电子病历文本分析系统的设计
2019-11-27李天凤杨凌燕黄艳平
李天凤 杨凌燕 耿 娟 杨 珂 黄艳平
电子病历(electronic medical record,EMR)是指基于信息化技术,可提供患者临床数据访问、预警及临床决策支持服务的电子化记录系统。按照国家卫生部颁发的《电子病历基本架构与数据标准电子病历》要求,EMR不仅应包含患者门诊及住院过程中的诊疗和诊疗记录,还应包括病历分析相关服务[1]。据统计,EMR中85%以上为非结构化信息,如以自然语言记录的患者主诉、临床医嘱等医疗记录[2]。但非结构化文本数据无法直接应用,需要针对不同应用需求选择对应的文本分析方法[3]。
随着医疗信息化技术的发展,医疗EMR中积累的非结构化文本数据增长速度快、来源复杂,因此需要建立专项EMR文本分析系统。为此,本研究电子病历文本分析系统具有兼容性,能够满足不同类型的文本应用需求,同时,建立快速处理机制,可满足海量非结构病历数据分析需求。
1 EMR文本分析系统功能
EMR文本分析系统需要实现以下功能。
(1)建立具有扩展性的数据访问机制。作为医疗信息的重要组成,EMR数据主要来源于医院信息系统(hospital information system,HIS)、检验系统及影像系统等,同时,考虑不同医疗机构特点及临床信息化发展,需要建立简便易行的数据访问机制。
(2)分析引擎可定制。病历文本分析功能包括文本初始化、分词、检索以及分析挖掘等功能[4]。不同的分析功能需要不同的分析算法和分析引擎,因此系统需要能够实现分析功能扩展。
(3)分析效率。随着医疗信息化的发展,EMR数据来源及规模逐渐扩展,尤其是面对用户实时分析请求时,传统分析方法已无法满足数据分析需求,需要建立快速分析方法,解决EMR文本分析效率问题。
2 EMR文本分析系统设计
系统设计基于分层结构实现,其中包括存储层、数据访问层、服务层、业务层及表现层。系统在运行中,可由存储访问功能定期抓取非结构化原始数据文件,经服务层数据预处理将数据整合形成顺序文件后,并行化调用文本分析引擎,并在存储层将分析结果实现持久化。当用户通过表现层发出应用请求时,业务层对应功能响应请求并调用服务层功能,访问存储层文本分析结果并返回表现层,实现用户交互,见图1。
2.1 存储层
