基于改进身份向量提取的短语音说话人确认
2019-12-04王铮,傅山
王 铮,傅 山
(上海交通大学 电子信息与电气工程学院,上海 200240)
1 引 言
说话人确认是计算机根据语音信息自动判别其是否来自特定说话人的技术.近年来,随着基于因子分析的身份向量(i-vector)的提出,结合概率线性判别分析(Probability linear discriminant analysis,PLDA)作为信道补偿和打分方法,说话人确认系统的性能得到了巨大的提升[1].然而,这一性能提升建立在存在足够时长(3分钟或以上)的语音数据分别用于身份注册和测试的前提之下.在语音数据量不足,如测试语音为短语音的情形下,i-vector系统的性能会明显下降,甚至低于传统的基于高斯混合模型(GMM-UBM)框架的系统[2].
为了克服短语音带来的挑战,研究者从不同角度做出了许多努力.文献[3]将语音时长不一致视为i-vector空间的加性噪声,提出一种得分校准方法用于再合成i-vector向量.在文献[4]中,作者提出通过在i-vector特征域进行语音时长不一致的归一化来对短语音进行补偿.在文献[5]中,作者提出对较小的语音单元类进行建模,并用统计方法弥补特征的稀疏.文献[6]通过挖掘短语音中的口音信息来增强现有特征的区分性.除了在语音特征层面的改进,也有研究者致力于改进PLDA来提升现有系统.文献[7]提出根据语音时长对PLDA建模的概率分布进行修正.文献[8]提出通过量化i-vector提取的不确定性建立全后验分布的PLDA.
此外,还有研究者尝试将深度神经网络(Deep Neural Networks,DNN)应用到说话人识别领域,如利用语音识别DNN取代GMM用于计算充分统计量[9,10],或从瓶颈层或者某个隐藏层提取与音素相关的语音特征,以及最近提出的端到端系统中提取的嵌入特征[11-13]等,对短语音识别取得了一定效果.然而,训练语音识别DNN往往需要大量的带文本标记的匹配数据,并且极大提升了计算复杂度.
短语音带来的i-vector估计准确性的下降[14],根源在于从有限的语音段中提取的说话人特征信息不足.本文直接对i-vector提取过程进行改进,挖掘出更多的信息用于i-vector估计.一方面,根据系统之前遇到的历史测试语音与当前测试语音来自同一人的概率为其赋予相应的权重,加入到Baum-Welch统计量的计算中,用于当前i-vector的估计.另一方面,由于通用背景模型(Universal background model,UBM)本身由大量语音数据训练得到,利用背景模型参数自适应更新Baum-Welch统计量,可以利用其中丰富的说话人信息.
本文余下部分组织如下:第2节描述i-vector及PLDA框架作为基线系统;第3节结合i-vector提取过程分析短语音i-vector估计的不确定性;第4节阐释了本文提出的改进i-vector提取的原理;第5节给出验证本文方法有效性的实验设置和实验分析;第6节进行总结与展望.
2 基线系统
首先,利用来自不同说话人的语音数据混合训练得到一个高斯混合模型,作为通用背景模型,代表当前环境下各说话人的平均特征.高斯混合模型可以视为C个多变量高斯分布的加权和,其概率密度函数为:
(1)

将说话人GMM中各个高斯分量的均值mc串联堆叠起来,得到一个DC维矢量,称为高斯均值超矢量,记为M.根据i-vector因子分析的思想,此均值超矢量M可分解为:
M=m+Tw
(2)
其中m是与说话人无关的均值超矢量,T是一个低秩的全局差异空间矩阵(TV Matrix),w是服从标准正态分布的隐随机变量.i-vector φ定义为变量w的最大后验(MAP)估计,其等于给定输入语音下w的后验均值.
由于i-vector中仍包含与说话人身份无关的信道信息,采用PLDA同时作为信道补偿和打分手段.在简化PLDA模型中,第i个说话人的第j段语音对应的i-vector可以表示为如下生成模型:
φi,j=η+Uzi+εi,j
(3)
其中η是各个i-vector的均值,U代表与说话人相关的子空间,zi是与说话人相关的说话人因子,εi,j是包含信道等信息的残差项.
最终i-vector及PLDA系统输出的得分为:
(4)
其中H1代表假设ztar和ztest来自同一说话人,H0代表假设ztar和ztest来自不同说话人.
3 i-vector提取分析
由公式(2)可知,在开发阶段i-vector模型的参数包括与说话人无关的均值超矢量m和全局差异空间矩阵T.通常,利用UBM的均值超矢量作为m,而矩阵T在与UBM相同的开发集上由大量语音数据根据期望最大化(EM)算法训练得到.故而二者不受评估阶段短语音造成的数据不足的影响.
