网络流量管理系统中队列管理器的设计与实现*
2019-12-04孙明乾乔庐峰陈庆华
孙明乾,乔庐峰,陈庆华
(陆军工程大学 通信工程学院,江苏 南京 210001)
0 引 言
在网络流量爆炸增长,各式各样的新业务不断涌现的同时,随之而来的是日益增多的网络安全问题,这对网络中的边缘接入设备以及核心交换设备提出了更高的要求[1]。一方面,要求上述设备具备一定的流量管理功能,能基于特定的策略或协议特征库对不同数据流的协议类型、应用类型或用户行为进行识别,进而能够针对不同优先级的应用所对应的数据流,分别为其分配不同的带宽资源,从而保证部分关键业务的QoS。另一方面,要求上述设备具备一定的网包过滤功能,借助于深度包检测技术,基于给定的模式特征库,对数据包的应用层内容进行检测,从而使别出特定数据包中潜在的非法信息及行为[2-3]。
目前,网络设备中的上述两种功能相对比较独立。通常来说,具备流量管理功能的设备很少提供有网包过滤的功能,而对于诸如防火墙、入侵检测系统等网络安全防护设备,也很少有流量管理存在的身影。事实上,二者并非互斥。对于流量管理来说,其主要包括流分类、流量监管、流量整形和流量评估四个方面[4],而流分类是实施后三个方面的前提。传统的流分类所依据的策略主要是数据包报文头中的源IP地址、目的IP地址、源MAC地址、目的MAC地址、协议(五元组)或应用程序的端口号[5],这种流量分类方法实现简单、判定速度快,且适于硬件实现。然而,随着网络应用的不断发展,网络协议类型不断增加,同时端口混淆技术的采用,使得上述方法实现的流量识别的准确率越来越低。大部分协议的特征信息隐藏在数据包的应用层载荷之中,因此,可以借助于DPI进行流量分类[6]。将各个协议所对应的特征字段进行整理,构造成协议特征库,基于协议特征库,DPI可以对数据包的报文内容进行检测,有效地识别出其中是否包含有特定的协议字段。对于网络安全防护设备,其使用DPI对数据包的应用层载荷中是否包含有某些威胁字段进行检测,而不同协议的数据包所对应的威胁字段特征不同,倘若使用同一模式特征库对所有数据包进行检测,模式特征库中的某一规则可能并非适用于当前数据包所对应的协议类型,这在一定程度上会造成系统性能和资源的浪费。因此,可基于不同的协议类型对模式特征库中的规则集进行分类。使用分类后的模式库分别对分流后的数据包进行检测,在减少资源消耗的同时可实现精准检测。
本文在上述分析的基础上,考虑到流量管理和深度包检测的特点,基于FPGA硬件平台,设计了一个具备深度包检测功能的流量管理系统并给出了该系统的硬件架构。同时,为实现对输入数据流的流量控制,系统中的队列管理器是一重要组成部分。队列管理器为不同种类的业务流提供缓存,提供了抗流量波动的能力,保证了数据的完整性,本文将进一步详细介绍其具体的设计与实现方式。
1 系统硬件架构
在当今网络带宽日益增长的背景下,传统的基于软件的流量管理系统或深度包监测系统已无法适应数据流的线速处理要求,而网络核心节点处的数据吞吐量也基本上都在万兆比特每秒的级别,同样需要大容量的网络设备的支持。目前,国际上的研究热点已经转向专用硬件实现高性能网络设备,芯片级流量管理方法及深度包检测方法迅速成为研究热点。
本文所设计的具备深度包检测功能的流量管理系统基于FPGA硬件平台,其整体架构如图1所示。

图1 系统硬件架构
