基于Q(λ)-learning的移动机器人路径规划改进探索方法
2019-12-20赵亚川赵忠英张平陆
王 健,赵亚川,赵忠英 ,张平陆
(1.沈阳新松机器人自动化股份有限公司 特种机器人BG,沈阳 110169.2.沈阳科技学院 机械与交通工程系,沈阳 110167)
路径规划是移动机器人导航的重要组成部分,其目标是在复杂环境下能够寻找一条从起点到终点的无碰撞路径。路径规划的优劣直接影响移动机器人的运动效率、机器损耗和工作效率。基于强化学习的智能移动机器人的导航和避障正在成为一个重要的研究方向。与其它机器学习方法不同,增强学习方法无需监督信号,通过智能体与环境之间的信息交互进行“试错”,以极大化评价反馈信号为目标,通过学习得到最优或次优的搜索策略。
目前强化学习已经引起国内外机器学习领域学者的广泛关注。文献[1]所提出的基于奖赏的强化学习方法具有较快的收敛速度;文献[2]深入研究基于BP神经网络的Q-learning,实现移动机器人环境下的自主导航;文献[3]将强化学习方法用于机器人的任务规划和调度;文献[4]以神经网络拟合Q-learning中的Q函数,再用经验回放和目标网络方法改善Q-learning收敛稳定性;文献[5]基于模糊逻辑的路径规划方法,利用状态空间与动作空间映射关系,解决了人工势场法容易陷入局部极小问题。
强化学习在未知环境下求解具有较少先验信息的问题具有巨大优势,是目前机器学习中富有挑战性和广泛应用前景的研究领域之一[6-8]。
在移动机器人路径规划相关应用中,传统的基于Q(λ)-learning探索方法存在由于探索不平衡致使无法找到最优解的问题。故在此通过改进探索方法,提出基于成功率动态调整探索因子的探索方法。
1 基于Q(λ)-learning的改进探索方法
Q-learning 是以状态-动作对应的 Q(s,a)为估计函数,逐渐减小相邻状态间Q值估计的差异达到收敛条件。更新公式为
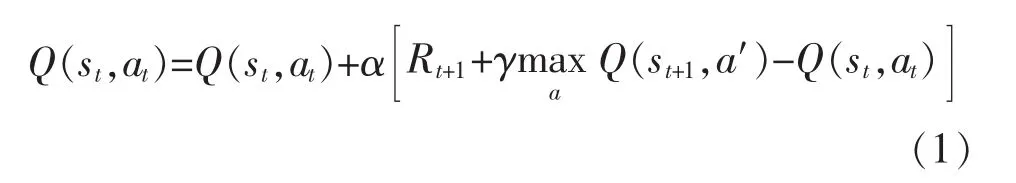
引入迹的思想,其更新公式为

误差项为
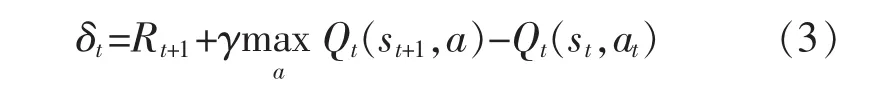
更新动作公式为

解决探索利用平衡问题常用的方法是ε-贪心策略。这种方法探索环境时,随着训练时间的增加而减小探索因子。搜索函数为

式中:σ为0~1之间的随机数;ε为探索因子,为0~1之间的数。传统调整探索因子的方法过多利用环境快速收敛到对应解,但由于探索不够充分,往往很难得到最优解。在此,采用基于成功率的方法动态调整探索因子ε,适时的鼓励探索,使移动机器人对环境探索的更加完全,找到更多解,从而找到最优解。其算法流程如图1所示。
随着训练次数的增加,移动机器人找到目标路径成功率逐渐增加,此时判断路径解数量。当低于最少路径解数量时,增大探索因子,以寻找更多解;当高于最多路径解时,说明移动机器人对环境熟悉程度已经很高,此时逐渐降低探索因子,直至降为0。

图1 动态调整探索因子算法流程Fig.1 Dynamic exploring factor algorithm flow chart
基于Q(λ)-learning的改进探索方法,具体实现步骤如下:
步骤1 初始化,并获取当前状态s;
步骤2 进行第i次迭代计算,最大迭代次数为n,根据图1所示流程更新探索因子ε;
步骤3 生成随机数σ,执行搜索策略π(s),如式(5)所示;
步骤4 执行动作a,得到奖励r,转移到新状态 s′;
步骤5 根据s′是否为目标状态更新成功率Suc,并根据路径解是否为新解,更新路径解数量Path;
步骤6 判断s′是否为终止状态,如果是则跳到步骤2进行下一次迭代(i=i+1),如果不是则跳到步骤7;
步骤7 根据式(3),计算误差;
步骤8 根据式(2),更新动作状态迹,并更新其他动作状态迹;
步骤9 根据式(4),更新动作值函数;
步骤10 s←s′,跳到步骤3搜索下一个状态。
2 仿真试验与结果分析
通过仿真试验来验证改进探索方法的有效性。试验环境采用10×10栅格地图,如图2所示。由图可见,以图左上角为移动机器人起点,右下角为目标,移动机器人无法穿越黑色栅格障碍物。

