基于降噪滤波与FHMM的非侵入式负荷监测算法
2019-12-20侯艾君王永生顾博川李晓枫
侯艾君,王永生 ,顾博川,李晓枫,孙 毅
(1.广东电网有限责任公司 电力科学研究院,广州 510080;2.东南大学 电气工程学院,南京210096)
随着智能电网的发展,家庭用电负荷的分析开始变得更为重要,不仅用户能获得家庭用电信息,用电部门也能通过提高用电负荷预测的准确性来为电力部门提供统筹规划的依据。这对于家庭能耗评估和节能策略的研究具有指导意义[1]。
根据方式的不同,负荷分解可分为侵入式负荷分解和非侵入式负荷分解。侵入式分解在户内的用电器上安装负荷检测装置,而非侵入式分解NILM(non-intrusive load monitoring)则是在进户前的总线端安装检测装置,通过用户的总负荷消耗预测每个用电器的能耗。NILM无需安装大量传感器、测量装置,可以降低购买、安装和维护NILM系统硬件的成本,是未来负荷分解的发展热点之一[2]。
为了提高NILM预测的精度,国内外已陆续提出各种不同的算法[3-4]。其中,隐马尔可夫模型HMM(hidden Markov model)在分析时序问题上,具有非常大的优势,因此被广泛用于模拟电器的能耗序列,从而应用于NILM领域。若将每个电器视作一条隐马尔可夫链,则模型被称为因子隐马尔可夫模型FHMM(factorial hidden Markov model)。 HMM 的许多其他的改进形式也被应用于NILM领域[5],如隐半马尔可夫模型HSMM(hidden semi-Markov models)和条件隐马尔可夫模型CHMM (conditional hidden Markov model)。
另一方面,若将电器的工作曲线视作信号,则在建立模型之前还涉及到对信号的预处理。滤波作为最常见的预处理方式,能快速滤去噪声,使模型能快速准确地读取到信号的特征而不受冗余部分的影响。故在此,提出了基于滤波信号预处理、因子隐式马尔可夫模型算法的非侵入负荷分解的方法。
1 隐马尔可夫模型介绍
隐马尔可夫模型HMM是一个生成概率模型,它由一串无法直接被观测到的隐藏序列与一串能被直接观测到的、由隐藏序列产生的变量序列构成。其中,隐藏序列是一组马尔可夫链,而它能被可观测序列间接观察到。
马尔可夫链是一组具有马尔可夫性质的离散随机变量的集合。给定一随机变量序列X,若X满足性质
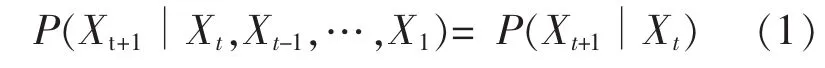
则称其为马尔可夫链。
HMM的参数共有3个:π为马尔可夫链的初始概率向量;A为前一个隐藏状态转变到后一个隐藏状态的概率,即转移矩阵;θ为给定某一隐藏状态时观测数据的概率分布,即发射概率分布。对任意的HMM 模型,只要给定参数(A,π,θ),则模型唯一确定。
1.1 因子隐马尔科夫模型