在图1中,输入至该系统的数据流首先经过预处理,分路后送至不同的网流分类模块。此处例化了多个网流分类模块,可并行处理以提高系统吞吐率。分类后的数据流依据其协议协议类型或应用类型,经由片外DDR3缓存,分别被送至不同的DPI匹配引擎处理,进行内容检测。一般情况下,DPI匹配引擎的数量较网流分类模块多,这是由于二者的检测范围和检测深度不同造成的。网流分类模块只需在正确识别出该数据流所属的协议或应用后,即可停止对其进行检测;而DPI匹配引擎必须将每一数据包中的应用层载荷的内容从头到尾过滤一遍,这是因为非法信息或威胁字段可能出现在数据包载荷中的任意位置。
经由DPI匹配引擎后的数据流,若被检测出威胁信息,可将其送至专门模块做进一步处理;若未被检测出威胁信息,则将其送往本文所设计的队列管理器,在队列管理器内部基于链表结构构建逻辑队列,等待后级调度器的调度输出,以实现针对不同协议或应用类型的流量控制。
2 队列管理器的结构设计
网络流量管理系统中主要存在两项关键技术:一是基于DPI的流分类技术,用于应用与协议识别;二是具备一定缓存容量的队列管理机制,用于实现对数据包的缓冲管理、基于流的排队管理以及数据流的输出调度和输出速度控制等。
队列管理器的模型结构如图2所示。其主体部分由多个相互独立的先入先出队列构成,每一队列与一特定协议或应用对应,多个队列可同属同一协议与应用。对于某一特定队列,为其分配一队列编号,称之为Flow ID(流编号)。此处Flow ID的数值范围为0-4095,可同时对4096个队列进行管理。需要注意的是,这里提到的队列数量,可根据业务的实际需求来进行动态调整。各个队列共享同一块数据缓冲区,考虑到系统中的网流分类模块和DPI匹配引擎对片内存储资源的需求,本文以DDR3作为该队列管理器的数据缓冲区,基于链表结构在片内为其构建逻辑队列,而实际的数据存储至片外DDR3中,由此可在较低片内存储资源消耗的情况下,实现对上千个数据流的精确管理。特别地,本文所设计的队列管理器具有以下特点:
(1)可针对特定业务,单独为其构建队列。可基于用户配置,为某一队列分配固定的缓存资源,即定义队列深度的上限与下限。同时设立公共缓存池,待某一队列独有的缓存资源耗尽时,可申请使用共享缓存;
(2)每一队列分属不同的优先级,同一优先级的队列具有同等的被输出调度的机会。输出调度器根据调度权重在不同优先级的队列之间分配带宽;
(3)使用片外存储器DDR3作为共享缓存,在保障了整个系统吞吐量的同时,有效地减少了片内存储资源的消耗;
(4)以块为单位对队列管理器中的大容量数据缓冲区DDR3进行划分并为之分配指针,块与块所对应的指针以链表的形式构建逻辑队列。逻辑队列所对应的指针存储至片内以提高自由指针的获取和归还速度以及逻辑队列的访问速度。

图2 队列管理器的模型结构
针对图1中的队列管理器,其具体电路细节如图3所示,包括写预处理电路、自由指针管理电路、多队列控制电路、DDR3控制器、DDR3用户接口电路和调度器等主要组成部分。
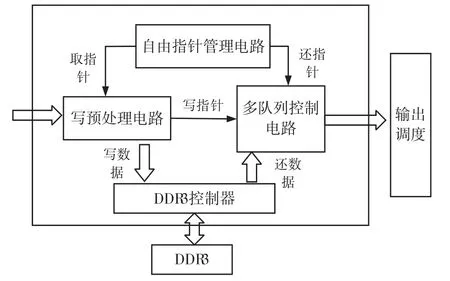
图3 队列管理器的电路结构
其中,需要特别说明的是,对于自由指针管理电路,其主要负责维护系统当前可用的所有自由指针,同时实现指针分发与指针回收的功能。自由指针指向了DDR3存储区中未被使用的存储空间,对于这一部分存储空间,后续可能被分配至任意队列,而非被某一固定队列所有,这也是提高整个队列管理器的灵活性与资源利用率的有效方式。
2.1 工作流程
系统上电后,DD3控制器首先对DDR3进行初始化,待初始化完成后,可依据图4所示流程图,完成队列创建、数据写入操作。

