多维数据驱动粮食供应链危害物风险综合评价
2019-12-23王小艺王珍妮孔建磊金学波苏婷立
王小艺,王珍妮,孔建磊,*,金学波,苏婷立,张 新
(1.北京工商大学 计算机与信息工程学院,北京 100048;2.北京工商大学 北京市食品安全大数据技术重点实验室,北京 100048)
粮食安全问题是关系国计民生的战略问题,影响着国家主权安全及经济、社会稳定发展。近些年由微生物性、化学性、物理性等危害引起的食源性粮食安全问题多有发生[1],开展科学合理性风险评价技术研究成为减少食源性风险威胁、强化粮食安全体系的重要手段。风险评价是结合食品特性、食品的污染水平、膳食暴露等各项因素对食源性危害物风险水平及组合形式进行比较[2],在众多复杂食品安全问题中量化风险级别、识别风险优先次序的一种方法。近年来,各发达国家以及相关食品安全组织已将风险评价应用于食品安全领域,世界卫生组织(WHO)和联合国粮农组织(FAO)指出,食品安全风险评价是一个结构化的决策过程,和风险管理[3-4]、风险交流[5]等密切相关。目前风险评价方法主要包括两大类:1)指标体系法:从食品抽检、调研统计等数据中抽取显著因素及潜在因素,构建多层次多维度的风险评价指标体系[6]。杨磊[7]对粮食食品中不同环节进行分析,构建了粮食生产安全、消费安全和流通安全3个层次指标的食品安全风险指标体系。周少君等[8]综合我国化学性危害物、食源性疾病的暴发流行病学数据特性,对广东省食品安全监督抽检数据进行评定,建立了以半定量风险评价为基础的食品风险分级指标体系,确定了7种需要重点关注的食品安全高风险组合。2)模型分析法:需要考虑食品的多样性、危害物的多样性及危害物毒性差异,以定量或半定量方式对风险发生的可能性和严重程度进行量化赋值和排序计算。目前,国际食品法典委员会提出概率暴露评价模型被国外普遍采用[9],而世界卫生组织、联合国粮食及农业组织共同推荐的决策评价法,成为欧洲计算膳食化合物风险值的常用方法[10]。其他常见模型还包括有sQMRA模型[11]、FIRRM模型[12]以及Risk Ranking Tool、iRisk[13]等。国内学者的研究主要以模糊综合评价法等为主,张娜等[14]在综合考虑了食品、危害物的多样性及危害物毒性差异上,运用模糊数学计算不同类别微生物的风险指数实现评价。