图2 10×10栅格地图Fig.2 10×10 grid map
移动机器人动作集A包括上移、下移、左移、右移4个动作。状态集用1~100表示,障碍物和目标状态为终止状态。当移动机器人移动到终止状态,本次训练循环结束,重新进行下一次训练。
将本文方法与典型的ε-decreasing探索方法进行仿真对比试验,验证该方法的有效性。ε-decreasing探索方法采用式(6)更新探索因子,即

式中:Vinit为探索因子初始值;i为迭代学习次数;S为步长。
Q(λ)-learning算法中几个重要的参数会直接影响收敛速度。仿真试验中,折扣因子γ初始化为0.8,学习速率α初始化为0.05。在此,探索因子ε初始化为0.5,ε-decreasing方法初始化为1,最大探索步数初始化为100。当搜索步数超过最大步数时,仍未到达终止状态,则认为此次训练失败,重新进入下一次训练。
奖励函数设置:当移动机器人到达目标状态时奖励1,当碰到障碍物得到-1的惩罚,到达其余状态时得到-0.05的惩罚,用于加快向目标状态移动。
ε-decreasing方法收敛曲线如图3所示,约在训练13000次时收敛;基于成功率搜索方法收敛曲线如图4所示,约在训练32000次时收敛。两者收敛时间差别较大,是因为当ε-decreasing搜索方法找到一条最优策略时,有很大的几率不去试探新的最优策略,很快地达到收敛状态,本文方法会根据最优解的搜索情况适当增大探索因子,牺牲收敛时间来寻找更多最优解。

图3 ε-decreasing方法收敛曲线Fig.3 Convergence curve based onε-decreasing search method
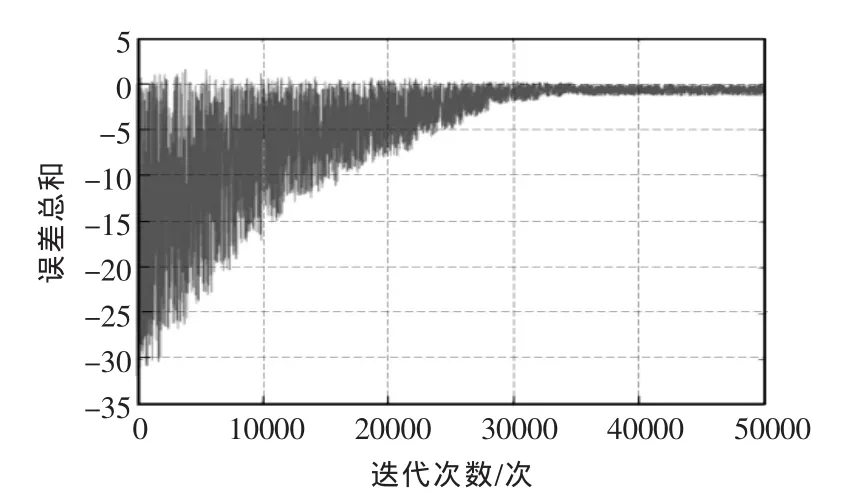
图4 基于成功率搜索方法收敛曲线Fig.4 Convergence curve based on success rate search method
2种搜索方法训练完成的最优策略分别如图5和图6所示。由图5可见,ε-decreasing搜索策略中,一些状态并未得到最优解(阴影表示),以图5中状态83和87为例,最优解应分别为向右和向下,由于训练过程中随着探索因子不断减小,不再进行新的探索,因此并未得到最优解。由图6可见,基于成功率的搜索策略,完全接近于最优策略。
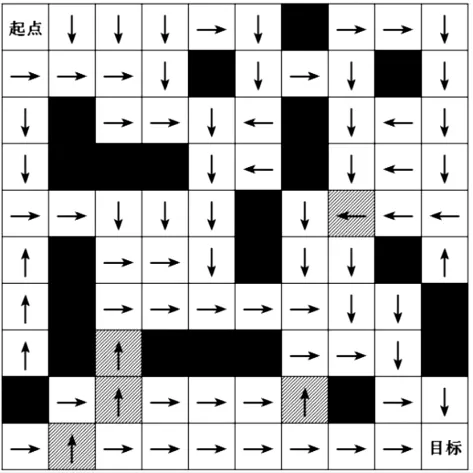
图5 基于ε-decreasing方法收敛策略Fig.5 Search strategy based onε-decreasing method

图6 基于成功率搜索方法收敛策略Fig.6 Search strategy based on success rate search method
统计移动机器人在地图所有状态下到达目标状态的平均步数见表1。其中,2号~5号试验为使用同样的方法,另外生成的4个障碍物分布不同的栅格地图,采用同样的参数完成训练。

表1 平均步数的对比Tab.1 Comparison of average step
移动机器人移动的平均步数越少,说明策略越优。由表1可知,本文搜索策略在4次试验中,平均步数均明显低于ε-decreasing策略。
3 结语
本文提出了一种基于成功率的探索方法,采用Q(λ)-learning算法对移动机器人进行路径规划,引入成功率的改进搜索方法,解决了强化学习中存在的探索利用平衡问题。最后通过仿真实验将改进搜索方法与经典ε-decreasing搜索方法作对比,验证了该方法的有效性。