图1描述了i-vector及PLDA系统在评估阶段由语音段到输出得分的过程.
假设UBM包含C个高斯分量,特征向量的维度为D.给定来自语音段i的特征向量集合Xi,由UBM可计算出对应第c个高斯分量的零阶和一阶Baum-Welch(BW)统计量如下:
(5)
(6)
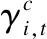
(7)
由BW统计量可以计算出后验均值E[wi],即所提取的i-vector如下:
(8)
其中Tc为矩阵T中对应第c个分量的子矩阵.从上述i-vector提取过程可知,来自评估语音段的特征信息完全囊括在由之计算出的Baum-Welch统计量中.由公式(5)可知,零阶Baum-Welch统计量Nc(Xi)满足:
(9)
即零阶Baum-Welch统计量Nc(Xi)的和等于语音段包含的总特征数t0.由文献[15]可知,当t0的值大时,语音段中蕴含的语音信息丰富,对Nc(Xi)的估计较好,反之,对Nc(Xi)的估计不足.文献[16]表明,在短语音情况下,对Nc(Xi)估计的变化性增大,说明对其估计的不确定性增加.更明确地,可以证明所提取的i-vector的后验协方差为[17]:
(10)
式中,∑c及Tc在开发阶段就已经训练得到,仅有Nc(Xi)来自评估阶段语音.在短语音情形下,Nc(Xi)变小,继而对i-vector的估计变得不准确.以上分析表明,为了提高语音段i-vector估计的准确性,关键在于改良BW统计量的计算.由于注册时的语音时长要求较易得到满足,本文余下部分主要针对测试短语音提出改进方法.
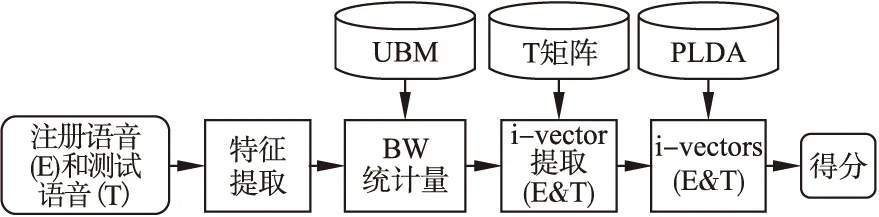
图1 i-vector及PLDA系统评估阶段框图Fig.1 Block diagram of i-vector/PLDA system
4 改进的i-vector提取
4.1 挖掘历史测试语音信息
由于仅从当前短测试语音中无法得到充足的说话人特征信息,进而给出BW统计量的准确估计,本小节尝试从系统之前遇到的测试语音中挖掘出更多信息纳入统计量计算.成功地纳入历史测试信息不仅可以解决短语音数据不足的问题,还可以将说话人在不同时期的声音变化(如感冒等)纳入统计,从而增加识别系统的鲁棒性.然而,系统的某条历史测试语音与当前测试语音有可能来自同一说话人,也有可能来自不同说话人.将恰好来自同一说话人的历史测试语音纳入当前BW统计量的计算自然会提高系统性能,但若误将来自不同说话人用于计算当前BW统计量,识别效果将会下降.
受文献[18]中GMM模型无监督自适应的启发,本文提出一种MAP估计器来对某历史测试语音与当前测试语音来自同一说话人的概率进行估计,进而把这一概率作为将该历史测试语音纳入当前BW统计量计算时的权重.对于每一段测试语音,首先均按照基线i-vector及PLDA系统输出一个原始得分.假设某测试语音的原始得分为s,此MAP估计器先计算其来自目标说话人的概率如下:
(11)
其中,P(s|tar)和P(s|imp)分别是得分s来自目标说话人和冒充者的得分分布的概率,Ptar和Pimp分别是测试语音来自目标说话人和冒充者的先验概率.目标说话人和冒充者的得分分布已提前在开发集上学习得到.
进而,任意给定两条测试语音,就可以由它们来自目标说话人的概率给出它们来自同一说话人的概率.假设当前测试语音的原始得分为s0,某条历史测试语音的原始得分为s1,则它们来自同一说话人的概率为:
α=P(tar|so)P(tar|s1)+[1-P(tar|s0)][1-P(tar|s1)]
(12)
注意因为是说话人确认任务,此处将两条测试语音均非来自目标说话人的情况视为来自同一说话人,即来自同一“非目标说话人”.
