基于机器学习的TCP拥塞控制算法识别研究*
2019-12-04许乾坤叶剑飞李俊何
许乾坤,李 烨,董 浩,叶剑飞,李俊何
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
TCP作为Internet上一种占主导地位的端到端传输协议,其数据流量占Internet中95%以上。随着近些年移动宽带网络技术和用户数量的迅猛发展,TCP网络的拥塞问题越来越明显,因而原本单一的RENO拥塞控制算法[1]发展为十几种,以应用于不同的网络环境。为了及时调度部署客户端和服务器端的资源,更好地预防和阻止网络拥塞,客户端需要识别服务器端所采用的拥塞控制算法。
目前已有的对拥塞控制算法的识别方法存在若干问题,迄今尚未有很好的解决。TBIT[2]是利用初始化窗口值、损失函数以及发送的数据包数量等进行识别的一种方法,由于提出时间较早,对近年来出现的TCP拥塞控制算法的识别效果不佳。Oshio等提出的集成分析方法[3]假设系统中仅存在两种TCP拥塞控制算法版本,应用上有很大的局限性。Feyzabadi等研究了Web服务器上拥塞控制算法的识别,但工作仅限于RENO和CUBIC之间的识别[4]。对于多种TCP拥塞控制算法的同时分类识别,Yang等提出了CAAI方法[5],但只考虑了拥塞控制过程中的慢启动和拥塞避免两个阶段,因而对于仅在快速恢复阶段有差别的算法无法识别。
RENO[6]、NEWRENO[7]、CUBIC[8]和 CTCP[9]是当前应用最广泛的几个拥塞控制算法。为了提高对其识别的效率和准确率,本文分析了拥塞控制四个阶段的特点,基于构造的特征向量,提出一种极限学习机(Extreme Learning Machine,ELM)和随机森林(Random Forest,RF)相结合的算法对服务器端的拥塞控制算法进行识别,并与多种机器学习方法对比研究。
1 拥塞控制的基本原理
拥塞控制一般分为四个阶段,即慢启动、拥塞避免、快速恢复以及快速重传[10],图1给出了发生丢包时各阶段拥塞窗口(CWND)的变化。在慢启动阶段,由设定的初始窗口大小开始,以指数方式增长,当窗口大小到达设定的阈值之后进入拥塞避免阶段。在拥塞避免阶段,各拥塞算法的窗口增长函数不一样,RENO、NEWRENO等采用线性函数,STCP采用指数函数,也有的拥塞控制算法会根据确认字符(ACK)以及网络环境如往返时间(Round-Trip Time,RTT)来决定增长函数[11]。在连续收到三个或以上的重复ACK时,意味着网络拥塞发生了不止丢一个包的情况,就会进入快速重传阶段以重传丢失的包。快速重传和快速恢复阶段一般是成对出现的,在快速恢复阶段,窗口值降到一个比例后直接进入拥塞避免阶段,这个比例不会很小,以避免不必要的带宽浪费。RENO算法不包含快速重传和快速恢复阶段,在发生丢包后会超时重传,重新进入慢启动阶段,如图1中虚线所示。
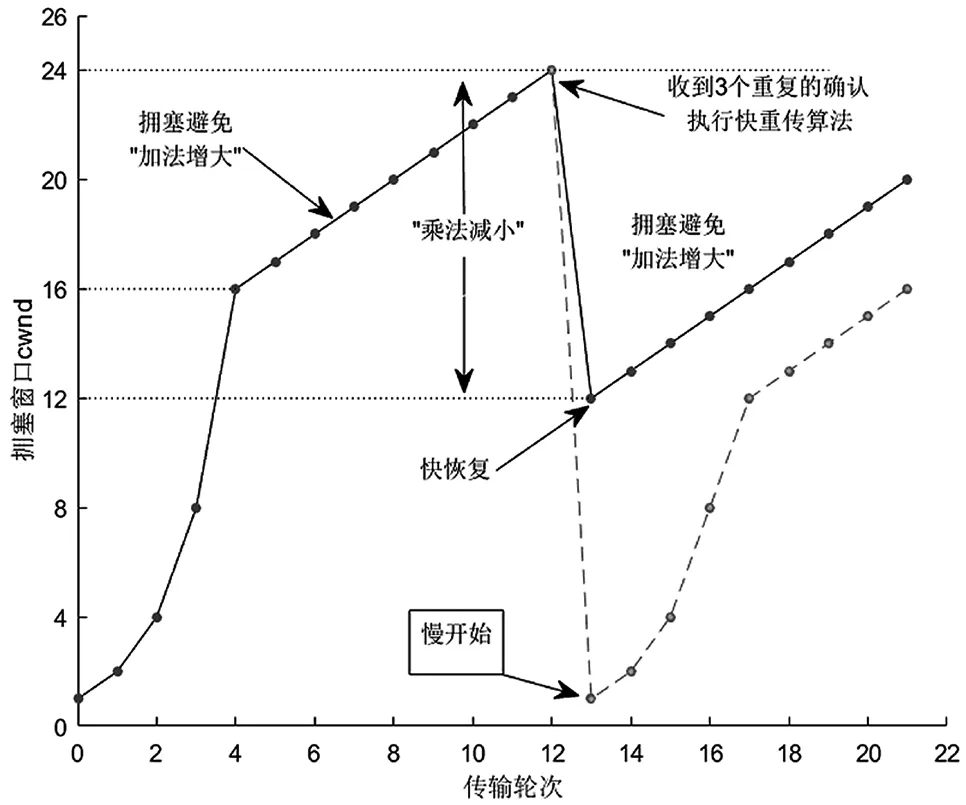
图1 TCP拥塞控制机制
2 特征向量构造
2.1 客户端数据采集
