基于GA-SVM模型的水上事故严重程度分类
2019-12-17李典张庆年何鑫宇
李典 张庆年 何鑫宇


【摘 要】 為降低水上交通事故发生概率,从人、船、环境及事故属性的角度分析不同因素对事故严重程度的影响,提出基于支持向量机的水上事故严重程度分类模型,利用粗糙集理论对水上事故数据进行约简预处理,最后利用样本数据对基于支持向量机的分类模型进行训练和测试。结果表明,该模型的测试精度达到85%,能较好地识别海事事故严重程度。
【关键词】 水上交通安全;事故严重程度;遗传算法;支持向量机;判别模型
0 引 言
水上交通安全一直是国内外学者研究的重点和热点问题,分析水上交通事故致因可在一定程度上减少水上事故的发生,提高水上安全状态。为保障水上交通安全,国际海事组织(IMO)制定并发布了大量保障船舶安全航行的规章制度及船舶安全操作指导方法。目前,我国对水上交通事故等级的分类主要是由人员伤亡和直接经济损失决定的,大多数研究[1]在分析水上交通事故时将不同等级的事故一概而论,没有考虑水上交通事故间的差异性。因此,研究不同事故等级之间影响因素的差异性对降低事故等级有重要的现实意义。
由于在水上交通实际运行中发生较大事故次数不多,能获取的调查数据较少,为较好地验证水上交通事故等级判别模型的有效性,本文主要研究小事故和一般事故。在现有统计数据基础上,分析水上交通事故的特点,多角度研究事故发生时间、船舶类型及人为因素等,利用粗糙集(RS)理论提取影响水上事故等级的重要特征因素,通过遗传算法(GA)优化支持向量机(SVM)模型中参数c和g,建立GA-SVM基于径向基为核函数的水上交通事故等级分类模型。分析一般事故与小事故发生的差异性,对于规避和减少水上交通事故的发生具有重要意义,可以更好地预防更严重的事故。
1 特征因素的选择和量化
1.1 事故等级判别特征因素的选择
《水上交通事故统计办法》将水上事故划分为特别重大事故、重大事故、较大事故、一般事故、小事故等5个等级,属于事后划分方式。
在分析水上交通事故等级的影响因素时,鉴于水上交通安全范围广泛、水况复杂,关键性特征因素选取的合理性直接影响到分类模型的准确性。基于水上交通历史事故调查报告和实地调研,结合专家学者先前的研究,船舶发生交通事故的主要原因如下:
(1)船舶值班人员疏于瞭望,操纵人员避让行为不协调、操纵不当等。
(2)船舶积载不当致船舶稳性不足,电器电线老化造成短路,航行过程中船舶出现主机故障、舵机失灵等现象。
(3)通航条件不佳,如恶劣的天气状况、航线经过水上水下施工区等。
(4)航运企业管理不当、船舶违规使用明火、垃圾未及时处理等。
由于不同的航运企业管理涉岸人员情况和规章制度各不相同,因此,本文从人、船、环境和事故属性等4个方面分析影响水上交通事故水平的特征因素。结合以上分析,按照科学、系统和易于量化的原则,选取人的身心状态、实践操作能力、是否操作违规、是否操作错误,以及船型、船舶总吨、天气状况、能见度、风级、事故类型、事故发生时间段、事故发生所属季节、人员伤亡及直接经济损失等14个特征因素作为事故等级分类的条件属性。
1.2 特征因素的量化约简
为避免因特征因素的可替代性造成结论的不准确,采用RS理论对各特征因素进行约简处理,使各个特征因素彼此独立,以确保结论的客观性和准确性。
在使用RS理论对水上交通事故等级特征因素进行筛选前,首先需要确定信息系统和决策表,两者之间存在映射关系。决策表在RS中起着重要作用,表达式为
S=(U, A,V, f)
式中:U为对象的非空有限集合,即论域;A为属性的非空有限集合,通常分为条件属性集C(即影响水上事故水平的所有特征因素)、决策属性集D(即两种不同类型的事故);V为属性值的集合; f 为一个信息函数。
在实际中,同属一个信息系统中的特征因素对决策集的影响是不同的,RS理论的约简是剔除条件属性集对决策属性集的影响为零的特征因素,即权重为零,从而达到约简的目的。
2 SVM判别模型的构建
为得到较为理想的事故等级判别模型,本文选取径向基(RBF)核函数,利用GA算法对SVM模型中的惩罚参数c和核函数参数g进行优化处理。基于GA-SVM的水上交通事故等级判别模型的构建步骤如下:
(1)选取利用RS理论约简后的指标数据,将数据集分为80%的训练样本、20%的测试样本,标签小事故为“ 1”、一般事故为“1”。
(2)利用GA算法优化参数c和g。
(3)确定参数c和g最佳值,并在SVM中训练样本。
(4)预测SVM模型中的测试集并评估SVM模型的分类性能。
传统的SVM模型虽然能较好地解决高维及非线性问题,但模型的准确性还依赖于参数c和g。因此,为了得到更高的模型准确度,本文选用GA算法对SVM模型中的参数进行寻优处理。
3 模型验证
3.1 数据的获取