前述方法在食品安全评价及监管工作中得到了一定的应用,以人体膳食健康评价为目标,找到合理有效的评价统一标准,避免不重要因素对风险评估干扰,从而最终实现对食品/危害物组合的合理、有效排序。然而食品安全监测数据往往具有数量大、维度多、结构多样等特点,现有风险评价方法难以在这个多维复杂的风险评价过程中科学运用这些数据资源。本研究的粮食供应链涉及种植、生产加工、流通仓储、销售消费等多环节,存在不同类别和程度的危害物风险因素耦合,且受到食品多样性、数据多源异构、时空差异变化等影响。目前的指标体系法依赖计量数据及统计数据,风险评价过程中缺乏真实抽检数据验证,容易从主观上获取违背实际规律的伪结论;而模型分析法则侧重在大量抽检采样数据对风险因素的量化排序,缺乏对危害物致病严重性、社会关注度、流行病学数据等风险因素的综合评价。因此,粮食供应链危害物风险评价需从全供应链过程演化机制和多维度多层次多角度进行综合研究,只有分析空间分布的规律性特征、地域之间的作用关系,才能采取针对性的防控措施,为政府的正确决策提供更加科学的依据。就食品行业而言,大数据的应用为相关研究者提供了足够的样本含量和数据[15],合理有效的预警方法能大大提高食品安全整体水平[16]。故本研究以大量抽检数据为基础,结合膳食暴露计量数据、流行病学数据和调查统计数据等,针对粮食供应链各环节中主要危害物,构建多维度层次的风险评价指标体系,并利用关联规则挖掘各风险指标内在关联,以获取各指标权重,对各类危害物的风险优先程度进行比较排序,希望为供应链危害物风险预警及防控提供针对性可信方案。
1 数据来源
以全国主要粮食生产省市的各类粮食食品进行实例分析。通过搜集、整理国家粮食局、国家质量监督检验检疫总局网站公布的数据,按照重金属、真菌毒素、微生物、食品添加剂、农兽药残留、品质指标等危害物安全问题及供应链环节来源进行分类整理和预处理。