大数据背景下高校家庭经济困难生的精准认定研究
2019-12-05王萍萍
王萍萍
(连云港职业技术学院,江苏连云港 222006)
自从十九大报告指出,2020年要全面建成小康社会之后,受到了各方的高度重视,他们竭尽所能,各司其职的为全面小康社会贡献自己的力量。而阻断贫困代际传递最有效的办法是让他们有知识,有技能,让他们有公平接受教育的机会,因此党和国家很重视家庭经济困难学生的上学问题,已建立起了以政府为主导、学校和社会积极参与的学生资助政策体系,资助范围上实现了“三个全覆盖”,即各个学段全覆盖、公办民办学校全覆盖、家庭经济困难学生全覆盖,资助效果上实现了“三不愁”,即入学前不用愁、入学时不用愁、入学后不用愁,从制度上保障了“不让一个学生因家庭经济困难而失学”。[1]其中,高等教育是获得技能的关键时期,国家更是重视,针对高等教育的学生资助政策有国家奖学金、国家励志奖学金、国家助学金、国家助学贷款、基层就业学费补偿贷款代偿、应征入伍服义务兵役学费补偿贷款代偿及学费减免、直招士官学费补偿贷款代偿、师范生免费教育、退役士兵教育资助、新生入学资助项目、勤工俭学、校内资助、绿色通道。2018年中国学生资助发展报告中指出,政府、高校及社会设立的各项高校学生资助政策共资助全国普通高等学校学生4387.89万人次,资助资金1150.30亿元,比上年增加99.56亿元,增幅9.48%。
那么,如何让这些好政策真正落到实处,帮助到真正需要帮助的人?十九大报告也明确指出要“坚持精准扶贫、精准脱贫”。而精准,就是要做到资助对象精准、资助标准精准、资金发放精准,其中资助对象的精准是关键,只有对象精准,一切的工作才是有意义的,才能为全面进入小康社会贡献力量,因此,本文在大数据的背景下深入研究高校家庭经济困难生的精准认定问题。
1 高校家庭经济困难生精准认定存在的问题
目前,大部分高校对贫困生的认定,都是按照教育部、财政部的要求来的,首先由学生申请并提供相关证明材料,其次由辅导员带着班级评议小组对学生的材料、表现、日常消费情况进行评议得出结果,然后由学院评议小组对结果进行初审,再然后报到学校资助管理中心进行复审,初步得出家庭经济困生的名单,最后进行公示,结果无异议后得出最终家庭经济困难生的名单[3]。这样的认定方式存在诸多的问题,经常导致漏报错报的情况发生。
1.1 真实性的问题
真实性是做好一切事情的前提和保证,在贫困生认定的过程中,材料的真实性至关重要,对评定结果有着决定性的作用。在实际工作中,相关证明材料是由学生本人提供的,由于各种原因,高校无法一一查访材料的真实性,所以真伪难辨。通过私下调查还发现,家庭经济调查表上的很多数据和信息是学生本人填写上去的,当地的政府机关或民政部门在盖章时也不进行调查,一是因为当地机构认为是为自己的学生好,故而偷懒省事;二是没有相关的监督机构进行监督问责;三是学校对于家庭经济情况调查表完整性的要求不是很高,很多经办人的签字和联系电话不全,这样导致盖章人员更加不重视。
1.2 客观性的问题
在贫困生认定的过程中都是由一级一级的评议小组进行评议的,难免存在一定的主观性,不管是学生评议小组还是辅导员都会不自觉的代入一定的主观色彩,比如学生在参与评议,会偏向于和自己想处好的同学,辅导员在评议时,会偏向表现良好,工作积极的同学,还有个人认知限制的主观性,这样的主观性必定会导致评议结果的不准确性。因此,如何在评议过程中减少人为的主观性,进行更多的客观性的评价,是值得我们思考的。
1.3 标准性的问题
教育部对于贫困生认定就是指学生总体家庭经济情况困难,学生和家庭没有能力支付学生在学校期间受教育的各种费用,包括住宿费、学费和其他应缴费用。这样的标准是一个很模糊的标准,在实际应用中很难把握,对于贫困等级的认定更是没有指导作用。然而,贫困等级的确定经常困扰着资助工作者,不知道以什么为标准,只能反复看材料,根据个人的认知进行比较来确定贫困生的等级。
1.4 名额分配问题
大部分高校是根据人员比例来划分名额的,学校在得到省里分配的名额后根据各学院的人数进行学院名额的分配,学院在根据年级班级的人数在进行名额分配。这样的分配方式,经常导致有的班级名额不够用,而漏掉了贫困的学生,有的班级因为名额多,而出现了伪贫困的学生。因此如何从学校整体出发,综合考虑情况,合理的确定贫困生人数,需要我们不断探索。
2 大数据的内涵
维基百科将大数据定义为无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合;权威IT研究与顾问咨询公司Gartner将大数据定义为大数据是大量、高速、及多变的信息资产,它需要新型的处理方式去促成更强的决策能力、洞察力与优化处理[5]。大数据的意义不在于拥有庞大的业务数据信息量,而是通过对各种相关领域内含有不同意义的孤立数据进行专业化处理,通过特定维度的聚合、挖掘和分析,得出符合发展趋势的预测或判断。大数据在应用时大致分为五个步骤:数据采集、数据处理、数据分析、数据展示、数据应用。
3 大数据在高校家庭经济困难生精准认定中的应用分析
高校的资助工作不同于其他阶段教育的资助,因为高校的学生来自五湖四海,分散在各个地方,有省里的,有省外的,有发达地区的,有偏远地区的,因此大数据在高校家庭经济困难生认定中的理想应用是:加强顶层设计,由国家牵头,统一规划,建立全国贫困生大数据平台,该平台与民政、扶贫、卫生医疗、残联、银行、学校等相关部门对接。这样既能保证系统的高水平和数据的真实性,还便于统筹安排,合理分配资源。但是目前还达不到这样理想的状态,那么现阶段大数据如何应用在高校家庭经济困难生的认定当中呢?
在家庭经济困难生的评定过程中,主要考虑学生的家庭情况和在校情况,家庭情况暂时无法通过共享大数据获得,目前比较容易实现的是学生在校的大数据。大部分高校都有校园一卡通,在校的大部分消费都是要通过一卡通来完成的,所以通过一卡通采集数据来分析学生的消费情况。学生在校的表现,可以通过学校的系统来查出学生的学习排名、获奖、工作等其他情况。但是仅凭学生在校的消费情况和表现不能完全反映出学生的实际贫困情况,因为通过一卡通采集的消费数据不一定完全准确,有些学生在校外吃的比较多而采集不到,有的学生减肥而消费少,可能还有一些其他特殊情况等。所以本文还要结合学生的家庭情况调查表采集一些数据来共同认定家庭经济困难生。通过调查发现,随着国家对扶贫工作的高度重视,各地方,各部门对扶贫资助工作也都规范起来,尤其乡镇的一线工作者对贫困户的认定审核更加仔细、负责,对于该撤销的撤销,该增补的增补,学校部门对高校家庭情况调查表也严格要求,不仅要求所填内容完整,而且也会通过查询各个乡镇的电话进行查访。因此,现在的家庭经济情况调查表是具有一定的参考依据的。
因此,本文通过一卡通和学校系统来获得学生在校的动态数据分析,通过家庭经济情况调查表来获得学生家庭情况的静态数据分析,然后采用模糊综合评价的方法,综合考虑各个因素做出科学的评价。
4 大数据背景下基于模糊综合评价的贫困生认定实例分析
4.1 指标的选取
一个家庭的经济情况不仅和收入有关,而且和必要的开支有关,因此本文分析家庭经济情况调查表后,选取家庭人均收入、教育费用、特殊花销。家庭人均收入包括需要赡养的老人、不包括已成家立业的兄弟姐妹;教育费用即是需要接受教育的兄弟姐妹所需的费用,根据统计,子女教育费用的比例在家庭开销中越来越大;特殊花销包括重大疾病、天灾人祸等花销。在校情况就选取学生的在校消费情况和在校表现两个指标,学生在校的花费从侧面反映了家庭的经济情况;资助工作是促进教育公平,激励学生更好的学习技能的,因此学生的在校表现也作为参考的依据。因此本文共选取5个指标,包括家庭人均收入、教育费用、特殊花销、在校消费情况、在校表现,且这五个指标全通过数据分析得来。
4.2 权重确定
本文通过层次分析法确定指标的权重,W:W=(w1,w2,w3,w4,w5),且,如表1。从表中看出家庭人均收入情况最能反映家庭经济情况;其次体现贫困程度的是学生在校的消费水平和教育费用;特殊事件是偶发事件或者少数事件,但是如果发生对家庭经济情况影响比较大;把学生在校表现纳入评价指标,一方面是为了激励学生表现,另一方面根据经验,越贫困的学生,在表现上越稳定。

