基于朴素贝叶斯的文本情感分类及实现
2019-12-05梁柯李健陈颖雪刘志钢
梁柯 李健 陈颖雪 刘志钢


摘 要:本文利用Python语言,对25 000条英文影评数据进行文本分类。首先利用词袋模型对文本数据进行分类。在此基础上加入Word2Vec建立新的词向量特征,通过精准率和召回率对比前后2种模型的分类效果;最后通过逻辑回归和朴素贝叶斯分类模型的分类效果对照得出研究结论。结果表明:对于英文影评文本分类,在同等条件下,使用Word2Vec构建词向量模型的精准率和召回率比使用bag of Word词袋模型分别高出0.02个百分点和0.026个百分点;在使用Word2Vec的基础上,朴素贝叶斯分类器的精准率和召回率分别高出逻辑回归分类0.027个百分点和0.028个百分点。
关键词: 文本分类;词袋模型;Word2Vec;逻辑回归;朴素贝叶斯
【Abstract】 This paper uses Python language to categorize 25 000 English film review data. Firstly, word bag model is used to categorize text data; Then, Word2Vec is added to build new feature vectors, and the classification results of the two models are compared by precision and recall rates; Finally, the classification effects of logistic regression and Naive Bayesian classification model are compared. The results show that the accuracy and recall rate of word vector model using Word2Vec are 0.02 and 0.026 percentage points higher than those using bag of Word model under the same conditions. On the basis of Word2Vec, the accuracy rate and recall rate of Naive Bayes classifier are 0.027 and 0.028 percentage points higher than Logistic Regression classification respectively.
【Key words】 text classification; word bag model; Word2Vec; Logistic Regression; Naive Bayes
0 引 言
互聯网已融入社会生活的方方面面[1],各种通讯电子等行业迅速发展,使得文本、图像、视觉等数据挖掘任务的需求不断增加,而文本分类技术现已广泛应用到信息过滤、信息检索、词义消歧、信息组织及管理、话题发现及跟踪等多个。研究可知,文本分类能够帮助用户对庞杂的数据信息进行精准分类,或是帮助用户快速定位和筛选所需信息,从海量文本数据中挖掘出对于当前个人用户或用户群最具价值的信息则有着较高的研究意义和应用价值。
