BSAED:一种基于双向语义关联的实体消歧算法
2019-12-25李子茂聂梦妍尹帆陈思敏
李子茂,聂梦妍,尹帆,陈思敏
(中南民族大学 计算机科学学院,武汉 430074)
实体链接是实体消歧的基本过程[1],目的是将文本中出现的实体指称链接到维基百科等结构化知识库.实体指称的歧义性是指同一个实体指称在不同的上下文语境中可能指代不同的实体对象. 实体消歧的本质是比较实体指称与候选实体的语义相似性.针对样例:
“一首《李白》用乡村摇滚风的率性旋律,写出李荣浩对随性生活的向往.”
我们依据“旋律”一词便能判断出这里的实体指称“李白”与候选实体“李白(歌曲)”的相似度比候选实体“李白(唐代诗人)”更高,从而将实体指称“李白”链接到知识库中的“李白(歌曲)”.
考虑到出现在同一文本的实体具有全局的语义一致性[2]问题,实体指称与候选实体之间语义相似性可被分为实体指称与候选实体之间的文本相似性以及候选实体之间的语义关联性.
在衡量实体指称和候选实体之间的文本相似性方面,最先被提出的词袋模型用一组无序的词来表达一个文档,利用上下文语境信息与候选实体的单词重叠率来表示候选实体的上下文相似度[3].也有研究利用向量空间模型(VSM)将上下文语境信息和候选实体分别表示为高维上下文向量和候选实体向量,利用点积或余弦相似度计算它们之间的相似度[4].最近一些研究结合深度学习的思想提出了Word2Vec模型,将实体指称、上下文信息和候选实体分别用分布式向量表示[5],然后利用余弦相似度等距离衡量方法计算上下文相似度.
在考虑候选实体之间的语义关联性方面,HOFFART等使用贪心算法在图模型中寻找最小强连通图对实体进行消歧[6].HAN等提出一种集体推理算法,利用实体指称和所有候选实体作为节点构成的依赖图捕获图中节点的相互依赖关系,共同推断出所有指称的实体[7].ALHELBAWY等使用PageRank算法将候选实体节点的首次排序结果与初始置信度动态结合,进行第二次排序以完成实体消歧的任务[8].近期相关研究进一步考虑了知识图谱中实体之间的最短路径,HULPUS等基于图的相关性计算实体之间的最短路径来对实体进行消歧[9],取得了较高的准确率.ZHU等使用互信息为最短路径长度加权来分析知识图谱中实体间的相似性[10],取得了良好效果.
上述方法在进行实体消歧时取得了不错的效果,但是在使用最短路径评估候选实体之间的一致性时,忽略了实体间的最短路径的不对称性问题,即从实体A到实体B的最短路径长度与从实体B到实体A的最短路径长度不相等.
本文针对命名实体的歧义消解,在PageRank算法的基础上提出一种利用双向表示两个实体之间的最短路径,联合实体间的语义相似性构建实体相关图模型,进一步结合上下文信息与候选实体的文本相似性进行链接的实体消歧算法,称为基于双向语义关联的实体消歧算法(BSAED,Bidirectional Semantic Associations for Entity Disambiguation).
1 双向语义实体消歧算法
1.1 数据预处理
本文只针对人名、地名、组织机构名3种类型的命名实体进行消歧.对任意一个给定的文本D使用Stanford NER工具进行命名实体识别,得到待消歧的实体指称集合,记为M={m1,m2,m3, …}.上下文语境词对一个实体指称起着重要的证据作用.相较于其他词性,名词能携带更丰富的信息,因此,使用Stanford NER工具从除去实体指称集合M的文本D中提取出名词,构成文本D的上下文语境词集合,记为C={c1,c2,c3, …}.
本文基于英文维基百科(2018-03-11 打包发布版本,包含500多万实体和3000多万条链接关系)的语料,使用Word2Vec词向量工具对候选实体与实体指称和候选实体之间的语义相似度进行比较.使用图数据库Neo4j将英文维基百科的实体词条和超链接关系抽取出来构建知识图谱.