最终,当前测试语音的BW统计量计算如下:
(13)
(14)
其中,N0和F0是直接由当前测试语音计算的BW统计量,Ni和Fi是由第i条历史测试语音计算的BW统计量,αi是由MAP估计器给出的第i条历史测试语音与当前测试语音来自同一人的概率,作为权重.至此,系统所遇到的所有测试语音以一种统一的方式纳入到BW统计量的计算.将公式(13)和公式(14)带入公式(8),即可得到当前测试语音的改进i-vector.
4.2 挖掘UBM参数信息
在经典的GMM-UBM说话人识别系统中,说话人GMM由UBM通过自适应得到,这样极大减少了训练目标GMM所需的数据量.然而,在i-vector提取中BW统计量的计算并不包含自适应过程,在短语音数据不足的情形下难以对其进行准确估计.本小节尝试在BW统计量的计算中加入UBM参数的自适应过程,以期更好地利用UBM中丰富的语音信息.
结合公式(5),为了研究零阶BW统计量与语音时长无关的性质,定义归一化的零阶BW统计量:
(15)
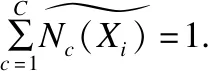
(16)
其中β(0≤β≤1)作为控制参数,作用类似于GMM自适应中的自适应参数,用于控制进行自适应的参数的量,其值可以通过经验或实验选定.最终,应用于i-vector提取的零阶BW统计量为:
(17)
将公式(17)带入公式(8)即可得到加入UBM自适应改进的i-vector表达式.
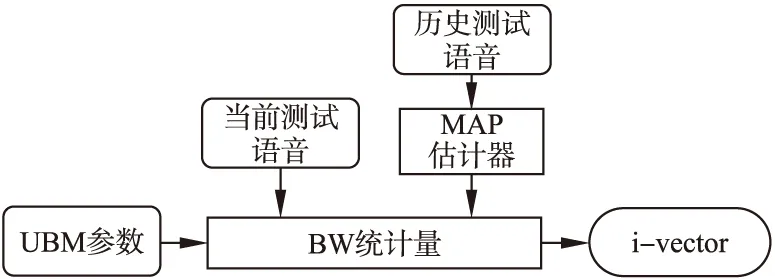
图2 改进i-vector提取框图Fig.2 Improved i-vector extraction
融合本小节和上一小节对BW统计量计算做出的改进,将公式(13)中BW统计量N代入公式(15)进行归一化再代入公式(16)和公式(17),即可以在BW统计量的计算中同时纳入历史测试语音信息和UBM参数的更多信息.图2描绘了融合两类信息的改进i-vector提取的过程.
5 实验与结果分析
5.1 实验准备
为了检验上文提出的改进i-vector提取方法的有效性,采用美国国家标准技术署说话人识别评测2010(NIST,SRE 2010)核心数据集中男性电话语音进行实验.原始语音数据平均时长2.5分钟,为了获取实验所需的短语音,起始帧随机地截取2秒,5秒,10秒(仅包含非静音帧)的片段.实验中系统注册所用语音时长为2.5分钟,测试语音为以上截取的三种短语音段.在测试阶段,建立的说话人模型为489个,测试样本351段,共进行了目标说话人测试353次,冒认者测试13307次.
对实验语音提取标准梅尔频率倒谱系数(MFCC)作为特征.预加重系数0.97,加汉明窗,帧宽20ms,帧移10ms,共抽取12维倒谱向量并计算能量系数,其后附加上一阶差分.利用基于能量的寂静音检测去除静音.在之后的建模与测试时均丢弃能量系数的一阶差分,因此本文所使用的特征共25维.为减小环境影响,将静音去除后的特征标准化为正态分布.系统训练数据采用SRE04-06数据以及Switchboard II数据.利用期望值最大算法训练出512分量高斯混合模型,全局差异子空间的维度为400维.在PLDA中,说话人相关的子空间维度为150维.
采用等错误率(EER)和检测代价函数最小值(minDCF)两项指标来衡量系统性能.EER是检测错误权衡(DET)曲线上虚警率和漏警率相等的点.在计算检测代价函数最小值时,检测代价函数中取值Cmiss=Cfa=1,Ptrue=0.01.
5.2 加入历史测试语音信息系统性能
本小节旨在检验4.1小节中将历史测试语音信息加入BW统计量计算的方法.在公式(11)中,测试语音来自目标说话人的先验概率设置为0.1.提前利用SRE04-06数据分别进行大量目标说话人和冒充者测试,将目标说话人和冒充者的得分分布由两个12分量GMM来代表.评估实验对比了基线系统(记为Baseline)及纳入历史测试语音的改进系统(记为Proposed-1)在三种不同长度短测试语音下的表现.实验结果见表1.表中给出了Proposed-1系统相对基线系统的提升,记为RI.
