应用ASTER遥感图像的岩矿信息提取研究
2020-01-02黄宇飞李智慧宁慧胡震岳曹海翊
黄宇飞 李智慧 宁慧 胡震岳 曹海翊
(1 北京空间飞行器总体设计部,北京 100094)(2 哈尔滨工程大学计算机科学与技术学院,哈尔滨 150001)
遥感影像在不同波段范围内反映了地物辐射、反射和发射电磁波的特性等信息。各种矿产资源的形成与产出都和一定的地质体与地质现象的空间展布等密切联系,不同的矿物、岩石或蚀变矿化等也可通过遥感影像上不同的波谱曲线反映出来。因此通过遥感波谱信息及空间信息的提取,可有针对性地获得与矿化有关的地质体、地质现象的类别和分布状况[1]。遥感工作者对不同矿化蚀变类型采取针对性的异常提取方法在在不同地区都开展了很好的实践。
近几年国内外遥感找矿的研究主要分为主成分分析方法、复合处理方法以及基于高级星载热发射反射辐射计(Advanced Spaceborne Thermal Emission and Reflection Radiometer,ASTER)数据的方法。文献[2]提出了“TM掩膜+主成分变换+分类”识别提取矿产弱信息的技术方法,在辽宁二道沟金矿提取三价铁蚀变火山碎屑岩信息,在河北华北地台北缘提取含金钾化带信息,均取得了较好的效果。文献[3]利用“多元数据分析+比值+主成份变换+掩膜+分类(分割)”的方法在新疆、内蒙古及江西、云南成功的提取了金矿化蚀变信息。文献[4]利用TM、SPOT数据数字高程模型及地球化学信息对爱琴海盆地Quatemary岛弧中的低温热液型金矿进行研究。文献[5]利用TM图像743波段合成图像,根据岩石变形变质特征及遥感影像特征,对喀喇昆仑区域进行地层划分研究并成功地划分出了该区的地层系统。文献[6]利用机载可见红外成像光谱仪(AVIRIS)和ASTER数据对成层火山的热液蚀变进行了研究。文献[7]采用ASTER的近红外,短波红外波段数据以及变差函数纹理等特征用于岩性分类。文献[8]利用ASTER波段数据、温度数据、高程数据等作为特征,用支持向量机进行预测。研究表明ASTER数据其波段设置比其他多光谱数据具有更好的波谱连续性,因此ASTER数据在岩性信息提取和矿物识别方面能达到更高的准确率。
ASTER传感器是搭载在“土”卫星(Terra)上的星载热发射反射辐射计,于1999年12月18日发射升空,其数据包括近红外、短波红外、热红外3个光学系统,共计14个频段,空间分辨率分别为15 m、30 m、90 m。ASTER遥感数据以其更多的频段,提取蚀变矿物异常类型更为丰富,在矿化信息识别取得良好的应用效果。
本文以ASTER数据为数据源,利用热红外波段数据计算出其对应的矿物学指数作为特征,通过随机森林分类算法,对岩矿信息提取分类并绘制矿藏分布图。
1 研究方法
本文采用的遥感图像为ASTER遥感图像,表1中列出了各个子系统对应波段的相关参数。

表1 ASTER图像的波段
岩矿信息提取通过机器学习方法实现,首先提取特征,然后通过随机森林方法实现岩矿信息分类,按以下四步实现,即辐射定标、归一化处理、特征提取和分类。
1.1 辐射定标
将ASTER图像上的亮度灰度值转换为绝对的辐射亮度
L=(d-1)×c
(1)
式中:d为从存储ASTER图像的文件中读取的图像亮度灰度值;c为每个波段对应的增益值;L为表面辐射值。
1.2 归一化处理
TIR频段基于普朗克定律,将所有像素的第13频段的亮度温度转换为固定温度并将其他4个波段的数据转换,得到传感器数据的归一化辐射值
(2)
式中:Li是由式(1)给出的频段i中的传感器数据的ASTER辐射值,i为波段号。λi是每个频段i对应的中心波长(μm);ε13是频段13中的假定发射率为1.0;T是第13频段被归一化的固定温度(K),通过经验公式的计算将其值定为300;c1=3.742×108J·m,c2=1.436 9×104K通过这种归一化辐射的过程,能够将碳酸盐指数对表面温度条件的重度依赖性显着改善。
