基于稀疏表示和特征加权的离格双耳声源定位∗
2019-12-04丁建策剑郑成诗李晓东
丁建策 厉 剑郑成诗 李晓东
(1中国科学院声学研究所噪声与振动重点实验室 北京 100190)
(2中国科学院大学 北京 100049)
0 引言
双耳声源定位利用耳道入口或者耳道内的传声器接收到的声信号来估计空间中声源的方位。它在虚拟声重放[1]、助听器[2]、智能音视频会议[3]等领域有着广泛的应用,研究双耳声源定位有着重要的科学意义和研究价值。
双耳声源定位算法中最常用的两种双耳特征分别为双耳时间差(Interaural time difference,ITD)和双耳声级差(Interaural level difference,ILD)。一般而言,ITD适用于中低频的声源定位,ILD适用于高频的声源定位。在Jeffress[4]提出双耳“巧合假说”模型(coincident theory)之后,研究者们提出了一系列双耳声源定位算法。常用的双耳声源定位算法有两类:一类是基于头相关传递函数(Head-related transfer function,HRTF)的双耳声源定位方法[5-6],另一类是基于机器学习的监督式双耳声源定位方法[7-8]。基于HRTF的双耳声源定位方法的一般做法是:提取观测双耳信号的双耳特征(如ITD、ILD等)和HRTF数据库中各个离散测量方位角对应的双耳特征,然后进行匹配定位。这类方法计算量小,适用范围广,然而在低信噪比或强混响环境下其定位性能会严重下降。监督式双耳声源定位方法通过机器学习方法训练声源方位角与双耳特征之间的关系,通常有着较高的定位准确率。这类算法需要预先构建训练数据库,训练过程计算复杂度高,而且在训练条件与测试条件不匹配的情况下定位性能会严重下降。本文重点研究基于HRTF的双耳声源定位方法。
在基于HRTF的双耳声源定位方法中,声源的方位角估计结果往往被限定在HRTF数据库的离散测量点上。当声源真实方位角与HRTF数据库的测量方位角不一致时,算法的定位性能会显著下降,这就是双耳声源定位中的离格问题。HRTF数据库的测量方位角间隔一般比较大(不小于5°),因此离格问题对基于HRTF的双耳声源定位算法的影响不可忽视。随着压缩感知技术的兴起,研究者们提出了一系列离格稀疏重建方法来解决阵列到达角(Direction of arrival,DOA)估计中的离格问题。2013年,Yang等[9]提出了稀疏贝叶斯学习(Sparse Bayesian learning,SBL)方法来解决窄带信号DOA估计中的离格问题。2017年,高阳等[10]提出了基于酉变换的实数域稀疏贝叶斯学习方法,有效降低了离格DOA估计方法的运算量。同年,胡顺仁等[11]提出了一种联合稀疏贝叶斯理论和子空间方法的近场声源定位算法,用于解决近场信号源的DOA估计问题。由于头和躯干的阴影效应的影响,双耳信号与阵列信号的声传播模型有所不同,因此上述这些离格阵列DOA估计算法都不能直接用于解决双耳声源定位中的离格问题。