收集到2013年至2018年的粮食加工品抽检结果,包括除港澳台、西藏、新疆、内蒙古、宁夏和甘肃以外的全国26个省份,涵盖粮食主要产区、消费大省及人口密集地区。数据主要由大米、大米加工品、小麦粉,小麦粉加工品、其他粮食加工品组成,反映了我国粮食供应链安全概况。每个样本由多个因素组成,包括产品名称、标称生产企业信息、被抽样单位信息、抽样环节、抽样场所、生产日期、区域类型、食品分类、抽检项目、抽检结果、标准值等。
另外,通过对文献和食品行业专业网站、新闻媒体信息的分析及预处理得到2013—2018年期间粮食食品安全事故的危害物类别及其来源数据;人口数据和消费数据参考国家统计局的第六次全国人口普查结果和《中国统计年鉴》(2013—2018年);致病菌的污染情况、危害程度和流行病学数据来源于《中国卫生统计年鉴》(2013—2018年)、《中国食品工业年鉴》(2013—2018年)。调查统计数据采用调查问卷的方式,共邀请自高等院校、食品药品监管部门、食品行业的专家及从业人员进行论证,发出并回收有效问卷461份。
2 多维层次风险评价指标体系
粮食供应链安全受到众多因素影响,除了受到种植到产品整个食品供应链上所有环节的直接影响,还受政策、法律法规、经济、社会关注等间接因素的影响。本研究在分析海量多维数据特性及粮食安全案例基础上,对各个环节可能出现的安全隐患和风险因素进行挖掘,将粮食供应链划分为生产加工、仓储运输和销售消费3个主要环节。以重金属、真菌毒素、农药残留、微生物、食品添加剂等危害物为研究对象,从统计特性、抽检特性和调研特性角度,构建多维层次指标体系对粮食供应链危害物的风险进行量化和排序分析。为达到快速初步评估的目的,风险分级通常以半定量方法进行,因此指标体系分为一级和二级2个层次指标,每个一级指标由其多个二级指标加权求和得到,而上层评价指标需通过下层评价指标的评价结果反映出来,既涵盖定性指标,如社会关注度、危害程度、监管可及性等,同时兼顾定量指标,如全省年度总产量、粮食生产及消费价格等内容,指标体系框架如图1。
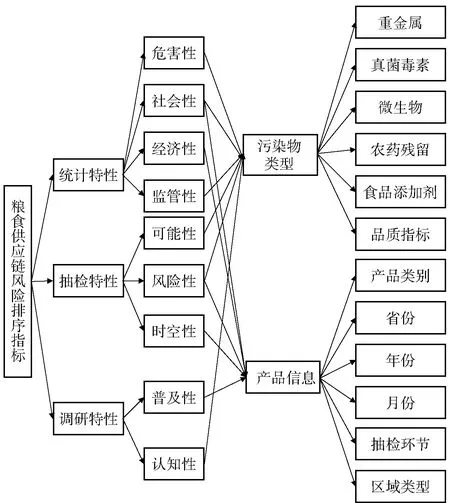
图1 多维层次风险评价指标体系Fig.1 Multi-dimensional risk assessment index system