分类是机器学习和数据挖掘领域中一项重要任务。分类是把数据样本映射到一个事先定义的类中的学习过程,其实质就是根据现有的样本组成的训练集判断一个新样本的类别。严格来讲,分类也是一种预测,是对一组离散属性(类标号)的预测,而预测通常指的是对连续值属性的估计[2]分类,现已成为众多领域的关键技术,诸如情感分类[3-4]、自然语言处理[5]、计算机视觉[6]、手写文字[7]等等。常用的分类算法有k近邻、决策树、随机深林、逻辑回归、贝叶斯、神经网络等模型[8]。而文本分类任务大多都是二分类任务,最常用的方法是逻辑回归和朴素贝叶斯分类模型。
基于此,本文运用kaggle网5 000条影评数据,并选取Python程序语言,来进行影评数据的情感分类研究。对此,本文拟展开分析论述如下。
1 英文文本预处理
数据预处理是数据挖掘的重要部分,在真实世界中,数据通常是不完整的(缺少某些感兴趣的属性值)、不一致的(包含代码或者名称的差异)、极易受到噪声(错误或异常值)的侵扰的。研究中对这些噪声数据进行处理,不仅有利于后续数据分析,并可使数据分析结果更有意义。
无论是中文还是英文数据,文本数据的预处理一般包括5个步骤,即:去掉html标签、移除标点、切分成词、去掉停用词和重组为新的句子。这里对各步骤的设计分析可做重点阐述如下。
1.1 去掉Html标签
在当今互联网时代,对文本数据来说,来源广泛,易获得,但质量参差不齐。考虑到很多数据都是从互联网上实时爬取得来,而爬取得到的数据会含有大量的Html网页标签和表情等,但Html标签对数据分析没有任何作用,甚至还会影响分析效果。综上分析可知,从互联网上取得数据后的第一步就是去除Html标签。
1.2 去掉标点符号
对于文本分类而言,标点符号和特殊符号的存在影响计算机识别效果,为了确保分类器的分类速度较快,以及得到良好分类的准确率,故需过滤掉这些噪声数据[9]。
1.3 文本分词
无论是在汉语还是英语中,词一般都代表最小的语义单位,因此在研究中就需要将句子划分成词,才可转入后续的研究分析中。在Python语言中,中文分词一般选用Jieba分词器,英文分词一般选用Nltk分词器。其中,Jieba是一款基于Python的中文分词器,目前也是一款流行的开源分词器,内部有多个算法,支持多种分词模式,并可以利用隐马尔可夫模型和维特比算法解决部分未登录词问题。Nltk(Natural Language Toolkit),是自然语言处理工具包,也是NLP领域中,最常使用的一个Python库,Nltk包括图形演示和示例数据。
1.4 去掉停用词
去除停用词可以大大减小特征词的数量,进而提高文本分类的准确性。停用词主要有2种类型。一种是人类语言中包含的功能词。这些功能词都较为常见,类似虚词,与其它词相比,没什么实际意义。比如英语中的the、is、at、which、on 等 ;另 一 种是 词 汇 词 , 比如want等。对中文来说,包括着诸如“的”、“和”、“在”、“是”等在内的一系列副词、量词、介词、叹词、数词。对文本分类来说,这些词汇几乎在所有文本中都会出现,不具备特殊性和区分度,反而会稀释那些有区分度的词,所以通常会把这些词从问题中移去,如此一来就提高了分类性能。
1.5 数据重组
数据重组是文本分类中的重要环节。数据重组就是将预处理后的文本数据重新组成一句完整的话,便于后面的词向量构建和模型的训练。
2 文本特征抽取和词向量模型
2.1 文本特征抽取
文本特征抽取是为了提高文本分类的效率,减少计算复杂度。研究时,可通过判断特征词来进行文本特征选择。总地来说,文本特征选取方法有文本频率和词频两种,其它包括卡方检验、信息增益、互信息等方法是以文档频率为基础,常用的TF-IDF则是综合词频和文档频率构建的特征选择方法。在本文研究中,选用了词频统计方法进行文本分类处理。
