基于Solr的农田数据索引方法与大数据平台构建
2019-12-06苑严伟冀福华姜含露樊学谦
苑严伟 冀福华 赵 博 姜含露 王 猛 樊学谦
(中国农业机械化科学研究院土壤植物机器系统技术国家重点实验室, 北京 100083)
0 引言
农田是农业生产的载体[1-4],我国农田呈现数量多、田块小、形态各异、信息多样化等特点,农田信息的多元异构、海量等特性已成为现代农业信息化发展的难题,为提高我国农业数字化与信息化程度,有必要构建面向精准农业的农田大数据平台,以实时、动态、高效地管理农田信息。
随着物联网、云计算、大数据等信息技术的发展,农田数字化已成为现代农业发展的主要方向之一。国外关于农田数据的研究较早,到目前为止,国外已有成熟的农田信息管理系统[5-7],如:美国凯斯公司的AFS系统、约翰迪尔公司的GreenStar系统以及AgLeader的PF(Precision Farming), 这些都是相对规范且成熟的农田数据模型。另外,国外研发了与农田数据相关的智能农业决策系统,如Farmeron公司[8]在2011 年推出了基于Web 端的农场管理平台,提供相对可靠的生产分析报告,以指导农民进行生产规划;VitalFields公司[9]以气象预测、病虫害、成本投入为研究对象,提供农作物种植阶段的相关服务,使得管理农场更加高效;2017年OneSoil公司[10]通过欧洲空间局的卫星影像和Mapbox的数据,利用人工智能的算法,推出了包括欧洲和美国超过5 700万块农田的交互式数字地图,用于自动检测地块、识别作物类型和监测作物发育。国外的地块大多为标准农场,而且在作物生产管理的方法和习惯方面与国内存在较大差异,国外的农田田块数据模型不适合我国复杂农情与多元经营模式。因此,国内仍需开发符合我国国情的农田数据模型与大数据平台。
国内关于农田数据的理论研究起步较晚。近年来,在国家十三五规划的带动下,与农田数据相关的技术发展较快,主要表现为多平台、多用途、多方法面向个性化的农田信息存储技术研究与实现。文献[11]利用1957—2007年河南省30个县、市的气象、土壤、作物等数据信息,构建了基于元数据的农田信息的存储、管理和共享模型;文献[12]以土地所有者、种植管理者、施肥管理、杀虫喷药等信息作为属性信息,构建了基于图的农田数据模型;文献[13]以土壤信息、环境信息、田间信息、GPS定位信息等作为属性信息,构建了基于GDAL的农田信息数据模型;文献[14]以河南省巩义市吴沟村为例, 以卫星遥感图像为建库数字化参照依据, 采用目视解译方法, 利用ERDAS Imagine 8.6和MapInfo Professional 7.0 SCP为数据库平台,依次提取旱地梯田、旱坡地、菜地、退耕还林地等不同田块图层,设计了基于RS、GIS的村域农田数据库。文献[15]以无线传感器采集平台的空气温湿度、风速、风向、光照为依据,建立了基于无线传感网的农田数据管理系统。国内研究大都基于传统的数据模型进行数据的储存和查询[16]。而随着数据量的增大,大数据的海量、非结构化的特性导致了传统数据库难以满足大数据的存储与高并发的访问需求,海量异构农田数据多样性、庞杂导致信息无法有效重构,农田田块大数据处理过程中易产生云端运算负担大、响应时间慢等问题。另外,传统的数据单机处理模式很难提供相对高效的计算资源整合,导致大量的硬件资源浪费。
针对上述问题,本文在前期农机深松监测系统的基础上,对农田数据在解析、存储与处理过程中的技术细节进行研究,建立基于Hadoop的农田大数据平台,对农田田块在作物的耕、种、管、收等过程中产生的海量农田数据进行动态管理。
1 大数据平台的设计与构建
1.1 系统总体架构