表1 Proposed-1系统与基线系统性能比较
Table 1 Comparison of baseline and proposed-1 system
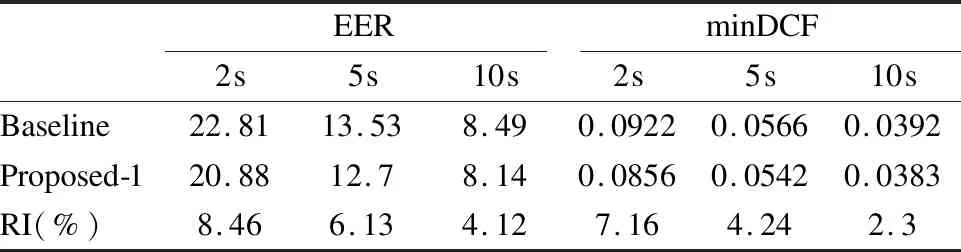
EERminDCF2s5s10s2s5s10sBaseline22.8113.538.490.09220.05660.0392Proposed-120.8812.78.140.08560.05420.0383RI(%)8.466.134.127.164.242.3
由表1可见,在测试语音时长变短时,基线系统的性能迅速下降.纳入历史测试语音信息改进i-vector估计后,系统性能优于基线系统,且测试语音越短,这种相对提升越显著.为了更详细地分析系统行为,图3显示了测试语音时长10s情形下,纳入历史测试语音的系统与基线系统在新测试语音不断加入时的minDCF对比.图中虚线代表基线系统的minDCF.
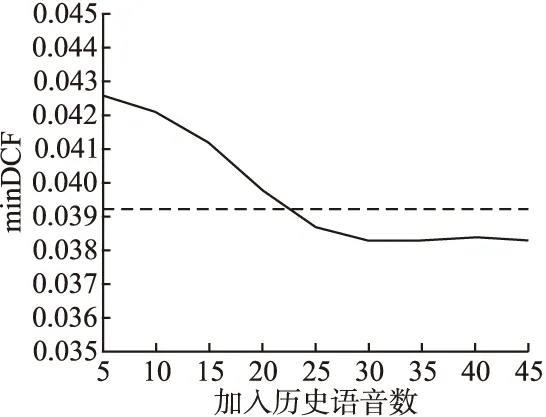
图3 Proposed-1系统性能与加入历史测试语音数的关系Fig.3 Proposed-1 system performance and the number of added historical test
由图3可见,由于引入与当前测试语音不同的语音信息,Proposed-1系统的性能在起初有一定的下降.然而,随着历史测试语音不断加入i-vector的估计,系统的性能开始回升.当有足够多历史信息加入后,Proposed-1系统的性能最终超过了基线系统,并最终稳定下来.这说明存在足够历史测试语音的情形下,这种方法是有效的.
5.3 加入历史测试语音信息性能分析
本小节旨在探究将历史测试语音信息纳入i-vector估计的潜在问题.首先,在通过MAP估计器给出两条测试语音来自同一人的概率作为权重时,虽然可以预期绝大多数来自不同人的测试语音所获的权重较低,但将它们用于BW统计量的计算仍会使系统性能有下降的趋势.与此同时,一些本身来自同一人的测试语音,却因为基线系统识别的效果不佳而被误分配了较低的权重,将这些测试语音用于BW统计量的计算会使系统性能趋于提升.为了揭示这两种相反的趋势对系统性能的影响,本文为用于计算BW统计量的历史测试语音权重设置门槛,当测试语音的权重低于这一门槛时,该测试语音将不再用于BW统计量的计算.表2列出了测试语音时长10s情形下,不同权重门槛值对应的实验结果以及被丢弃的历史测试语音数.
由表2可见,当可用于BW统计量计算的权重门槛提高,虽然因权重值较低而被丢弃的测试语音绝大部分是来自不同人的语音,系统的性能却下降了.这说明纳入因基线系统性能不佳而被误分类的测试语音带来的益处要大于纳入低权重的不同人测试语音带来的损害.将原本来自同一人而被误分配较低权重的测试语音纳入i-vector提取对系统性能提高具有巨大的价值,这证明了本方法将全部历史测试语音纳入计算的合理性.
表2 权重门槛设置实验结果
Table 2 Results of different weights

门槛设置EERminDCF丢弃语音数同一人不同人无门槛8.140.038300α<0.028.190.03913237α<0.058.330.0389161053
在前述实验中,用于提前估计得分分布的开发集使用的是SRE 04-06数据,改用Switchboard数据作为开发集进行实验,在仍采用SRE数据进行得分规整的情况下,系统性能的浮动很小.这一观察扩大了本方法的适用性.
