朴素Bayes分类器文本特征向量的参数优化
2019-11-28方秋莲王培锦郑涵颖吕春玥王艳彤
方秋莲,王培锦,隋 阳,郑涵颖,吕春玥,王艳彤
(中南大学 数学与统计学院,长沙 410083)
随着互联网的迅猛发展,产生了大量的文本数据,处理文本数据的基础是文本分类.在文本数据中多数为新闻数据,目前新闻文本数据的分类仍采用由编辑者进行人工分类的方法,这种方法不仅耗费了大量人力、物力,而且可能存在分类结果不一致的情况[1],因此急需建立一个自动文本分类器解决上述问题.
一个文本分类器的实现主要包括下列3个步骤:1) 特征提取;2) 建立分类器;3) 结果输出.在特征提取方面,常用的方法有文档频率(document frequency,DF)法、信息增益(information gain,IG)法、互信息(mutual information,MI)法以及TFIDF(term frequency-inverse document frequency)算法等[2].DF法、IG法和MI法都假设信息量较少的词对文本的分类过程没有影响,但这种假设在分类问题中通常并不成立,所以在实际应用中其很少被单独使用.而TFIDF算法的优势是其能同时考虑到低频词和高频词对分类过程的影响,因此其特征向量提取的效果相对较好.在建立分类器方面,目前较流行的分类算法有最小距离分类器、K-最近邻分类器和朴素Bayes分类器等.最小距离分类器适用于类间间距大、类内间距小的样本[3];K-最近邻分类器中K的选择存在较大的主观性;而朴素Bayes分类器适用于一般分类样本且不受主观因素影响,所以被广泛应用.在结果输出方面,通常用准确率或查全率评价分类器的优劣,而为了更全面地研究分类器的输出结果,庞剑锋等[4]将两者结合提出了检测结果更精准的F1测试值指标.
本文考虑朴素Bayes文本分类器对中文新闻文本的分类问题,使用N-gram算法和TFIDF算法提取文本的特征向量,通过Python软件实现对中文新闻文本的自动分类.在参数选择方面,本文讨论了N-gram算法的参数N、特征向量长度及特征项词性等对文本分类效果的影响,并得到了参数的最佳取值.
1 特征向量提取
在处理中文文本时,为了增加文本对计算机的可读性,通常选择对文本进行向量化处理,如将文本d用向量V表示,记为V=(v1,v2,…,vn),其中vi是第i个特征项.在提取特征项时,需选择一个合适的特征项,使其既能体现所属类别的特点,又能区别于其他类别.由于中文文本没有像英文文本一样的自然分词,所以在提取特征向量前需先对文本进行分词处理,再用N-gram算法提取文本特征向量.在选择特征项时,还可以考察低频词和高频词对文本分类结果产生的不同影响,即使用TFIDF算法提取特征向量.
1.1 N-gram算法
当分析文中一个词出现的概率时,通常假设该词出现的概率仅与其前若干个词相关,所以可以用条件概率表示该词的出现概率,于是一个文本出现的概率可用每个词出现概率的乘积表示:
P(S)=P(w1,w2,…,wn)=P(w1)P(w2|w1)…P(wn|wn-1,…,w1),
其中:S表示一个文本;wi(i=1,2,…,n)表示文本中的第i个词.
基于Markov假设[5]的N-gram算法认为在文本中第n个词出现的概率仅与其前(N-1)个词相关,其中N (1) 同理可得3-gram和4-gram模型.3-gram模型表示为 P(S)≈P(w1)P(w2)P(w3|w1,w2)…P(wn|wn-1,wn-2); 4-gram模型表示为 P(S)≈P(w1)P(w2)P(w3)P(w4|w1,w2,w3)…P(wn|wn-1,wn-2,wn-3). 在使用N-gram算法对文本进行特征提取时,需主观赋值N. TFIDF算法的基本思想是对于一个在数据集中较少见的词,若其在某文本中频繁出现,则其很可能反映该文本的重要特征[6]. 