1.2 候选实体生成
将集合M中的命名实体指称通过Google 发布的Google Knowledge Graph所提供的搜索API获取预备候选实体集,对预备候选实体集进行信息提取及格式化整理,筛选后生成最终候选实体集合N={{m11,m12, …,m1x, …}, {m21,m22, …,m2y, …}, …},其中实体指称mi生成候选实体集合为Ni={mi1,mi2,…,mij, …},Ni∈N.
1.3 实体相关图模型构建
BSAED算法将同一个文本中候选实体之间的双向语义关联结构化表示成一个实体相关图模型G= (V,E),其中V表示顶点集合,E表示边集合.实体相关图的构造分为2个步骤:顶点集合构造和边集合构造.
1.3.1 顶点集合构造
顶点集V:与给定文本D中出现的实体指称对应的所有候选实体集合N,其中mij表示与实体指称mi相对应的第j个候选实体.
V={mij|∀i,j,mi∈D,mij∈Ni}.
(1)
图中每个顶点被赋予一个置信度(CM, Confidence Measure),CM表示在不考虑文本上下文信息的情况下,一个候选实体被链接的可能性,使用Google Knowledge Graph的搜索API返回的ResultScore(匹配分数)作为置信度.
与其他实体消歧方法类似,为避免图模型复杂度,选择CM排名前5的候选实体参与顶点集构造.若候选实体个数不足5,则全部加入最终的候选实体集合中.为方便计算,使用式(2)对同一实体指称对应的所有候选实体的置信度进行归一化处理.
(2)
1.3.2 边集合构造
本文图模型的边由候选实体之间的双向语义关联结构构成.双向语义关联结构由候选实体在知识库中节点间的双向路径关联度和候选实体间文本描述信息的语义相似度决定.双向路径关联度能更有效地表示实体间的差异性,语义相似度能更好地表现出实体间的共性.
(1)候选实体间的双向路径关联度
在使用维基百科作为背景知识库的图模型方法中,已有的方法是利用维基百科中两个词条之间的超链接所构成的最短路径来衡量两个词条之间的关联度,从而构成图模型中两个节点的边[9,11].但是这种方法只是将两个词条之间的超链接网络视为无向图,忽略了其方向,在衡量两个词条之间超链接路径长度时,随机地选择任一词条作为起点进行探索[12],然而,在现实世界中,转换词条的终起点能得到两个不同的最短路径长度.
本文提出一种新的判定两个词条之间路径关联度的方法,即双向最短路径判定法.视词条之间的超链接结构为有向图,记从实体A链接到实体B路径为前向最短路径,从实体B链接到实体A的路径为后向最短路径.
定义两个节点之间的最短路径如下:
ShortPath(va,vb)=
(3)
其中,FShortPath表示前向最短路径长度,BShortPath表示后向最短路径长度.为了更好地描述两个节点之间的路径关联度,将路经长度转化成路径关联度,公式为:
(4)
由式(4)可见,两个节点之间的路径长度越小,两个节点的路径关联度越大.根据“六度分离”理论,在探索两个节点最短路径长度时,把最短路径长度的上限设置为6,即如果两个节点之间的路径长度超过6,则认为这两个节点没有路径关联度.
(2)候选实体间的语义相似度
相关研究表明,利用语义信息为最短路径加权能更好地表达两个节点之间的关联度[10],本文利用候选实体在知识图谱中的文本描述信息来计算两个候选实体的语义相似度.使用SimText(va,vb)表示顶点va与顶点vb分别所代表的候选实体的语义相似度.分别将顶点va与顶点vb所代表的候选实体的文本描述信息通过Word2Vec工具向量化表示为TA(ta1,ta2,ta3,…),TB(tb1,tb2,tb3,…),利用余弦相似度计算可表示为:
(5)
进行归一化处理,得到:
(6)
使用Wightba表示图G中边(va,vb)的权重,若Wightba=0,则表示图G中的两个节点之间没有边连接.需要注意的是,对于同一实体指称源对应的多个候选实体(顶点),不考虑其相互之间的关联关系,即实体相关图中同一实体指称所对应的候选实体顶点间不存在关系边,其Wightba=0.Wightba计算方式如下:
Wightba=αRePath(va,vb)+(1-α)SimText(va,vb).