客户端只能通过接收的数据来提取拥塞控制算法的特征信息。根据TCP协议,通信过程在每个RTT内服务器会向客户端发送一定窗口值的数据,利用数据包的接收序号(Received Sequence Number,RSN)可计算出客户端接收到的来自服务器的数据总和。在服务器进行数据传送时,每个TCP协议包自动开启时间戳,且同一个CWND内的数据包,服务器端默认同时发出,每个包的时间戳近似相等,RSN在客户端根据时间戳计算每个RTT内的窗口值。对采集的数据进行处理后,可获得类似图1实线所示的拥塞控制四个阶段CWND大小的变化轨迹。
2.2 特征提取
对于所研究的四种主流拥塞控制算法,RENO、NEWRENO与CUBIC、CTCP在拥塞避免阶段和丢包点的处理上有差异,而NEWRENO作为RENO的改进算法,主要是在快速恢复阶段进行了改进。文献[5]的CAAI方法可识别RENO、CUBIC和CTCP,对于RENO和NEWRENO的区分则无能为力。为了更准确地识别服务器端采用的拥塞控制算法,同时使得识别方法可应用于所有主流拥塞控制算法,本文提取如下特征:
(1)窗口值下降比例β:当拥塞发生丢包时,连续收到三个重复的ACK,此时窗口阈值会下降一定比率。不同拥塞算法采用的比值不同,比如RENO为0.5,而CUBIC为0.8。根据丢包点前后拥塞窗口值的比值可确定窗口值下降比率:
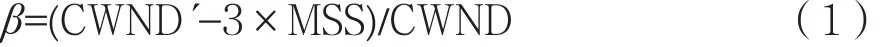
其中,CWND´为丢包后进入快速恢复阶段的拥塞窗口值,CWND´为丢包点的拥塞窗口值,MSS(Maximum Segment Size)为每个TCP包传输的最大报文长度。
(2)拥塞避免窗口增长函数g(x):在拥塞避免阶段,对于窗口增长函数g(x)特征,采用该阶段中两个时间点的窗口值ws+i和ws+j分别与拥塞避免阶段的起点窗口值ws+1作差,使用相对值ws+i-ws+1和ws+j-ws+1表示该阶段的函数曲线特征。
(3)快速恢复窗口增长函数h(x):在快速恢复阶段,当服务器连续收到三个DUPACK时,不同的算法处理不同,比如等待超时重传(RTO),或者不断增加窗口值直到收到重传的包。本文采用该阶段中的某个时间点窗口值与起点值作差wk-w1表示该特征。
由此,构造特征向量如下:
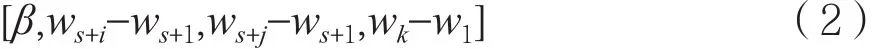
3 识别方法
3.1 极限学习机
ELM是一种单隐层前馈神经网(Single-hidden Layer Feedforward Neural Network,SLFN)学习算法,该算法能够随机产生输入层与隐含层之间的连接权重以及隐含层神经元的阈值,且在训练过程中无需调整,只需要设置隐含层神经元的个数,便可以获得唯一的最优解。与传统前馈神经网络算法相比,ELM避免了容易陷入局部极小值、学习率选择敏感以及迭代学习方法常见的过拟合等问题[12],并且学习速度快、泛化性能好。
理想SLFN模型的数学表达式为:

其中,Y为期望输出矩阵;β为隐含层与输出层之间的权矩阵;H=(W,b)为神经网络隐含层输出矩阵,W表示输入层与隐含层之间的权矩阵,b表示隐含层的偏置向量。
由于参数W和b是任意给定的,利用二者计算出H并令其保持不变,只需确定参数β即可。权值β可通过求解下式获得:

其中,||·||为欧式范数,H+为H的Moore-Penrose广义逆矩阵。