1.2.1 特征项频率 特征项频率(term frequency,TF)用于表示某词i在文本j中的频率,记为 (2) 1.2.2 反文本频率 反文本频率(inverse document frequency,IDF)表示如果一个词普遍存在于各类文本中,则该词对于分类过程不重要[7],词i的反文本频率可记为 (3) 其中:N表示测试集中总文本数;ni表示包含词i在测试集中的文本个数.为使式(3)有意义,引入一个极小的常数c[8].于是,TFIDF算法的经典计算公式为 TFIDFij=TFij×IDFi, (4) 其中,TFIDFij值越大表示词i对文本j越重要. 朴素Bayes分类器在文本分类领域应用广泛,其主要利用文本类别的先验概率和特征向量对类别的条件概率计算未知文本属于某一类别的概率.Bayes分类器基于文本特征项间相互独立的假设[9]. 给定一个文本d,特征向量为V=(v1,v2,…,vn),于是d被分类到类别ck的概率为 (5) 其中:P(ck)表示类别ck的概率,为避免P(ck)=0,采用Laplace估计定义概率[8]为 (6) |C|表示训练集中类的数目,Nck表示类别ck中的文本数目,Nc表示训练集中总文本数目;P(d)表示未知文本d属于某一类别的概率是一个不变的常数, (7) P(vi|ck)表示类别ck中文本含有vi的概率, (8) 朴素Bayes算法是基于Bayes基本原理对已有文本的训练算法,其基本思想是计算未知文本d属于各类的概率,然后将其归类于c1,c2,…,cn这n个类别中的一个,步骤如下: 1) 利用特征向量提取算法处理待分类文本d,得到特征向量V=(v1,v2,…,vn),由式(8)计算类别ck中的文本含有vi的概率P(vi|ck),其中:i=1,2,…,|V|;k=1,2,…,Nck; 2) 根据式(7)和式(8),计算先验概率P(ck)和P(d); 3) 根据式(5)计算分类的后验概率,即未知文本属于各类的概率P(ck|d),并比较其大小,选择将其划分到概率最大的一个类别,公式为 (9) 图1 文本分类器流程Fig.1 Flow chart of text classifier 在建立文本分类器时,通常把工作分为两部分:第一部分是训练过程,包括训练文本的预处理和特征抽取;第二部分是新文本的分类过程,包括新文本预处理和结果输出.文本分类器流程如图1所示. 在训练文本预处理阶段,先用Python的 jieba分词组件对训练集文本进行分词处理,同时去除停用词和可能存在的空格或标点符号;然后将文本打乱,随机分成训练集和测试集.在训练集特征抽取时,本文选择N-gram算法,提取出现词频前(N-1)个词作为特征项组成各类文本的特征向量. 在分类过程中,首先对新文本进行预处理,使用TFIDF算法将文本转化成向量的形式,然后利用朴素Bayes文本分类器对新文本进行分类. 在朴素Bayes文本分类器中,除数据集的容量会影响分类的准确性外,还有一些相关参数的设定也会对分类效果产生较大影响.本文通过实验分析以下3个参数的取值问题: 1)N-gram算法中参数N; 2) 各类别特征向量长度n; 3) 特征项的词性. 本文选取近年各大新闻网站的新闻文本,该数据集包括汽车、娱乐、军事、体育、科技等5个新闻类别,每个类别选取20 000个新闻文本,随机选取66 446个样本作为训练集,用于分析gram的长度及特征向量长度对分类结果的影响.本文重新搜集了80个测试样本(新测试样本与上述数据集交集为空),用于分析文本特征项词性对分类结果的影响. 在分析朴素Bayes文本分类器的结果输出阶段,为同时考虑准确率和查全率,本文采用F1指标度量分类结果[3]: (10) 3.2.1 gram长度及特征向量长度 将数据集分成由66 446个文本组成的训练集和33 554个文本组成的测试集.通过设置不同的gram长度和特征向量长度,研究相关参数的最优设置,所得结果列于表1. 