存储层基于Hadoop分布式文件系统(Hadoop distributed file system,HDFS)实现[4-5]。该框架基于分布式存储管理并采用流数据访问模式,能够实现并行化数据访问及超大文件处理,具有高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征[6-7]。同时,存储具有灵活性,可结合临床业务需求动态扩增存储规模,可满足海量EMR文本分析系统的应用需求[8]。
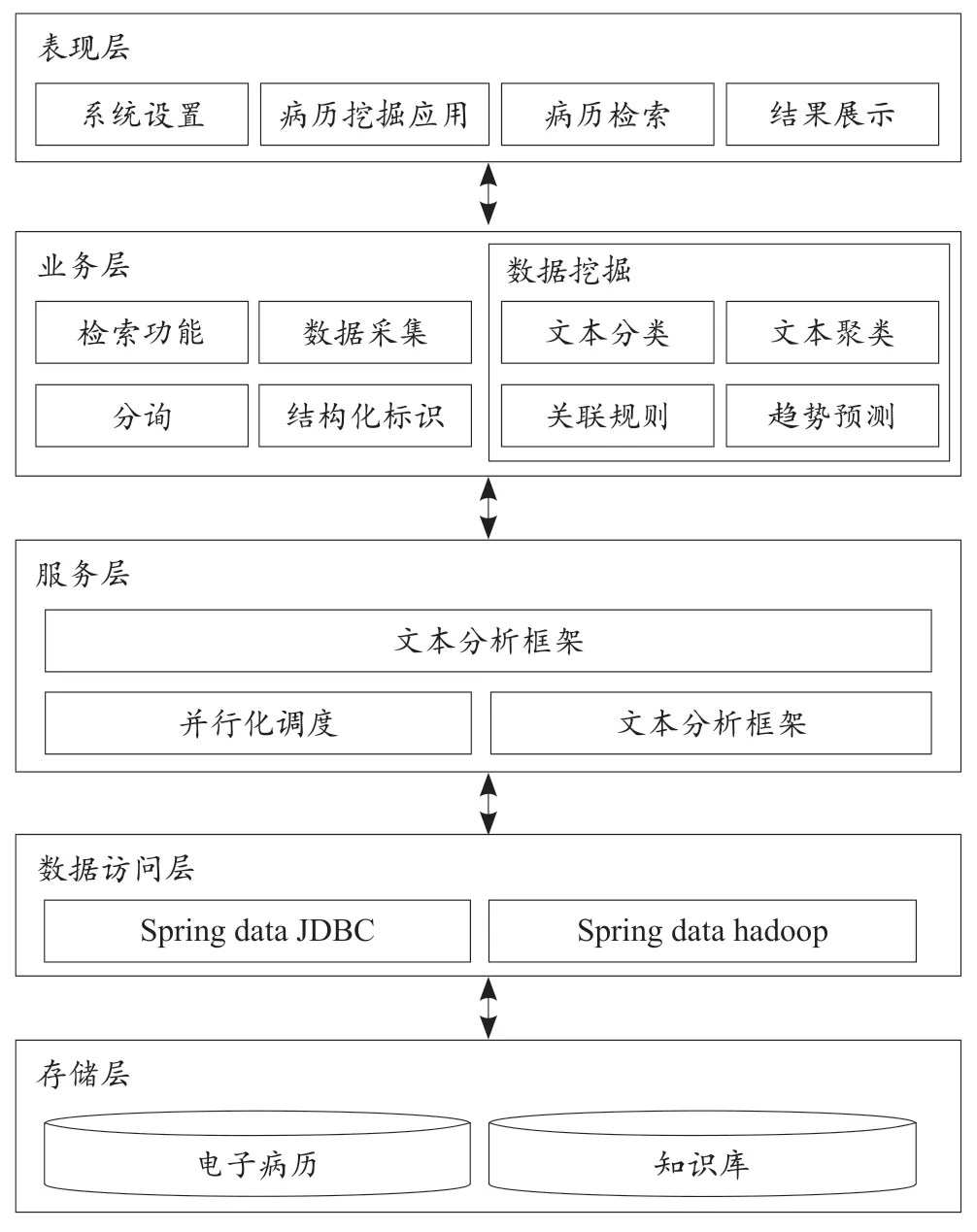
图1 EMR文本分析系统架构
2.2 数据访问层
数据访问层提供了不同数据源信息访问功能,系统采用Spring data作为数据访问接口,不仅可实现传统关系型数据库接口,而且可实现HDFS数据访问功能。
(1)结构化数据访问。系统采用Spring data框架并基于Java数据库连接(Java database connectivity,JDBC)实现Oracle等结构化关系型数据访问功能。系统通过Maven引入Spring-data-jdbc包实现调用:


(2)非结构化数据访问。系统采用Spring for Apache Hadoop实现数据访问,可支持Map Reduce、Streaming、Hive、Pig及Hbase等扩展工具,可通过Spring Batch为HDFS操作提供工作流支持,降低功能复用性。系统通过maven引入Spring-data-hadoop包实现调用:

2.3 服务层
服务层主要包括并行化调度及文本分析框架等功能,为具体业务提供基础服务支持。具体包括并行化调度、文本分析框架、非结构化信息管理应用程序(unstructured information management applications,UIMA)和Hadoop整合、业务层和表现层。
(1)并行化调度。系统采用并行化调度加快数据处理,并行化调度基于Hadoop Map Reduce计算模型,该模型实现了并行计算框架,通过将计算过程分解为Map和Reduce两部分,结合HDFS分布式存储,自动实现文本分析任务的并行化处理[9]。系统并行化计算流程采用如下方式进行:在任务计算前,划分计算数据,将数据映射为键值对,并将键值项自动分配在计算集群节点中;在计算过程中,将文本分析引擎载入Map过程,计算完成后,在各个节点上收集计算结果,并通过指定Reduce函数整合分析结果,提高计算效率[10]。该框架提供了开放性流程设置接口,用户可通过指定具体文本分析引擎能够自动实现海量EMR文本分析分布式计算,同时能够自动实现分布式存储、集群通信、数据容灾等技术细节,提高了开发效率并降低了实现难度[11]。