为了解决双耳声源定位中的离格问题,本文提出一种基于加权宽带稀疏贝叶斯学习的离格双耳声源定位方法(Off-grid binaural sound source localization based on weighted wideband sparse Bayesian learning,WWSBL-OGBSSL)。首先建立离格双耳信号的稀疏信号模型,将离格双耳声源定位问题转化为一个凸优化问题,然后基于双耳相干与扩散能量比(Binaural coherent-to-diffuse power ratio,BCDR)特征对双耳信号的各个频点进行加权以降低噪声和混响的影响,最后利用加权宽带稀疏贝叶斯学习方法来估计离格声源的方位角。WWSBL-OGBSSL算法通过离格稀疏信号模型将声源方位角和测量方位角之间的偏离值作为估计参数进行迭代运算,有效提高了离格声源的方位角估计准确率。仿真和实际实验结果表明,和现有的基于HRTF的双耳声源定位方法相比,WWSBLOGBSSL算法在各种复杂的声学环境下都有着更高的定位精度和更强的鲁棒性,特别是提高了离格情况下的双耳声源定位性能。
本文常用的符号如下:x、xT和xH分别表示x的共轭、转置和共轭转置;AP×Q表示一个P×Q的矩阵,0P×Q表示P×Q的全零矩阵,IP表示一个P×P的单位矩阵,diag(x)表示一个对角矩阵,其对角线的元素与向量x的元素相同;tr(A)表示矩阵A的迹,(A)ij表示矩阵A中的(i,j)元素值。‖AP×Q‖1和‖AP×Q‖22分别表示AP×Q的L1范数和L2范数;C表示复数集。
1 信号模型
1.1 离格双耳信号的稀疏表示模型
假设s(n)为点声源,xl(n)和xr(n)分别为左右耳传声器采集到的声信号。研究表明,声源到双耳内传声器的房间传递函数与声源到传声器的距离、声源的方位角和俯仰角密切相关[12]。本文只考虑远场声源水平面方位角定位问题,此时双耳信号xl|r(n)(xl(n)或xr(n))可表示为
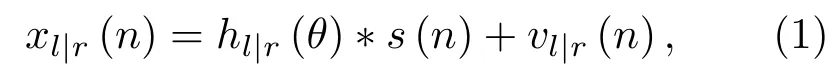
其中,“∗”为卷积运算符,hl|r(θ)为声源到达左右耳(左耳或右耳)传声器的房间脉冲响应,θ为声源的方位角,vl|r(n)为左右耳传声器接收到的环境噪声。在频域中,式(1)可表示为
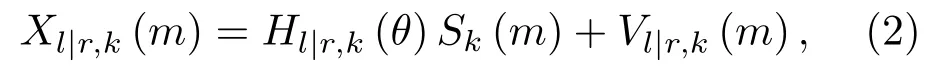
其中,Xl|r,k(m)、Hl|r,k(θ)、Sk(m)、Vl|r,k(m)分别为xl|r(n)、hl|r(θ)、s(n)、vl|r(n)第m帧NSTFT点短时傅里叶变换(Short-time Fourier transform,STFT)第k个频率分量,k∈{0,1,···,K-1},K为频点总数。
声源方位角θ对应的导向矢量可定义为ak(θ)=[Hl,k(θ)/Hr,k(θ),1]T,那么式(2)可近似为
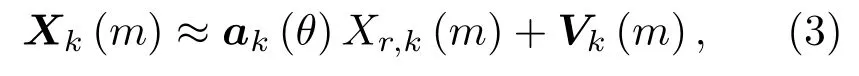