2.2 词向量模型
词向量模型是将文本文件表示为标识符(如索引)向量的代数模型。其主要适用于信息过滤、信息检索、索引和相关排序方面的研究。词向量就是用一个向量的形式表示一个词。机器学习任务则是把任何输入量化成数值表示,同时再充分利用计算机的运算能力,计算求出最终想要的结果。
本文分别使用bag of Word模型和Word2Vec模型进行词向量构建,并且对比分析了2种词向量模型进行文本分类的性能优劣。
3 文本分类模型
4 基于Python的英文文本分类设计实现
本文选取kaggle网上25 000条英文影评数据进行实例分析,通过考察用户评论,对该评论进行情感分类,分为积极(Positive)和消极(Negative)两类影评数据,并选用精准率和召回率来评价分类效果。基于前述分析流程,逐步实现分类任务,包括词向量构建对比分类和分类器对比分类。部分数据如图3所示。对此研究过程,可得阐释分述如下。
4.1 数据预处理
根据上文可知,数据预处理包括5个部分,即:去掉Html标签、去除标点符号、切分成词、去掉停用词和数据重组。程序代码如图4所示。將预处理好的数据进行重组,命名为clean_review,详见图5。
4.2 特征抽取和词向量模型
本文运用词频方法抽取数据特征(用sklearn的CountVectorizer),分别选用bag of Word和Word2Vec 两种词袋模型构造词向量,部分代码参见图6。
4.3 文本分类模型
4.3.1 逻辑回归分类
使用bag of Word模型的逻辑回归分类,部分代码如图7所示。
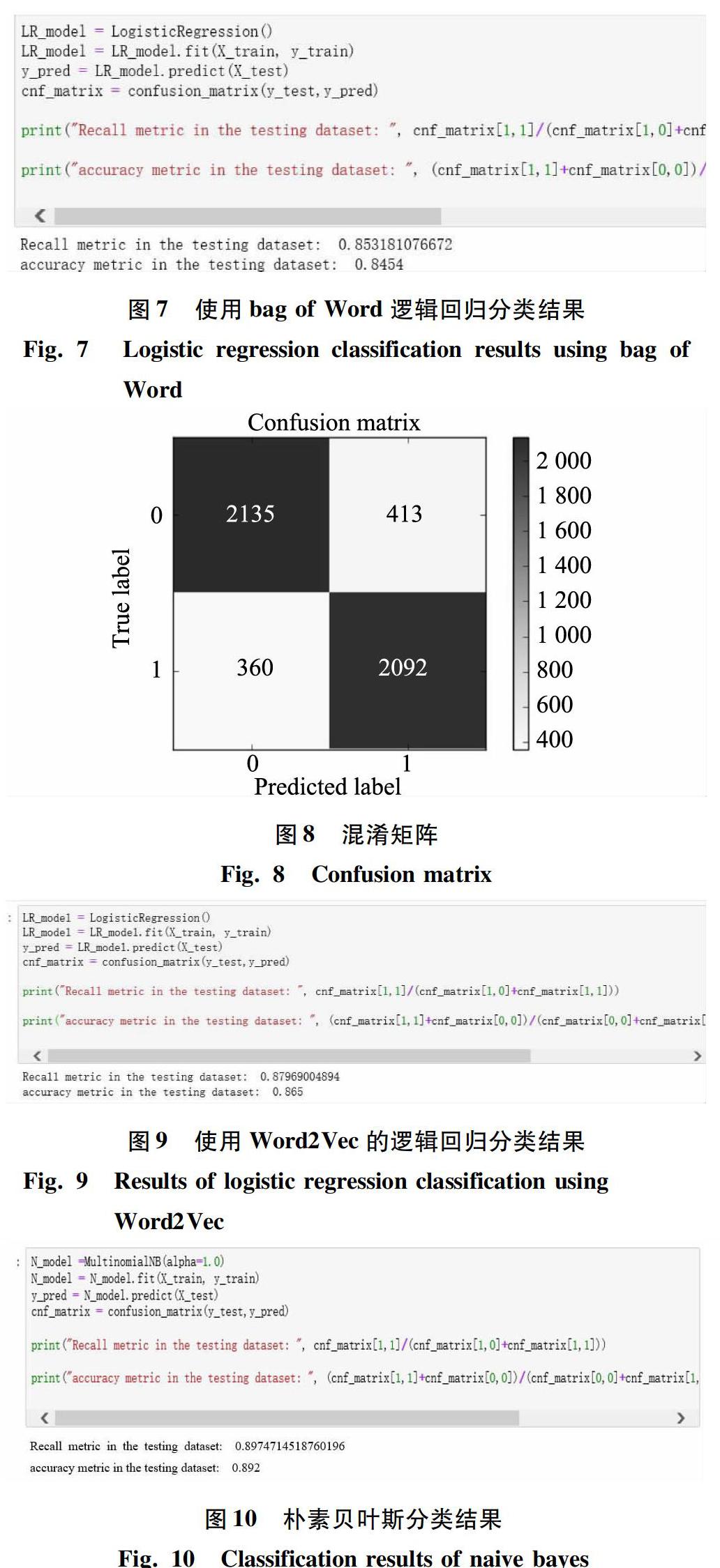
使用bag of Word 预料模型的逻辑回归分类效果见图7,准确率为0.845,召回率为0.853,分类效果较好,其混淆矩阵如图8所示。
使用Word2Vec模型的逻辑回归分类中,词向量维度设为300,最小单词数量设为40,单词移动窗口设为10。分类结果如图9所示。
由图9可知,使用Word2Vec模型的逻辑回归比使用bag of Word的精准率提高了0.02个百分点,召回率提高了0.026个百分点。
4.3.2 朴素贝叶斯分类
通过以上分析,使用Word2Vec构建词向量的逻辑回归分类效果更好。本节在Wor2Vec的基础上,选用朴素贝叶斯分类器,分别采用逻辑回归和朴素贝叶斯算法对影评数据的分类效果进行比较。研究最终得到的朴素贝叶斯的分类结果如图10所示。
由图10可知,朴素贝叶斯分类器比逻辑回归分类精准率高出了0.027个百分点,召回率高出了0.028个百分点。由此可见,在影评文本分类中,朴素贝叶斯分类器的分类效果要优于逻辑回归。
5 结束语
本文讨论了文本分类常用的分类方法,即逻辑回归和朴素贝叶斯算法。与此同时又可看到,近年来已陆续涌现数目可观的利用深度学习进行文本分类的研究,并在许多公开数据集和分类任务上都取得了最优结果。但仍要指出,深度学习也有着严重缺陷,对此可做详尽剖述如下。
(1)需要大量的数据。深度学习是一种数据驱动型的技术,海量的数据与深度学习算法结合往往能带来巨大的效果提升,但如果数据量不足(比如本文中用到的新闻分类数据集)时,深度学习算法容易出现过拟合,泛化效果很差。
(2)缺乏解释性。深度学习端到端的训练和学习带来很多便捷,无须人工繁杂地提取特征,也无须设计过多中间步骤,但这种端到端也会带来不可预测的黑箱效应。参数调节与最终结果的好坏难以做到一一对应,缺乏指导意义,并且很难复现模型。鉴于前述分析可知,朴素贝叶斯在现今工业界也仍会受到青睐。