图4 数据写入流程
数据流经分类、深度包检测后,若未被检测出威胁信息,将携带各自的Flow ID被送至队列管理器,Flow ID定义了当前数据流应当所属的队列。队列管理器中的控制器以Flow ID为地址,从电路内部相应的片内RAM中读取出当前队列的状态信息,包括当前队列深度、队列首指针地址、尾指针地址、尾指针地址所对应的存储区余量等。若当前队列深度小于系统为该队列的预留深度,则可以直接进行后续的自由指针获取、数据存储操作,进而更新队列状态信息,继续进行下一数据流的写入;若当前队列深度大于系统为该队列的预留深度,则需要先向公共缓冲区申请额外的缓存资源,申请成功后方可进行后续操作。
数据流的读出过程与上述过程类似。调度器针对某一特定队列,发出数据读取请求,相应队列接收到该请求后,从DDR3中读取出队首的数据,随后归还自由指针、更新队列状态信息。
2.2 基于块的存储区分配
队列管理器需要能够提供一定的抗流量波动能力。假设在某种情况下,某一协议或某一应用所对应的数据流量突然增多,进而导致其所对应的队列深度急剧增加,队列管理器就需要为该队列分配更多的存储资源,这就对整个队列管理器所能拥有的最大存储资源提出了更高的要求。在网络流量管理系统中,为了提高流分类模块与DPI匹配引擎的处理速度,一般将其检测所需的DFA(Deterministic Finite Automata,确定型有穷自动机)表项存储至片内RAM中[7],而DFA表项的存储往往需要消耗大量的片内存储资源,特别是在协议特征集或规则集较大的情况下,这种现象尤为严重。
考虑到DDR3具有存储容量大、读写速度快等优势,因此采用片外DDR3作为数据缓冲区。为了提高读写效率,DDR3采用突发操作,在突发长度为8,突发数据位宽为64 bits的前提下,一次突发操作可以写入或读出512 bits数据。传统的基于链表的队列管理器,一个指针往往与单次读写数据宽度对应。在此处,一个指针对应于512 bits的数据。对于存储容量为4GB的DDR3,采用上述方式划分存储空间,总共所需的指针数量为4 GB/512 bits=8 MB。指针数量过多而无法存储于片内,只能存储至DDR3中,将DDR3中的一部分空间作为自由指针存储区。在这种方式下,可以使用指针预读取的方式,将自由指针提前读取至片内,供自由指针管理模块进行指针分发操作,以提高队列管理效率[7]。这种方法的优点是队列管理器对数据的操作管理灵活,操作模式简单,存储管理颗粒度精细,但同时该方法需要消耗大量的资源来存储自由指针和逻辑队列。由于链表的存储和访问特点,通常需要使用高速静态RAM进行链表存储。在很多典型的应用中,如果数据缓冲区容量非常大,那么需要的指针缓冲区深度也会很大,此时使用芯片内部或者FPGA内部的存储器实现会消耗大量的片内资源,通常需要使用片外高速存储器进行链表存储,但此时的存储访问速度会受到片外存储器访问速度的制约,会使DDR等大容量数据缓冲区的读写速度优势不能得到充分发挥。基于此,本文提供了一种基于大颗粒度存储单元的队列管理器实现机制,具体电路细节如图5、6所示。
对大容量数据缓冲区以块为单位进行划分,一个块内可以存储多个数据流,以块为单位分配指针,可以使指针的数量大大减少,从而减少了自由指针和逻辑队列的资源消耗;此时自由指针和逻辑队列可以存储在高速片内RAM中以提高自由指针的获取和归速度以及逻辑队列的访问速度;本地信元按照块内部地址进行连续存储或读取,块与块所对应的指针以链表的形式构建逻辑队列,可以减小指针的获取和归还频率。这种管理方式可靠、高效且易于扩展以支持更大的数据缓冲区容量。
