基于图像伺服控制的TLD算法
2019-12-11王光庭
刘 豪,曹 凯,王光庭
(山东理工大学 交通与车辆工程学院,山东 淄博 255049)
目标跟踪一直是计算机视觉研究的热点。虽然目标跟踪已经有成功案例,但对特征点不明显的目标进行跟踪仍然非常具有挑战性[1]。
许多跟踪方法采用静态模型,即手动定义跟踪目标,对第1帧图像进行训练[2]。但这些方法往往会因目标表面出现重大变化而出现跟踪困难的现象,如何降低干扰是目标跟踪成功的关键[3]。
随着计算机技术的发展,目标跟踪技术也获得了软硬件上的支撑,并伴随着获得了巨大的发展。其中,TLD算法是由英国萨里大学的捷克籍博士生Zdenek Kalal,在其攻读博士学位期间提出的一种新的单目标、长时间跟踪算法[4],该算法虽然实现了对目标的跟踪,但运行速度较慢,甚至会出现卡顿现象,并且受光照变化影响比较大,抗干扰能力较差。国内学者也对TLD算法做了一定研究。龚小彪[5]在TLD算法的基础上提出了基于卡尔曼滤波等三种抗遮挡的算法;吴忠文等[6]提出了根据图像的大小进行动态扫描的方法;谷文华等[7]将粒子滤波算法与TLD算法结合,实现目标的跟踪。虽然以上学者对TLD算法进行了一定改进,但算法的实时性与鲁棒性整体不太理想,并且运算速度也比较慢。本文采用基于图像视觉伺服的方法来控制在目标跟踪过程中出现的误差累积,以试图将误差控制在理想范围内。
1 TLD算法
1.1 TLD架构
TLD(Tracking Learning Detection)是一种新型且高效的跟踪架构,该架构分为三个部分:跟踪器,学习器和检测器。框架如图1所示。此架构的应用前提是设定的目标物必须是可见的。跟踪器计算出连续的视频帧之间目标发生的运动,检测器把视频分解成一帧帧的图像,扫描图像全局得到图像的特征,在扫描的过程中,无论是正样本还是负样本都会不可抗拒地出现错误信息,而学习器则根据跟踪器和检测器出现的错误信息进行不断地自我修正,囊括更多的目标特征,并产生更多的背景信息[8]。
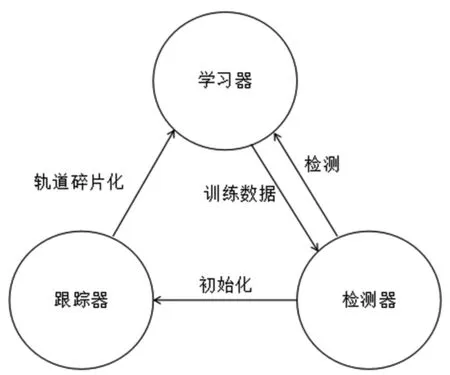
图1 TLD结构框架Fig.1 the block diagram of the TLD framework
1.2 P-N学习机制
P-N学习(P-N learning)作为一种半监督在线学习的机制,能够有效提高外观模型的的整体性能,评估当前检测器,指出其错误并进行及时修正,以保证实时跟踪的有效性。这一过程的实现主要是把检测器的错误用两种类型的约束进行标记,用正约束标记错误的负样本,用负约束标记错误的正样本[9]。
本节讨论的P-N学习方法如图2所示。P-N学习首先从标记的数据中训练出一个分类器,这个分类器的作用是将数据进行迭代处理:(i)通过分类器标记未标记的数据,(ii)识别并重新标记违反了结构约束的样本,(iii)拓展训练集合,(iv)分类器再训练。设x是特征空间X的一个实例,y是标签空间Y={-1,1}的一个标签,实例X和标签Y组成标签集合,用(X,Y)表示。P-N学习的任务是学习一个分类器f:x→y是来自先验标记集合(Xl,Yl),并且,未标记的数据Xu引导其表现。