表1 指标的权重
4.3 隶属度确定
本文采用模糊统计的方法,邀请专家对家庭情况进行评议,由评判结果构造出模糊矩阵R:

其中rij=评其为第j个等级的人数/评委的总人数。
请专家进行评议之前,会对各个指标的数据进行分析处理,然后将各个指标的数据资料提供给各个专家。其中,家庭人均收入指标中还会提供当地的最低居民生活保障,家庭人均收入与最低生活保障的比值,所有申请人比值的排序;教育费用需要学生提供兄弟姐妹接受教育费用的发票,得出每个申请人教育费用的总和,然后对所有申请人的教育费用进行排序;特殊消费也是需要学生提供账单的,比如重大疾病,需要提供医院的诊断证明和费用清单等,同样对这些费用进行汇总,然后排序;在校消费情况中,给出每个申请人一卡通每月的平均消费金额、每顿饭的平均消费金额,全校学生一卡通每月平均消费金额、每顿饭的平均消费金额,然后进行排序;在校表现,给出学生的综合测评排名,获奖情况等。
4.4 结果分析
《教育部财政部关于认真做好高等学校家庭经济困难学生认定工作的指导意见》中指出,各地认定标准可设置特殊困难、困难和一般困难。因此本文根据实际需要,建立评语集V={V1,V2,V3,V4}={特殊困难、困难、一般困难、非困难}。
本文选20为资助工作的专家,根据提供的数据和数据分析的结果进行评议,以学生甲为例,由专家参照评价集进行评议并对评议结果进行统计,得出模糊矩阵如下:

根据最大隶属度原则,对照评语集,可认定甲同学为特殊困难。为了便于比较可给定一个评价等级C=(90 80 70 60),得到一个具体的标量值
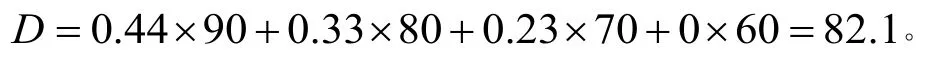
本文的研究可以得出如下结论:一是指标的真实性提高了,更具有参考价值;二是指标的选取都是一些可以进行处理分析的数据,大大提高了客观性,减少了人为的主观因素;三是这样的方法可以提高认定的精准度;四是根据评价的数值,可以从学校整体和学生的实际情况来认定贫困生,而不是按照班级比例分配名额来认定;五是根据此评价结果可以为贫困等级的确定提供可靠的参考依据。
