Lucene架构下布尔查询的执行计划研究
2019-12-04赵广
赵 广
(武汉体育学院 体育工程与信息技术学院,湖北 武汉 430079)
Lucene[1]是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,提供了完整的查询引擎和索引引擎.Lucene分别通过索引器和检索器来实现2大核心功能,即创建索引和检索索引.创建索引是使用分词器对源数据进行处理,把关键词提取出来,利用倒排索引技术和增量索引方式生成索引库的过程;检索是对索引库的逆操作,用户的检索请求,通过分词器分词,生成检索关键词,与索引库中的词典进行比对,取出命中词的倒排表,进行打分、合并与排序,将结果返回给用户[2].
在全文检索应用中,布尔查询凭借精确和高效的特性被广泛采用,如百度、谷歌、中国知网.布尔查询语句往往同时混合了多种布尔操作,如AND、NOT、OR,其表达式相对繁琐,对大多数用户来说,理解并灵活应用布尔表达式来精确定义检索请求是很不容易的.因此,深入研究布尔查询的执行逻辑,对于灵活应用布尔查询逻辑,并实现检索功能的优化具有十分重要的意义.
布尔查询也是Lucene检索功能的主要实现方式,学者对其执行计划的研究极少.文献[3]研究了在Lucene环境中,复杂布尔查询文档搜集和打分策略的优化方法,并设计了一种性能回归预测机制;文献[4]研究数据集成中的布尔查询的改写问题,给出了两种改写处理的方法,并证明了方法的可靠性;文献[5]通过实验深入研究了SQL的执行计划.这些文献,虽然不是对布尔查询执行计划的直接研究,但具有极强的借鉴意义.本文利用这些方法或思路,在Lucene架构下,首先深入研究布尔查询的执行计划,包括表示方式、查询解析、执行时序,运算规则等,然后对布尔查询进行剖析,提出布尔查询表达式构建的优化规律和交换律,并通过实验模拟进行验证.
1 布尔查询
在全文检索应用中,布尔查询,是指在查询词项上通过布尔操作符(与非或)构建出查询表达式,从而表达用户希望文档所具有的特征[6].在Lucene框架下,无论是一框式搜索,还是高级查询器,都可以转化为布尔查询.布尔查询也可以多层嵌套,一个布尔查询可以作为另一个布尔查询的子句,具有嵌套关系的布尔查询称为复杂布尔查询.
1.1 布尔查询的表示
绝大部分的应用中,布尔查询语法都是使用AND、NOT、OR和括号来连接查询关键词,如:(xORy)AND (uORz),其中x,y,u,z为查询关键词.在Lucene中,布尔查询采用了全新的表示方式,假设有以下查询项:a,b,c,d,e,f,需要检索满足条件的文档表示如下:
Q=(+a-(+c-d)-b+(ef)).
(1)
则Q是一个典型的布尔查询,其中a,b,c,d,e,f可以是原子查询,也可以是查询子句.子查询的布尔关系有3种,如表1所示,假设a为一个Term.