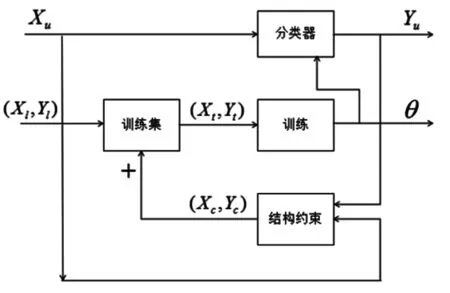
图2 P-N学习方法Fig.2 The illustration of the P-N learning approach
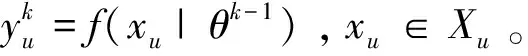
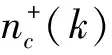
(2)
1.3 P-N学习模型
P-N学习模型由P结束和N约束构成,评价约束质量的4个指标如下:
(1)P+,P约束的精度,其值为正确的正样本数除以P约束的样本总数,即
(3)
(2)R+,P约束的查全率,其值为正确的正样本数除以错误的负样本数,即
(4)
(3)P-,N约束的精度,其值为正确的负样本数除以N约束的样本总数,即
(5)
(4)R-,N约束的查全率,其值为正确的负样本数除以错误正样本数,即
(6)
在这里假设约束在整个训练过程中都是固定的,因此时间指数从标记中被去掉了。在k次迭代中,正确和错误的样本的数量被表达如下:
(7)
(8)
(9)
(10)
将式(1)、式(2)与式(7)-(10)合并,得到:
(11)
(12)
(13)
(14)
最终将方程转化为
(15)
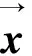
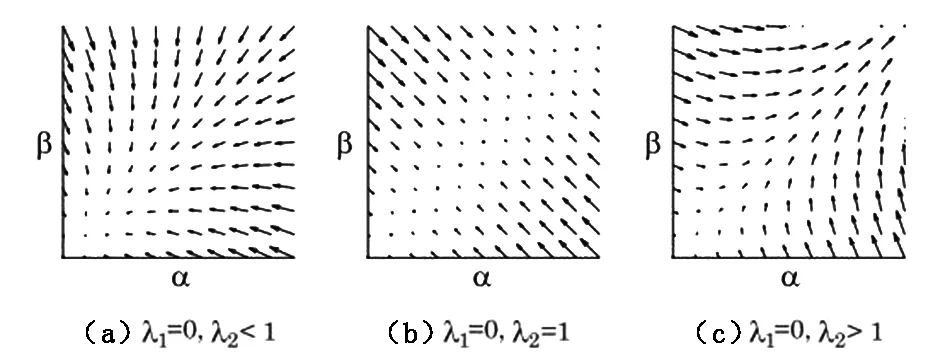
图3 矩阵M的特征值λ影响分类器错误演变的示意图Fig.3 The diagram of how eigenvalue λ of matrix M affects the error evolution of classifier
矩阵M表示分类器错误二维空间的一个线性变换,特征值可以理解为沿着特征向量收放的比例系数。如果比例小于1,那么每次迭代中都会减少错误。在实际过程中,也并不可能识别分类器的所有错误,因此,训练结果不收敛于无误差分类器,但仍可以保持一个稳定的水平,即将不完美的约束进行组合,仍然可以将错误取消。P-N学习不对任何约束有要求,即便约束条件的精度很低也能使用,只要矩阵M的特征值小于1。
2 图像伺服控制
2.1 视觉系统
如表1所示,相机模型大体可分为针孔模型、球面模型和统一化模型[10]。
视觉伺服中的视觉反馈按照反馈方法总体上可分为三类:图像特征的视觉反馈、基于位置的图像反馈和多视图几何方法的视觉反馈。 其中, 基于图像特征的视觉反馈方法提取图像的特征点,这些特征点包括了点、线、面等多种视觉特征,并以这些特征为依据进行识别追踪;基于位置的视觉反馈方法将视觉系统的动态模型转化为目标识别和定位, 即通过定位来寻求目标位置,从而简化了整个系统控制器的设计,对目标追踪的应用相对简便,但是一般需要已知目标物的模型, 且对图像噪声和相机标定误差较为敏感;多视图几何的方法将多张二维的图像还原出三维的实际物体,即一个三维重建的过程。整体来说,基于图像特征的方法稳定性更高,目标识别和跟踪主要采用此方法[11]。