本文利用Python语言,对25 000条英文影评数据进行文本分类。首先利用词袋模型对文本数据进行分类;在此基础上加入Word2Vec建立新的词向量特征,通过精准率和召回率对比前后两种模型的分类效果;最后,即对逻辑回归和朴素贝叶斯分类进行了对比研究。结果表明,对于英文影评文本分类,在同等条件下,使用Word2Vec构建词向量模型优于使用bag of Word词袋模型,朴素贝叶斯分类效果优于逻辑回归分类。在后续工作中,尤其在诸如决策树、神经网络等算法对比上仍有待进一步的深入探索与研究。
参考文献
[1]Miniwatts Marketing Group.世界互联网统计网站[EB/OL].[2019-08-21]. http://www.internetworldstats.com.
[2]毛承胜. 基于贝叶斯决策理论的局部分类方法研究及其应用[D].兰州:兰州大学,2016.
[3]LI Xiaowei, ZHAO Qinglin, HU Bin, et al. Improve affective learning with EEG approach[J]. Computing and Informatics, 2012, 29(4): 557-570.
[4]LU Yifei, ZHENG Weilong, LI Binbin, et al. Combining eye movements and EEG to enhance emotion recognition[C]//IJCAI'15 Proceedings of the 24th International Conference on Artificial Intelligence.Buenos Aires, Argentina:AAAI,2015:1170-1176.
[5]張春燕.基于自然语言处理的文本分类分析与研究[D]. 赣州:江西理工大学,2011.
[6]GRAUMAN K, DARRELL T. The pyramid match kernel: Discriminative classification with sets of image features[C]//
IEEE International Conference on Computer Vision. Beijing, China: IEEE, 2005: 1458-1465.
[7]CAO Jun, AHMADI M, SHRIDHAR M. Recognition of handwritten numerals with multiple feature and multistage classifier [J]. Pattern Recognition, 1995, 28(2): 153-160.
[8]周志华. 机器学习[M].北京: 清华大学出版社, 2016.
[9]DILRUKSHI I, ZOYSA K D. Twitter news classification: Theoretical and practical comparison of SVM against Naive Bayes algorithms [C]//International Conference on Advances in ICT for Emerging Regions(ICTer).Colombo Sri Lanka:IEEE, 2013:278.