基于Hadoop的农田大数据平台可用于分布在全国各地的农业合作社农田田块信息管理。该平台将大数据、物联网、WebGIS等技术进行深度融合,向用户提供农田田块数据的快速检索、处理和动态展示。其总体架构如图1所示,主要包括感知层、网络层、中间层和应用层。

图1 系统总体架构Fig.1 Overall architecture of system
1.2 系统功能设计
基于Hadoop的农田大数据平台的功能设计如图2所示,主要包括角色管理、地块管理、设备管理、农资管理、作业管理、统计管理,其主要面向对象为各种用户。

图2 系统功能设计Fig.2 Function module of system
(1)角色管理
平台的用户主要分为管理员和普通用户两种类型,不同类型的用户会分配不同的使用权限,如政府机关具备所管辖合作社的浏览权限、任务分配权限等;合作社具备本合作社业务的日常维护权限。另外为了便于系统的维护,设置了管理员角色作为最高权限。
(2)地块管理
地块管理是整个大数据平台最重要的环节,它负责管理地块的位置信息、作业信息、气象信息、附着物信息,为地块的精细化管理提供了丰富的数据支持,具备地块信息的录入与检索,并通过WebGIS技术,将部分数据可视化。
(3)设备管理
设备管理主要有两个作用:获取田块信息和进行田块作业。设备管理的内容主要为设备的基本信息、工作详情。其中包括录入设备基本信息和设备工作详情,设备工作详情主要指用户在客户端可实时查询设备的位置及机手信息,其中设备位置信息可调用天地图API实时获取。
(4)作业管理
作业管理主要包括作业类型、作业详情、作业记录、作业时间4部分。其中作业类型为农机作业的基本类型,如:深松、打捆、籽粒直收、植保等;作业详情为实时展示作业现场并抓拍作业场景;作业完成情况是指作业轨迹、作业的完成率,已作业面积;作业记录是指作业的历史信息,这些信息包括作业轨迹、作业面积、机手信息、作业时间、作业时随机抓拍的图像。
(5)农资管理
农资管理是对地块的使用资源(化肥、农药等)的统一整合,可对地块的农资使用情况提供较为详尽的记录。另外,可记录地块的产出数据,这些数据都能为农作物科学管理及分析决策提供数据源支持。
(6)统计管理
统计管理是在农资管理、设备管理、地块管理的基础上,对农田数据进行深层次的加工,比如:统计造成不同地块产量差异性的原因,探究农机作业、农资使用与农作物产量之间关系。
2 农田数据关键技术设计
2.1 数据结构
本文以农田田块为研究对象进行农田数据的分析,农田田块数据包括田块的位置信息、气象信息、作业信息及附着物信息等。位置信息包含田块经度、纬度、海拔及坡度等地理信息,气象信息包括历年的温度、湿度、光照、风速、风向等;作业信息主要是不同农业机械的历年与实时作业信息,如深松机作业深度、播种机播种施肥量、植保机喷药量、收获机产量分布信息等;附着物信息是指对农业生产影响较大的信息,如水井、电线杆、农舍的经纬度和局部轮廓等。数据结构如图3所示。由于数据量大,为了便于检索和存储,现有的农田田块大数据平台将数据进行分表保存处理。

图3 农田数据结构Fig.3 Data structure of farmland
2.2 数据库选取与部署
农田田块数据类型复杂,不仅有常见的结构化数据,而且还有半结构化数据。 HBase[17]作为高性能、列存储、可伸缩、实时读写的分布式数据库,可支持集群存储海量数据。目前由于对农田数据的存储多选用传统的数据库,如Mysql、PostgreSql等,这些数据库在解决事务性问题上有其独特的优势,然而随着数据量的增加,数据存储的因素主要从数据检索性能来考量。
数据库Hbase的检索过程如下:
(1)客户端从ZooKeeper找到存放在Master上的Region服务器的位置信息、Region的元数据信息以及Region与Region服务器的映射关系。
(2)通过Region服务器检索存储在Region的数据。
(3)通过HDFS(Hadoop distributed files system)读取存储在磁盘上的数据。
Hbase[18]的部署服从主从原则,依附于Hadoop集群。本文部署的Hbase的所有协调工作均由ZooKeeper来执行,来实现HMater的选举与主备的切换、系统容错、任务管理。而且Hbase与ZooKeeper为独立部署,这样可避免二者发生强耦合,便于后期集群的升级与维护,由于ZooKeeper具备轻量化的特性,部署的ZooKeeper仍构建于HDFS之上,此外,它还提供了整个大数据集群的负载均衡。
2.3 行键
Hbase表主要由行键(Rowkey)、列族、列限定符和时间戳等组成。行键是其主键,在满足行键设计长度原则、散列原则、唯一原则的前提下,为提高数据对内存的使用率,对于64位操作系统的行键设计应为8字节的倍数,本设计中选择16字节行键设计。将行键的高位作为散列字段,低位作为时间值,可以使得数据相对均衡地分布在Region服务器中。由于Hbase的行键按字典顺序增加,为了避免写热点,设计Rowkey需使不同行的数据放在同一个Region中,如果没有散列字段,直接存放时间值将可能产生所有新数据都在一个Region服务器上堆积的热点现象,导致数据检索时负载将会集中在个别Region服务器,降低查询效率。在农田大数据平台中,由于地块编号、设备号、作业人及作业时间等字段使用较为频繁,所以在设计行键时包含了上述信息。同时,由于地块编号采用字母+数字的格式,将地块编号写入开端可以避免写入数据时行键的顺序递增的问题。因此,本系统行键设计为:Rowkey=“地块编号+归属人+作业人+时间”。
2.4 列族
农田田块数据主要字段包括:地块编号、地块位置、地块面积、地块归属人、地块管理人、作业类型、设备号、车牌号、作业时间、温度、湿度、光照强度、风速等128个字段。对于作业时间要求精确到分钟,采用8位占位符进行存储。对于位置信息采用独立的几何属性列族存储;其他字符均采用字符型。各字段长度不一,由于列族少时,底层的I/O开销就会降低,因此所有非几何字段构成一个唯一的列族,其具体设计如表1所示。

表1 农田数据表结构Tab.1 Structure of land data
2.5 基于Solr二级非主键索引的设计
Solr[19]是Apache基金会下的一款基于Lucene的全文搜索服务器。用户可通过Http协议获得该系统对外提供的类似于java-web的API,并向该系统提交生成索引的XML文件,最后可通过Get请求获取索引结果。另外,Solr的搜索引擎采用Java5开发,而本文的大数据平台也采用了Java开发,可以使得大数据平台很好地兼容Solr。因此,本文选取了Solr进行系统二级索引。
根据表1添加了4个索引字段,分别为:地块类型(landType)、地块面积(landArea)、地块产量(landOutput)和地块作业类型(workType)。其配置信息中name表示字段名;type表示定义的字段的属性,一般情况下integer字段的索引效果更好;indexed表示是否索引,作为索引字段必需设置为true;stored表示是否被存储,为了改进性能,对于不需要作为结果存储的均设为false;multiValued表示是否包含多个值,对于可能存在多值的字段全部设为true,从而避免构建索引时报错,索引字段的类型与配置信息具体如下
