基于YOLO和排斥力损失函数的行人检测方法
2019-12-04周莉莉叶智慧张静敏
周莉莉,段 鹏,叶智慧,张静敏
(云南民族大学 数学与计算机科学学院,云南 昆明 650000)
行人检测(pedestrian detection)是计算机视觉领域的一个关键问题,它往往作为无人驾驶、智能监控和行人行为分析等应用的基础.但是由于行人外观易受穿着、姿态以及遮挡等问题的影响,导致目前的行人检测算法无法在兼顾速度的同时达到较高的准确率,使得行人检测一直都是计算机视觉研究领域的难点与热点.
目前,针对行人检测的方法主要分为3类:一是基于背景建模的方法,主要有高斯混合模型、ViBe算法[1]、光流法[2]等,这些算法的思路主要是通过连续的帧学习得到一个背景模型,然后分析当前帧中运动目标相对于背景的差异,最终确定运动目标所在的位置.但是当运动目标之间有重叠或是被遮挡时,背景建模的方法无法区分不同的目标,从而导致目标检测失败.二是基于机器学习的方法,主要有:Navneet 等[3]在2005年提出的基于HOG + SVM 的行人检测算法,在得到候选区域的HOG 特征后,利用线性支持向量机分类器对该区域进行分类,从而确定行人位置.Felzenszwalb 等[4]提出了一种基于组件的检测算法DPM,在检测中使用HOG特征,针对行人不同部位的组件进行独立建模,并结合鉴别能力很强的latent-SVM 分类器,在人体检测中取得了很好的效果.这些算法虽然运行速度较快,但是精度较低,尤其是行人存在姿态变化较大或者遮挡问题时,会导致大量的误检和漏检.由于深度学习提取的特征具有很强的表达能力和很好的鲁棒性,使得基于深度学习的行人检测算法成为当前的主流.Angelova等[5]提出了一种利用级联卷积网络进行行人检测的方法,前面简单的卷积网络可以快速排除掉大部分背景区域,后面复杂的卷积网络用于判断一个候选窗口是否为行人,通过组合在保证检测精度的同时极大的提高了检测速度.Wang 等[6]提出了一种专门为人群场景设计的新型边界框回归损失函数,称为排斥力损失函数,通过实现对目标的吸引力以及对其他周围物体的排斥力,从而有效解决了行人的遮挡问题.同时一部分研究者直接使用目标检测的算法来进行行人检测,也取得了很好的效果.Redmon等[7]提出的YOLO模型将目标检测作为一个回归问题,从单个神经网络中一步直接从完整图像预测目标边界框,并采用了新颖的多尺度训练方法,实现了又快又好的目标检测.
本文为了能够实现快速且准确地行人检测,采用目前性能最好的YOLO模型作为基础检测器并对其进行改进,使其能够更好地检测行人,同时引入Repulsion loss函数来处理遮挡问题,从而实现快速准确地行人检测.
1 方法概述
本文提出了一种结合YOLO模型和排斥力损失函数的行人检测方法,用于快速准确地检测行人,从而满足目前计算机视觉实际应用的需求.与现有方法相比,该方法将改进的YOLO模型和排斥力损失函数结合起来,实现了快速且准确地行人检测.如图1描述了本文的算法流程:首先,对YOLO模型进行改进,并利用公开的行人数据集进行模型训练;然后将测试图像输入训练所得的行人检测模型,获得初步的行人预测框;最后,结合排斥力损失函数对预测框进行排斥力计算,得到最后的行人检测结果.
2 改进的YOLO模型
2.1 YOLO网络
YOLO算法采用一个单独的CNN模型实现端到端的目标检测,整个系统如下图2所示:首先将输入图片调整大小到448×448,然后送入CNN网络,最后处理网络预测结果得到检测的目标.相比与其它基于CNN的目标检测算法,YOLO模型的框架统一且速度更快.


YOLO网络将输入之后经过重新调整大小的图像分成S×S个网络,如果行人的中心落入某个网格单元,则该网格单元负责检测该行人,每个网格单元预测出行人的边界框和对应的置信度分数.如果该单元格中不存在行人,则置信度分数为0;反之,如存在行人,这里我们定义置信度分数为预测框与地面实际位置的交并比(IOU)距离,即公式为:
(1)
其中,P(pedestrian)为预测框包含行人的概率.
2.2 YOLO模型的改进
YOLO是目标检测领域中表现突出的算法,为了适用于行人检测,这里我们进行了一些改进,使其更加适合行人检测的应用背景.
首先,在训练开始时设置人工选取的预选框.因为预选框选取的好坏会影响网络的学习速度,并且不同的数据集中目标真实边框的位置以及大小均有一定的差.这里需重新定义训练标签:
(2)