1.3 特征提取
通过不同类别的岩石在对不同波长的吸收程度分析,分别得出石英指数(QI)、碳酸盐指数(CI)、镁铁质指数(MI)的计算公式为
(3)
(4)
(5)
式中:Ni为式(1)求得的归一化后的辐射值。
特征提取步骤:
(1)读取ASTER图像的TIR的波段数据,共五维,利用式(1)将其图像亮度灰度值转换成辐射值;
(2)将步骤1中的辐射值利用式(2)进行归一化处理;
(3)用归一化处理之后的数据进行指数计算分别求出每一个像素对应的QI、CI、MI的值。
每个已知数据点选取其周围7×7邻域的像素计算,每个像素为一个样本,将其计算出的QI、CI、MI的值作为特征输出。
1.4 随机森林分类算法
1.4.1 分类决策树
随机森林是一种有监督学习算法,它创建了一个森林,并使它拥有某种方式随机性[9]。所构建的“森林”是决策树的集成,分类决策树算法通过熵作为评价指标对分类效果进行评估。熵值越大,表明数据的纯度越低。当熵等于0,表明样本数据都是同一个类别。
假设D表示样本集个数,属性a有v个可能的取值(离散或连续)。进行最有划分属性时,比如先找到了属性a,对a进行评价,接下来对其他属性重复a的过程,分别得到一个评分,选择评分最高的那个,即信息增益最大的作为最有划分属性。
1.4.2 模型建立
将样本集D随机分成训练集S与测试集T,特征维数为F。决策树的数量为t,每个节点使用到的特征数量f。终止条件:所有的节点都训练过了或者被标记为叶子节点。
(1)从S中有放回的抽取大小和S一样的训练集S(xm),作为根节点的样本,从根节点开始训练。
(2)如果当前节点上达到终止条件,则设置当前节点为叶子节点,该叶子节点的预测输出为当前节点样本集合中数量最多的那一类c(n),概率p为c(n)占当前样本集的比例,继续训练其他节点;如果当前节点没有达到终止条件,则从F维特征中无放回的随机选取f维特征。利用这f维特征,寻找分类效果最好的一维特征k及其阈值h,当前节点上样本第k维特征小于h的样本被划分到左节点,其余的被划分到右节点,继续训练其他节点。
(3)重复(1)(2)直到所有节点都训练过了或者被标记为叶子节点。
(4)重复(1)(2)(3)直到t棵树都被训练过。
1.4.3 预测分类
在得到随机森林训练的分类器模型之后,输入未经训练得岩矿指数特征,让森林中的每一棵决策树分别进行分类:
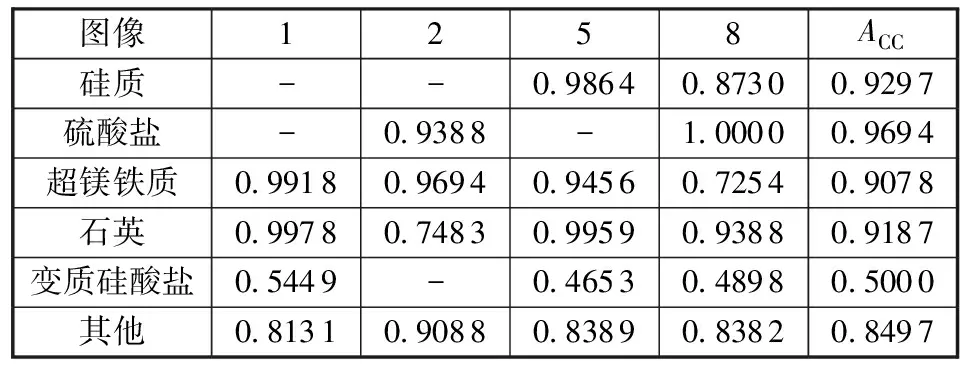
(1)从当前树的根节点开始,根据当前节点的阈值h,判断是进入左节点( (2)重复执行(1)直到所有t棵树都输出了预测值,输出为所有树中预测概率总和最大的那一个类。 首先将文献[10]公布的岩矿标记图像通过谷歌地球软件导出为GEOTIFF格式的图片,利用ENVI软件读取其中已知真实数据点,包括其经纬度以及岩矿类别。待研究的样本是帕米尔高原地区的,已知的岩矿数据点共50个,分布在编号为1~10的十张图像中,每个数据点为某点附近的一小块区域。 所判别的岩矿矿物类型共计五种,分别为硅质、硫酸盐、超镁铁质、石英以及变质硅酸盐。采用3种测试方法:①交叉验证测试,是对所有已知点数据进行交叉验证测试;②新图像测试,即测试集与训练集选取完全不同的图像进行测试;③整张图像类别测试,将所有图像的已知数据点作为训练集,然后对整张图像的类别进行预测。 2.2.1 交叉验证测试 鉴于已知数据点个数有限,所以第一项测试方法采用K-Fold交叉验证,K值取4,将原始数据分为4个子集,每个子集分别作为一次测试集,其他3个子集作为训练集,进行循环交叉验证,并计算得到交叉验证正确率。 岩矿分类评价指标正确率为 (6) 式中:Rj表示用于交叉验证的子集j分类正确的样本数,Aj表示子集j的总样本数。 测试方法是将以上是一张图像已知数据点提取整合,打乱顺序,然后分组进行交叉验证,将所有ACC加和平均作为最终评价结果。