2.1 粮食供应链统计特性
统计特性从危害物本底出发,客观反映粮食供应链各危害物风险状况,如表1。其中健康指导值包括日容许摄入量,耐受摄入量、急性参考剂量等[17],致癌性依据国际癌症研究机构对不同危害物致癌等级进行划分[18],其他毒性依据危害物类别选择欧盟生殖毒性分级、EPA神经毒性分级、WHO化学品分级及急性半数致死量LD50等进行划分[19-20]。而总体关注度为危害物的百度指数,经济性二级指标则客观表示了各地域粮食生产消费经济结构,监管可及性则表示加强各供应链环节的监管力度对危害物影响性。
2.2 粮食供应链抽检特性
抽检特性则考虑抽检数据分布特性,根据不同省份、不同时间对不合格产品进行划分,如表2。其中危害物含量超标倍数指食品中危害物的含量超过国家标准限量的倍数,表明了污染的严重程度;危害物超标率是指危害物超标样品数占总样品数的比率,表明了污染概率程度;危害物频次总占比是危害物超标样品在不合格总样本比率,表明了污染排序及普遍程度。而风险预防性是指不合格产品危害物产生的环节,本文定为生产、流通和消费;风险可控性指危害物的城镇乡村区域分布情况;健康风险指文献调研中获取的不同人群对象对危害物耐受性和敏感性。时空性二级指标则反映在不同省份、年份及季度、环节出现不合格产品分布情况,频次越高表示食品安全问题越严重。
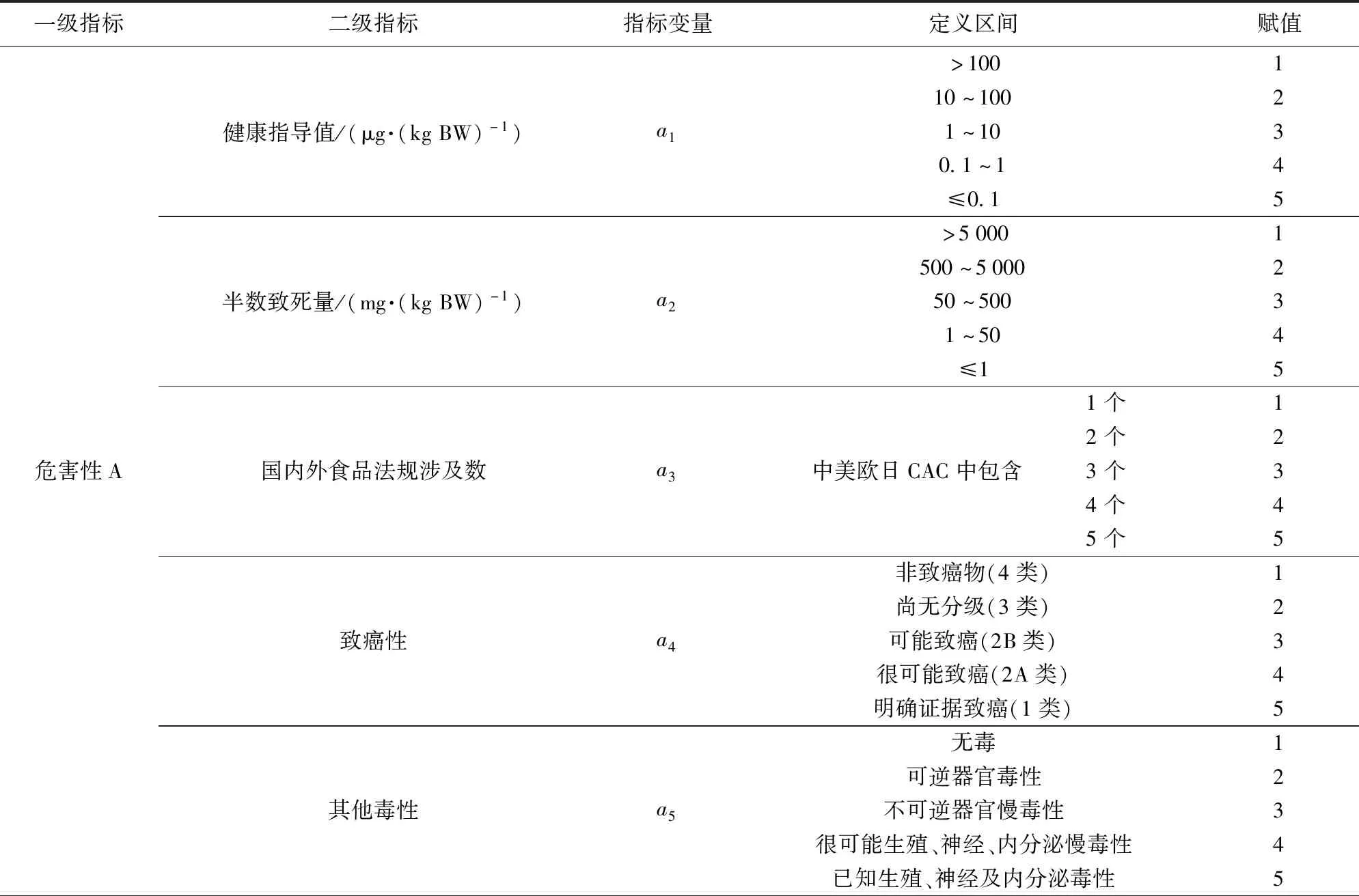
表1 统计特性指标Tab.1 Statistical characteristic indicators
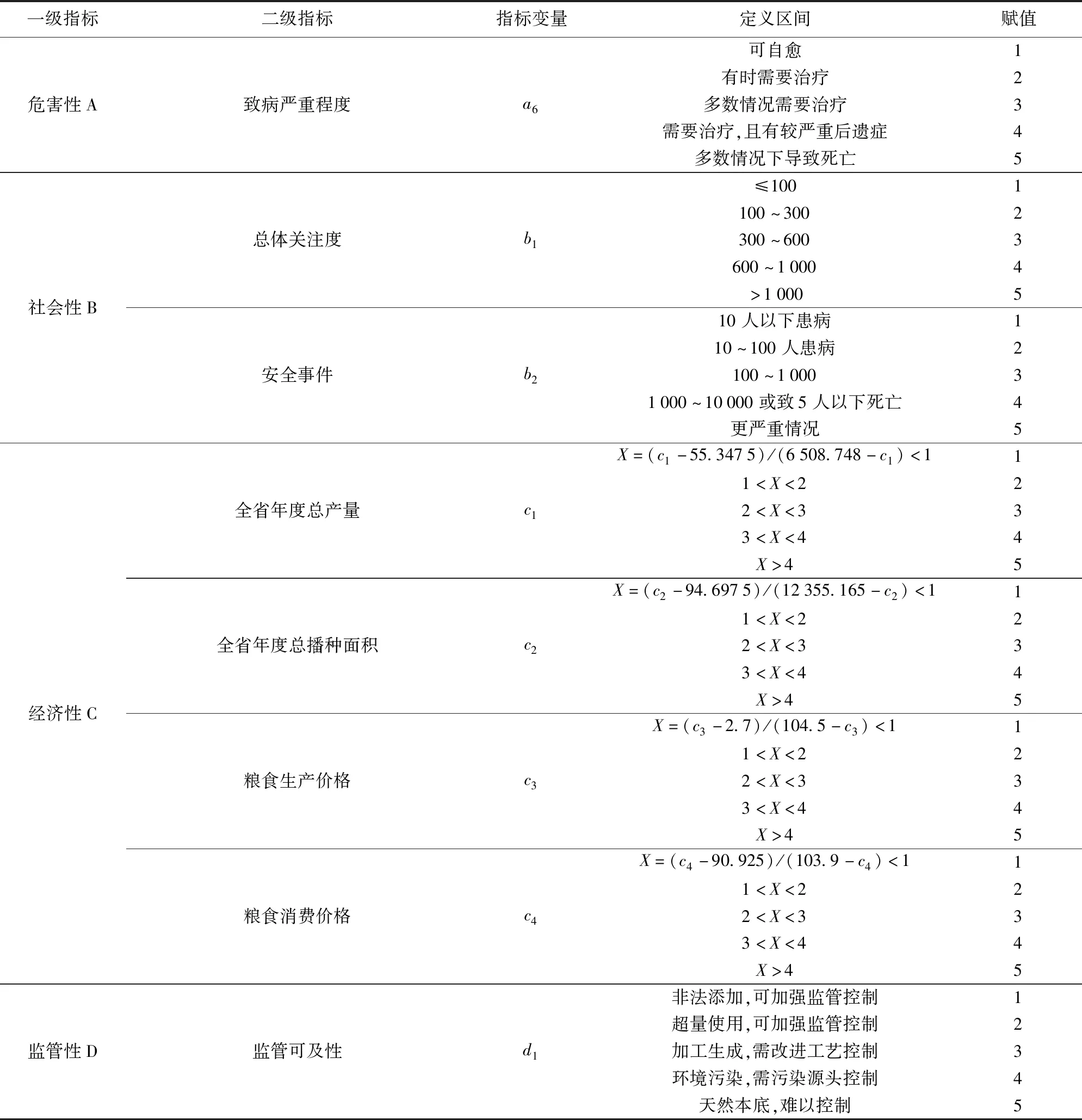
续表1
2.3 粮食供应链调研特性
调研特性依据文献调研和问卷咨询形式来对粮食供应链中危害物风险进行辅助评价,如表3,对于普及程度和认知程度高的指标,给予更高的赋值和权重。
3 粮食供应链危害物风险综合评价
3.1 综合评价方法