其中,Xk(m)=[Xl,k(m),Xr,k(m)]T,Vk(m)=[Vl,k(m),Vr,k(m)]T。
假设HRTF数据库在人工头前半水平面内包含J个等间隔分布的测量方位角,为方位角间隔为δ。若声源方位角θ满足且那么该声源为在格声源,对应的双耳信号为在格双耳信号;{若声源方位角θ位}于测量方位角之间,即,那么该声源为离格声源,对应的双耳信号为离格双耳信号。利用HRTF数据库中的头相关脉冲响应(Head-related impulse responses,HRIRs)可计算出每个测量方位角对应的导向矢量由此双耳声源定位中的字典矩阵可表示为

其中,bk(θp)为ak(p)的一阶偏导数。定义一个偏导数矩阵和一个偏移矢量其中,
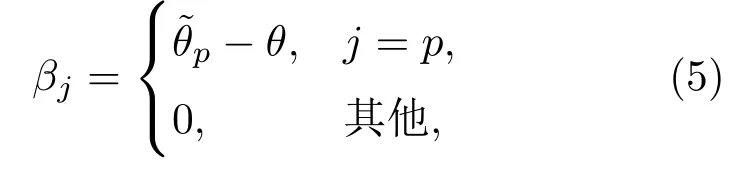
那么包含离格偏移参数的离格字典矩阵可表示为

进一步定义一个稀疏系数向量Yk(m)=其中,
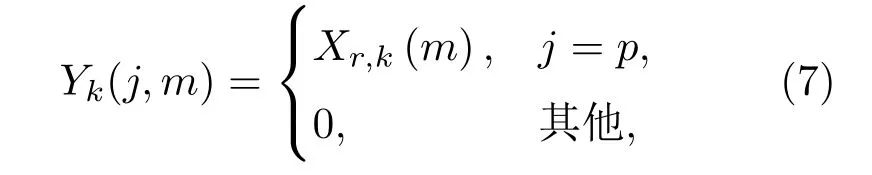
那么,离格双耳信号的稀疏表示模型为

由于声源方位角θ为未知量,因此稀疏系数向量Yk(m)和方位角偏移矢量β都是未知量。基于声源的空间稀疏性,可将式(8)中的离格声源方位角估计问题转化为一个凸优化问题,并通过稀疏重建方法[13]估计Yk(m)和β。离格声源方位角估计问题可简化为
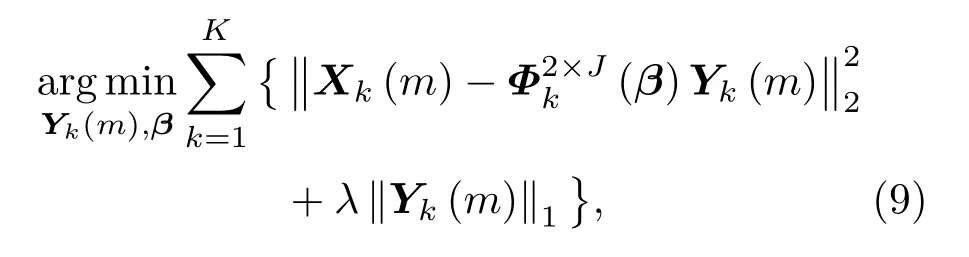
其中,λ为常量,表示拉格朗日乘子。
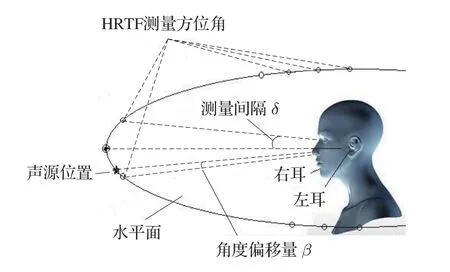
图1 离格双耳声源定位示意图Fig.1 Off-grid binaural sound source localization
1.2 导向矢量模型
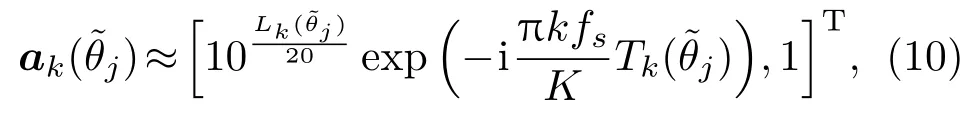
其中,fs为信号采样率,为虚数单位。根据文献[5],和与测量方位角之间的关系可近似为以下参数模型:

其中,ξk和ςk为与频率有关的参数,d为双耳内传声器之间的距离,c为空气中的声速。ξk和ςk可通过最小均方(Least square,LS)算法计算得出[5]。将式(11)和式(12)代入到式(10)中,并对其求导,可得
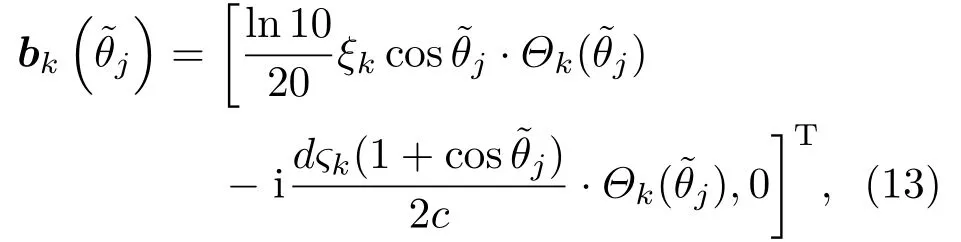
1.3 基于双耳相干与扩散能量比的加权方法
与现有的基于HRTF的双耳声源定位算法类似,若直接采用稀疏重构方法求解式(9)中的离格双耳声源定位问题,那么算法的性能在噪声或混响条件下会显著下降[5-6]。研究表明,利用双耳相干与扩散能量比(BCDR)特征对各频点双耳特征进行加权处理可以明显提高噪声或混响条件下双耳声源定位算法的性能[14-15]。因此本文进一步提出利用BCDR特征对各个频点的双耳信号进行加权以降低噪声和混响的影响。