(7)
1.4 双向语义关联实体消歧算法
基于双向语义关联的实体消歧算法根据候选实体的重要度和候选实体与查询文本的文本相似性,得到候选实体与实体指称的语义相似性,选择语义相似性最大的候选实体作为真正的链接对象,由此得到实体的消歧结果.
1.4.1 候选实体重要度的计算
根据已得到的实体相关图,利用候选实体的双向语义关联结构对候选实体的重要度进行计算.本文基于对PageRank算法的改进,提出一种新的候选实体重要度计算方法,称之为重要度排序(IR,Importance Rank)算法.

表1 IR算法中所有符号定义Tab.1 All symbol definitions in IR algorithm
IR算法的数学公式如下:
(8)
其中,λ为阻尼因子,一般取值为0.85;CM(va)可由公式(2)得到;IR(va)表示顶点va所对应候选实体的重要度;T(b,a)表示实体相关图G中从顶点va到顶点vb的带权转移概率:
(9)
其中,Weightba表示图G中边(va,vb)的权重,可由式(7)计算得到;Nh(vb)表示顶点vb的邻域,即图G中直接与vb相邻的顶点集合.所有候选实体的带权转移概率构成转移概率矩阵Mp;根据算法得到N中每个候选实体的IR值. IR算法的伪代码框架如下.
算法1 候选实体的重要性算法(IR).
输入:候选实体置信度VCM,转移概率矩阵Mp,阈值ε=0.000001,λ=0.85.
输出:候选实体的重要性VIR.
VIR0←VCM;
k= 1;
repeat
VIRk+1=λ·Mp·VIRk+(1-λ)VCM;
k=k+ 1;
until ‖VIRk+1-VIRk‖≤ε;
returnVIRk+1
1.4.2 候选实体与查询文本的文本相似度
IR算法中,节点的重要性计算仅仅依赖于节点之间的关联关系(即候选实体间的双向语义关联结构),无法与待消歧的查询文本建立链接,因此,利用候选实体与查询文本的上下文信息,通过IR算法得到每个候选实体节点的重要性的取值之后,结合候选实体与查询文本的文本相似度对候选实体进行链接.
使用上下文语境词集合C表示文本,词向量表示为TC(tc1,tc2,tc3, …),mij的文本描述信息(取名词)词向量表示为TM(tm1,tm2,tm3, …).计算mij与查询文本的上下文信息的余弦相似度如下:
(10)
进行归一化处理,得到:
(11)
1.4.3 实体链接
考虑到候选实体的重要度和候选实体与查询文本的文本相似度两个方面,用S(mij)表示候选实体mij与实体指称mi的语义相似度:
S(mij)=IR(mij)+SimCon(mij).
(12)
对于实体指称mi,获取最佳链接实体的方法如下:
(13)
其中Link(mij)是指当S(mik)取最大值时,实体指称mi所代表的候选实体.基于双向语义关联的实体消歧算法的伪代码框架如下.
算法2 基于双向语义关联的实体消歧算法(BSAED).
输入:实体相关图G,实体指称集合M.
输出:实体链接结果S.
S←∅;
for eachvh∈Vdo
IR(vh)←使用IR算法计算每个候选实体的IR值;
S(vh)←IR(vh) +SimCon(vh);
end
for eachmi∈Mdo
ifisNIL(mi)
S←S∪NIL;
else
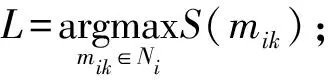
S←S∪L;
end
returnS
针对空链接(NIL)实体指称,提出两种规则进行判定:1)实体指称mi没有对应的候选实体;2)实体指称mi有候选实体,但是链接到的候选实体不是维基概念.
假定文本D中待消歧的实体指称个数为n,IR算法的迭代次数为t(与PageRank算法类似,t是常量级).BSAED算法的时间复杂度分析如下:第1步,初始化实体链接结果的时间复杂度为O(1);第2-5步,计算每个候选实体的IR值的时间复杂度为O(t·n2),计算所有候选实体的IR值的时间复杂度为O(t·n3),所以计算所有候选实体的语义相似度S的时间复杂度为O(t·n3);第6-12步,筛选最佳链接实体的时间复杂度为O(n);第13步,返回最终链接结果的时间复杂度为O(1);BSAED算法在第3步计算IR值时,使用邻接矩阵来存储双向语义关联结构,空间复杂度为O(n2).综上,BSAED算法的时间复杂度为O(n3),空间复杂度为O(n2).