本研究由多维度多方面数据出发,针对粮食供应链中各危害物的风险分析。从抽检数据中随机选取样本进行归一化处理,将其输入到多维层次风险指标体系中,得到一级指标危害性A、社会性B、经济性C、监管性D、可能性E、风险性F、时空性G、普及性H和认知性I,见式(1)。

表2 抽检特性指标Tab.2 Sampling characteristic indicators
A=wa1a1+wa2a2+wa3a3+wa4a4+wa5a5+wa6a6,
B=wb1b1+wb2b2,
C=wc1c1+wc2c2+wc3c3+wc4c4,
D=wd1d1,
E=we1e1+we2e2+we3e3,
F=wf1f1+wf2f2+wf3f3,
G=wg1g1+wg2g2+wg3g3,
H=wh1h1+wh2h2+wh3h3+wh4h4,
I=wi1i1+wi2i2。
(1)
其中wj(j=a1,a2,…,i2)对应各个二级指标的权重,a1,a2,…,i2对应各个二级指标变量,下级指标加权求和得到上级指标后,可以分别得到统计特性(Fact1)、抽检特性(Fact2)和调研特性(Fact3),结果见式(2)。
Fact1=A×B×C×D,Fact2=E×F×G,Fact3=H×I。
(2)
结合抽检数据中n个样本,计算得到综合风险评价结果为:
(3)
其中W1,W2和W3分别表示统计数据、抽检数据和调研数据对风险的影响权重。考虑到各风险指标由定性指标和定量指标结合,为避免人为设置对权重的干扰影响,本文使用频繁模式增长(FP-growth)关联规则算法,挖掘指标间频繁模式和内在关联信息,明确3个特性间及各二级指标间的权重,关联规则获取的支持度、置信度和提升度如式(4)。
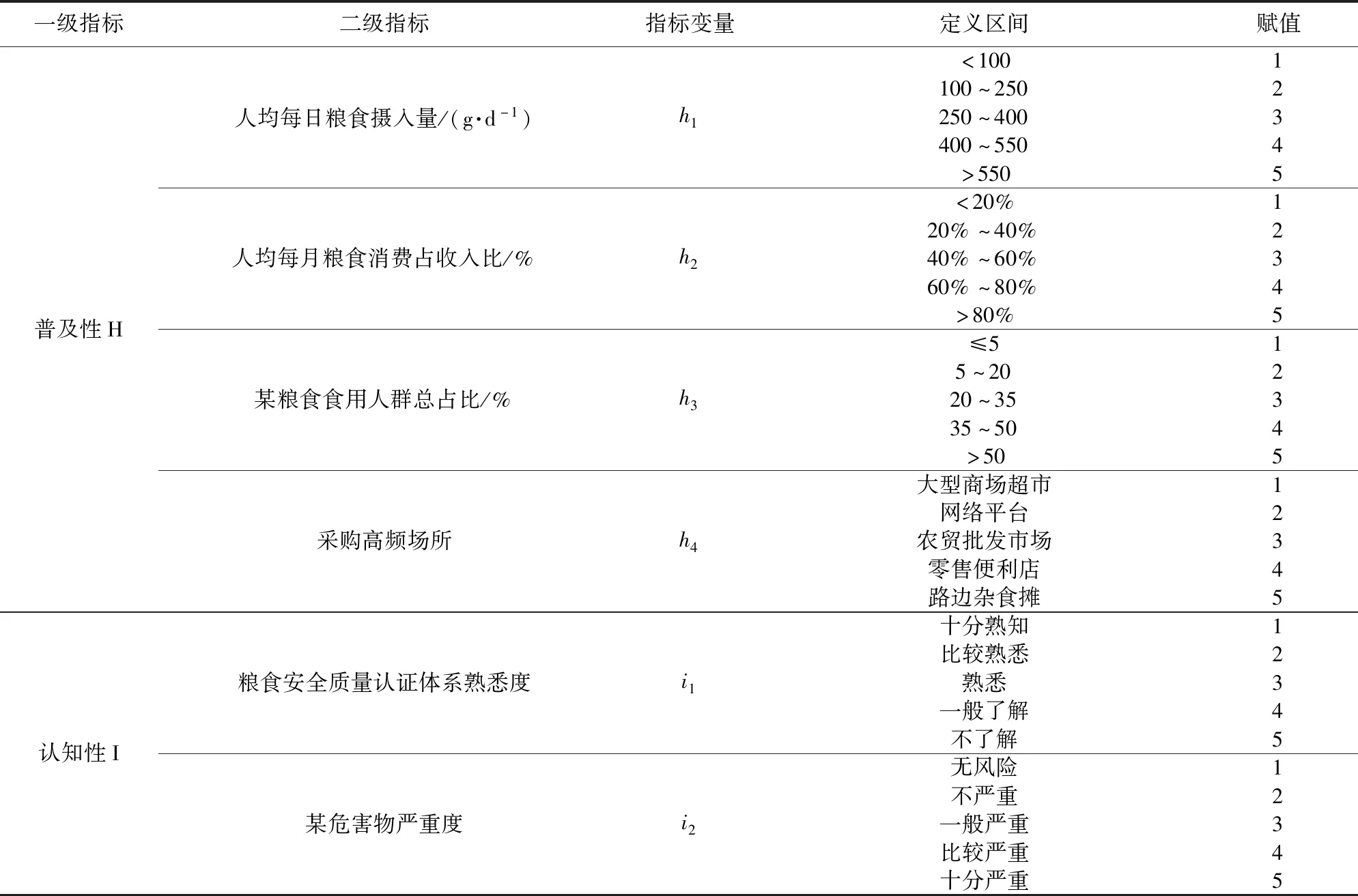
表3 调研特性指标Tab.3 Research characteristic indicators
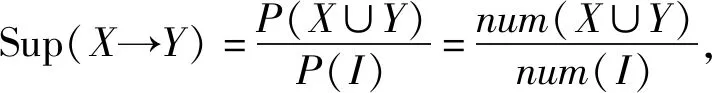
(4)
