分布式水文模型在华北平原水资源管理中的应用
2019-12-03欢12
秦 欢 欢12
(1.东华理工大学 核资源与环境国家重点实验室,江西 南昌 330312; 2.东华理工大学 水资源与环境工程学院,江西 南昌 330013)
在过去的几十年,地下水被大量用作城区供水和灌溉用水[1-4],其超采现象已成为主导水资源争论的一个主要问题[5-6]。由于地下水的不可持续开采和不充分补给,世界上一些地区主要含水层的地下水水位迅速下降,如印度尼西亚的西爪哇[7]、孟加拉国首都达卡[8]、中国的华北平原[4,9-10]及北京市[11-13]。地下水水位的持续下降会对自然径流、地下水对湿地的补给及相关的生态系统产生破坏性影响[2],由此导致一系列诸如地面沉降、海水入侵等生态环境问题[11,14-16]。因此,地下水可持续管理对区域社会经济发展和生态环境保护都具有极其重要的意义。
大尺度水文模型是可持续水管理研究中的有效工具,受到越来越多的重视[17-18]。然而,由于存在诸如观测站点分布不均匀或数据获取的不充分等原因,大尺度水文模型开发和校正过程还存在巨大挑战[19]。分布式水文模型根据地形、土壤、土地利用及降水等因素的不同,将研究流域划分为不同水文单元,用一组参数反映某个单元的流域特征[4],逐渐成为可持续水管理及流域水文循环研究中的重要工具,获得了长足的发展[3]。MIKE SHE是一种确定性的、基于物理过程的分布式水文模型(http://www.dhigroup.com),涵盖主要水文循环过程及其相互作用[20],广泛应用于环境、水文、生态等领域,在不同气候和水文条件下得到了测试和验证[21],其典型应用范围包括流域规划、水资源管理、土地利用变化的影响等[21]。
作为我国的政治、经济及文化中心,华北平原社会经济发展给水资源带来了巨大的压力,水资源短缺已成为制约其社会经济和生态环境可持续发展的关键问题。作为华北平原的主要供水来源,地下水占总供水量的70%左右[22-23],北京、石家庄、邢台、邯郸、保定、衡水、廊坊、唐山等城市该比例已达70%以上。华北平原人均水资源占有量极少(501 m3/a),只有全国人均的23%[3]。同时,由于不合理开采地下水,华北平原产生了一系列诸如地面沉降、塌陷、土壤次生盐渍化等严重的生态环境问题,给该区域社会经济发展和生态环境保护带来了深远影响[24]。除地下水超采严重外,华北平原水资源利用过程中还存在水资源综合利用率低、浪费和污染严重、生态环境恶化及干旱频率加大等问题[4]。