(2)文本分析框架。文本分析框架基于UIMA实现,UIMA是一个用于分析非结构化内容的组件架构和软件框架实现。该框架提供了非结构化信息分析通用流程,可提高非结构文本分析开发效率[12]。该框架由收集器(collection reader,CR)、分析引擎(analysis engine,AE)及通用分析结构消费者(common analysis structure consumer,CASC)等组件组成[13]。其中,CR组件实现非结构化信息的获取过程。CR通过调用数据访问层Spring-datahadoop接口从分布式存储HDFS数据源中收集信息,形成文本包并推送给AE组件。为提高数据采集速度,系统分别针对患者首页、诊疗过程记录、检验记录、检查、医嘱、手术、护理及生理参数监控等具体场景,派生CR接口定制资源获取器,并针对不同接口建立收集方法。由CR组件将采集到的文本信息经预处理后转换为UIMA通用分析结构(common analysis structure,CAS),实现UIMA不同组件间数据交互[13]。AE作为文本分析的功能组件,可实现从非结构化文本进行具体分析的功能。框架根据应用需求选择对应的分析引擎,AE从CR获取CAS分析对象,根据用户需求对CAS中的标注和元数据等信息执行相应的处理,分析结果根据不同应用需求推送到不同的CASC组件。
(3)UIMA与Hadoop整合。系统服务层采用Hadoop Map Reduce调度UIMA EMR分析引擎实现。具体流程包括:当用户发出文本分析请求后业务层调用服务层提取数据,经预处理后完成数据准备过程。Hadoop启动Job Tracker执行分析操作,通过分布式计算引擎将任务及数据自动分发到集群上执行。集群上各节点执行文本分析通过调用UIMA集合处理引擎(collection processing engine,CPE)实现[14]。CPE作为UIMA引擎基础执行组件,可独立实现文本分析部署、启动、执行及异常处理等操作,包括CR、AE及CASC组件。CPE根据用户需求调用AE处理CAS信息,完成处理后在集群各计算节点内形成临时处理结果,完成Map执行过程。经Reduce执行后,整合Map中间结果,实现数据整合,生成并将最终CAS结果存储到知识库中,见图2。
2.4 业务层
业务层基于服务层功能实现平台功能,包括数据源管理、数据采集、数据预处理、分析功能等,其中包括非结构化数据源管理、数据采集、分词、结构化标识、检索功能以及数据挖掘。