其中I代表包括各种危害物和风险因素在内的总风险项目,X和Y是不相交的对象,num表示抽检数据中特定项目的出现次数,X→Y是关联规则形式。本文分别对各一级指标中的二级指标进行关联,利用支持度将高关联程度的二级指标给予更高的权重,低关联程度的指标给予较低的权重,再利用关联规则挖掘统计特性、抽检特性和调研特性间关联,实现风险权重的赋值。以评价指标作为控制变量,以关联规则分析各控制变量对状态变量影响的程度,获得不同变量间内在联系概率。这样计算得出的权重结果,避免了人为自主设置权重的干扰,更好融合定量与定性指标,使评价结果更加接近真实数据蕴含规律。
3.2 综合评价与分析
3.2.1单样本风险评价计算过程
3.2.1.1 统计特性
以重金属镉超标的某大米样本为例,镉的每周耐受摄入量为0.2 mg/kg,故健康指导值为4,半数致死量分值取1,世界卫生组织癌症研究所对于镉的评级级别为I级,致癌性为5,法规中涉及个数分值为5,属于中等毒性。但镉可在人体肾脏和肝脏中存留多年,会引起骨痛病、肾损伤等,其致病性为3。大米中镉的百度指数为1 873为3分。湖南省曾出现严重的镉大米事件,故该省风险水平更高,分值为3,2015年份风险水平分值为2,第四季度风险水平分值为2,粮食全省年度总产量、粮食全省年度总播种面积、粮食生产价格、粮食消费价格均与产品生产以及抽检企业所在省份相关,属于客观因素,湖南省四项分值均为1分。镉通常来源于天然本底,主要是通过灌溉用水、土壤以及大气导致污染,其监管可及性较低,分值为5。因此,2015年- 第四季度- 湖南省- 城市- 流通环节- 大米- 镉的客观特性=(1×4+0.4×1+0.6×5+1×5+0.4×3+0.4×3)×(0.6×3+0.6×3+0.6×2+0.6×2)×(0.4×1+0.4×1+0.6×1+0.6×1)×(0.6×5)=14.8×6×2×3=532.8。
3.2.1.2 抽检特性
在本文数据中,镉的超标倍数的分值为5,超标率分值为2,镉在26个省份的波及范围为96.15%,则对应分值为5。检出不合格的环节为流通环节,则风险预防性分值为2;抽检区域类型为城市,则风险可控性分值为1,健康风险值为3。在湖南省产品出现污染的比例为17.08%,分值为1,春季、夏季、秋季、冬季的污染比例分别为34.75%、26.88%、24.99%、15.04%,分值分别为2、2、2、1。