目前,已有许多学者对华北平原地下水进行研究[22-23,25]。MODFLOW是多数研究采用的工具,而采用分布式水文模型进行研究的例子较少。在前人研究中,地下水补给是通过下渗系数或降水量来进行处理,忽略了蒸散发和灌溉的影响。Kendy E[26]的研究表明,地下水补给量与降水量的比值取决于降水和灌溉的数量和分布,对其简单处理会在模型中引入很大的不确定性。与此不同,MIKE SHE模型依据降水、蒸散发和灌溉等因素自动进行地下水补给的计算,在一定程度上降低了前述不确定性。因此,可采用分布式水文模型对华北平原地下水利用与管理进行更可靠的研究[27]。
本文使用MIKE SHE软件建立了华北平原地表水-地下水耦合的分布式水文模型,模拟水文循环的主要过程。利用地下水水头观测数据对模型进行校准和验证,在此基础上分析华北平原水均衡组成部分,掌握华北平原地下水组成和利用的特征。校准后的模型被用于分析分布式水文模型在华北平原可持续水管理中的作用,为解决华北平原水资源短缺问题提供有效的指导和科学的建议。
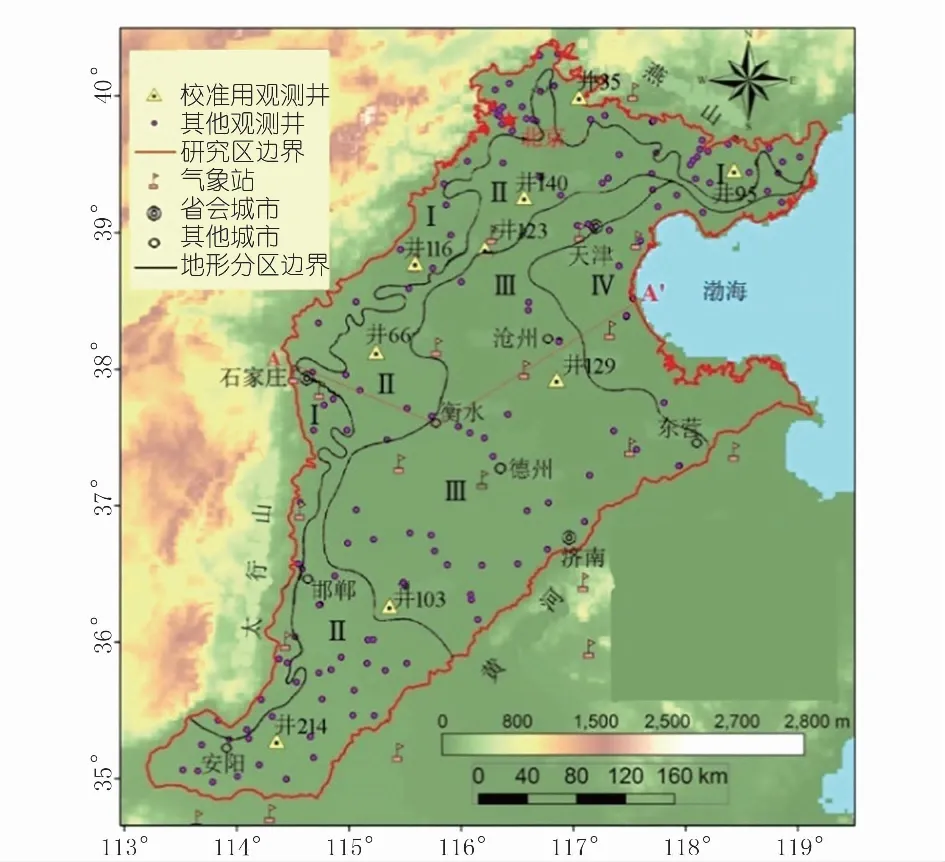
(1)气象站点和观测井;(2)地形区边界[25];(3) 省会及其它城市图1 华北平原地理位置和地形图[3,25]Fig.1 Location and topography of the NCP
1 研究区概况
华北平原(36°N~41°N,114°30′E~118°30′E)是指黄河以北、燕山以南、太行山以东的冲积平原区,包含京、津、冀、鲁、豫等省市(见图1)[3-4]。华北平原属温暖带半干旱季风型气候区,多年(1951~1995年)平均降水量554 mm,降水量年内分配不均、年际变化也大,6~9月的降水占全年的75%以上;平均气温13.0℃,水面蒸发量900~1 400 mm,蒸发量随纬度增加而递减。
调查表明,华北平原天然地下水量为227.4亿m3/a,2000年地下水开采量为212.0亿m3,其中浅层和深层开采量分别为178.4亿m3和33.6亿m3,开采程度分别为112%和139%,地下水水位低于海平面的范围已达到76 732 km2。从20世纪70年代开始,华北平原局部出现逐步加剧的超采现象,目前已累计超采浅层900亿m3的地下水,形成了世界上最大的地下水降落漏斗区。
2 华北平原MIKE SHE模型的建立
2.1 模型数据