若模型中只有一条马尔可夫链,则所有的观测状态都由这一条马尔可夫链产生。然而在NILM问题中,会有不同的电器在同时工作。又因为每一种电器在一段时间内的功率消耗序列均可看做一段时序列,所以实际能观测到的序列(总功率消耗)是由多条马尔可夫链共同产生的。FHMM示意图如图1 所示。 图中,ai,bi,ci均为隐藏变量;oi为总的观测变量;i为时刻,i=1,2,…,5。 可以看出,每一时刻观测量oi都是由3个隐藏状态共同产生的。

图1 FHMM示意图Fig.1 FHMM schematic
由图可见,针对需要解决的这一特定的实际问题,FHMM更容易模拟分解能耗的实际情况。在FHMM中,隐藏的马尔可夫链有多组,而被直接观测到的数据则由所有的隐马尔科夫链所产生的可观测量叠加而成。
1.2 模型训练
分解能耗的需求应由FHMM完成。更具体地说,基于时间序列之上,每一个电器都是一组独立的马尔可夫链,而每一特定时间t非侵入电表所观测的用户总能耗,即为全部马尔可夫链所产生能耗的叠加。
(1)单电器模型建立
在开始分解总电表数据前,先对模型进行训练,而这里的训练方式即对一段时间内捆绑每一个电器的电表数据进行学习,也因此,这种学习方式也被称作监督式学习。在学习过程中,针对每一个电器建立一个独立的HMM。
首先,HMM的隐藏序列所包含的可能状态数量即为电器可能的工作状态种数,而可观测量当然就是各电器每一时间的能耗。可以人工对电表数据进行处理,明确指出机器有多少种运行状态,也可以不进行处理,而只确定最多运行状态数,再使用K均值聚类的方法来总结出电器运行状态的种数。
其次,要选定可观测变量所服从的概率分布。又因能耗显然是连续性随机变量,用正态分布模型来模拟发射概率分布。此时,参数θ便是正态分布的均值与方差。
(2)期望最大化算法
期望最大化算法可用向前向后算法实现,其本质是根据观测序列使用最大似然估计来求得HMM的各个参数。若有观测序列 O={O1,O2,O3,…,Ot},无法观测到的隐含状态序列为I,待求参数λ=(A,π,θ),某次迭代中参数值为,则联合分布 P(O,I∣λ)
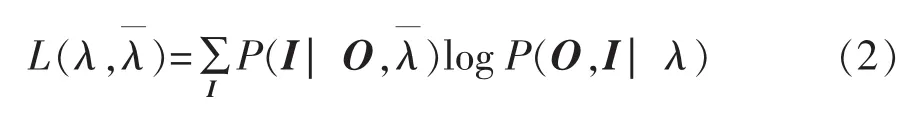
则使得该期望最大时的参数λ为
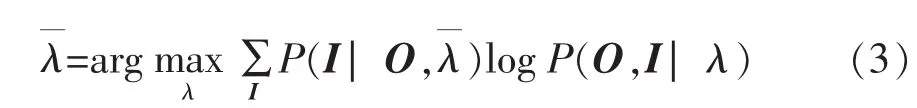
重复上述迭代过程,直至λ收敛为止。
(3)参数合成
现在对每一个电器的模型参数进行处理,因为在分解过程中可观测序列为所有电器能耗的叠加值,故在此需要将独立的多组马尔可夫链统合成一组马尔可夫链。
对于转移矩阵A,将不同电器的A依次进行克罗内克积。克罗内科积使得相乘的两矩阵中的任一元素都能得到配对,这样也就考虑到了不同电器间不同工作状态组合的所有情况。由于不同组的隐藏变量(也就是电器的工作状态)彼此独立,故可以直接相乘得到不同情况叠加后的概率。初始概率向量π的处理方式同转移矩阵。