表1 不同gram长度及特征向量长度下的分类准确性 图2 不同gram长度和特征向量长度下的分类准确率Fig.2 Classification accuracy under different gram lengths and feature vector lengths 由表1可见,对于任意的N-gram模型,如果特征向量的长度小于10 000,则分类器的准确率都小于0.85.为保证分类器的准确率,本文仅研究特征向量长度大于10 000的情形.当gram长度固定时,特征向量越长分类准确率越高,但在实际应用中还需考虑时间成本,因此特征向量不宜过长. 图2为不同gram长度和特征向量长度下的分类准确率.由图2可见,当特征向量的长度从10 000增加到15 000或从20 000增加到25 000时,分类准确率的增加最明显,分别提高了0.009 3和0.007 9. 3.2.2 特征向量词性 在使用TFIDF算法时,适当地选择特征项词性可在很大程度上降低文本分类的时间成本,并提高分类准确率.本文考察了特征项既有名词和又有动词、仅为名词、仅为动词这3种情况对分类的影响,结果列于表2.由表2可见:当未知文本特征项词性为动词和名词时,朴素Bayes文本分类器的文本正确分类数量最多,为53个;仅为名词时次之,为49个;仅为动词时最差,为34个.这主要是因为新闻类文本的特征项大多数为名词,去掉动词特征项对特征向量影响较小,所以当特征项仅为名词时,正确分类数量下降不明显;但若去掉名词特征项将对特征向量产生巨大影响,进而使分类错误概率极大增加. 表2 朴素Bayes文本分类器的分类结果 表3列出了朴素Bayes文本分类器的分类准确率、查全率及F1指标值.由表3可见,当未知文本特征项词性为动词和名词时,F1指标值最大为0.662 5,说明分类效果最好;仅为名词时,分类效果与为动词和名词的情况相差较小,达0.612 5;仅为动词时分类效果最差,仅为0.425.所以,在对F1指标的大小要求不严格但对训练时间限制严格的情况下,可以仅选择名词作为特征项. 表3 朴素Bayes分类器分类结果的相关指标 综上所述,本文建立了用于处理中文新闻文本分类问题的朴素Bayes文本分类器,在训练阶段采用N-gram算法提取各类文本的特征向量,在实验阶段使用TFIDF算法提取未知文本的特征向量.由于N-gram算法处理训练集的速度比TFIDF算法快,所以本文针对不同数量级的数据集采取不同的特征提取算法,即对训练集使用N-gram算法,对未知文本使用TFIDF算法.在此基础上,本文还考察了构建文本分类器中抽取特征向量阶段的参数选择问题,即N-gram模型中的N、特征向量长度n和特征向量词性等3个参数,得出结论如下: 1) 对于新闻类文本,2-gram模型和4-gram模型的分类准确性较高; 2) 在N确定的条件下,特征向量长度与分类准确率成正比;特别地,当向量的长度从10 000增加到15 000和从20 000增加到25 000时,分类器准确率增幅最大; 3) 对于TFIDF算法,特征项词性为动词和名词时分类准确率最高,特征项仅为名词时准确率降低,仅为动词时准确率最低,所以在选择词性时应避免仅选择动词.
1.2 TFIDF基本原理
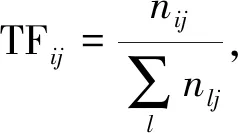
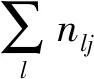

2 Bayes算法
2.1 Bayes基本理论



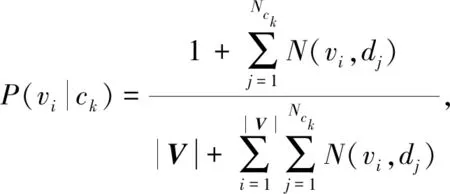

2.2 朴素Bayes算法

2.3 朴素Bayes分类器设计

3 实 验
3.1 实验数据集及评价指标
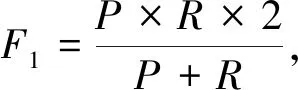

3.2 实验结果与分析