(1)非结构化数据源管理。系统基于Spring data数据访问组件实现动态数据访问,用户可建立参数配置,建立并修改数据源,系统通过维护“应用描述-数据源参数文件”映射实现该过程。
(2)数据采集。系统通过调用不同数据源配置,调用Spring data具体数据访问接口实现不同来源数据访问,访问数据经初始化后,由UIMA分析引擎中CR组件形成CAS信息。
(3)分词。系统支持用户选择词典分词法、逆向最大匹配算法RMM及最佳匹配法等实现分词功能。
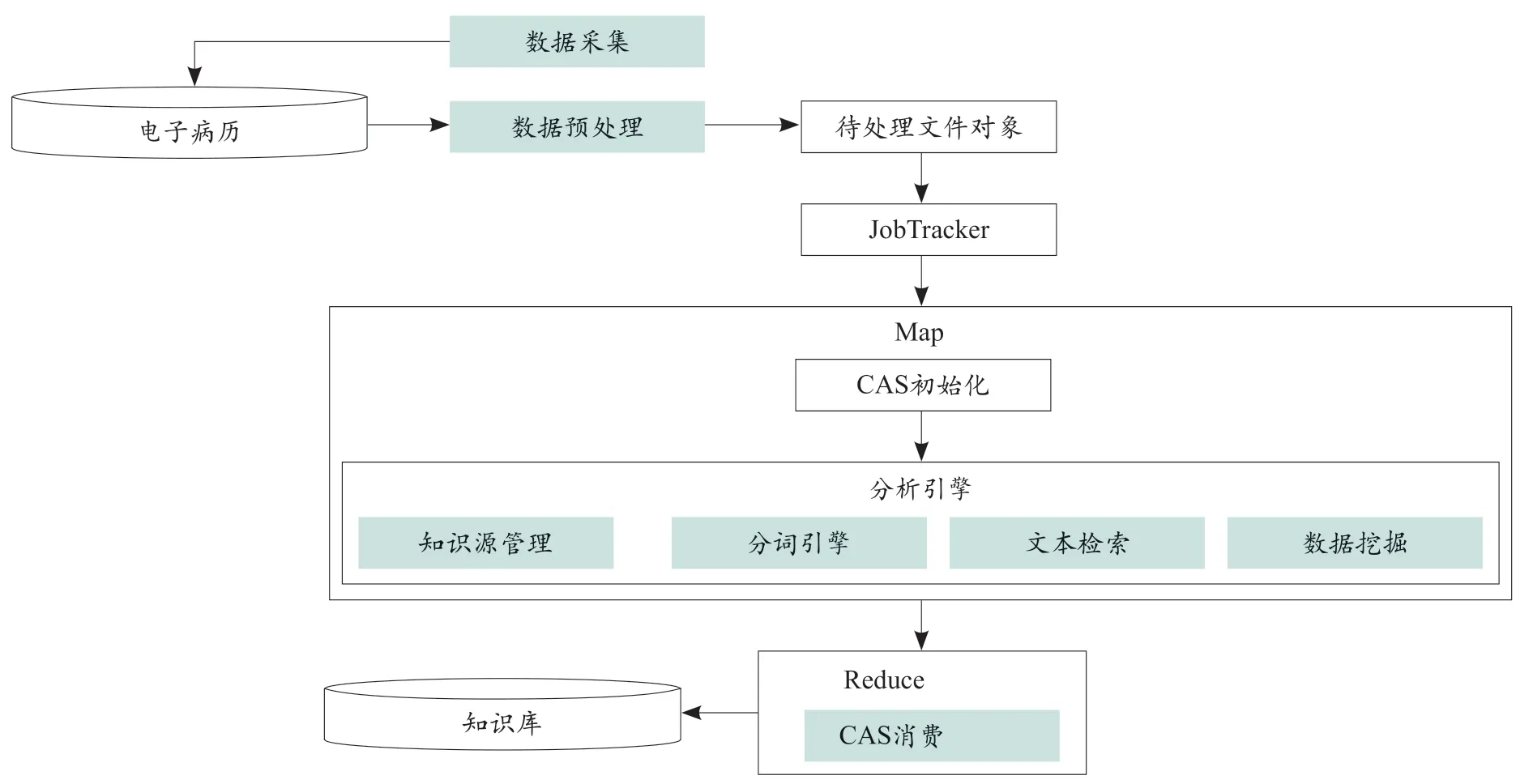
图2 UIMA及Hadoop整合策略流程
(4)结构化标识。系统可将EMR记录统一到设定的词向量空间中,实现词库维护[17]。其流程包括:剔除重复词汇、错误修正、垃圾词汇删除、无语义词汇清楚、建立词典及对应权重矩阵等。
(5)检索功能。系统检索功能采用Lucene检索引擎实现,该组件采用面向对象设计,引擎架构定义了功能实现接口,开发可结合业务特点定制实现过程,同时,该引擎屏蔽了底层实现过程,降低了开发难度。系统采用Lucene检索引擎实现文本索引库记录更新功能:


系统检索功能通过Spring Data for Elasticsearch实现,系统基于Elastic Search Template类及各个病历记录结构派生对应检索类,实现Elasticsearch快速访问。检索结果通过标准记录结构文档与简单Java对象(Plain Ordinary Java Object,POJO)之间的自动智能映射建立持久化对象,并实现JavaScript对象交换格式(JavaScript Object Notation,JSON)结果拼接,最终调用持久化对象序列化功能完成结果传递。
(6)数据挖掘。EMR文本挖掘应用主要包括文本分类、文本聚类、关联规则提取及趋势预测。系统可结合用户需求动态选择对应数据挖掘引擎完成分析过程。系统在此以文本分类应用为例测试系统分析流程。系统文本分类包括特征提取及分类算法两部分:①用户可选择不同的特征提取算法及分类算法实现分类过程,系统支持的特征提取算法包括词袋模型、TF-IDF、word2vec、doc2vec、隐语义模型及文本主题模型等,分类器算法可选择逻辑回归、支持向量机或梯度提升树[18];②用户设定分类算法及数据筛选条件后,业务层接受用户请求,调用服务层并通过数据访问层检索数据,对象数据经预处理、分词、结构化标识以及采集后完成数据准备,服务层调用Hadoop及UIMA文本框架,将用户分析需求实体化为对应分析引擎后形成MapReduce Job,执行MapReduce过程,目标数据经映射分段后执行并行化分类器分类操作后返回分析结果。