在一般声场中,双耳信号可以分为相干信号成分xl|r,ss(n)和扩散信号成分xl|r,dd(n)。在BSSL中,声源角度是未知量,因此本文根据双耳信号xl|r(n)的相干函数Γxx,k(m)和扩散信号xl|r,dd(n)的相干函数Γdd,k(m)来估计BCDR。xl|r(n)的相干函数Γxx,k(m)可以表示为

其中,(·)∗表示取共轭,E{·}为期望函数。Lindevald等[16]的研究表明,远场条件下房间内xl|r,dd(n)的相干函数Γdd,k(m)与帧数m无关,可以近似为

其中,fk=k·fs/2(K-1)。那么BCDR的无偏估计公式为[17]

其中,R{·}表示取实部。定义加权系数Wk(m)为


2 基于加权宽带稀疏贝叶斯学习的离格双耳声源定位算法
在多测量矢量(Multiple measurement vector,MMV)模型下,本节推导加权宽带稀疏贝叶斯学习算法(WWSBL),用于解决式(18)的凸优化问题,从而实现离格声源方位角的估计。
在MMV模型下,经过特征加权后的离格双耳信号的稀疏表示模型为

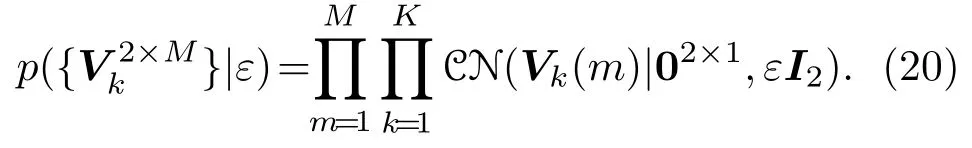
为了估计稀疏系数矩阵YJ×M k和方位角偏移矢量β,需要已知二者的先验概率分布。在高斯混合模型下,假设每帧信号各个频率分量对应的稀疏系数向量Yk(m)相互独立,且符合同一复高斯分布Yk(m)~CN(0J×1,ΛJ×J),其中,协方差矩阵ΛJ×J=diag(α)为一个对角矩阵,α=[α1,···,αj,···,αJ]为Yk(m)中各个元素的方差。根据高斯分布的性质,αj的先验概率分布可假设为独立同分布的Gamma分布。稀疏系数矩阵以及α的先验概率密度函数可表示为
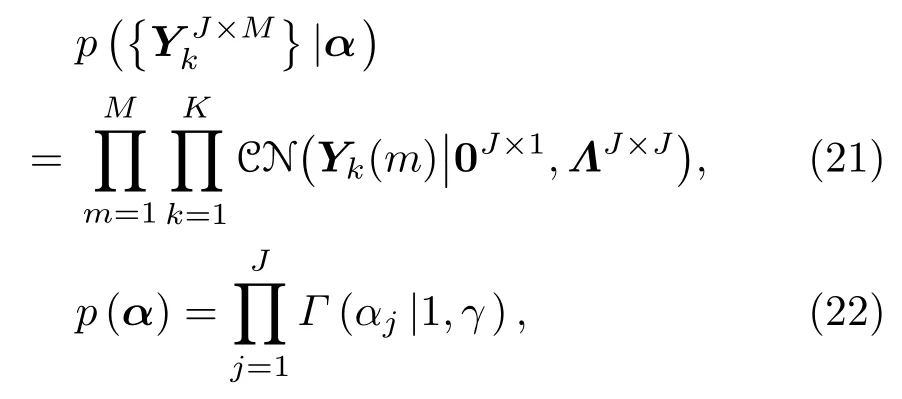
其中,γ为Gamma分布的参数。方位角偏移矢量β中各个元素的先验分布可假设为相互独立的均匀分布,那么β的先验概率分布可表示为

综上,WWSBL算法中的待估参数如下:

根据文献[9],式(24)中的模型参数可通过期望最大化(Expectation maximization,EM)算法进行求解。WWSBL中的EM算法将稀疏系数矩阵作为一个隐含变量处理,即优化过程中不再出现而将参数α和偏移向量β作为优化对象,通过最大化
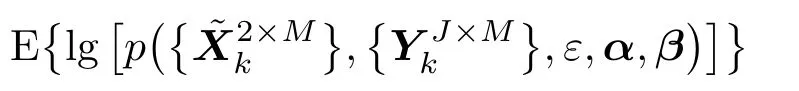
来估计各个参数的最佳值。各个参数的迭代更新公式如下:
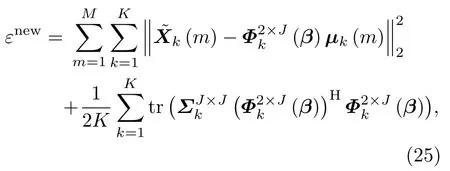

其中,µk(m)和ΣJ×Jk分别为Yk(m)后验概率分布的均值和方差,可通过高斯混合模型推导计算出来。每次迭代中,更新了参数ε和α之后,再更新偏移向量β。假设αnew的第jopt个元素为αnew的最大值,那么只更新β的第jopt个元素,其他元素保持不变。偏移向量β的更新公式如下:
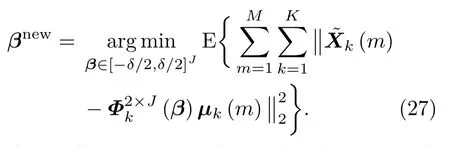
偏移向量β的更新公式无法用显式表达,可以通过遍历法得到最优解。