3.2 随机森林
RF是由Breiman提出的集成学习方法[13]。RF由多棵决策树组成,每棵决策树使用随机抽样方法从总的训练集(n个样本,m维特征)中有放回的抽取样本来训练,且每组样本的样本容量一般与总训练集相同。使用的特征同样是从所有特征中按照一定的比例无放回抽取,这个比例大小由自己定义,一般取为特征数目的开方、开方的一半、或者两倍的开方等。RF包含的决策树的数量由自己设定,且每棵树的分类结果相互独立,最后所有树的决策结果可通过多数投票法组合,即得票最多的类可以判定为RF的分类结果。RF不容易陷入过拟合,对很多数据集表现良好,精确度较高且具有很好的抗噪声能力[14]。
3.3 本文方法
出于网络实时通信和故障快速恢复的需求,对TCP拥塞控制算法的识别要求有较高的准确率和识别效率。为了解决此问题,可以从两方面考虑。一方面,尽可能的减少分类器的训练时间,优化参数调整过程,避免不必要的迭代计算;另一方面,为了提高识别的准确率,需要尽可能的提取有效特征,避免冗余信息对识别结果造成干扰。因此,将ELM和RF相结合,即用ELM算法代替RF算法原理中决策树的位置来进行样本的训练和结果分类,最后ELM算法的分类结果可通过多数投票法组合。算法模型如图2所示。
算法步骤为:
1)假设训练集为D,测试集为T,特征维数为M,极限学习机的数量为N,每个极限学习机的隐藏节点的个数为n,算法输入的特征数量为m。
2)应用自展法在训练集D上有放回地随机抽取N个新的自助样本集。
3)在总的M个特征上随机抽取m个特征作为每一个极限学习机算法模型的输入,结合步骤2)的样本集Di进行极限学习机i的模型训练计算。
4)采用多数投票法将训练得到的多个极限学习机进行组合。
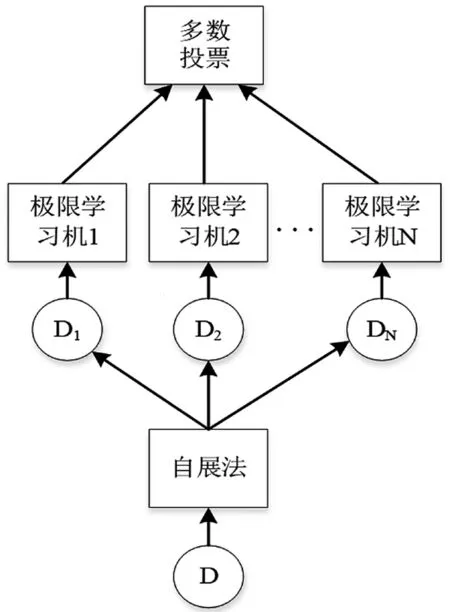
图2 所提算法模型
4 仿真实验
4.1 数据的获取与处理
在服务器端为RENO、NEWRENO、CUBIC、CTCP四种拥塞控制算法设置不同的网络环境参数,以实现数据的多样性。其中RTT的值(单位为毫秒)设置为20、40、60、80、90;丢包点设置为接通后的3~18秒内;丢包数设置为:1、3或5个。在通信过程中,产生通信数据信息,在服务端获取拥塞窗口变化轨迹,生成768个样本。在接收端采集RSN数据,根据时间戳获取测试集。
实验中,在拥塞避免阶段提取出第4个RTT和第8个RTT的窗口值,即取i=4和j=8,在快速恢复阶段提取第4个RTT对应的窗口值,即取k=4。因此,特征向量为:
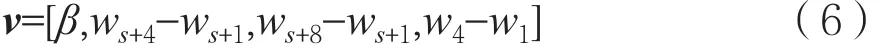
4.2 实验设置
为验证所提基于ELM和RF的识别方法的有效性,与K-最近邻算法(k-Nearest Neighbor,KNN)、Logistic回归(Logistic Regression,LR)、支持向量机(Support Vector Machine,SVM)、极限学习机(Extreme Learning Machine,ELM)以及随机森林(Random Forest,RF)进行对比研究,算法参数设置如下:
1)KNN:k值取为3,采用欧氏距离作为距离度量方式,以少数服从多数的规则进行分类。