表1 布尔关系表
1.2 执行计划分析
执行计划即为布尔查询在检索过程中的执行方案.在Lucene中,即为根据布尔查询语句从索引库中读出倒排表、合并倒排表,得到结果文档集并对文档打分的过程.Lucene的布尔查询执行的过程复杂而又高效.
1.2.1 布尔查询执行的时序图
索引器是Lucene实现检索功能的组件,对于输入的布尔查询语句,将转换为Query对象树,检索执行的时序如图1所示.
通过分析Lucene文档及跟踪源代码可得:Weight对象树,用于计算词的权重;构造Scorer对象树,用于计算检索词的打分;在构造Scorer对象树的过程中,其叶子节点会将词典和倒排表从索引中读出来;倒排表合并及打分由SumScorer对象树来实现,此步将倒排表合并后得到结果文档集,并计算最终得分,将收集的结果集及分值返回给用户.倒排表的合并及打分,需要读取文档对象,因此需要IO操作,这个过程是查询主要耗时点.Lucene中采用迭代器来实现结果集的收集,而不是一次性全部读入.对结果集的大小取舍,直接决定着查询效率.
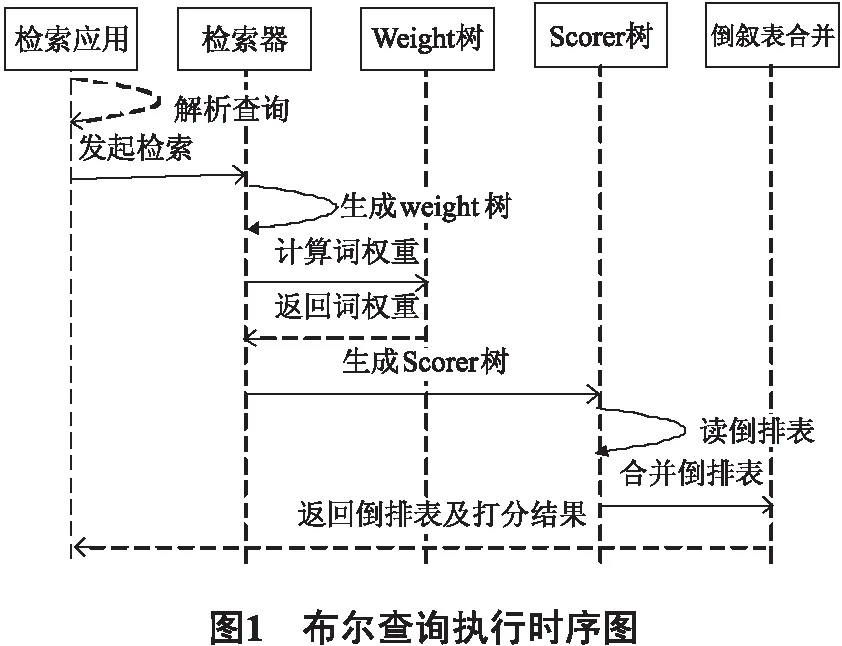
1.2.2 布尔查询的解析
从时序图可以看出,对于一个布尔查询的解析并生成Query对象树是执行计划的第一步.对于式(1)表示的查询,可以解析为如图2所示的查询树.每一个子树被称为一个子查询.


Query对象树的每一个叶子节点为一个查询Term,也称为原子查询,该Term直接在索引词典中进行匹配运算,从而获取含有该Term的文档倒排列表.各个子查询的结果合并即为倒排表合并,对于Query对象树,Lucene采取先合并子树,然后子树与子树再进行合并,直到根,这个过程如图3所示.
1.2.3 布尔子查询的运算规则
Query对象树子查询的合并是典型的逻辑运算,但是它又有别于与或非的运算规则.对于查询树同级子查询的合并运算规则如表2所示.
子查询的合并运算,本质上就是倒排表的归并运算,归纳起来,主要有3种,即交集运算、并集运算、和差集运算.对于3种集合运算,Lucene均采用多路归并运算[7].多路归并运算就是多条子查询的倒排表同时参与归并运算,以交集运算为例:
假定Q=(+x+y+z),x,y,z为子查询,Lucene采用基于跳表的多路快速合并算法,图4为合并流程示意图,初始状态的倒排链表如图4第1部分所示.首先将x、y、z链表按长度排序,从最短链表y第一个元素开始,然后在链表z中查找,如图4中第2部分;当在z中找到相同的元素,再开始在x中查找,找到了相同的元素,则该元素命中,如图4第3部分;如此进行,直到链表y结束.

表2 布尔运算规则表
Lucene中,对于3种子句的混合布尔运算按先MUST子句结合,再MUST_NOT,最后SHOULD的优先级进行多路归并运算.因此,对于一个查询Q,含有多个子查询,表示如下:
Q=(+a-bc+d+e),其中a,b,c,d,e为子查询;
根据表2运算规则和优先级规则,Q的合并运算过程如下:
Q=(((+a+d+e)-b)c);
Q=((+Q1 -b)c),其中Q1=(+a+d+e);
Q=(+Q2c),其中Q2=(+Q1 -b);
2 布尔查询执行计划的剖析
布尔查询执行计划直接决定着Lucene检索的性能,对该执行计划的深入研究有利于寻找检索性能优化的途径.本文从2个方面进行剖析,并提出可能的优化策略.
2.1 布尔查询表达式的优化
假定一个布尔查询Q1=(+a+b+(+c+d-e)-f),其中a,b,c,d,e,f为子查询,其对应的查询树如图5所示.这是一颗深度为2的查询树,根据Lucene布尔执行计划,先合并子树,再合并上一级子树,直到根节点,同一级的子查询按优先级进行多路合并.从执行逻辑上,图5查询树需要执行4次多路归并运算,并产生3个中间结果;而如果将Q1化简为图6所示的Q2查询树,则只需要执行2次多路归并运算,只产生1个中间结果.从理论上来看,查询的效率和空间复杂度将会大大改善.