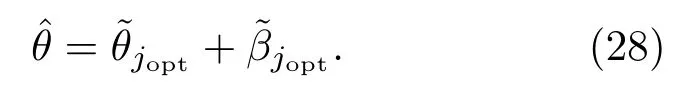
3 实验结果及分析
本文分别在仿真和实际声学环境下对WWSBL-OGBSSL算法的性能进行了测试。3.1节测试了本文算法在自由场环境下的双耳声源方位角估计性能,3.2节测试了本文算法在噪声环境下的方位角估计性能,3.3节测试了本文算法在混响环境下的方位角估计性能,3.4节测试了本文算法在实际环境下的方位角估计性能。
在自由场环境和噪声环境下,实验中的双耳信号是由HRTF数据库中的HRIRs卷积纯净语音信号生成。本文选用的HRTF数据库为MIT HRTF数据库[18],纯净语音信号选自TIMIT数据库[19]。由于只考虑声源水平角的估计,因此本文算法只采用了HRTF数据库中前半水平面的HRIRs数据。本文将生成的双耳信号分帧加窗后,提取ILD、ITD等双耳特征。双耳信号的采样率为16 kHz,帧长为32 ms,帧移为16 ms,窗函数采用汉明窗。由于MIT HRTF数据库使用的KEMAR人工头半径为7.6 cm,因此本文将ITD特征的取值范围限定为[-1,1]ms,同时将ILD特征的取值范围设定为[-40,40]dB。空气中的声速为343 m/s。
本文选取两种现有的基于HRTF的双耳声源定位方法与WWSBL-OGBSSL算法作对比,分别为Finger等[6]提出的在线校准(Online calibration,OC)算法和Liu等[20]提出的双耳匹配滤波器(Interaural matching filter,IMF)定位算法。本文中声源方位角估计的均方根误差(Root mean square error,RMSE)定义如下:
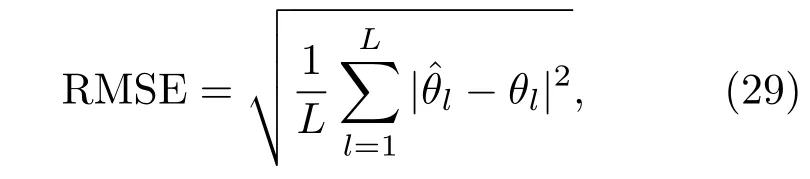
其中,L为双耳信号数据段总数,θl为第l个数据段的声源真实方位角,为对应的声源方位角估计值。声源方位角的估计准确率(Accuracy,Acc)定义如下:
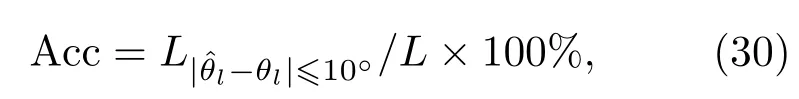
其中,L|ˆθl-θl|≤10°为方位角估计误差不大于10°的数据段总数。
3.1 自由场环境下的双耳声源定位实验
本小节通过仿真实验测试WWSBL-OGBSSL算法在自由场环境下的方位角估计性能。在前半水平面内,MIT HRTF数据库包含37个方位角的HRIRs,分别为{-90°,-85°,···,85°,90°},方位角间隔为5°。为了仿真在格声源和离格声源的情况,可假设˜θ={-90°,-80°,···,80°,90°}为所有的测量方位角,这些方位角对应的HRIRs数据用于生成在格双耳信号,其余18个方位角的HRIRs数据用于生成离格双耳信号。测量方位角共有19个,方位角间隔δ=10°。在每个方位角下,随机选取TIMIT数据库的400句语音信号仿真生成400句自由场环境下的双耳信号。