2)LR:惩罚项选用L2范数,由于是四类分类问题,采用一对多的拆分策略进行处理,共构造4*(4-1)/2=6个两类分类器。
3)SVM:采用C-SVC模型,核函数为径向基函数(Radial Basis Function,RBF)核,gamma取为0.1,惩罚系数C为0.5。采用一对多的拆分策略进行处理。
4)ELM:隐含层节点数为8,激活函数采用Sigmoid函数。
5)RF:随机森林的树的深度为8,树的数量为180。
4.3 实验结果
采用查准率和召回率作为算法的性能度量,由于二者是一对矛盾的指标,将其综合如下:

其中,P表示查准率,R表示召回率,α的取值代表了对查准率和召回率的偏好,α>1时,模型更看重对正样本的识别,α<1时,模型更看重对负样本的区分能力,而α=1时即为标准F1值,是基于两者的加权调和平均,表示两者同等重要。本文实验取α=1,分类结果如表1~表4所示。

表1 不同分类模型F1值

表2 不同分类模型R值
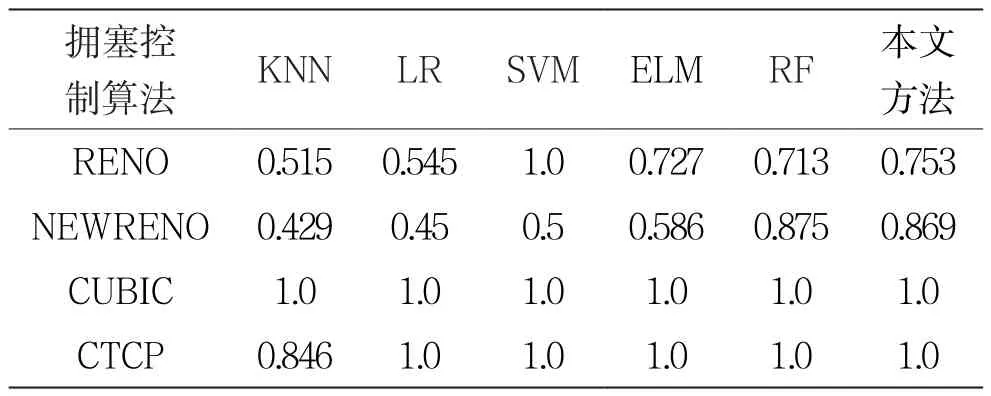
表3 不同分类模型P值

表4 平均分类准确率
比较表1~表3数据可见,本文方法对于拥塞控制算法的识别结果最优,其综合指标F1值明显高于其他五种分类算法,特别是对RENO和NEWRENO的识别有明显的提升,而对于CUBIC和CTCP两种算法均达到了100%的识别率。由表4可以看出,本文分类算法对数据集中四种拥塞控制算法的平均分类准确率最高,由此验证了所提算法的有效性。
4.4 特征提取效果分析
文献[5]提出了可以对多个拥塞控制算法进行识别的算法CAAI,采用从拥塞避免和快速重传阶段提取的三个特征。相比于CAAI算法,本文构造的特征向量增加了快速恢复窗口增长函数h(x)。为了研究其对于拥塞控制算法的识别效果的作用,将本文算法与CAAI识别算法进行对比研究,实验结果如图3所示。
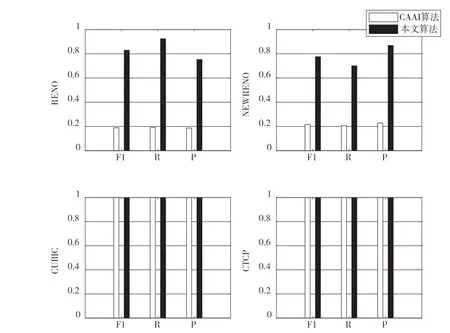
图3 本文算法和CAAI识别结果对比图
可以看出,对于CUBIC和CTCP,采用两种算法均可以很好的识别,但对于RENO和NEWRENO,仅采用CAAI算法提取的三个特征时几乎无法对其进行识别。而采用本文算法提取的四个特征时,在保持对CUBIC和CTCP 100%识别率的前提下,对RENO和NEWRENO两种算法的识别也有了很大的提高。
经验证,在实际应用中为获取上述识别所需的特征向量,最小只需要3.14兆TCP流的大小,即可获得较为理想的识别效果,因此对TCP流的大小要求较低。
5 结 语
TCP协议在网络传输中普遍使用,使得拥塞控制算法的识别在改善网络环境、提高用户的网络体验等方面越来越重要,也对互联网性能与稳定性的分析具有重要意义。本文基于客户端接收的数据估计服务器端拥塞控制算法窗口变化轨迹,提取拥塞控制各阶段特征信息以构造特征向量,并提出了一种ELM与RF相结合的新算法应用于拥塞控制算法的识别。相比于已有方法,所设计的特征向量包含的信息更加全面,提高了识别准确率,扩大了应用范围,取得了更好的识别效果。
致谢:感谢华为技术有限公司合作项目“无线智能网络架构仿真平台技术研究”为本文提供研究和实验环境支持。