MIKE SHE是基于物理过程的分布式水文模型,所需数据较多,包括气象、土地利用、河流湖泊、土壤、地形、地下水开采、地下水观测等不同类型、不同来源的数据(见表1)。
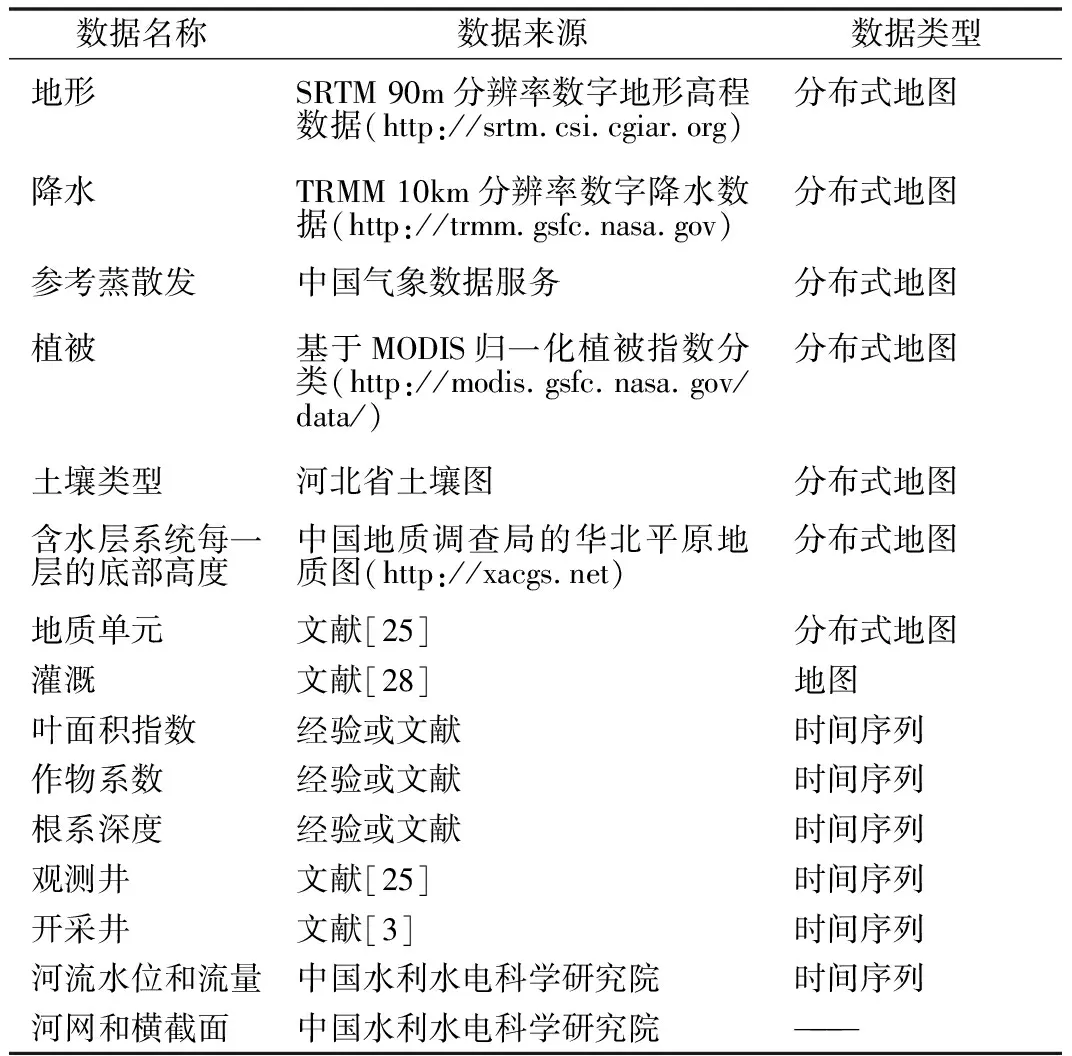
表1 华北平原分布式水文MIKE SHE模型中的数据及其来源Tab.1 Data and their sources in the distributedhydrological MIKE SHE model of the NCP
气象数据包括分布式降水率和基于站点的参考蒸散发,前者来自NASA科学(http://trmm.gsfc. nasa.gov)的热带降水测量卫星(Tropical Rainfall Measuring Mission)的3B42日值产品,后者来自中国气象数据服务提供的19个站点的数据,使用Penman-Monteith公式[29]进行计算。为满足模型网格划分要求,使用双线性重采样方法将降水率的分辨率处理为10 km,采用泰森多边形法将参考蒸散发分布于整个研究区。采用MODIS归一化植被指数,根据2003年产品的季节性变化对土地利用进行分类[30],见图2。植被参数根据经验或文献确定,对于同种类型,叶面积指数和根系深度取值相同,作物系数和灌溉需水量取值不同。冬小麦和夏玉米是研究区典型作物轮种类型,前者生长周期为10月至来年6月初,后者则为6~9月,棉花和果树的生长周期均为5~10月。
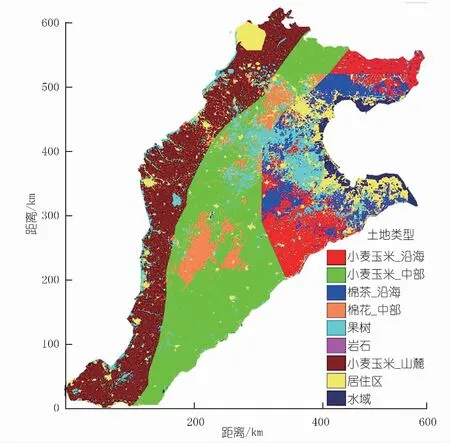
图2 华北平原土地利用类型分布图[28]Fig.2 Distribution map of land use of the NCP
研究区开采地下水用于农业灌溉、工业生产及居民生活,对它们有不同的处理方法:农业灌溉地下水依据作物类型和生长周期进行计算,工业生产和居民生活地下水来源于SD模型的结果[31]。大型水文模型中用于灌溉的浅层地下水水井的具体信息(数目和位置)是无法确切掌握的。在这种情况下,模型采用了“浅层井来源(Shallow Well Source)”来进行处理。灌溉方式为喷灌,即灌溉回归水将会以降水的形式重回模型。在模型中,考虑21个城市用于工业和生活的深层(III和IV层)地下水开采,其数据来自文献[31]。本文采用随机点方法(random- point approach)和虚拟井(virtual well)来描述研究区抽水井多且位置信息无法精确获知的现象。生活需水分为城镇和农村生活需水,同时引入重复利用因子F,对工业和生活地下水净开采量进行处理,具体步骤如下。