2 实验及结果分析
2.1 实验数据
本文验证BSAED算法有效性的测试集使用的是ALHELBAWY等[8]使用的AIDA数据集,它由CONLL 2003数据集构建,主要用来测试实体消歧的效果,包括一个训练集(TRAIN)和两个测试集(TESTA,TESTB).用于实验的是TESTA测试集,包含215篇文本,内含5919条实体指称,其中可被链接的实体有4785条,涉及到各个知识领域.
2.2 实验评估方法
本文采用准确率P、召回率R和F1值指标对实体链接消歧算法的性能进行评估,计算方法如下:
(14)
(15)
(16)
2.3 实验参数设置
BSAED算法中包含的参数α用于权衡实体相关图中边E的权重.通过在测试集上的实验发现,为使算法的F1值取最优,α=0.4,如图1所示.

图1 参数α的取值对实验结果的影响Fig.1 The influence of parameter α on experimental results
2.4 实验结果分析
2.4.1 特征有效性分析
BSAED算法进行实体消歧主要采用了候选实体的置信度CM、候选实体的文本相似度SimCon、候选实体文本描述相似度SimText和双向路径关联度RePath四个特征,为验证本文选用特征的有效性,在AIDA测试集上进行实验,验证方法是以上述最优配置为基础,分别去掉各个特征来比较实验结果:CM被赋值为1/N,其余各个特征的权重赋值为0,相应的实验结果如表2所示.
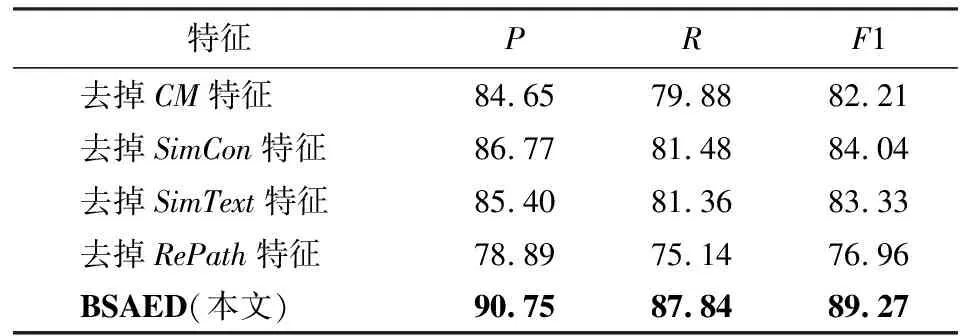
表2 去掉某一特征的实验结果Tab.2 Experimental results without one of features %
从表2可以看出,去掉RePath特征时,实体消歧方法的效果表现最差,F1值的下降幅度达到了13.79%,由此可见双向路径关联度对于实体消歧效果的重要性,进一步分析可知,两个实体之间的最短路径长度能有效表示实体间的差异性,路径越长,两个实体的关联性越弱,考虑到同一查询文本中实体的一致性,关联度弱的实体容易被区分出来.相对而言,CM、SimCon和SimText这3个特征对消歧效果的重要性区别不大,针对CM这一特征,由IR算法原理可知,算法的随机游走过程主要依赖于节点间的相互关联关系,而弱化了节点初始值的效果.至于SimText这一特征,通过数据分析发现部分实体在知识图谱中存储的文本描述的信息比较接近,这种情况下,利用SimText进行实体区分的效果便不太明显,SimCon同理.另外,在算法的性能方面,因RePath需要图数据库Neo4j的支持,花费时间会比其他3种特征长(其他3种特征所需时间差异不大).
2.4.2 双向语义关联度有效性分析
为了验证双向语义关联度的有效性,本文在AIDA测试集上,与使用无向最短路径构造实体相关图模型的方法进行比较,其中,对于实体消歧过程中候选实体筛选和候选实体排序等部分采用与本文相同的处理方式,实验结果如表3所示.