〈fields〉
〈field name = "Rowkey" type = "string" indexed = "true" stored = "true" multiValued = "false" / 〉
〈field name = "landType" type = "integer" indexed = "true" stored = "false" multiValued = "false" /〉
〈field name = "landArea" type = "string" indexed = "true" stored = "false" multiValued = "false" /〉
〈field name = "landOutput" type = "integer" indexed = "true" stored = "false" multiValued = "false" / 〉
〈field name = "workType" type = "string" indexed ="true" stored = "false" multiValued = "false" /〉
〈/fields〉
构建二级非主键索引后,数据传输过程为:采集到的农田数据分别存储在采集终端和大数据集群服务器上。采集终端可以存储近期内一部分数据,主要是为防止采集终端野外作业时由于信号丢失等引起短时间内数据无法正常传输到服务器端的问题。采集终端采集到的数据(生产者)会通过kafka将数据打包发送到数据中心(消费者),数据中心解析之后存储在构建于HDFS之上的Hbase数据库中。系统的元数据信息存储在Master结点的内存中,元数据信息主要包括维护文件系统的FsImage和记录操作日志的EditLog。当客户端发出数据请求时,数据处理相关模块首先判断是否存在主键索引,若存在则直接通过Hbase的主键索引检索数据,若检索条件涉及二级非主键索引字段,则通过多条件查询到相关主键值,最后通过主键在Hbase里进行检索。该索引模块设计在一定程度上可提高检索速度。
3 实验结果分析
3.1 集群部署
系统部署在阿里云服务器,软件环境为:Hadoop 2.7.1、Hbase 2.0.X、JDK 1.8、ZooKeeper 3.4.6、操作系统为CentOS7.0;硬件配置信息:CPU型号为Intel 酷睿i7 8700K, 3.7 GHz主频,32 GB内存,20 TB硬盘,千兆以太网,各个节点配置信息如表2所示。
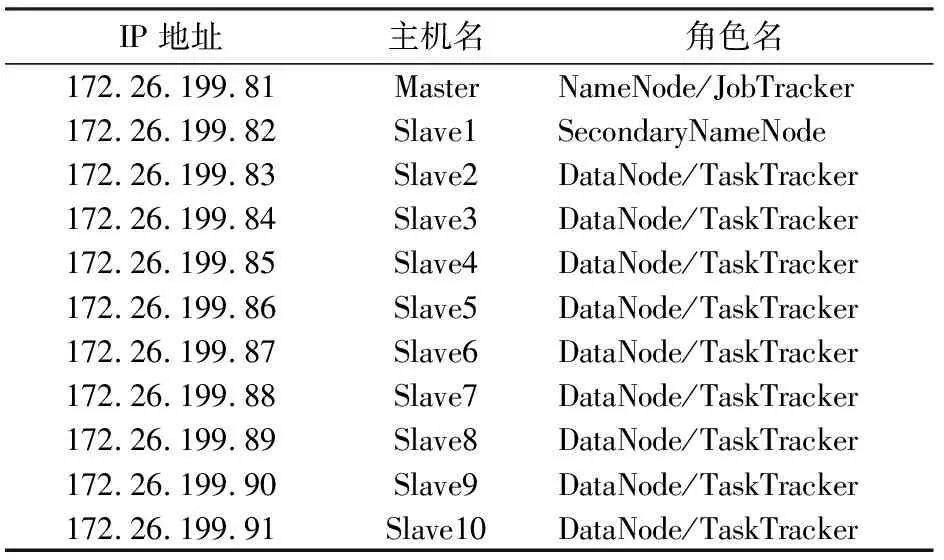
表2 服务器各节点信息Tab.2 Server nodes information
3.2 数据来源
实验数据选取了某省农机深松、植保、保护性耕作等8种作业类型产生的100 TB作业数据,该数据集记录了某省2015—2018年的作业情况,每条记录不等长,数据信息的类型包括文字、图像、视频等,数据存储结构如图3所示。本文用于对比实验的数据是通过Sqoop[20]工具导入,硬件环境与上述Hadoop集群保持一致。
3.3 实验结果与分析
3.3.1多条件检索、性能分析及其优化
检索数据仍采用上述数据,检索条件依次增加,本文设定的检索条件的个数(n)分别为2、3、4;检索次数为10次,检索时间取其平均值。其检索性能对比如图4所示。

图4 n为2、3、4多条件检索性能对比Fig.4 Contrast graphs of retrieval performance