若对于电器Q1与Q2,假设两电器均只有2种工作状态(即开启和关闭),且其初始概率向量π分别为π1=[π11,π12]和 π2=[π21,π22],则进行克罗内科积后,得到的新初始概率向量为
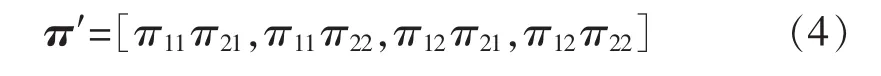
对于状态转移矩阵则需考虑更多不同的状态转移的组合,故合成得到的新转移矩阵一般非常庞大。
正态分布均值则对不同组的任一均值进行随机组合,并将每一种组合中的各均值相加,得到情况叠加后新的均值。方差的处理方式同均值。
1.3 负荷分解
当完成训练与参数合成的步骤后,便可以通过已知的马尔可夫链参数,即输入的总电表测量数据和所得到的模型参数,得到概率最大(最可能)的隐藏状态序列。
(1)维特比算法
在HMM中,在已知观测序列的情况下,一般使用维特比算法来计算使得该观测序列出现概率最大的隐状态序列。即
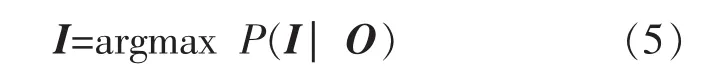
在马尔可夫链的假设下,其等价于
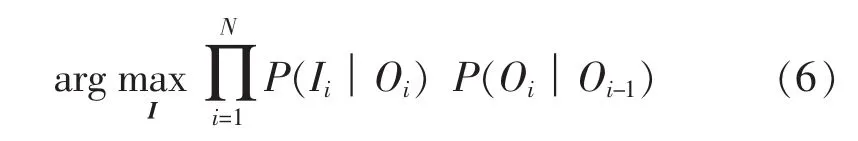
(2)回溯到各电器
得到隐藏状态序列后,还需要通过把每一时刻的状态点(即电器工作状态的叠加情况)对应回每一种电器究竟工作在哪个状态。在此无需进行复杂的分解,而只在前一节处理参数的时候对每一组π进行严格的排序,使得处理后新的π中的每一个元素能与每一种组合情况对应起来。这样只要给定任意时间t的隐藏状态,都可以回溯到各电器在时间t的工作状态及能耗。至此,分解工作已经全部完成。
2 滤波方式的选择
因为在记录电器的功率信号的同时,被记录进的还有因环境、干扰等因素而产生的波动与噪声,这些噪声对于负荷的辨识与分解是没有益处的。因此需要先对波形信号进行一次滤波处理。在此采用了一阶滞后滤波和维纳滤波。
2.1 一阶滞后滤波
一阶滞后滤波采用了将此刻的采样值与前一时刻的输出值加权相加的方式来达到滤波的目的,它适用于消除周期性的噪声,其表达式为
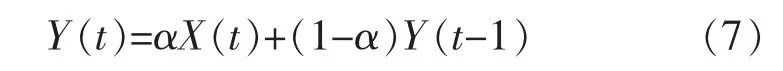
式中:α为加权系数;X(t)为t时刻的采样值;Y(t)为t时刻的输出值。α越小,滤波输出更平稳,但信号灵敏度越低;α越大,信号灵敏度越高,但滤波输出更不平稳。在此设定α=0.3。
2.2 维纳滤波
维纳滤波器是一种线性滤波器,主要用于处理被平稳噪声污染的信号。维纳滤波要求无噪声信号与原始信号之间的均方误差最小,即

维纳滤波器有着直接输出完整波形而非零散参数的优点,另外,无论平稳随机过程是连续或离散、标量或向量,它都能进行处理;在特定的情况下,还易于求出传递函数的显式解,从而使用简单的元器件便能构造出维纳滤波器,为工程应用极大程度地提供了便利。
3 试验算例
3.1 数据集介绍
