基于Python的图书采购查重系统的设计与实现*
2019-12-05方炜
方 炜
(安徽师范大学图书馆 安徽芜湖 241003)
图书采购查重是指对海量的馆藏文献资源与计划采购的文献列表进行筛选、去重,避免因重复采购而造成资源的浪费。这在图书馆资源建设过程中是非常重要的一环,但也是图书馆采访人员长期以来面临的难点。因为图书查重是一种劳力密集的重复性工作,既简单又枯燥,必须耗费大量的人力和时间,同时采访人员长时间进行重复单调的工作,很容易产生漏检和错检[1]。目前业界出现了多种查重方法和查重系统,各有优劣。笔者通过分析现有查重方法和系统的使用效果,针对其不足之处,设计了一套基于Python语言以及PyQt工具包的图书采购查重系统。
1 常见查重方式及对比
1.1 常见查重方式
采访工作中的查重,实际上是将两个书目信息列表进行比对的过程,现有馆藏书目(以下简称“源书目”)信息一般存储在各图书馆数据库中,而计划采购书目(以下简称“目标书目”)信息一般为图书馆自搜集的书目清单,或由书商提供的书目清单。从技术层面来看,目前常见的查重方式有以下3种:①图书管理系统。图书馆在文献资源建设时一定会使用图书管理系统,而大多数管理系统如ILAS、ALEPH 500中已经集成了采访查重功能,因此部分图书馆直接通过其正在使用的图书管理系统进行查重。②工具系统。在图书管理系统无法充分满足自身查重需求时,部分图书馆采用内部开发或购买独立的查重工具系统的方式进行查重。③人工比对。早期,在图书馆数字化建设还不够成熟的时候,人工比对是唯一的查重方式,但是随着馆藏资源数量的剧增,纯粹意义上的人工比对方法已经无法实施。但是针对某些信息不规范或残缺的特殊文献,采访人员需进行人工主观鉴别,再进行查重。
1.2 查重方式优劣对比
以上提到的3种查重方式仍然广泛应用在图书馆的采访工作中,其使用环境和查重效率方面各有优劣。
1.2.1 图书管理系统
图书管理系统工作过程是图书管理系统自动分析采访人员上传的目标书目文件,进行数据库比对,并由管理系统自动输出结果。这种方法要求目标书目文件格式规范,满足系统输入要求,且比对项符合系统规则,可以被系统正常识别。
图书管理系统查重的优点为:实时准确。因为是直接访问源数据库,其信息都是实时的,不会出现信息滞后,查询结果准确。其缺点为:①依赖网络。无论采访人员在馆内还是馆外,都必须具有网络访问权限,且要求网络快速稳定,否则将造成无法访问或查重效率低下等问题。②灵活性差。系统对目标书目文件的格式有着严格的要求,且查重字段也必须完全相同,但工作人员从各种渠道获得的目标书目文件格式各异,所以需先进行整理和转换后才能进行查重。③可维护性差。常见的系统都是商业公司的产品,如果采访人员需要根据特定的场景自定义查重方法,很难单独要求其修改功能,即便进行了修改,在升级系统时也难免会影响到其他功能的正常使用。
1.2.2 工具系统
目前常用的工具系统主要分为B/S架构和C/S架构。如果图书管理系统提供了对外访问接口,两种架构都可以进行远程实时查重,区别不大。但在没有访问接口时,B/S架构的系统一般是先将源数据库导出备份到服务器上,再连接查询备份的数据库。而C/S架构的系统则是从源数据库中导出Excel、MARC等格式的备份文件,然后再利用读取文件信息的方式解析其中包含的书目信息,进行比对后输出结果。
工具系统查重的优点为:①灵活性高。工具系统在研发设计时针对性较强,完全为采访查重工作服务,可以充分满足采访人员的查重需求。②易维护。因为是独立的工具系统,所以易于修改和扩展,及时满足采访人员的工作需求,具有更多的灵活性,而且不用担心会影响到图书管理系统。其缺点为:①实时性受限。如果图书管理系统提供了接口,查询结果具有实时性。反之,因为是备份数据,所查询出的结果具有滞后性。②需要技术支持。无论是导出到备份数据库或是本地文件,都需要相关技术人员的操作,后期的扩展和维护更是需要技术支持。
1.2.3 人工比对
针对某些特定文献或特殊场景,人工查重是一个更加主观准确的查重方式。采访人员首先利用自身专业知识和工作经验对目标书目进行信息提取和分类,再逐条输入到图书管理系统中查询,并对最终的查重结果做出修改和确认。
人工比对查重的优点为:灵活性高。采访人员可以主观分辨出相似的书目,也可以根据经验对记录有误的信息进行人工纠错等。其缺点为:①效率低。在目标书目数量较为庞大的情况下,人工比对的速度慢,需要耗费大量时间完成。②易产生误差。因为是人工比对,难免会因为工作疲劳或疏忽而导致结果出现偏差。