(1) 分别搜集第i个城市城镇生活、农村生活和工业的总需水量UDWT(i,t)、RDWT(i,t)、IWT(i,t)数据,其中1≤i≤21,t是模拟时间。这些需水量根据人口、牲畜数量和工业产值,利用SD模型进行计算[31]。
(2) 视城市的相对重要性,随机生成第i个城市的Ni(10≤Ni≤25)个点,代表Ni个虚拟井,同一城市的虚拟井使用相同开采率。
(3) 搜集城镇生活、农村生活和工业需水量的消耗率FUD、FRD及FI。年均约10.6 mm的地表入海径流是研究区水文系统消耗水的另一个来源[32],它被平均分配(5.3 mm/a)到城镇生活和工业用水中。
(4) 第i个城市每口井的开采率由公式(1)计算,其中UDW(i,t)、RDW(i,t)和IW(i,t)分别是城镇生活、农村生活和工业需水量的地下水开采率,αUD和αI是5.3 mm/a的径流量相对于城镇生活和工业开采量的比率。计算公式如下。
(1)
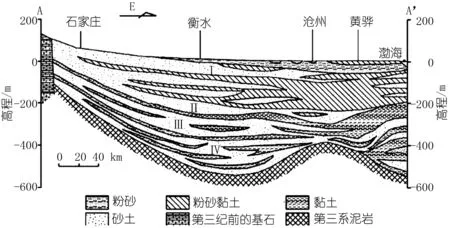
注:沿图1中A- A′的华北平原水文地质横截面图[25],Ⅰ、Ⅱ是第1层(浅层含水层),Ⅲ、Ⅳ是第2,3层(深层含水层)图3 华北平原水文地质横截面Fig.3 Hydrogeological cross section of the NCP
2.2 模型结构和设定
研究区MIKE SHE模型囊括陆面水文循环主要过程及其相互作用,采用有限差分法求解控制方程,包括坡面流(2D Saint-Venant方程)、河道径流(Kinematic Routing求解器)、非饱和水流(Two-Layer Water Balance法)、饱和水流(三维Boussinesq方程)、林冠截留(解析解)和蒸散发(解析解)。模拟时间是2000年1月1日至2008年8月31日,地下水和河流湖泊水流的时间步长分别是1 d及5 min,研究区被离散化为300列350行、大小为2 km×2 km的网格,模拟面积14万km2。研究区第四纪含水层包括4个含水层单元[25](图3中的Ⅰ-Ⅳ),对应地质单元分别是全新统(Qh4)及晚期(Qp3)、中期(Qp2)和早期(Qp1)更新统[25,33-34]。模型垂向上分为3层[25]:前两个含水层(Ⅰ和Ⅱ)为第1层,Ⅲ和Ⅳ为第2,3层。模型顶部高程数据来自SRTM 90 m分辨率高程数据[25,35]。模型中考虑了5条主要河流(滦河、永定河、滹沱河、漳河和卫河),河网、横截面和边界条件等数据由中国水利水电科学研究院提供。每条河流都包括设为定值的上游入流(inflow)和下游水位(water level)边界条件,通过耦合段和地下水系统进行水量交换。