在试验中使用公开数据集REDD[6]。REDD共有6户数据,每一户数据都记录有测量总功率消耗的总电表和测量用户各个电器功率消耗的分电表。REDD的电气数据主分电表单位不同,主电表采用视在功率,采样频率为1 Hz;分电表则采用有功功率,采样频率<1 Hz。
由于REDD包含有历时较长的主分电表数据,且电气种类囊括了厨房电热类、微波炉、冰箱等常用家庭电器,故方便用于FHMM的训练与分解。同时,也方便用于比较信号滤波前后对负荷分解效果的影响。在实际算例中会统一将采样频率降采样到1/5 Hz。
3.2 训练集与测试集的划分
由于REDD每一户数据所包含的电器种类不尽相同,数据所历时长也不同 (第5户数据点较少),故不可以笼统对所有用户建立一个FHMM模型。为了更全面地评估试验效果,应选取一户建立模型,并且仅挑选这一户耗能最大的5种电器来进行训练。这样,既能涵盖用户日常使用最频繁的电器种类,又能减小参数合成时生成的矩阵规模,从而降低计算的复杂度。由于第1户数据点较多,故对这第1户数据建立模型,电器则选用微波炉、插座、冰箱、洗衣机和电灯。
为了方便起见,统一按历时2∶1的比例来划分模型的测试集,并用之前所有的数据来训练建立FHMM模型。
3.3 试验步骤
基于一阶滞后滤波与维纳滤波的信号处理方式,通过试验对FHMM的辨识效果做出评估。试验步骤如下:
步骤1 划分数据集。将用户数据进行维纳滤波处理,并将功率数据降采样到1/5 Hz。最后,将经过滤波处理与没有经过滤波处理的数据集按历时2∶1的比例,划分出训练集与测试集,用于后续的试验比较。其中,训练集仅包含各分电表的功率数据,测试集仅包含主电表的功率数据。
步骤2 训练FHMM模型。对用户滤波处理前后的训练集进行训练,在每次训练时先对参数赋初值,再使用期望最大化算法迭代至收敛。得到每条因子隐马尔可夫链的参数后,接着将参数进行合成,并将用作下一步骤的分解使用。
步骤3 分解总负荷。按照合成完毕的参数对用户数据建立新的隐马尔可夫模型,输入训练集对应的测试集功率数据,按照维特比算法得到概率最大的隐状态序列。根据步骤2中参数组合的顺序,将每一个合成链的隐状态拆解为单个电器的隐状态。
步骤4 根据事先制定好的评价函数评价各个模型的结果,比较滤波预处理对负荷分解效果的影响。
试验过程流程如图2所示。
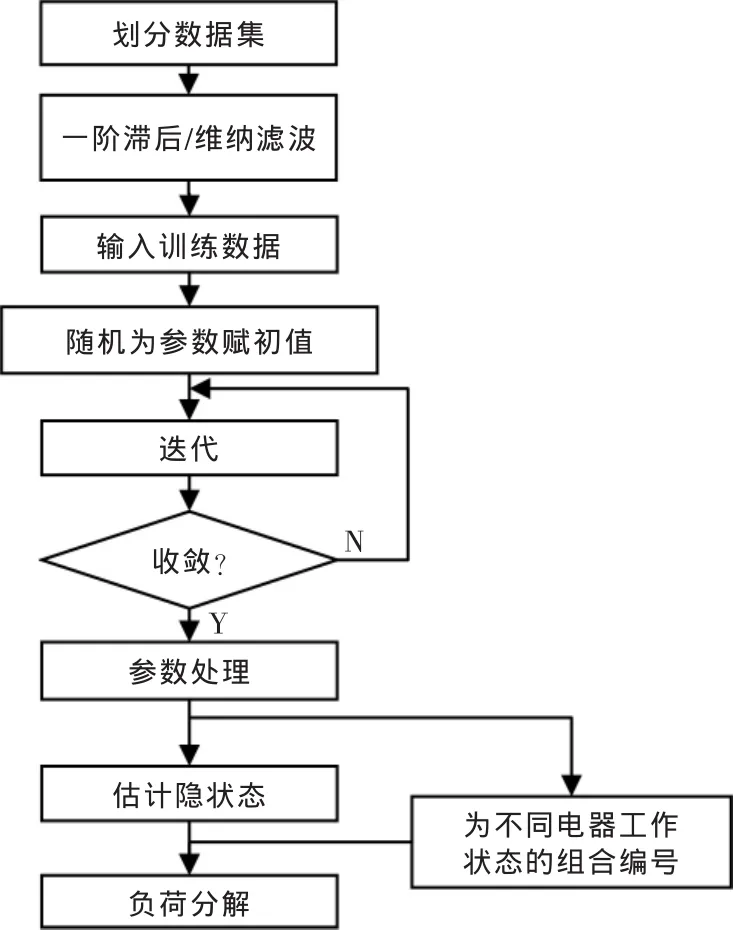
图2 试验流程Fig.2 Flow chart of the experiment
4 结果与分析
4.1 评价指标
对分解出的5种电器的功率序列,与其真实的功率序列进行对比。具体指标为,对比每一个点,判断电器在那一点的工作状态是开启还是关闭,评价指标为
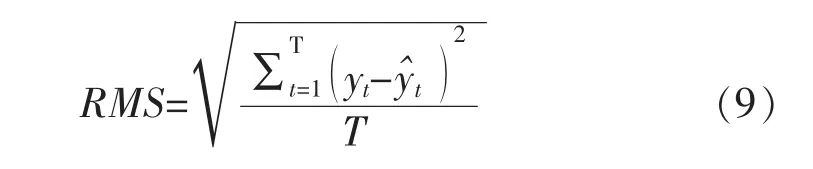
式中:yt为时间t某电器的实际功耗;yˆt为时间t某电器的估计功耗。