接着讨论在BW统计量计算中纳入历史测试语音时间和计算复杂度增加的问题.在本方法中,对每一条测试语音,系统只需要提取一次BW统计量,进行一次原始得分计算,这部分与基线系统相同.然而,对每条历史测试语音,本方法需要利用其原始得分通过MAP估计器计算相应权重,从而得到加权后的历史BW统计量,这部分的代价随着历史测试语音数量的增加而线性增加.在系统的历史测试语音很多时,会拖慢系统响应速度.对此,可以考虑只使用固定数量的历史测试语音(如最近的30条历史测试),以达到系统性能和系统响应速度的平衡.另外,还可以考虑将相似度高的历史测试语音提前归为一组,在利用MAP估计器给出权重时以各历史测试语音组为单位进行,这将是我们未来研究的方向.
5.4 加入UBM自适应和融合系统的性能
本小节给出检验4.2小节中UBM参数自适应和融合系统性能的实验结果.为了获取UBM自适应的最优性能,首先通过实验的方式为公式(16)中适应参数β选择恰当的数值.在为此,在开发集上,以0.1为间隔分别为β取值:0,0.1,…,0.9,观察系统性能.以测试语音时长为5s为例,β取不同值时系统minDCF如图4所示.

图4 β取值对系统性能的影响Fig.4 β and system performance
由图4可知,在测试语音为5s时β取值0.6系统性能达到最佳.用同样的方法为不同的测试语音时长分别选择最优的β值,基线系统、纳入UBM自适应的系统(记为Proposed-2)和融合系统(记为Fusion)的性能对比见表3.表中列出了β在不同测试时长下的取值.
表3 Proposed-2、Fusion系统与基线系统性能比较
Table 3 Comparison of baseline,proposed-2 and fusion system
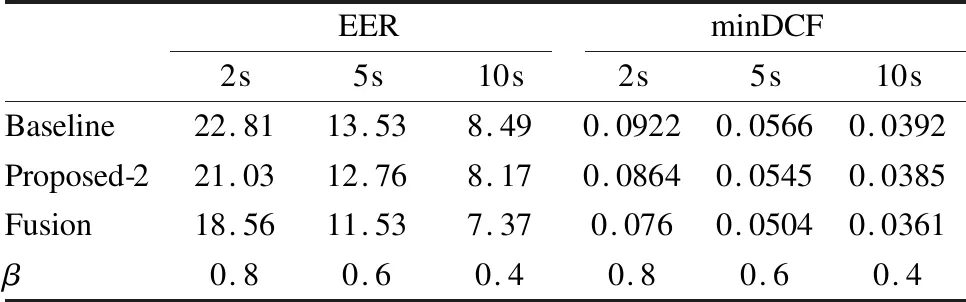
EERminDCF2s5s10s2s5s10sBaseline22.8113.538.490.09220.05660.0392Proposed-221.0312.768.170.08640.05450.0385Fusion18.5611.537.370.0760.05040.0361β0.80.60.40.80.60.4
由表3可见,进行UBM自适应的系统性能优于基线系统性能.观察β取值可见,当测试语音时长变长,β取值较小.这表明UBM参数自适应尤其对短语音起到作用.结合表2和表3可以发现,纳入历史测试语音信息的系统性能优于进行UBM自适应系统的性能.这一观察符合我们的预期:在纳入历史测试语音信息的系统中,利用MAP估计器给出了说话人的标签信息,这比单纯利用无监督学习得到的UBM中信息有效.最终,融合系统的性能优于只采用一种改进的系统,这说明历史测试语音信息和UBM参数信息具有一定的互补性.
6 结束语
短语音带来的性能下降是限制说话人识别系统实际应用的一个难题.为了提升测试语音时长有限情形下的系统性能,首先,通过分析确定在短语音情况下i-vector估计的不确定性增加源于用于BW统计量计算的信息不足.为改善测试语音i-vector的估计,本文提出两种方法用于改进BW统计量计算:一种是纳入带有权重的历史测试语音信息,另一种是利用UBM参数自适应统计量.实验表明,两种方法都能够提升系统性能,融合两种方法后系统的性能进一步提高.
在下一步的研究工作中,将着重于优化历史语音权重的估计过程,以降低存在大量历史测试情况下系统工作的时间和计算成本.由于当前自适应参数β的取值是在开发集上针对不同语音时长预先估计的,在未来的研究中,拟探究β取值在测试过程中的动态估计以更符合实际应用情况.另外,还可以研究测试语音时长不定时(如2s、5s、10s混合)系统的性能表现.