研究区的土壤类型包括壤土(loam)、粉砂壤土(silty loam)和砂土(sand)。采用二层水均衡模型(Two-layer Water Balance Model)计算非饱和含水带水流,需要饱和含水量、田间持水量、凋萎点含水量及饱和导水率等数据(见表2)。
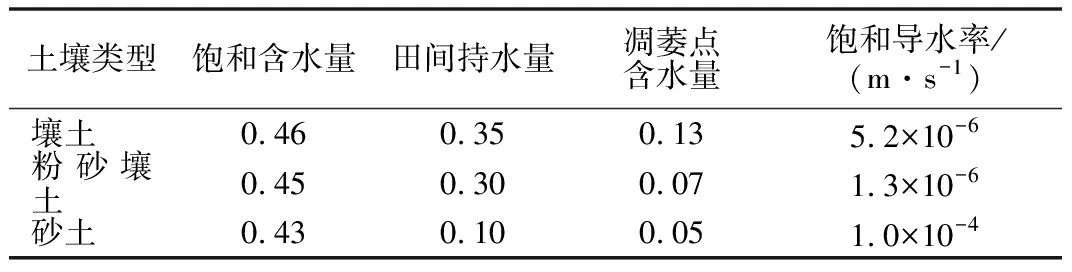
表2 华北平原不同土壤类型的参数值Tab.2 Parameters for different soil types of the NCP
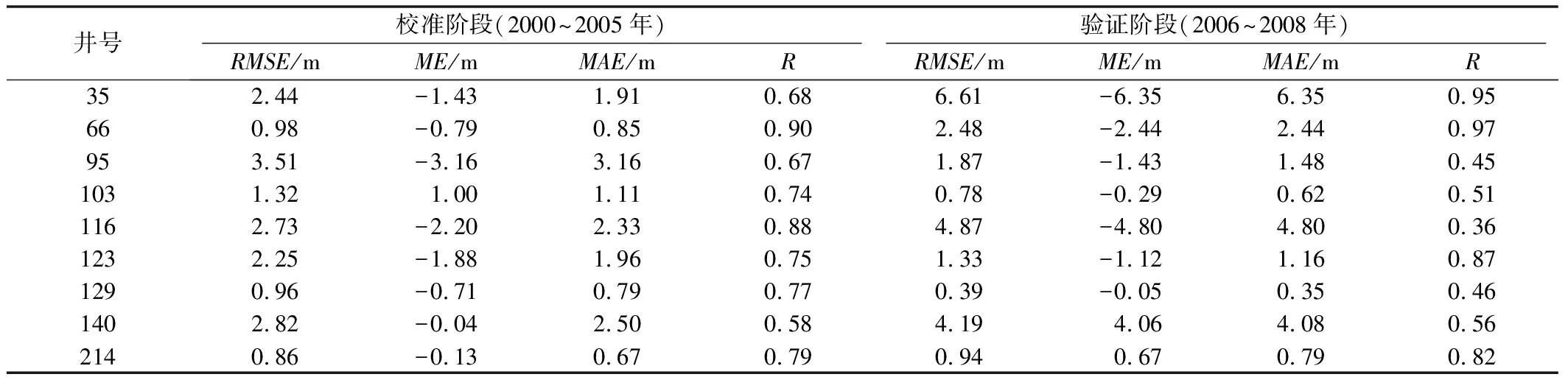
表3 模型校准和验证阶段的指标结果Tab.3 Performance results of the calibration and validation periods
MIKE SHE需要ET表面深度来计算实际蒸散发,其值等于毛细带的厚度(模型中该值为0.2 m)。饱和地下水含水层分为3层,通过27个水文地质单元进行参数赋值,同一个单元使用相同水文地质参数,水力传导系数和贮水系数通过抽水试验进行估算。2000年1月1日初始水头用作模型的初始条件。第1层包括3类边界条件:东北部与渤海湾相连,为第1类边界条件(固定水头为零);东南和南部以黄河为界,为第2类边界条件(固定水头为初始值);西部是太行山和山麓平原的交汇处,为第3类边界条件(零流量)。第2层包括两类边界条件:东北部为零水头边界,其它部分为零流量边界。第3层采用零流量边界条件。
2.3 模型的校准和验证
模型使用AutoCAL作为优化校准工具,利用226口观测井(见图1)数据对地下水水头进行校准(2000~2005年)和验证(2006~2008年)。自动校准的目的是最小化均方根误差(RMSE),此外还有3个定量化指标:平均误差(ME)、平均绝对误差(MAE)和相关系数(R),计算公式为
(2)
(3)
(4)
(5)
3 结果和分析
3.1 校准和验证结果