首先将每个双耳信号分成时长为1 s的数据段,并对每段双耳信号分帧,然后基于语音端点检测(Voice activity detection,VAD)算法去除非语音帧数据。分别采用OC算法、IMF算法和WWSBL-OGBSSL算法对每段信号进行声源方位角估计。每段信号中语音帧的总数即为WWSBLOGBSSL算法中MMV模型的快拍数。自由场环境下的加权系数Wk(m)恒为1。图2给出了自由场环境下三种算法对在格声源和离格声源的方位角估计均方根误差(RMSE)曲线图,“on-grid”和“off-grid”分别表示在格声源和离格声源,“Proposed”表示WWSBL-OGBSSL算法。
从图2中可以看出,WWSBL-OGBSSL算法对在格声源的定位性能稍优于OC算法和IMF算法,对离格声源的定位性能明显优于OC算法和IMF算法。这是因为OC算法和IMF算法的方位角估计结果被限定在了离散测量方位角上,而WWSBLOGBSSL算法通过迭代估计出离声源真实方位角最近的测量方位角和二者之间的偏移量,估计结果可能为声源真实方位角附近的任意值。OC算法和IMF算法对在格声源的方位角估计误差为{0°,10°,20°,···},对离格声源的方位角估计误差为{5°,15°,25°,···},最小估计误差为5°;而WWSBLOGBSSL对在格声源和离格声源的方位角估计误差都可以为任意小的值,在理想情况下误差可以降至0°,因此WWSBL-OGBSSL算法可以显著提高离格条件下的双耳声源方位角估计性能。
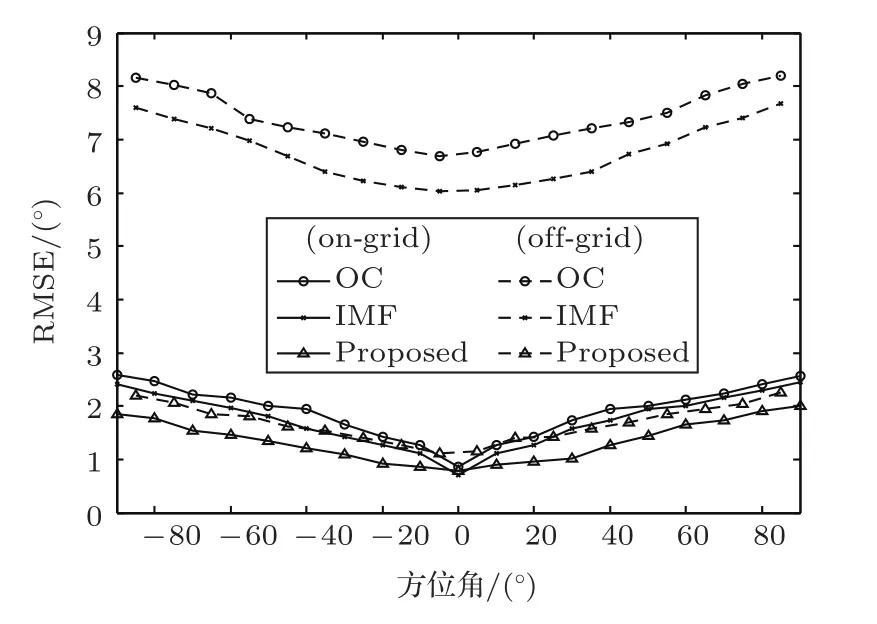
图2 自由场环境下三种算法对在格声源和离格声源的方位角估计的RMSE曲线Fig.2 The RMSE of azimuth estimation of the OC,the IMF,the WWSBL-OGBSSL methods for the on-grid sound sources and the off-grid sound sources
3.2 不同噪声环境下的双耳声源定位实验
本实验主要测试了WWSBL-OGBSSL算法在不同信噪比下的方位角估计性能。为了模拟噪声环境,本实验在3.1节自由场环境下生成的双耳信号中加入扩散场噪声,生成带噪双耳信号。本实验中在格双耳信号的声源方位角为-30°,离格双耳信号的声源方位角为25°,其他实验条件与3.1节相同。扩散场噪声是由MIT HRTF数据库中72个水平面方位角的HRIRs卷积高斯白噪声后叠加生成的。带噪双耳信号的信噪比(Signal-to-noise ratio,SNR)设定为0 dB到30 dB,间隔为10 dB。本实验采用方位角估计准确率指标来衡量三种算法对在格声源和离格声源的方位角估计性能。图3给出了不同信噪比下三种算法对在格声源和离格声源的方位角估计准确率。
