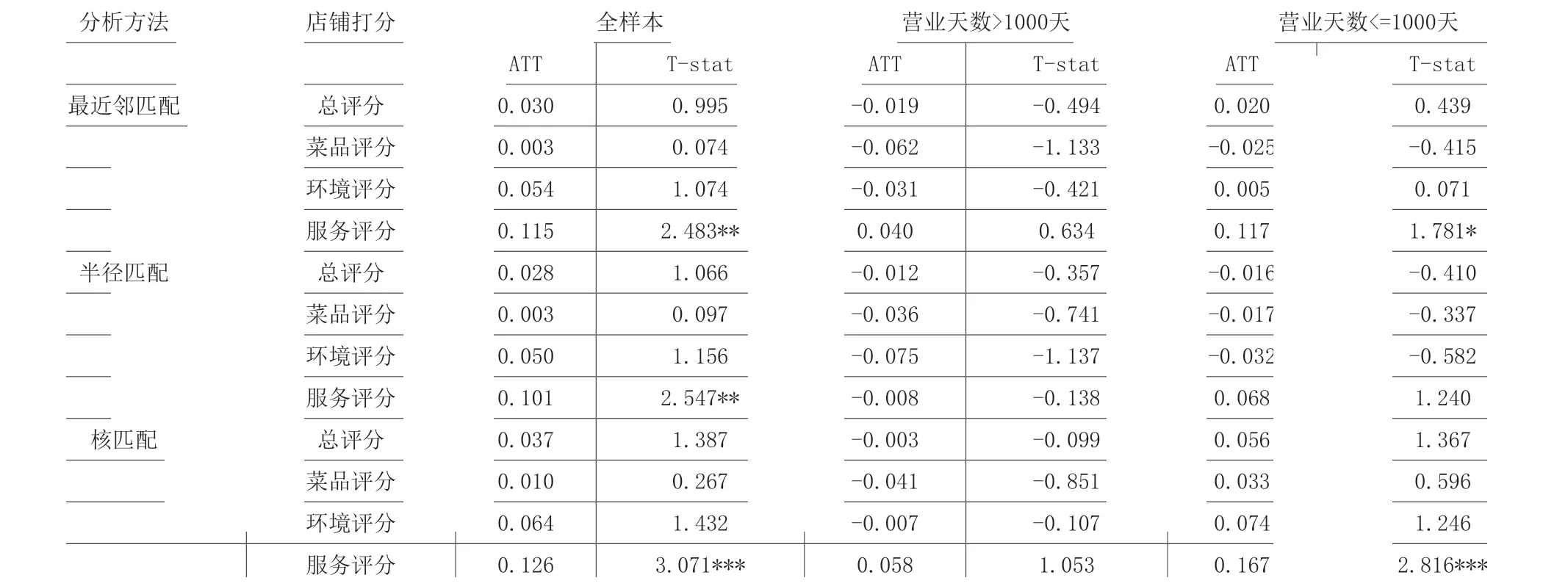
表3 全样本、不同营业天数类别的ATT估计值
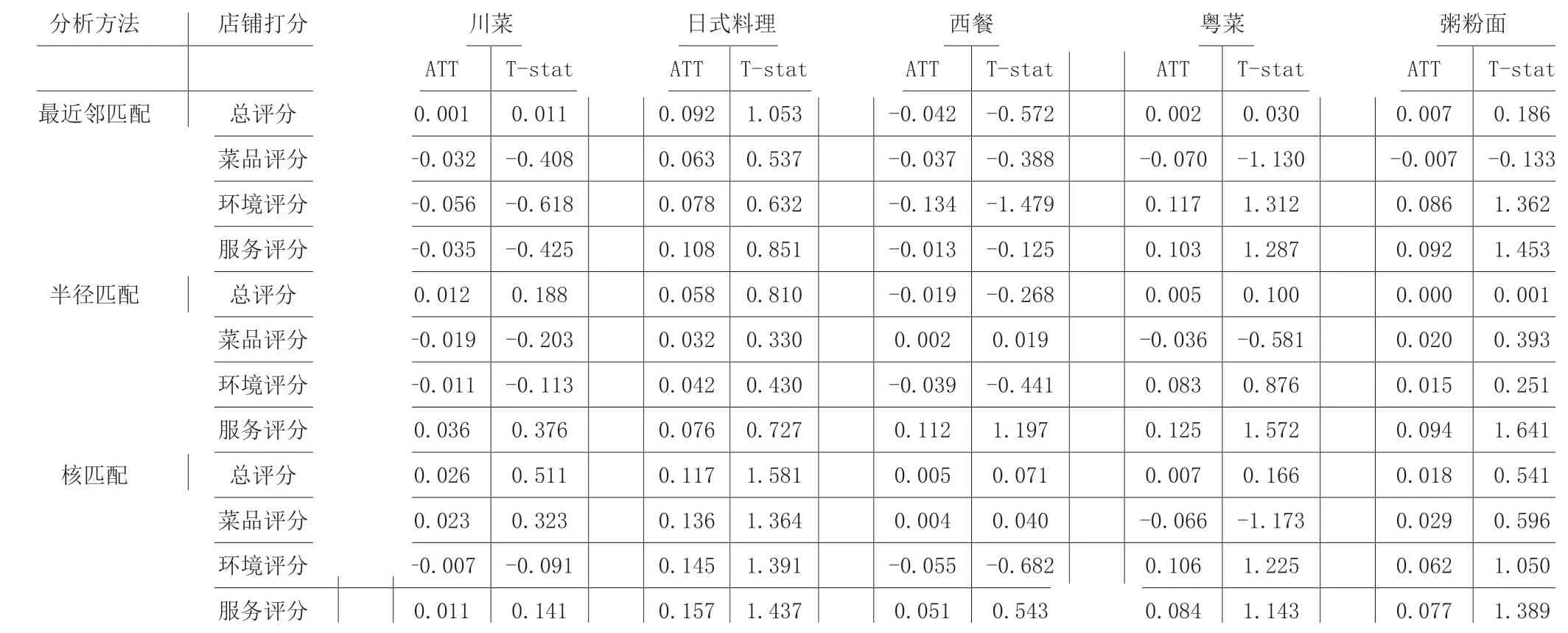
表4 菜系为分类的ATT检验
[1]陈燕.餐饮消费者购买行为影响因素探讨[J].商业经济研究,2016(1):36-38.
[2]岳子静,章成志,周清清.利用在线评论挖掘用户饮食偏好——以北京地区为例[J].图书馆论坛,2017,37(3):108-115.
[3]吴丽云,陈方英.基于网络评论内容分析的餐饮消费者行为研究[J].人文地理.2015(5):147-152.
[4]任彬.基于微博的用户饮食特色及表达习惯分析[D].哈尔滨:哈尔滨工业大学,2005.
[5]庄岩,毛晓东.中国农村居民旅游消费行为与消费结构分析.改革与战略[J].2017(9):114-116.
[6]蔡晓梅,赖正均.广州居民在外饮食消费行为的时空间特征研究[J].人文地理,2008,101(3):79-84.
[7]司倩楠,2018,"大众点评网餐厅口碑数据",http://dx.doi.org/10.18170/DVN/EB6KJ1, 北京大学开放研究数据平台,V1.
[8]Estimating the impact of antenatal care visits on institutional delivery in India: A propensity score matching analysis.
[9]Sturmer, Joshi, Glynn, Avorn, Rothman and Schneeweiss.2006.10.1016/j.jclinepi.2005.07.004.