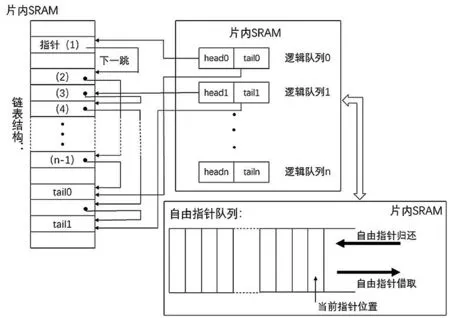
图5 自由指针及逻辑队列的组织结构
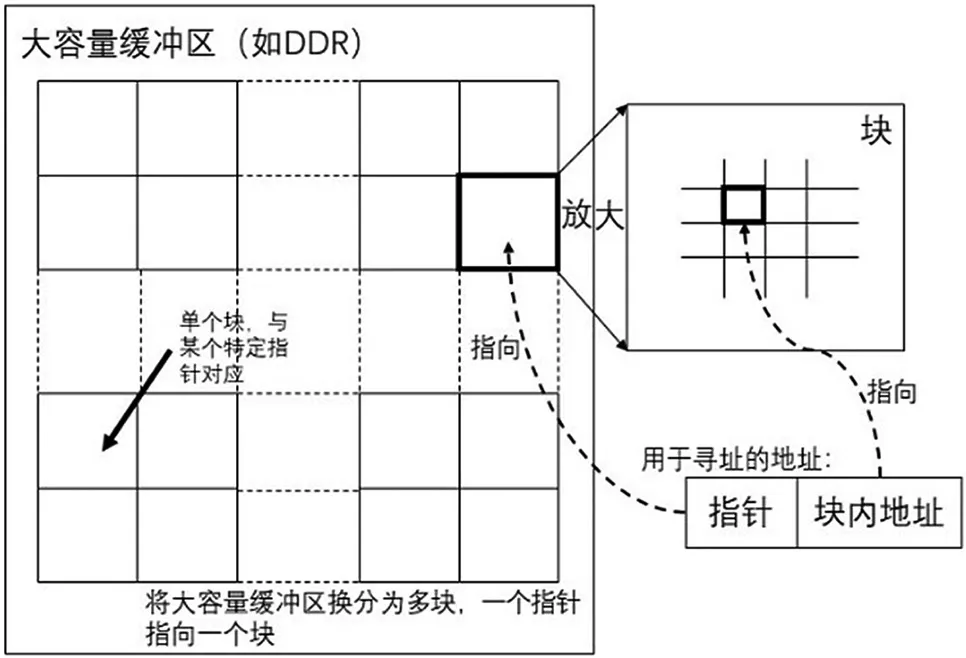
图6 DDR3的地址划分与寻址方式
3 仿真结果与分析
本设计中,队列管理器的电路核心模块采用Verilog HDL编程实现,开发环境采用的是Xilinx集成开发环境ISE 14.7,使用仿真软件Modelsim SE 10.6d对整个系统进行行为级仿真。
3.1 自由指针的获取及队列状态更新的仿真
某一队列所使用的当前指针,若其所对应的内部缓冲区已无法缓存更多的数据,且恰逢该队列有新的数据流要加入时,那么该队列需要向自由指针管理模块发出申请(ingress_ptr_req=1),同时附带当前队列的Flow ID(ingress_qnr=64,说明当前队列的流编号为64,如图7所示),请求自由指针管理模块分发给自己一个新的自由指针,以供使用。自由指针管理模块接收到请求,在发出应答的同时(ingress_ptr_ack=1),将一暂未使用的自由指针分配给该队列(ingress_ptr=03ffb),同时更新本模块内部的队列状态信息,包括队列的首尾指针地址(ht_ram)、队列长度(q_len_ram)、逻辑队列所对应的链表(ll_ram),上述信息皆以片内RAM存储。
3.2 指针与块内地址联合寻址的仿真
前文图6中描述的寻址方式,需要将指针与块内地址结合起来,才能正确地访问单个存储数据单元,其中指针指示了DDR3中某一存储块的首地址,块内地址指示了当前数据位相对与当前存储块首地址的偏移量。
若当前的块内地址(wr_ptr_b)达到预先设计的阈值,信号wr_ptr_reach_rail将被置1,表示当前块内已无法再存储下一数据包。当下一数据到来时,队列向自由指针管理模块申请得到新的指针(ll_in=03ffb),同时当前块内地址被更新为0(在图8中,wr_ptr_b由471变为0),表示新的数据将存储至由新指针指向的存储块内。
3.3 业务流调度输出的仿真
队列管理器中的数据输出受调度器的控制。调度器依据其内部运行的调度算法,计算出当前需要调度输出的队列编号,在cell_q_req_map有效时(cell_q_req_map不为0),通过cell_q_req_0信号指示出希望读取的数据在哪一队列,从而完成一次数据读取请求,如图9所示。

图7 自由指针获取及队列状态更新的仿真结果

图8 指针与块内地址联合寻址的仿真结果

图9 业务流调度输出的仿真结果
4 结 语
本文提出了一种基于FPGA硬件平台的网络流量管理系统架构,在此基础上,针对其中的核心关键模块,队列管理器,进行了设计与实现。所设计的队列管理器为了减少片内资源消耗,且能够提供较大容量的数据缓存功能,使用了片外DDR3作为数据缓冲区。此外,针对链表结构,提出了一种可靠高效的基于块的存储区分配方式,在提高了电路处理速度的同时,也可以支持更大的数据缓冲区容量。
仿真结果表明,该电路实现了对不同流的有效管理,正确地完成了数据流的写入与读取操作,能够对不同的业务提供不同的QoS保证,减少了关键业务的时延。进一步地,本文所设计的队列管理器可以作为一种通用模块,应用于不同种类的网络设备中,以实现对不同业务流的管理。