由图4可知,随着数据量的增加,Hbase的响应速度降低较为明显,当数据规模达到千万级时,响应时间大于3 s。从理论层面上分析Hbase是一种面向列的数据库,其底层在行键上建立了基于行键的类B+树索引,可以相对高效地支持基于行键的数据检索;对于多条件查询的非行键数据的检索,系统需要调用全表扫描的功能,数据的整体检索效率低下。随着数据量的不断增加,优化后的索引方法的优势越来越明显,当数据量达到5×107条时,响应时间小于1 s,优化的性能与原生Hbase相比提高了3倍,能满足用户的需求。
为了更好地说明问题,本文对检索数据做了纵向对比,选取检索规模(C)为3×107条时,检索条件个数n取2、3、4,Hbase检索时间分别为3.576、2.887、2.458 s,二级索引Hbase检索时间分别为0.742、0.582、0.421 s。
可知,二级索引的性能均优于原生Hbase,而检索时间随着检索条件的增多呈下降的趋势。从理论上分析,由于检索条件的增多,从数据库中检索出符合条件的数据在减少,相当于减少了数据的并发量,因此,检索时间持续下降。
3.3.2系统压力测试
为了验证系统架构的合理性与安全性,本文选取了请求次数较多的大数据平台首页进行了压力测试,首页界面如图5所示。选用YCSB[21]作为系统的压力测试工具,选取每秒查询率(QPS)、吞吐量(TPS)和响应时间(RT)等作为系统性能度量的主要参数。本文通过多线程并发的方式模拟不同角色的用户,表3为5×105次并发用户压力测试结果,测试时间为5 min。实验结果取5次实验的平均值。

图5 大数据平台首页Fig.5 Home page of big data platform

参数 Hbase二级索引Hbase每秒查询率(QPS)233821424211每秒吞吐量(TPS)46588657响应时间(RT)/ms643183
通过测试结果,可以得出在高并发量(5×105次)时,优化后系统的RT提高了2.5倍。系统平均响应时间183 ms,系统的QPS、TPS提高了1倍左右,说明该系统在高并发时可高效稳定运行。
此外,对系统的读写能力进行了压力测试,表4描述了不同读写操作情况下(分别插入1×105、1×106、1×107条数据)系统插入数据的结果,每组实验进行5次,结果取5次插入的平均值。
由表4可知,在二级索引情况下,插入数据需要消耗的时间更多一些,这是由于二级索引需要触发协处理器将索引数据不断存入Solr中,随着数据量增多,与原生Hbase相比二级索引插入性能不断降低。从实验结果来看,3组实验的插入性能平均降低了13.3%。降低的插入性能与提高的检索性能相比,可忽略。

表4 插入响应时间测试结果Tab.4 Results of testing for insert performance ms
4 结论
(1)研究了负载均衡大规模集群数据处理技术,实现了农田田间耕、种、管、收及农田田块自身产生的多源异构海量数据的存储与检索,保证了海量农田田块数据存储的安全性与检索的高效性。
(2)针对Hbase数据库在农田田间数据进行多条件检索时性能不佳的问题,研究了面向列数据库高效索引技术,提出了基于Solr二级非主键索引的检索方法,在数据规模达到5×107条时,响应时间小于1 s,农田田块数据多条件关联检索时,相对原生Hbase数据库优化性能提高了3倍,大大提高了数据库的检索性能。
(3)研发了基于Hadoop的农田大数据平台,并对该平台进行了压力测试,测试结果表明,该平台在高并发量(5×105次)时,优化后系统的RT提高了2.5倍,平均响应时间为183 ms、系统的QPS及TPS提高了1倍左右,可保持系统的安全与稳定。目前该平台已具备农田田间管理功能,能对农田田块的大数据进行高效整合与处理,对指导大规模农田的安全生产与分析决策具有重大意义。