校准阶段的性能指标(见表3)表明模型校准结果是合理的,对于多数观测井,R值在0.75以上,表明观测值和模拟值之间良好的一致性。大多数井的RMSE值在0.86~3.51 m之间,相对研究区尺度来说是很小的。在验证阶段,除了95,116号和129号井外,大部分井的R值都很高,表明校准过程是成功的。对于全部226口井来说,ME、MAE和RMSE值分别是1.54 ,13.15,19.49 m,相对于研究区地下水降落漏斗中心浅层和深层最大水位变化分别为60 m和70 m[25]来说,这些值是很小的。在模型验证阶段,模拟结果并没有反映某些井的地下水水头动态性,误差相对较大,其原因可能是:① 同一网格中存在的密集的抽水活动对模拟曲线形状会产生平滑影响;② 对模型中采用的井的精确位置信息有误差。总体来说,模型校验结果基本证明了研究区MIKE SHE模型的有效性。图4列出了校准和验证阶段所选观测井水头模拟值和观测值的比较,模拟的地下水动态性与观测的结果吻合得很好,进一步证实了校验后的MIKE SHE模型的可靠性。
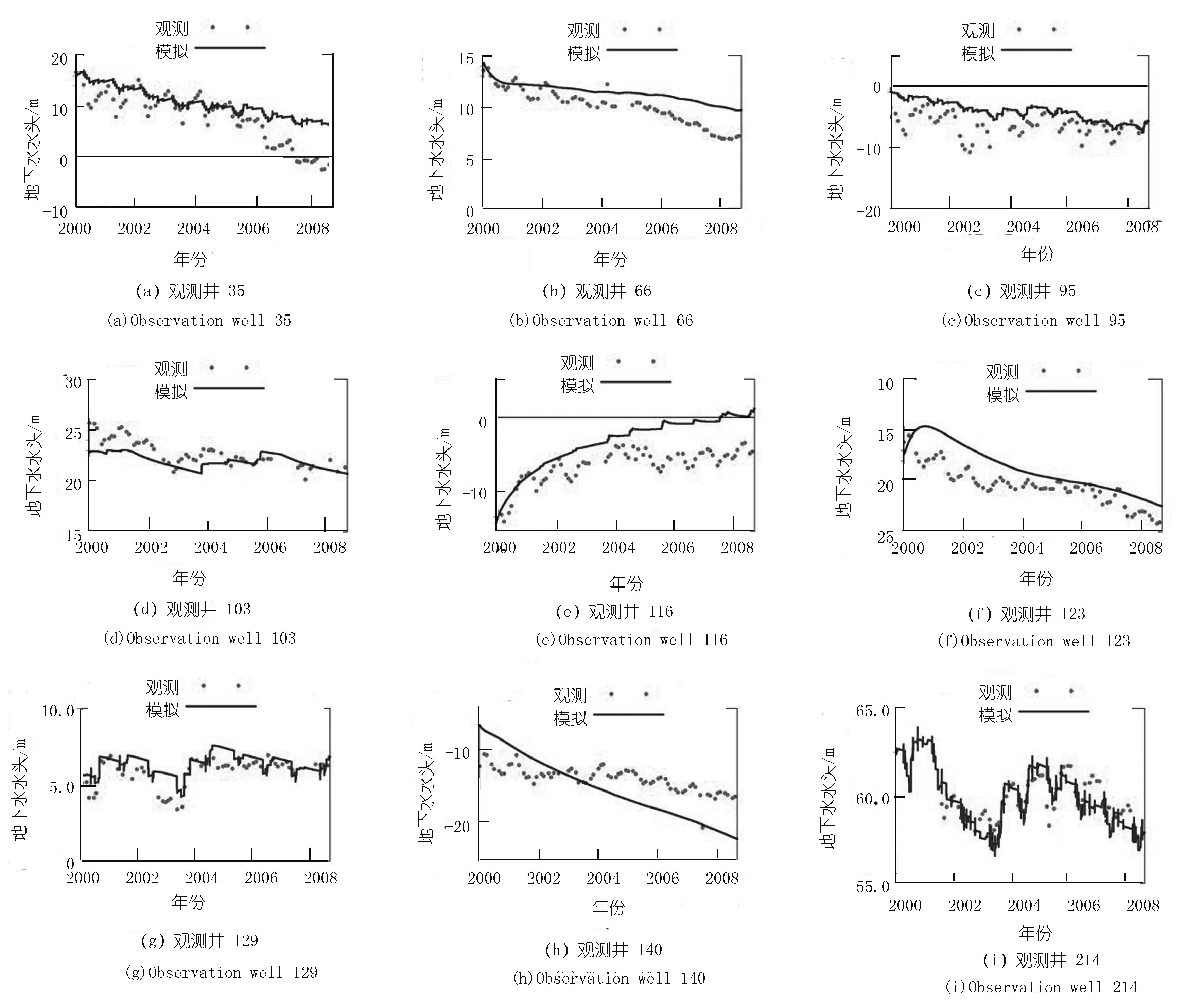
注:2000~2005年为校准期;2006~2008年为验证期。图4 观测井的地下水水头模拟值和观测值的比较Fig.4 Comparison of simulated and observed groundwater heads for selected observation wells
3.2 地表水模拟结果
图5是模拟期内研究区河流地表水流量及区域平均降水量时间序列结果。从中可以看出,流量呈减少且波动的规律,峰值出现在汛期,这与研究区内大多数河流呈干涸状态一致。值得注意的是,由于数据的可获得性问题,模拟结果没有与观测值进行比较,这是模型下一步可以改进和深入的地方。
3.3 水均衡分析
水均衡是一个重要的模拟结果,能给出研究区水资源可用性及使用情况的有用信息,可由下式计算:
IT-OT=ΔST=ΔSUZ+ΔSSZ
(6)
式中,IT和OT分别表示总流入、流出量,ΔST,ΔSUZ和ΔSSZ分别表示含水层、非饱和含水层和饱和含水层储量变化,正、负值分别表示增加和减少。
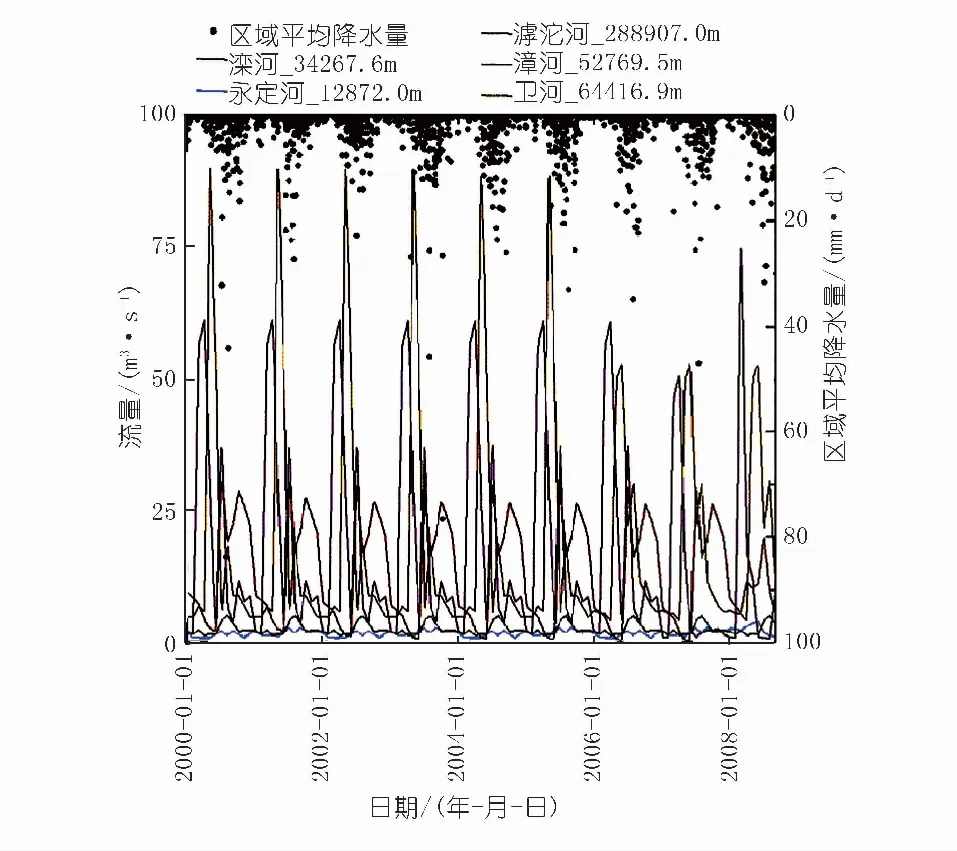
注:河流名字后面的数字表示该点所处的河流长度,m图5 模拟期内研究区河流地表水流量及区域平均降水量Fig.5 Surface discharge and regional rainfall instudy area during simulation pericol