图1显示K-Fold交叉验证结果,显示测试集编号分别为1、2、3、4的准确率。 图1 帕米尔高原图像K-Fold交叉验证结果 结果显示,此种方式对于训练数据点与测试数据点在同一张图像上的样本分类能够得到较高的正确率,但其并不能够反映该分类器能够以上表得出的正确率去分类一张没有进行训练的图像。 2.2.2 新图像测试 为了测试所训练的模型对不同图像的分类性能、反映不同图像间的分类准确性,现采用第1项测试,测试图像同表1,第2种测试方法根据待分类中数据点存在的分布选取6张图像(编号为3、4、6、7、9、10,这6张图像中包含所有的数据点)的数据点进行训练,剩下4张图像(1、2、5、8)分别用来测试已知数据点的正确率,正确率计算公式同测试一所述,每张图像每个类别对应分类准确率如表2所示。 表2 帕米尔高原图像分类结果 结果显示,对于训练数据点与测试数据点取自完全不同的图像的情况下,平均正确率能够达到0.849 7,对于变质硅酸盐的分类效果与其他类别的分类效果相比较弱,但平均正确率也能达到0.5以上,对硫酸盐和硅质的分类效果较好,平均正确率都在0.9以上。 2.2.3 整张图像分类测试 将所有图片中的已知数据点作为训练集,训练随机森林的分类器,对整张图像所有像素进行测试,并将图像中的不同类别用不同颜色标注出来,与文献[10]的预测方法进行对比。 图2,图3分别是对编号为8和10的图像进行全图预测的结果,图中白色的标记点是已知数据点,本文预测结果与文献[10]的颜色不是完全一致,可通过白色的标记点找到对应关系。通过同文献[10]结果的对比,可以看出本文预测得到的岩矿分类图与文献[10]的一致性较高。由于图像的质量,如云层的干扰,积雪的干扰等都对数据产生较大的影响,所以对全图预测的结果是有偏差的。 图3 编号为10图像的预测类别图 2.2.4 指标分析 在利用ASTER数据进行岩矿分类的文献中,文献[8]利用ASTER波段数据、温度数据、高程数据等作为特征,用支持向量机进行预测,共预测9类,其中包括五种岩矿类型,如图4所示。分类精度能够达到0.792 8,对超镁铁质的分类精度为0.672 5,但本方法对超镁铁质的分类精度能够达到0.907 8。 图4 文献[8]分类精度 综合同以上文献的对比,本文对已知数据点分类的准确率相对较高,能够识别硅质、硫酸盐、石英、超镁铁质以及石英镁铁质这5个类别,平均分类正确率能够达到0.849 7以上。对所有研究图像进行了类别预测,主观评价结果也较好。 本文以红外多光谱数据为数据源,选取帕米尔高原地区的岩矿数据作为研究对象,计算石英指数,碳酸盐指数,镁铁质指数为特征值,采用随机森林的分类方法训练出分类模型,再利用该分类模型去判断该地区的岩矿种类,根据判断出的结果得出已知数据点的正确率。 从测试结果可以看出,本文所述方法能够通过遥感图像识别出5种岩矿类型,对于训练数据点与测试数据点取自完全不同的图像的情况下,平均正确率相对其他文献来说较好,对整张遥感图像绘制矿藏分布图,主观判断其效果较好。 本文主要用到ASTER遥感图像数据,按照ASTER项目的计划,其数据应用于全球变化研究中,在科研工作中起到了很好的促进作用。ASTER图像质量较高,其近红外和短波红外波段平均信噪比分别为186.73,196.33。但是在下载ASTER数据时发现,在2008年后的ASTER-L1T数据缺少短波红外的数据,虽然本项目的研究主要用到的是热红外的5个频段,但对数据点进行筛选的过程还是需要借助于短波红外的频段数据的,除此之外ASTER的图像时间分布不均,很多月份的数据不存在或者文件中数据丢失,这种状况对图像分析存在影响。对于岩矿信息提取,采用的主要是热红外波段,波长范围在8.125~11.650 μm之间(共计5个频段),由于其热红外波段数较多,对岩矿信息提取有很大的帮助,但热红外波段的空间分辨率较低,应该适当提高其空间分辨率。2 试验验证
2.1 试验数据
2.2 实验方法



3 结论