问题:Q1和Q2表示的布尔查询是否等价?答案是肯定的,证明如下:
令A、B、C、D、E、F分别对应子查询a、b、c、d、e、f子查询的结果集,则:
Q1=A∩B∩(C∩D-E)-F
=A∩B∩(C∩D∩)-F
=A∩B∩C∩D∩-F
=A∩B∩C∩D-E-F
Q2=A∩B∩C∩D-E-F;
因此,Q1=Q2,证毕.
笔者对中国知网、百度、谷歌等全文检索系统的检索接口研究发现,用户检索需求解析为Query查询树时,深度均为2,因此深入研究用户查询需求布尔表达式,将表达式或部分表达式化简,减少查询多路归并的次数和中间结果的个数,具有提高查询效率的意义.本文根据集合运算规则,深入研究了各种深度为2的布尔表达式,表3列出了具有规律且能够化而简之的类型,限于篇幅证明省略.

表3 布尔表达式化简规律表
2.2 交换律
从布尔子查询运算规则和归并运算规则来看,用户查询请求中生成的布尔运算顺序,不是最终的运算顺序,Lucene会根据子查询的类型和运算的需要进行二次组合和排序.因此,从用户的角度,构造查询请求布尔表达式时,同一层子树,子查询满足交换律,例如:
Q1=(+a+b)=(+b+a);
Q2=(+abc)=(c+ab)=(bc+a);
与SQL语句执行计划不同,不需要刻意考虑将查询结果少的子查询放在最左边.
3 实验仿真
为了进一步分析布尔查询的合并运算规则和执行效率,验证布尔查询表达式优化策略和交换律,本文构建实验环境,模拟各种优化方案,比较查询结果和执行效率.Lucene版本为4.10.3,分词器为IKAnalyzer02012_u6,采用14万条商品订单记录构建索引库,每条记录含有编号、商品名、类型、地址、收货人、价格字段,分别映射到Document对象中number、name、type、address、user、price域.所有实验数据均在计算机负载稳定条件下,3次执行取平均值.实验中选取五个查询关键词:
a=name:”男”,b=type:”会场”,
c=name:”棉”,d=type:”内衣”,
e=name:”正版”.
所有的查询实验,均基于以上5个关键词的组合而得.
3.1 布尔查询表达式优化仿真
针对表3所列的两大类型5条优化规律,分别构建布尔表达式进行检索,查询结果个数、时间耗费、排序情况记录如表4所示.

表4 化简规律实验数据表
从表4的实验数据看出,表3所列的布尔表达式优化规律是正确的,优化所带来的执行效率均有提高.由于实验数据量较小,订单记录转换的文档也非常小,查询表达式相对简单,机器负载比较低,执行效率的改善不明显.随着数据量的增加、查询负载的加大,优化的查询执行效率必然会有很大的提高.
3.2 布尔运算规则的交换律仿真
根据表2所列的布尔运算基本规则,对于每一条规则,进行交换子查询位置检索实验,查询结果总数、运行时间数据如表5所示.

表5 交换律实验数据表
从表5的实验数据很容易看出,Lucene布尔查询表达式同一级的查询子句满足交换律,打分与排序结果不受子句的顺序影响,查询耗时基本相同.由此说明从应用层面,控制查询子句的顺序,不会带来查询效率的提升.
4 总结
本文深入研究了Lucene框架下布尔查询的执行计划,涉及布尔查询的表示方式、子句类型、执行过程、运算规则和子查询多路合并算法.根据布尔查询的逻辑过程,一方面剖析了复杂布尔表达式的化简规律,并选定一个类型进行了证明;另一方面,提出了布尔运算规则满足交换律的特性.通过理论分析和模拟实验验证,复杂布尔表达式的化简规律和布尔运算的交换律是正确的,并且,对复杂布尔运算的化简,有效地提高了检索效率.