图6是模拟期内研究区含水层水均衡情况,而表4是水均衡组成情况。水均衡主要包括流入项(降水、灌溉)和流出项(蒸散发、抽水)。在模拟期内,平均总流入、流出量分别是731.42 mm/a和794.58 mm/a,其差异造成了非饱和及饱和含水层7.50 mm/a和55.38 mm/a的储量消耗(见图6)。王荣[36]计算出华北平原2002年和2003年的地下水储量消耗为52 mm。而Wang等[37]计算出华北平原2002年和2003年的地下水储量消耗为51 mm。同时期本文计算的地下水储量消耗为67 mm。从水均衡角度来看,这些比较证明了本模型的可靠性。
表4 模拟期内水均衡分析结果Tab.4 Annual water balance analysis results in the simulation period mm/a
系统中大部分水(70.6%)通过蒸散发的形式离开,其余的水通过抽水的形式离开,表明研究区水均衡存在明显的亏缺。除一些湿润年份(2003,2004年和2008年),实际蒸散发大于降水量(见表4),说明研究区水资源利用的不可持续性。在整个模拟期内,研究区的总蒸散发量大于总降水量,由此导致饱和及非饱和含水层储量分别消耗480 mm和65 mm,而且这种消耗具有年度变化规律,即冬季消耗增加,夏季消耗减少。2003,2007年和2008年降水量充沛,导致这些年含水层储量变化为正值,反映在图4中是地下水水位的增加。
一直以来,密集的地下水开采被认为是造成研究区地下水枯竭的主要原因。从表4和图6可以看出,研究区地下水开采量占降水和灌溉水量之和的31%,说明目前的地下水开采是不可持续的。实际的地下水开采活动具有很大的不确定性,该问题的解决有助于建立更准确的MIKE SHE模型。
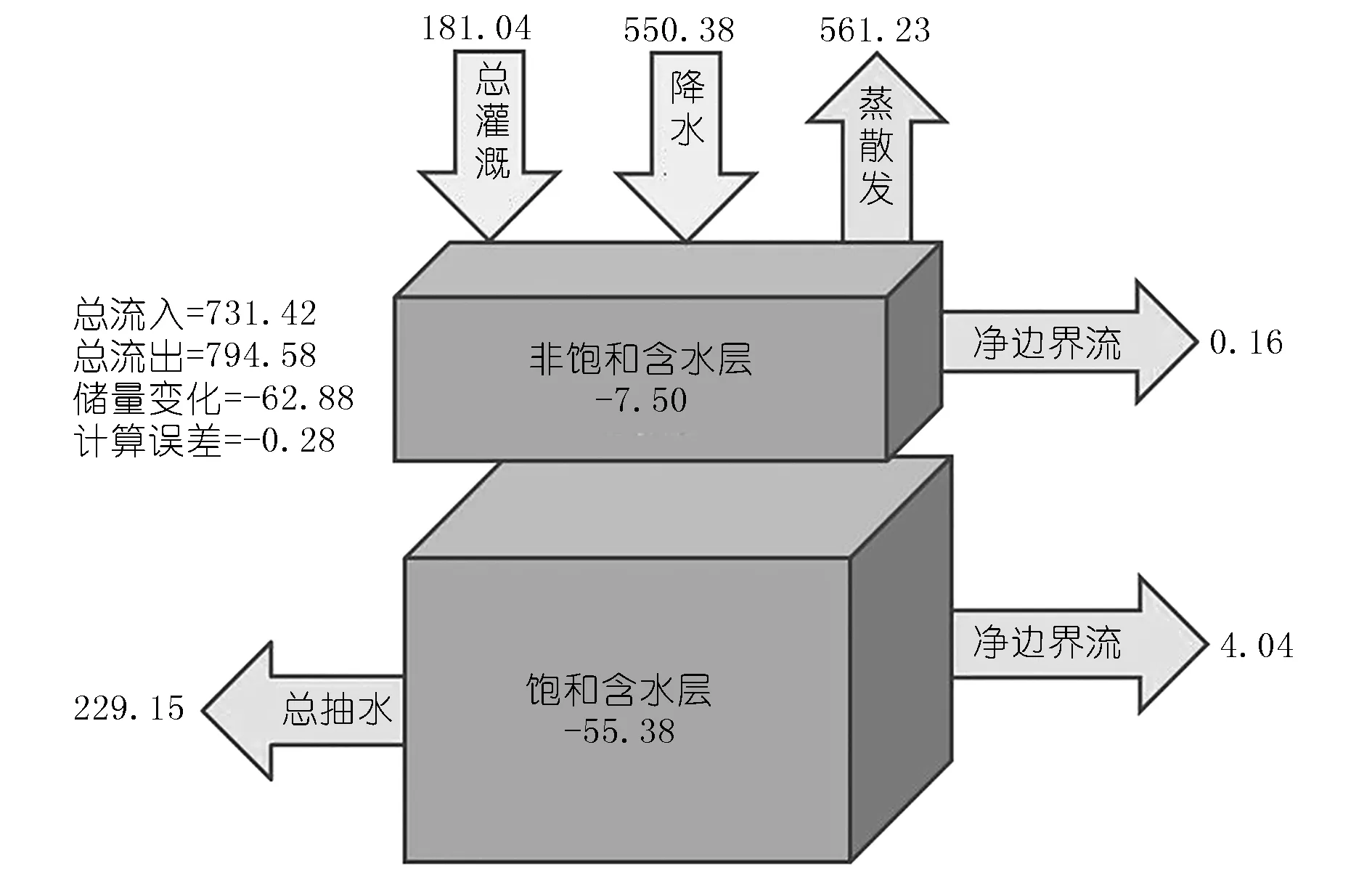
图6 华北平原含水层系统年均水均衡结果(单位:mm/a)Fig.6 Annual average water balance of aquifer systemin the NCP
3.4 可持续水管理分析
基于蒸散发是系统中唯一真正消耗的水[38]的事实,考虑到研究区蒸散发量约占总流出量的70.6%,因此减少蒸散发是缓解研究区缺水压力的一种有效且可行的方法,与此相对应的具体措施包括节水技术的更新和改进、作物轮作方式的改变等等。从表4可以看出,模拟期内研究区用于灌溉、工业及居民生活的地下水开采量占总开采量的比例分别为79%(从2000年的83%到2008年的77%)和21%(从2000年的17%到2008年的23%),意味着工业的迅速发展和城市化进程的加速给研究区带来了供水的巨大压力,进而给研究区地下水的开采和水资源的可持续发展带来压力。