从图3中可以看出,在不同的噪声环境下,WWSBL-OGBSSL算法对在格声源的方位角估计准确率比OC算法和IMF算法高出3%~15%,对离格声源的方位角估计准确率比OC算法和IMF算法高出5%~20%。特别是在信噪比为0 dB时,WWSBL-OGBSSL算法对在格声源和离格声源的方位角估计准确率分别比OC算法和IMF算法高出15%和20%左右。值得注意的是,OC算法和IMF算法对离格声源的最小估计误差为5°,WWSBLOGBSSL算法对离格声源的最小估计误差理论上可达到0°。WWSBL-OGBSSL算法基于BCDR特征对各个频点进行加权,将扩散场噪声占主要成分的频点去除,降低扩散噪声对方位角估计性能的影响,有效提高了双耳声源方位角估计准确率;同时WWSBL-OGBSSL算法基于各频点信号能量优化模型参数,能量强的频点具有更大的权重,从而进一步提高了噪声环境下的方位角估计准确率。
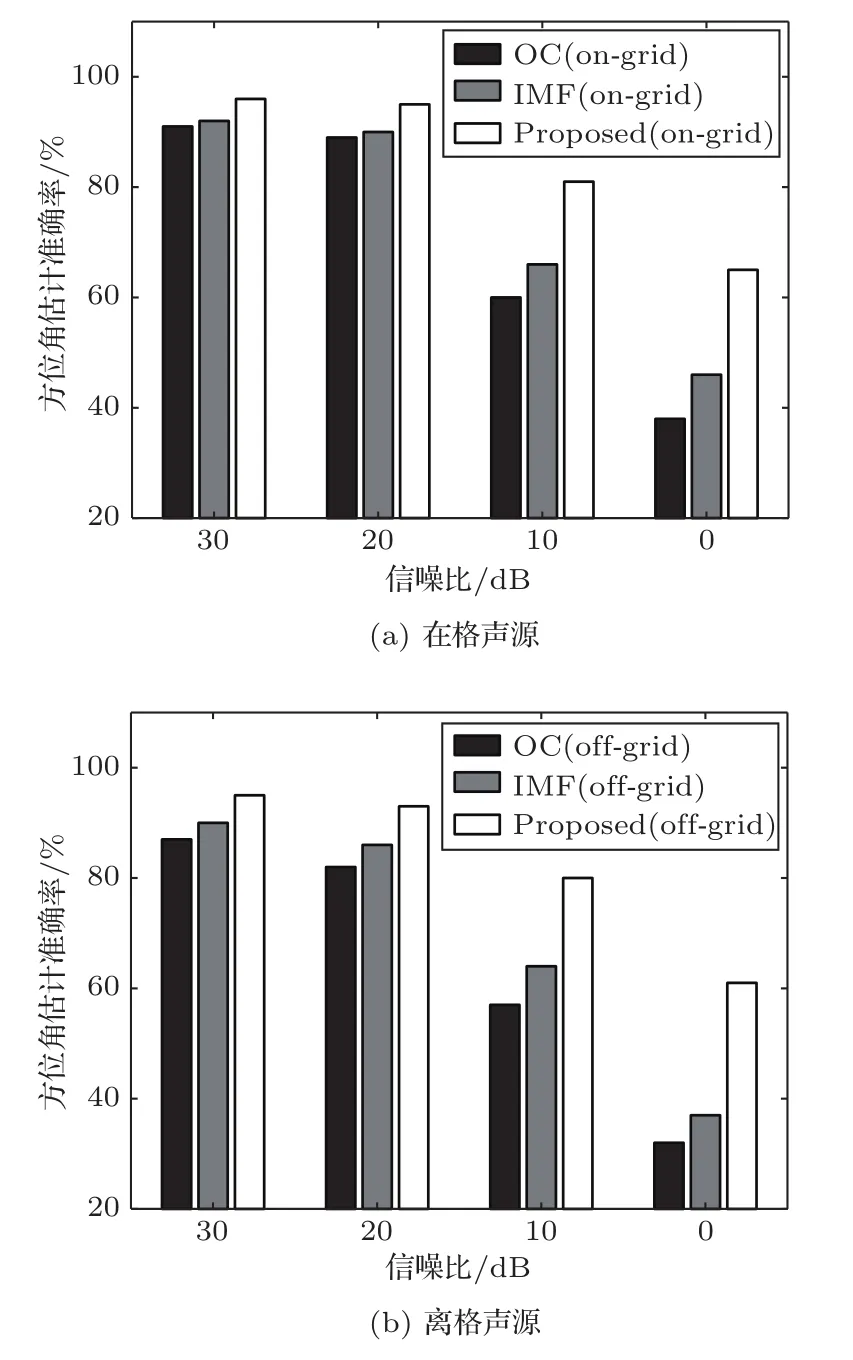
图3 不同信噪比下OC算法、IMF算法和WWSBL-OGBSSL算法的方位角估计准确率Fig.3 The azimuth estimation accuracies of the OC,the IMF,the WWSBL-OGBSSL methods under different SNRs
3.3 不同混响环境下的双耳声源定位实验
本小节通过仿真实验测试了WWSBLOGBSSL算法在不同混响条件下的方位角估计性能。双耳信号是由不同混响条件下的双耳房间脉冲响应(Binaural room impulse responses,BRIRs)卷积纯净语音信号生成。不同混响条件下的BRIRs是由MIT HRTF数据库中的HRIRs经镜像法[21]模拟生成。混响时间分别设定为100 ms到600 ms,间隔为100 ms。本实验中在格双耳信号的声源方位角为-30°,离格双耳信号的声源方位角为25°。图4给出了不同混响条件下三种算法对在格声源和离格声源的方位角估计准确率。

图4 不同混响条件下OC算法、IMF算法和WWSBL-OGBSSL算法的方位角估计准确率Fig.4 The azimuth estimation accuracies of the OC,the IMF,the WWSBL-OGBSSL methods under different reverberation times
从图4中可以看出, 在不同混响条件下,WWSBL-OGBSSL算法对在格声源和离格声源的方位角估计准确率比OC算法和IMF算法高出2%~15%。随着混响增大,OC算法和IMF算法的方位角估计性能都会严重恶化,这是因为混响情况下,由于房间反射,在格双耳信号和离格双耳信号的双耳特征(ILD、ITD等)与自由场环境测量的HRTF数据库中提取的双耳特征严重不匹配。WWSBL-OGBSSL算法基于BCDR对各个频点的双耳信号进行加权,将混响占主要成分的频点去除,有效降低了混响对方位角估计性能的影响;而且WWSBL-OGBSSL算法基于各频点的能量对各个参数迭代更新,能量强的频点会有更大的权重,因此在混响条件下WWSBL-OGBSSL算法的方位角估计性能更优。