最后镉在流通环节检出比例为38.26%,分值为2;在生产环节检出比例为61.74%,分值为4。因此,2015年- 第四季度- 湖南省- 城市- 流通环节- 大米- 镉的数据特性=(0.6×5+0.6×2+0.4×5)×(0.6×2+0.5×1+0.4×3)×(0.4×1+0.4×1+0.4×2)=6.2×2.9×1.6=28.768。
3.2.1.3 调研特性
在调查数据中,镉多存在于大米及加工品中,普及性均为3分,某粮食品种食用人群总占比较高,设为5分,某粮食采购高频场所项目为1分,广大消费者对于镉的认知程度一般为2分,危害度为4分。因此,2015年- 第四季度- 湖南省- 城市- 流通环节- 大米- 镉的调研特性=(0.4×3+0.4×3+0.5×5+0.5×1)×(0.6×2+0.4×4)=5.4×2.8=15.12。
3.2.1.4 综合风险值
利用总风险公式计算出高风险食品危害组合的总风险,则2015年12月- 湖南省- 城市- 流通环节- 大米- 镉的总风险=0.6×客观特性风险+0.2×数据特性风险+0.2×调研特性风险=0.6×532.8+0.2×28.768+0.2×15.12=328.4576。需要对该样本进行高度重视。
3.2.2风险评价分析
根据本文所建立的风险评价体系,可以对粮食供应链中各危害物进行风险评价。分析供应链各个环节中主要危害物风险值如表4。从表4可以看出,流通环节的风险相较其他环节更为明显;3种不同类型产品在生产、流通、消费环节中危害分布情况较为相似,因此在流通环节需严格把控产品的危害物残留量。
表5呈现了粮食抽检数据中分值较高的几项产品信息。在2013年到2018年的抽检数据中,2014、2016、2017年为3个高危年份,其中每年第一季度危害较低,均未发现得分较高的产品;在26个省份中,河南、山东、北京和江苏相较其他省份更应引起相关监管部门的关注;而流通环节在粮食供应链中尤其重要;在城市中不合格产品的检出相较于乡村区域影响更为广泛;最后多种危害物复合出现在粮食产品中为较普遍规律,需要监管人员给予重视。