2.5 表现层
系统采用轻量级前端框架Vue.js实现,该框架具有双向数据绑定的优势,可自动响应数据的变化情况,并且根据用户在代码中预先写好的绑定关系,实现数据和视图内容同步,适合EMR分析系统开发场景;同时便于前端设计采用自底向上组件化结构实现。表现层通过用户需求响应,触发对应业务层功能,从而驱动分析过程,生成结果后同步显示在前端组件中,实现用户交互过程。
3 EMR文本分析系统设计应用
3.1 应用分析
EMR文本分析系统测试中采用3台R730XD服务器组成计算集群测试系统功能,单台服务器采用2颗48核心E5-2678V3处理器,1333 MHz 96 G内存。Web服务器采用Tomcat8.5,操作系统Ubuntu16.04。
系统服务部署可通过用户配置实现数据源连接,获取并关联患者及病历相关信息。临床使用科室工作站可通过浏览器访问系统,发送应用请求。系统通过文本检索测试文本分析流程,系统可根据用户检索条件完成检索任务(图3a)。在检查记录检索应用过程中,通过单台主机与并行化集群对比显示(图3b),采用集群分布式运算,系统检索功能能够获得显著提升,同时,在部署过程中,采用Hadoop并行化框架可降低集群部署的难度,在日益增长的EMR分析需求中具有现实意义。

图3 EMR文本分析系统运行文本检索并行化检索速度对比
3.2 应用效果
EMR文本分析系统在后续测试过程中显示,医疗EMR以短文本记录为主,其中2 kb以下文本约占95%。大量小文件调度操作降低了集群读写、存储及分析效率,因此在后续文本分析中,采用小文件校验码与文件建立字典结构,组成文件对象,批量执行分布式操作(图3b),文本分析效率有了较为显著的改善。
4 结语
本研究从EMR需求现状出发,针对目前存在的非结构EMR文本分析缺乏兼顾效率及兼容性分析平台的问题,基于非结构化信息管理工具UIMA及并行化计算框架Hadoop,尝试构建了海量EMR标准化分布式文本分析平台[19-20]。用户可通过系统设置实现数据源配置及管理,并通过分析功能选择,实现数据分析过程,增强了文本分析效率,提高了文本分析能力。同时,对于各医疗机构构建类似系统具有参考意义。