3.4 实际环境下的双耳声源定位实验
本小节通过实际实验测试了WWSBL-OGBSSL算法在实际环境下的方位角估计性能。本文在一个铺设有吸声材料的房间内采用B&K 4128人工头采集双耳信号。房间的大小约为6.4 m×4.8 m×2.8 m,混响时间约为T60≈350 ms,混响半径r0≈1.60 m。声源位于人工头的水平面上,距人工头的距离为1.80 m,真实方位角分别为{-90°,-85°,···,85°,90°},方位角间隔为5°。在每个方位角处,随机选取TIMIT数据库的200句语音信号作为声源信号,采集200句双耳信号。假设˜θ={-90°,-80°,···,80°,90°}为HRTF数据库中所有的测量方位角,那么当声源真实方位角θ∈{-90°,-80°,···,80°,90°}时,声源为在格声源,当声源真实方位角θ∈{-85°,-75°,···,75°,85°}时,声源为离格声源。将每个双耳信号划分为时长为1 s的双耳信号数据段,然后分别采用OC算法、IMF算法和WWSBL-OGBSSL算法估计每段信号的方位角。图5给出了实际环境下三种算法对在格声源和离格声源的方位角估计准确率。
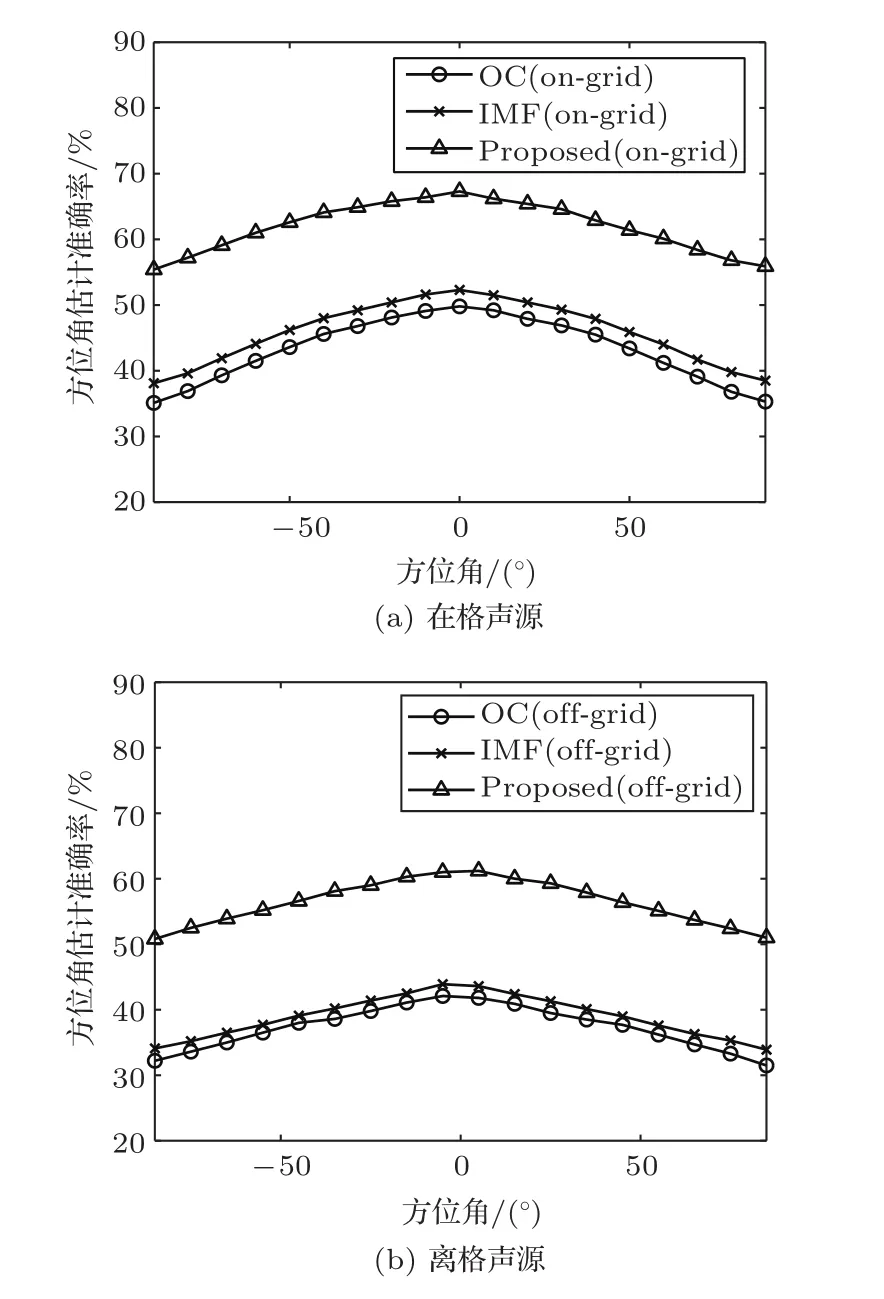
图5 实际环境下OC算法、IMF算法和WWSBLOGBSSL算法的方位角估计准确率Fig.5 The azimuth estimation accuracies of the OC,the IMF,the WWSBL-OGBSSL methods in real environments
从图5中可以看出,在实际环境下WWSBLOGBSSL算法对在格声源和离格声源的方位角估计准确率比OC算法和IMF算法高出15%左右。这是因为WWSBL-OGBSSL算法基于BCDR对各个频点进行加权,去除了受混响影响比较严重的频点的双耳信号,有效降低了混响的影响;而且WWSBL-OGBSSL算法中能量高的频点有着更大的权重。另外,从图5中可以看出三种算法对人工头正前方声源的方位角估计性能明显优于人工头两侧声源的方位角估计性能,这是因为人工头正前方声源方位角的变化对双耳信号双耳特征的影响更显著,因此定位性能更好。
4 结论
针对双耳声源定位中的离格问题,提出了基于加权宽带稀疏贝叶斯学习的离格双耳声源定位算法(WWSBL-OGBSSL)。首先,该算法基于压缩感知理论建立了离格稀疏双耳信号模型,将离格双耳声源定位问题简化为一个凸优化问题,并采用双耳相干与扩散能量比特征对各个频点进行加权以降低噪声和混响的影响,然后通过加权宽带稀疏贝叶斯学习方法来估计模型参数,最终实现离格声源方位角估计。与现有的离格阵列DOA估计算法相比,离格双耳声源定位算法既考虑了离格问题的影响,也考虑了头和躯干的阴影效应的影响。仿真和实际实验结果表明,本文算法在各种声学环境下都有着更高的定位精度和更强的鲁棒性,特别是提高了离格条件下的双耳声源方位角估计性能。