其中pc表示是否有目标,若有目标行人,则由(3)给出边界框坐标bx、by、bh、bw:
(3)
其次,我们考虑改进特征提取策略,主要是重新设计网络,采用类似SSD[8]的多尺度检测策略,主要是将其按照尺度大小均分为3个尺度.
尺度1 在基础网络之后添加一些卷积层再输出box信息.
尺度2 从尺度1中的倒数第二层的卷积层上采样再与最后一个16×16大小的特征图相加,再次通过多个卷积后输出 box 信息,相比尺度1变大两倍.
尺度3 与尺度2类似,使用了 32×32 大小的特征图
苜蓿与禾草2∶1混播禾草的抗氧化酶(SOD、POD)活性最低。单播苜蓿和2∶1混播苜蓿具有较低的抗氧化酶活性。
最后,使用改进的YOLO模型在ETH行人数据集上重新训练行人检测模型,最后得到初步的行人检测结果,即Pc=(xPc,yPc,wPc,hPc).
3 排斥力损失函数计算
在行人检测的实际应用场景中,行人往往会属于不同的群体,此时群体之中的行人会存在相互遮挡的情况,因此如何处理相互遮挡遮挡问题成为行人检测研究中的重点和难点.本节主要受Zhang[9]、Wang[6]、Zhang[10]等对行人检测中遮挡问题研究的启发,考虑从优化的角度来解决行人之间的相互遮挡问题.
由改进的YOLO行人检测模型所得的初步检测结果Pc=(xPc,yPc,wPc,hPc),其中x和y为检测框的左下顶点坐标,w和h为右上顶点的坐标,并且为检测框的高度和宽度.接下来我们会进行进一步的优化,这里的优化我们定义为排斥力损失计算,主要有两个方面组成:
Lu=α×LX+β×LP,
(4)
其中吸引项LX使得初步预测框和已匹配上的目标框尽可能接近,排斥项LP使得初步预测框远离其他行人的预测框.系数α和β作为平衡辅助损失的权重.
设P=(lp,tp,wp,hp)和G=(lG,tG,wG,hG)为预测框和其它目标框.则两个函数模块如下所述.
3.1 吸引力损失Lx
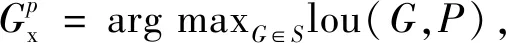
(5)
其中P+={P}是所有预测框的集合,BP是从行人初步检测框P回归的预测框.
3.2 排斥力损失LP
NMS是大多数行人检测框架中必要的后处理步骤,用于合并同一对象的主要预测边界框.然而对于人群密集的情况下,NMS会导致检测结果出现大量漏检和误检.为了使检测器对NMS不那么敏感,进一步提出了排斥力损失LP,其目的是排斥其它不同行人的检测框.LP使得预测框Pi和周围的其他预测框Pj尽可能远离,Pi和Pj分别匹配上不同的目标框,它们之间的距离采用的是IoU距离,则排斥力损失LP定义为:
(6)
其中,BPi和BPj是从行人初步检测框Pi和Pj回归的预测框,ε为防止除数为零而设置的小常数.从上式可以发现当行人预测框Pi和周围的其他预测框Pj的IoU距离越大时,则产生的loss也会越大,因此可以有效防止两个预测框因为靠的太近而被NMS过滤掉,进而减少漏检.
最终经过排斥力损失的计算,可以由最初的检测结果Pc=(xPc,yPc,wPc,hPc),得到最后的检测结果Pz=(xPz,yPz,wPz,hPz).
4 实验结果与分析
4.1 实验设置
本文在CPU Intel i9-9900k、GPU 2080ti、内存32G的PC机,以及python 3.6、pytorch 0.4.0的软件环境下进行相关实验.采用ETH行人数据集[11]中的3个序列(pedcross 2、linthescher、bahnhof)来进行实验,这些序列主要包含了行人检测中的主要挑战,包括严重遮挡、光照变化等问题.为了验证方法的有效性,我们将其与现有主流的3种目标检测算法进行对比分析.具体见4.2节.
4.2 实验结果分析
分别从3组图像序列来分析本文方法的有效性,其中主要包括严重遮挡、光照变化等问题.具体实验结果如图4所示:

图4 实验结果
由上面的实验结果可以看出,本文提出的算法在ETH数据集的3个序列(pedcross 2、linthescher、bahnhof)中表现良好,表明改进的行人检测算法在没有增加较多运行时间的同时,更好地解决了行人相互遮挡问题,从而提高了行人检测的精确度.
4.3 对比分析
本文采用文献[12]提出的3个指标来衡量算法的质量:平均准确率(average precision,AP)每秒传输帧数(frames per second,FPS).
主要是对传统的HOG+SVM,原始的YOLO模型以及本文的方法进行对比实验.测试结果如表1所示.

表1 本文方法与其它方法对比结果
通过对比可知,本文基于YOLO和排斥力损失函数的行人检测方法与传统的HOG + SVM 检测方法、以及原始的YOLO检测方法相比,不仅在准确率上有提高,而且在检测速率的上也有小幅提升,实现了快速准确地行人检测.
5 结语
本文针对行人检测中的若干挑战性问题展开研究,提出一种基于YOLO和排斥力损失函数的行人检测方法.该方法分为3个模块:基于改进的YOLO模型的行人检测模块;使用排斥力损失函数的检测优化模块.通过两个模块的有机结合,使本文方法很好地处理了严重遮挡、光照变化等问题.基于大量行人数据集序列的实验结果表明:与现有主流行人检测方法相比,在多种检测挑战情况下,本文方法的检测结果具有更高的精确度,并具有较好的实时性,说明本文方法能够更高效地处理行人检测中的挑战,提供更快更准确的检测结果.但是由于本文方法没有专门针对行人预测框进行阈值设定,导致一些无意义的检测结果,下一步我们将对行人预测框进行专门处理,在保证精确度的同时进一步提高算法运行效率.