鉴于地下水是研究区供水的主要来源,对地下水的保护在研究区水资源可持续管理中起着举足轻重的作用。有鉴于此,一些有利于缓解水资源供需压力的措施,如从区域外调水、使用其它地表水作为供水来源、采取减少蒸散发的措施(改变作物轮作方式、节水措施的改进等)等,是研究区未来应该采取的方案。作为研究区最大的水资源消耗者,农业用水效率的提升是政府部门关注的焦点。诸如畦灌、低压管道灌溉和喷灌等节水灌溉技术[39],可以代替目前研究区广泛使用的漫灌技术,从而有助于节水措施的实施,保障研究区水资源的可持续发展。
南水北调工程开始向研究区供水后,将提供额外的地表水给研究区的农业灌溉、工业生产和城市生活,从而减少地下水的开采量,这对于研究区地下水的保护和缺水问题的缓解起着重要的作用[31]。除此之外,由于水资源的污染会加重缺水问题[31],对于研究区地表水和地下水水质的保护也十分重要。处理后的污水可以被重新用于工业生产和城市绿化等方面,可有效减少相应的地下水开采量,帮助缓解研究区的缺水问题。减少用水量和控制水污染相结合,对于研究区水资源的可持续管理具有显著的作用。
4 结 论
(1) 本文建立了华北平原基于MIKE SHE的地表水-地下水耦合的分布式水文模型,模拟了主要陆面水文过程,如坡面流、河流和湖泊、不饱和流、蒸散发、饱和流、地下水开采和农作物灌溉,在此基础上对华北平原水均衡及可持续水管理进行了分析。
(2) 研究区大部分水(70.6%)通过蒸散发的形式离开,而其余的水通过地下水开采的形式离开,这表明研究区水均衡存在明显的亏缺。就模拟期平均来说,总流入、流出量分别是731.42 mm/a和794.58 mm/a,由此造成非饱和含水层和饱和含水层7.50 mm/a及55.38 mm/a的储量消耗。模拟期内总蒸散发量大于总降水量,由此导致饱和及非饱和含水层储量的消耗,总消耗量分别为480 mm和65 mm。
(3) 可持续水管理是华北平原社会经济发展中的一个关键问题,水均衡分析对于华北平原可持续水管理具有重要影响,与此相关的建议包括减少蒸散发、南水北调工程调水、节水灌溉技术推广和水质保护。
(4) 蒸散发是水均衡要素中最重要的流出部分,而且是系统中唯一实际消耗的部分。因此,可以采用诸如改种耗水少的作物和杂粮作物、休耕土地和城市化等有效措施,来减少蒸散发。这将有助于减少缺水的压力,确保华北平原未来水资源的可持续发展。