表1 相机模型
Tab.1 Camera models

模型应用范围优点缺点针孔模型透视相机简便、畸变小范围小球面模型全景相机视野广、旋转不变畸变大、模型复杂统一化模型各种相机旋转不变、归一化畸变大、模型复杂
2.2 控制系统
在图像视觉伺服系统中,控制系统的最终目的就是控制误差,求得最小误差e(t),e(t)=s[m(t),a]-s*。基于图像的控制方案一般都采用图像平面的一组点构成视觉特征集合s。图像测量m通常是图像点集合的像素坐标,而且相机固有参数a就是用于把像素的图像测量变换到特征点。
在相机里一个三维的坐标点表示为X=(X,Y,Z),转化为图片一个二维的坐标点表示为x=(x,y),由此可以得到
(16)
m=(u,v)是用像素单位表示的图像点的坐标,a=(u0,v0,px,py)是相机固有参数的集合,u0和v0是主要特征点坐标,px和py是焦距和像素大小的比值。摄像机的空间速度为vc=(vc,ωc),vc是像机原点的瞬时线速度,ωc像机原点的瞬时角速度。由此,特征集合s以及空间速度的关系为
其中矩阵Lx为
(17)
当目标选定之后,基于伺服控制的TLD算法经过以下步骤:
(1)设置当前目标,选定初始帧为i=0;
(2)TLD算法对该帧图片提取特征点,进行计算;
(3)摄像头通过TLD的计算对目标进行跟踪;
(4)IBVS对图像进行误差控制,并将误差反馈给TLD;
(5)跟踪是否成功,如果成功,当前帧替换上一帧图片作为新的跟踪目标,i=i+1;如果不成功则重新选定目标。
该步骤如图4所示。

图4 目标跟踪示意图Fig.4 Target tracking schematic diagram
3 实验
3.1 实验结果
在TLD算法的基础上,加入图像视觉伺服控制以减小误差,用实验来认证跟踪是否有效,并评估其跟踪的鲁棒性,在不同的环境下,设置不同的干扰因素来多次试验,这包含了对不同目标(人,物体等)的跟踪,不同干扰因素(遮挡,光照等)条件下的试验,试验部分如图5—图8所示。
(a)追踪前 (b)初始追踪 (c)5 min后追踪图5 人脸跟踪Fig.5 Face tracking

(a)追踪前 (b)初始追踪 (c)5 min后追踪图6 二维码跟踪Fig.6 QR code tracking

(a)追踪前 (b)初始追踪 (c)5 min后追踪图7 钱包跟踪Fig.7 The wallet tracking

(a)追踪前 (b)初始追踪 (c)5 min后追踪图8 人脸跟踪Fig.8 Face tracking
实验由4组实验样本组成,分别展示了对人脸、二维码、钱包的追踪,每一组实验截取了(a),(b),(c)三张图,(a)表示了对目标追踪前实验系统的成像状态,(b)表示的是选取目标后进行的初始追踪状态,(c)表示的是进行5 min之后的追踪状态。