2 系统设计
2.1 方案选定
通过上面的优劣对比,笔者认为工具系统查重是三者中最为方便、灵活的查重方式。不仅可以在不影响源数据库的情况下进行操作,还可以利用其可扩展性充分满足采访人员的工作需求,其效率和准确度上也为最优。其中,C/S架构的系统比B/S架构的系统更为合适,理由如下:①易于安装部署。B/S架构的系统必须安装数据库软件,而数据库软件本身又比较庞大,不便于安装,而且需要进行配置部署后才能访问。相反,C/S架构的系统安装程序体积小,无需配置部署,直接操作交互界面即可使用。②适用场景广泛。B/S架构的系统一般都部署在固定的服务器上,必须通过网络远程访问。而C/S架构的系统则不仅可以通过网络访问远程数据库,也可以在无网络的环境下直接操作本地备份文件,适用于馆内馆外的各种场景。
Python是一门应用广泛的通用编程语言,易于学习使用且功能强大,适合各种规模的软件编写[2]。其文件处理功能也非常强大。例如,可以使用xlrd、xlwt模块对Excel文件进行读写;利用xml.dom模块对XML文件进行读写等。此外,针对超大文件,Python还可以进行分块读取,很好地解决了内存不足等问题。
Qt库是目前最强大的GUI库之一,而PyQt作为一个强大的工具包,成功地将脚本语言Python和Qt库融合到了一起,利用它可以很方便地创建GUI应用程序[3]。这是实现查重系统中用户交互界面模块最佳的方案。
因此,本查重系统是基于Python语言,再结合PyQt工具包进行开发,最终生成了一个Windows环境下的安装程序,采访人员直接进行单机安装即可投入使用。
2.2 整体工作流程设计
采访人员在查重时的工作流程一般分为4个步骤:①输入源书目信息以及目标书目信息。这些信息一般以文件的形式呈现,如Excel文件、MARC格式的.marc文件或.iso文件等。②选定需要进行比对的字段。书目信息一般包含多个字段,但因存储方式不同,各字段又无法一一对应,因此要人工选取合适的字段进行比对。③执行查重。查重系统根据输入的文件信息,以及采访人员选定的字段进行自动比对。④输出结果。待查重系统运算完毕之后,根据采访人员指定的结果存储方式,将结果输出到本地文件中。
2.3 系统功能设计
2.3.1 文件读取
通过调查采访人员的工作过程发现,采访人员存储书目信息的文件格式一般为Excel文件或者MARC格式的.marc文件和.iso文件,其中MARC作为机读目录格式的大统一,借其数据格式的标准化及细分化优势,广泛应用于各类图书馆的编目工作中,在采访工作中也是主流文件[4]。因此,查重系统中应该具备读取并解析这些文件格式的功能模块。此外,还需要考虑到源书目文件较大,可能是GB级别的文件,而一般的计算机闲置内存可能只有几百MB,如果全部直接加载到内存,系统可能会因为内存耗尽而无响应等问题,需要确保此功能模块可以处理大文件。
2.3.2 解析字段
常见的查重比对都是只比较ISBN字段,但是为了让采访人员可以更灵活地比对书目信息,本系统将提供字段解析模块,首先应分析文件的类型,再用不同的方式获取其字段信息。例如,Excel文件中,其字段信息一般为每个Sheet中第一行的数据;而MARC格式的字段则是和数据一起存放在每个条目中。
因为存在多种文件格式,所以对应字段的存储方式存在差异。例如,MARC字段中代表出版社的字段为“010”,子字段“b”,而在Excel文件中,字段名称直接存储为字符串“出版社”,无法直接进行比较。因此本模块将采用配置文档的方式,使得用户可以自定义MARC字段表示的名称,从而实现不同类型文件之间的查重。
2.3.3 比对查重
根据采访人员选择需要比对的字段信息,采用遍历的方式,提取源书目和目标书目中被选字段对应的数据,最后再通过字符串比对的方式进行查重。但是如果直接字符串比对,又无法兼容一些可能存在的问题。例如,2007年起使用的新版ISBN号是13位,而在此之前都是使用10位来表示,对于同一本书的新旧表示方法,必须在比对时要考虑到兼容性[5]。此外还有字符串中存在多余空格、大小写等问题也将在本模块中考虑到。
2.3.4 输出结果
对于采访工作人员来说,最终的查重结果一般为方便存储、阅读的本地文件。因此,本系统拟将结果写入到新创建的Excel文件中,并分成重复列表和非重复列表两个工作Sheet,采访人员可以直接用Office软件打开查看。其中重新创建Excel文件的方式可以保证原始文件不会被损坏。
3 系统功能实现