本文通过查询和下载长江水域范围内各海事局官方网站上公布的统计数据,查阅各类水上交通事故分析报告,其中收集到2014―2018年发生在长江区域水上交通事故352起。由于本文主要关注小事故、一般事故,剔除了较大、重大及特别重大事故数据,基于数据的完整性和有效性筛选出200组长江水上交通事故数据进行量化约简处理。
3.2 影响水上事故指标的量化约简
Rosetta软件是一款基于RS理论对数据表格进行分析的软件,其具备常见的数据离散化处理、数据补全及属性约简等功能。影响水上交通事故严重程度的各特征因素之间存在关联性,因此,本文应用Rosetta软件对各特征因素之间进行数据挖掘及分析研究。
本文结合专家意见和问卷调查来量化所使用的特征因素。以环境因素中能见度为例:当能见度在7级及以上时,这一特征因素并不影响船舶安全航行;当能见度低于3级时,船舶的安全航行将受到严重影响。因此,本文将能见度分为4个量级进行量化,即:能见度大于等于7级,赋值1;能见度为5~6级,赋值2;能见度为3~4级,赋值3;能见度为0~2级,赋值4。
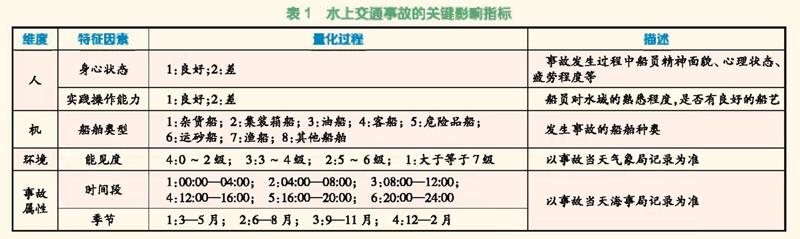
以上量化处理后得到的200组事故数据作为Rosetta软件处理的基本数据,其中将影响水上交通事故等级的16个指标作为条件属性,决策属性为事故等级,利用频率划分算法对数据进行离散化以生成决策表。最后利用贪婪算法(Johnson's algorithm)得到指标约简结果。结果表明,人的身心状态、实践操作能力、船型、能见度、事故发生时间段和季节可作为影响水上交通事故水平的6个重要指标。具体见表1。
3.3 水上事故等级识别模型的建立
本文选取采用RS约简后的6个指标,构成新的包含200组样本的数据集,将数据分为160组的训练集和40组的测试集。事故等级作为标签,小事故和一般事故分别用“ 1”、“1”表示。使用Libsvm工具在MATLAB环境下实现SVM训练模型,并选择RBF作为SVM模型中的核函数,即参数选择“ t=2”。对数据进行预处理,并将训练集和测试集标准化到[0,1]范围,运用Mapminmax函数来标准化训练集和测试集数据,选取参数c、g的值。本文将gaSVMcgForClass.m用于优化参数c、g,GA算法中各参数设置如下:最大的遗传代数为50,种群数量为20,参数c、g的值在[0,100]之间,代沟取值0.9。由GA-SVM适应度曲线(见图1)可以看出,随着迭代次数的增加,平均适应度仍在不断变化,处于跌宕起伏的状态,在第31~41次迭代过程中,其平均适应度曲线处于较为平缓的状态。优化结果为最佳惩罚参数c=2.280 9,最佳核函数参数g=56.955。
根据寻优后的参数结果,利用Svmtrain建立SVM网络训练模型,代入通过GA算法寻优后的参数值,得出模型准确率为85%。引入Sigmoid函数对分类结果进行概率运算,测试集中部分概率输出值(见表2)如下:在包含40组数据的测试集中,有6组被误判,其中,有4组一般事故被误判为小事故,2组小事故被误判为一般事故。这表明通过GA算法参数寻优后得到的SVM分类模型可以有效地判别事故等级为一般事故还是小事故。
为了更好地证明GA-SVM模型分类性能,本文选取交叉验证理论中K-fold Cross Validation(K-CV)方法与遗传算法作对比,K-CV可以有效地避免过学习以及欠学习状态的发生。基于本文样本数较少,选择K=3,将原始数据均分成3组,每个子集数据分别作为一次验证集,其余的2组子集数据作为训练集,依次训练,最终验证集的分类准确率的平均数作为此3-CV下分类器的性能指标。
在MATLAB环境下,利用3-CV-SVM对参数进行优化,定义参数c、g取值范围在[2 5,25],最优惩罚参数c=2,最优核函数参数g=32,CVaccuracy=90.625%,代入SVM网络训练模型,预测精度为80%。通过对比两种优化方法(见表3)可知,GA-SVM模型分类精度更高,准确率更高。
4 结果讨论
(1)通过RS理论筛选出的6个特征指标,即身心状态、实际操作能力、船舶类型、能见度、事故发生时间段及季节,可以更好地反映水上交通事故水平。
(2)引入Sigmoid函数进行概率计算,通过调整6个特征指标的不同状态可输出不同的事故水平,由此为降低事故严重程度提供了参考方向。
(3)基于GA-SVM的水上交通事故嚴重程度判别模型,准确度达到85%,能较好地判别水上交通事故水平。
(4)通过与CV-SVM模型的对比,GA算法寻优后得到的模型准确度高于CV方法寻优后的模型准确度。
(5)根据海事局对事故等级的定义,小事故和一般事故的最大区别在于有无人员伤亡,属于事故发生后的定义。通过本文建立的水上交通事故严重程度判别模型,能根据易引发事故的特征因素状态有效判别出事故严重程度,从而更好地形成预警方案,尽可能地降低事故危害性。
参考文献:
[1] 雷海.“东方之星”轮沉没事故对水上客运安全的警示[J].水运管理,2015(10):1-3.