TP(true positive)即预测点和真实点都为开启;
TN(true negative)即预测点和真实点都为关闭;
FP(false positive)即预测点为开启而真实点为关闭;
FN(false negative)即预测点为关闭而真实点为开启。
式中:Rrecall为召回率;Rprecision为精确率;F1,score为F1分数。
4.2 试验结果
试验结果见表1~表4。根据表1结果绘制的均方根误差柱形图如图3所示。
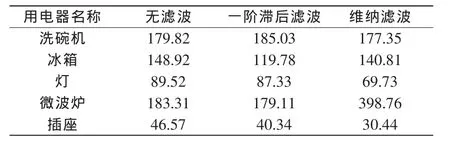
表1 均方根误差结果Tab.1 Results of RMS error
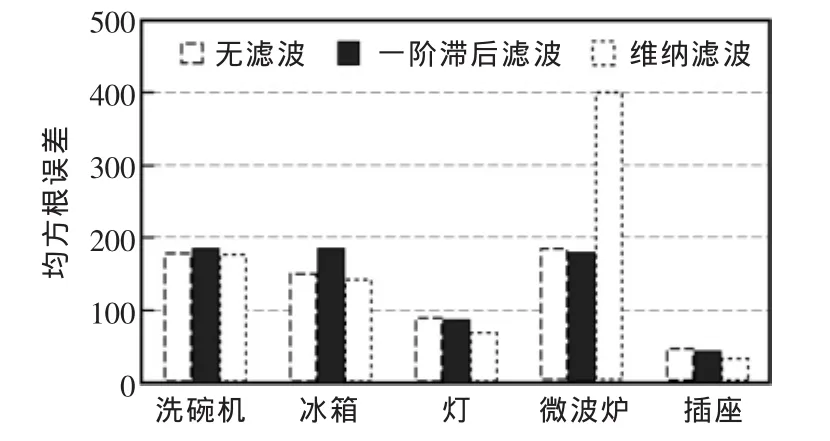
图3 均方根RMS误差Fig.3 RMS error

表2 无预处理的结果Tab.2 Results without signal pre-processing
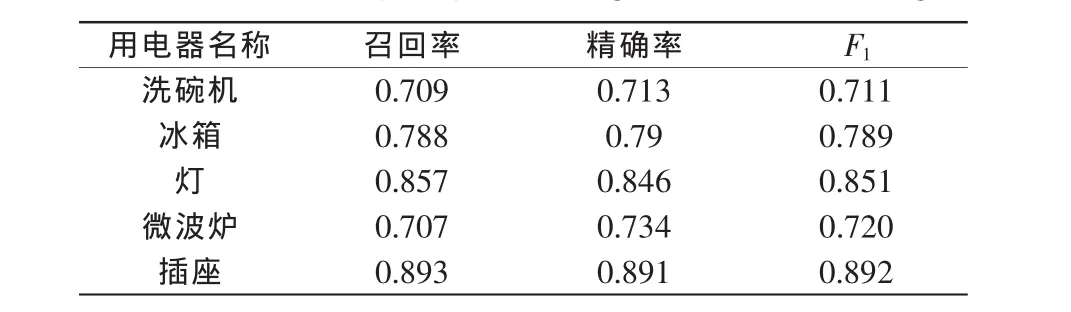
表3 一阶滞后滤波器预处理后的结果Tab.3 Results after pre-processing with first order lag filter
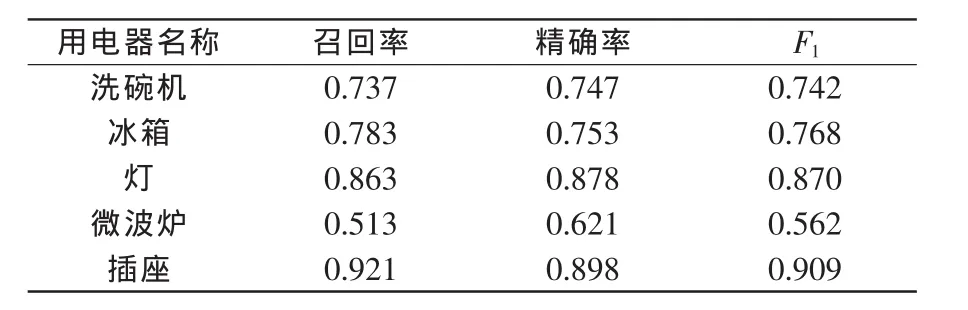
表4 维纳滤波预处理后的结果Tab.4 Results after pre-processing with Wiener filter
可以看出,FHMM模型在波形简单、状态变化单一的电器如电灯上表现得更加优异,但在其它的几种波形复杂、状态变化更加多变的电器上则表现得稍差。这是由于FHMM是基于电器随时间工作状态转变的规律来进行概率分析的模型,而在洗碗机这类工作模式较多、规律较难统计的电器而言则表现得较差。
此外,也可以看出,经过滤波处理过的信号模型更容易处理,在负荷辨识上得到了更高的准确率,而维纳滤波在除冰箱和微波炉以外的电器上比一阶滞后滤波更具有提高准确率的效果。首先,这证明了滤波预处理在非侵入负荷分解的领域上,对电器信号有着正面的效果。其次,在较低的采样频率下,维纳滤波对噪声的平滑处理比一阶滞后滤波对周期噪声的处理更适用于FHMM非侵入式负荷分解。
5 结语
基于因子隐式马尔可夫模型,提出了加入维纳滤波进行信号预处理的改进式模型,旨在用FHMM学习电器状态转移规律进行概率分析的同时,减小信号中因干扰产生的噪声,从而使得模型更易学习到电器的工作特征。根据试验,选取了一户REDD的电器数据,并按照进行滤波与不进行滤波的对比,分别建立模型并评估负荷分解效果。试验结果表明,FHMM对工作状态变化较少的电器分解效果较好,并且滤波对模型的学习能力起到了促进作用,维纳滤波在多数电器上比一阶滞后滤波取得了更好的效果。