本系统的开发IDE选为PyCharm。PyCharm是一款功能强大的Python编辑器,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,且具有跨平台性[6]。
3.1 文件读取
文件读取功能的实现主要使用的是I/O函数、xlrd和xml.dom模块:
# Read and parse MARC file
class MARCHelper(object):
def __init__(self,file_path):
self._file = open(file_path,'rb')
… …
# Read and parse Excel file
class ExcelHelper(object):
def __init__(self,file_path):
self._ file_data = xlrd.open_workbook(_file_path,use_mmap=0,on_demand=True)
… …
# Read and parse config file(.xml)
class MARCFiledManager:
def __init__(self,file_path):
self.file_dom = xml.dom.minidom.parse(file_path)
… …
3.2 字段读取
Excel文件读取字段的方式为直接读取第一张工作Sheet的第一行内容:
… …
def get_column_names(self):
column_names = self.get_row_value(0,0)
return column_names
… …
针对MARC文件的方式则为解析字段以及子字段标识符,再通过比对XML格式配置文档里的信息,找到对应的字段名称[7]。其中配置文件的格式如下:
… …
… …
采访人员可以根据需求自行修改配置文件中的字段名称,以便更灵活地进行字段比对。
3.3 比对查重
比对方面,设计时采用了面向对象中多态的概念,在处理Excel文件的ExcelHelper类,以及处理MARC文件的MARCHelper类中,定义了相同的check_row_exist函数:
def check_row_exist(self,compared_columns_index,tar_value,tar_columns_index):
除此之外,还定义了一个遍历书目信息的迭代器,可以循环读取数据:
… …
def set_iter_begin(self):
… …
def get_iter(self):
… …
def next_iter(self):
… …
查重时迭代器的使用方法如下:
self.__instance_tar_file_helper.set_iter_begin()
iter_not_end = self.__instance_tar_file_helper.next_iter()
while iter_not_end:
… …
iter_not_end = self.__instance_tar_file_helper.next_iter()
其中,Excel数据以读到最后一张工作Sheet的最后一行作为结束,MARC文件则是读到空行作为结束。
由于数据量可能较大,比对过程将需要很长的时间,所以必须采用多线程的方式进行比对操作,否则主交互界面将会卡死,导致程序崩溃,用户交互也不够友好。因此在实现此功能时继承了QThread类,并采用Signal与Slots的方式让数据处理层和UI层进行通讯:
… …
class GetDuplicateColumnNamesThread(QtCore.QThread):
GetDuplicateColumnNames_Finished_Signal= QtCore.pyqtSignal(list)
… …
class CheckAndSaveThread(QtCore.QThread):
CheckAndSave_Finished_Signal = QtCore.pyqtSignal()
… …
3.4 结果输出
为了方便阅读,最终的结果是存储到Excel文件中,所以采用的是xlwt模块,为此代码中专门定义了一个ExcelSaver类,并新建一个文件:
class ExcelSaver(object):
def __init__(self):
self._work_book = xlwt.Workbook()
进行比对之前会先建立两个工作Sheet,即重复的和非重复的,并写入列名:
… …
excel_saver = ExcelSaver()
excel_saver.add_sheet(u'非重复')
excel_saver.add_sheet(u'重复')
column_names = self.__instance_tar_file_helper.get_column_names()
excel_saver.insert_row(u'重复',0,column_names)
excel_saver.insert_row(u'非重复',0,column_names)
… …
比对过程中会自动插入数据,在结束时进行保存:
… …
if duplicate:
excel_saver.append_row(u'重复',tar_value)
else:
excel_saver.append_row(u'非重复',tar_value)
… …
excel_saver.save(result_file_path)
… …
3.5 用户交互界面
本系统的UI界面是先使用Qt Designer创建并设置好所有控件,再转换为Python文件,效果如图1所示。
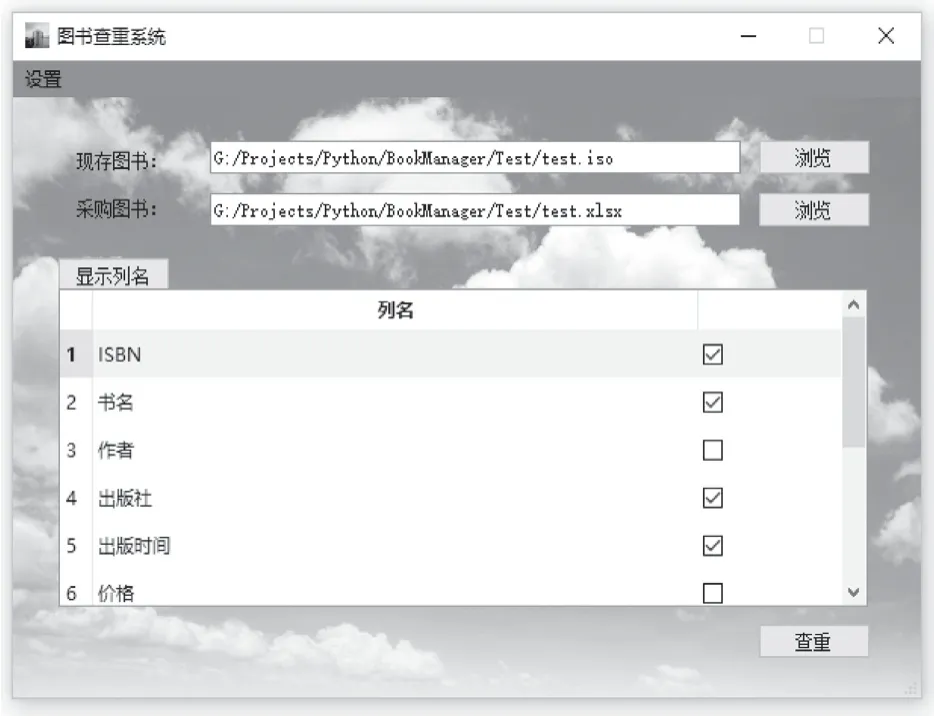
图1 UI界面效果图
UI上用两个QLineEdit分别表示源书目和目标书目的文件路径,并提供QFileDialog方便用户选择文件。
在用户设置完路径并点击显示列名后,UI下方采用QTableWidget来显示可以进行比对的字段,以及可以让用户勾选的CheckBox。
用户选择完毕后直接点击QPushButton实现的查重按钮,会出现让用户选择保存结果文件的对话框,然后即开始进行查重。查重的同时UI界面的中间会出现一个模态等待对话框。
… …
class WaitingDialog(QtWidgets.QDialog):
def __init__(self,parent=None):
QtWidgets.QDialog.__init__(self,parent)
self.setWindowTitle('Please wait...')
self.setWindowFlag(QtCore.Qt.SplashScreen)
… …
待查重完毕之后,会有对话框提示用户操作完成,此时用户可以打开保存的文件,阅读查重结果。
在进行UI界面的设计时,也考虑到了采访人员所用系统语言环境的问题,将要显示的文字都进行了国际化处理,程序可以自动识别当前系统的语言,显示对应的语言文字:
… …
def translate_ui(self,BookListCheckerClass):
_translate = QtCore.QCoreApplication.translate
BookListCheckerClass.setWindowTitle(_trans late("BookListCheckerClass","图书查重系统"))
self.label_source_books.setText(_translate("BookListCheckerClass","现有图书:"))
… …
4 结语
本系统的设计和实现采用了目前较为前沿的Python语言和Qt框架,充分发挥了其文件处理功能和GUI搭建功能,为后来图书采购查重系统的开发选择提供了参考,推动了图书采购查重自动化的发展。总体来看,具有以下优点:①易安装使用。系统的安装程序大小在35MB以内,易于携带和安装。采访人员无需网络,无需配置数据库等操作,即可随时使用。对于经常在外采购图书的工作人员非常适用。②支持文件类型丰富。为了充分满足查重需求,本系统在文件类型的支持上涵盖了常用的.xls、.xlsx、.iso、.marc等书目信息格式。③比对灵活。不仅可以让用户复选比对字段,还考虑到了ISBN的兼容性问题、Excel字段和MARC字段不对应的问题,并允许用户进行自定义字段,使得系统可以更灵活地满足查重需求。④系统可移植性高。本系统所采用技术,无论是Python还是Qt都是跨平台的,其可移植性高,可以不仅仅依赖于Windows操作系统。
本系统依然存在不足之处。例如,文件类型的支持虽然已经满足常用的需求,但是还可以进一步扩大,如.txt和.cvs等格式的文件。另外,本系统虽然在设计上已经预留了网络查询接口,但在实现上还没有全部完成,暂时没能弥补其实时性差的缺点。希望在后续的工作中可以继续完善该系统,更好地为查重工作提供自动化服务。