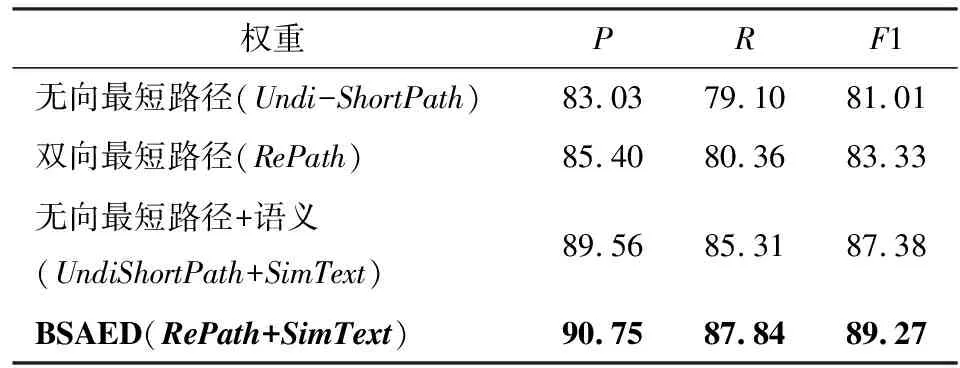
表3 是否使用双向最短路径的实验结果Tab.3 Experimental results with bidirectional shortest paths or not %
由表3可知,只使用无向最短路径(Undi-ShortPath)来作为实体依赖图模型的边进行实体消歧时,F1值为81.01%,当使用SimText为边的权重加上语义信息后,F1值提高了7.86%,可见通过综合实体的差异性和共性能更好地评估候选实体的重要度.双向最短路径(RePath)较无向最短路径(Undi-ShortPath)的F1值提高了2.86%,可见本文提出的双向最短路径能更准确地描述两个实体的关联度.双向最短路径与文本相似度结合使用(BSAED)更进一步地将F1值提高了10.2%,表明本文提出双向语义关联度对实体消歧算法的有效性.
2.4.3 BSAED算法有效性分析
为验证本文提出BSAED算法的有效性,与在同样数据集上消歧效果表现较好的两种算法进行比较,相对应的实验结果如表4所示.
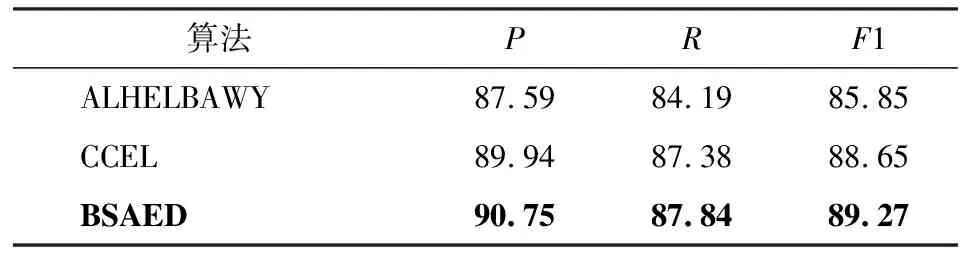
表4 BSAED与相关算法实验结果Tab.4 Experimental results of BSAED and correlation algorithms %
由表4可得,本文提出的BSAED算法在准确率、召回率和F1值的指标上的表现均优于另两种算法.与基于PageRank的集成实体链接算法ALHELBAWY等相比,BSAED算法在AIDA测试集上的F1值提高了3.98%,该结果表明:通过使用知识图谱中的最短路径,可以更好地利用实体的一致性,从而提高了实体消歧的效果;与使用超链接路径的直接关联和间接关联关系来衡量实体之间一致性的CCEL算法相比,BSAED算法在AIDA测试集上的F1值提高了0.7%,该结果表明:通过引入调用Google Knowledge Graph提供的搜索API可以获取到更全面有效的候选实体,一定程度上解决了有效候选实体未出现在最终的候选实体集合中的问题,从而提高了实体消歧的准确率.
3 结束语
本文提出了一种衡量实体间语义关联的方法,充分利用维基百科的超链接结构,更准确地表示了两个实体在知识图谱中的平均最短路径,更合理地描述了实体间语义关联性;同时提出了一种新的基于双向语义关联的实体消歧算法,实验结果表明该算法的准确率和召回率有了提高.