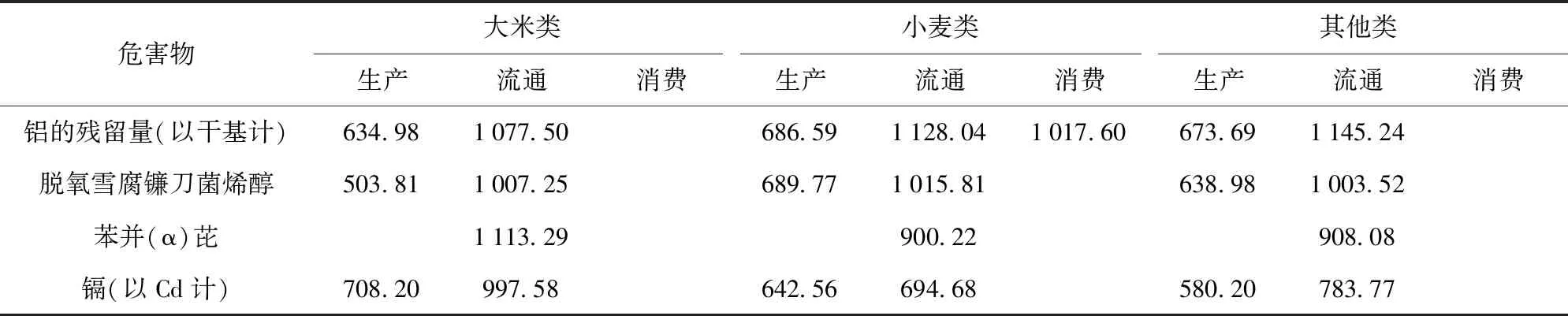
表4 粮食供应链各环节中危害物风险评价结果Tab.4 Risk assessment results of hazardous materials in all aspects of grain supply chain
由于本文所研究粮食抽检数据分布不均,表中展现风险评价结果部分缺失。
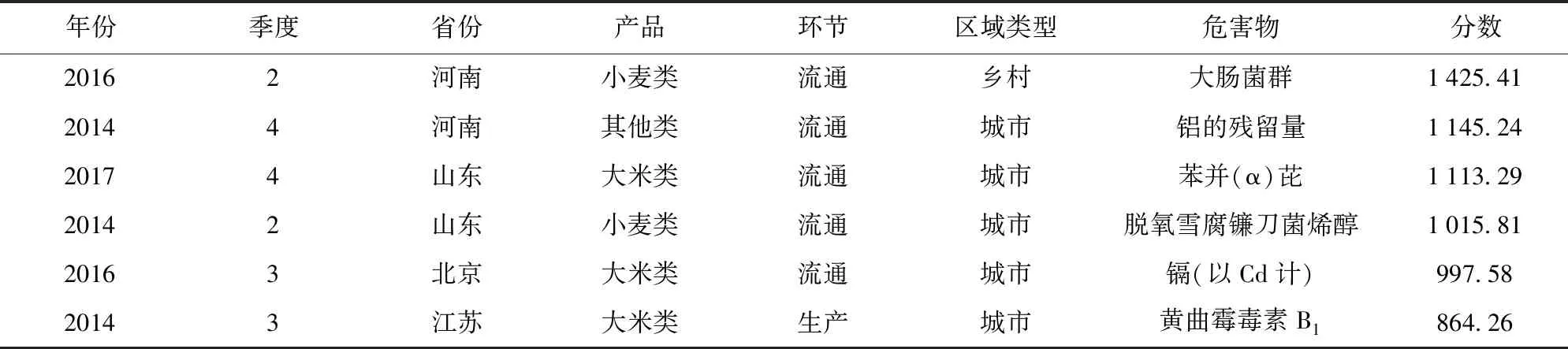
表5 粮食抽检数据危害物风险评价排序Tab.5 Hazard risk assessment ranking of grain sampling data
4 总结与展望
粮食供应链安全是多维、复杂、耦合的过程,现有风险评价方法受到监管目的性、数据可及性及评价可行性等因素影响,存在一定的应用局限。本文在分析26个省份的抽检数据及其他多源异构数据基础上,从统计特性、抽检特性和调研特性3种互补角度构建多维层次风险指标体系,结合定量指标和定性指标的主要优点,一定程度上提升粮食供应链危害物风险综合评价的准确性和可行性。在此体系基础上,采用关联规则挖掘各指标间内在关系,客观准确地获取各指标权重,实现多维数据驱动的粮食供应链危害物风险评价和程度排序。此风险指标体系和评价方法的初步建立,能识别出粮食供应链中危害物综合风险和优先次序,为监管部门制定有针对性的预警策略、确立优先监管领域和合理分配风险管理措施资源提供科学依据,也为广大消费者在选择粮食产品时提供有效可行的指导意见。
随着农业物联网的完善,农业大数据分析在智能农业中拥有巨大的机遇,这不仅取决于大数据分析的硬件条件,还取决于技术和方法的实用性,以及大数据源的日益开放。“十三五”规划中对于智慧农业的强调,鼓励了更多对于推进农业机械化、加强农业与信息技术融合的学术研究,以期在未来逐步完善智慧农业体系。在未来工作中,我们计划研究更多基于机器学习或深度学习的模型,对粮食产品全供应链的监控数据进行深入研究,及时预警不合格产品,实现粮食全产业链的智慧风险监管,为相关政府机构、工厂以及消费者提供科学可靠的评估结果,以满足更多实际应用需求。