从实验结果来看,所采用的方法对人脸的追踪效果最理想,几乎可以完美地对目标进行长时间跟踪,即便在中间过程中使用遮挡物遮挡,或是目标离开摄像头一段时间,而当目标再次回归到可视窗口时仍能进行继续的跟踪;对二维码的追踪效果同样是有效的,并且追踪的鲁棒性较高;而当对作者使用的钱包进行追踪时,其追踪的表现性较差,当目标物振动剧烈时,偶尔存在跟踪丢失现象,并且重现追踪会有较长的反应时间。
对于前两个目标,从目标本身来讲具有较明显的特征,所设计的系统对于特征点的提取较为容易。而对于钱包来讲,由于整个二维表面特征点不够突出,与背景区别相比较于前两个较小,所以其追踪效果不理想也在预料之中。其中,图5与图8的试验对比中,图5光照条件理想,背景与目标区别显著,图8光照条件较为昏暗,但两者依然追踪效果理想,所以本系统在对特征点较为明显的目标进行追踪时,几乎可以不受光照限制。
3.2 实验对比
本文从样本数量、运算速度和正确率三个方面与原始算法对比,结果如下。
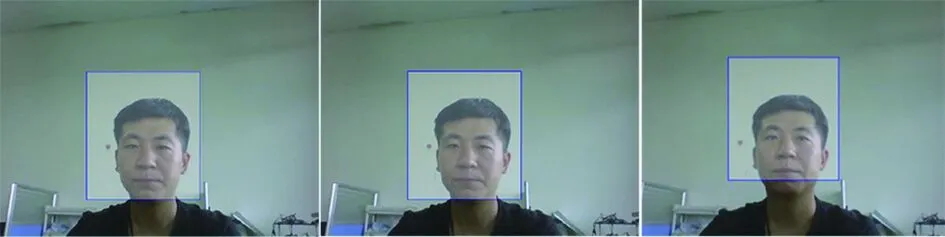
图9 输入样本数量对比图Fig.9 Comparison chart of input sample size
如图9所示,虚线表示的是原始的TLD算法在目标跟踪中产生的样本数量,实线是改进后产生的样本数量。改进后的样本数量由于伺服控制的反馈降低了TLD算法本身的计算量,从而加快了算法的运行速度,进而也保证跟踪的实时性。
表2 原始算法与改进后算法运算速度对比
Tab.2 The speed comparison between original and improved algorithms

视频库总帧数原始算法运算速度/帧· s-1改进后算法运算速度/帧· s-1人脸二维码钱包153315011486252421413935
表2中表示的是原始TLD算法与改进后的算法运算速度的比较,人脸与二维码的特征点相对于钱包较为明显,所以其运算速度较快。
表3 原始算法与改进后算法正确率对比
Tab.3 The accuracy comparison between original algorithm and improved algorithm
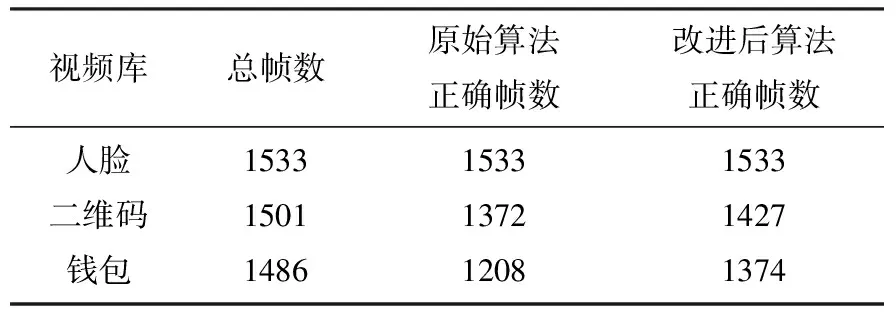
视频库总帧数原始算法正确帧数改进后算法正确帧数人脸二维码钱包153315011486153313721208153314271374
表3表示了算法改进前后对目标跟踪准确率的对比,改进后的算法在准确率上也有提高。
4 结束语
本文将图像视觉伺服控制应用到TLD算法中,从整体实验效果来看,基于图像视觉伺服的TLD算法目标追踪应用广泛,对于特征点明显的目标追踪效果显著,对光照因素要求不高,但是在对特征点不明显,与背景对比差异较小的目标追踪时,效果不够理想,但也能基本完成对目标的追踪。同时,改进后的算法在运算速度以及正确率上都有所提高。但该方法仍具有不足之处,如何更好地提取特征点,如何将特征集合的误差控制到更小,这都将是作者后续工作中要解决的问题。
