基于成绩变化趋势的多任务成绩预测模型
2019-11-23李松江苏瑀黄春雨王鹏任涛
李松江,苏瑀,黄春雨,王鹏,任涛
(长春理工大学 计算机科学技术学院,长春 130022)
学生成绩预测已经成为EDM(教育数据挖掘)领域的热门研究方向之一[1],有效进行学生成绩预测对全面提高教学质量,合理分配教学等方面发挥着至关重要的作用。近年来,针对学生成绩预测的相关研究在国内外取得了一定的成果。童睿[2]分析学生消费行为数据与成绩间的关联性,选取消费行为中具有较强关联性的变量,采用机器学习算法对学生成绩进行分类预测。Chen J F和Do Q H等人[3]结合学生标准化的考试成绩及影响成绩的外在因素,将布谷鸟搜索(Cooperative Cuckoo Search)与自适应神经网络推理系统(ANFIS)进行组合用于学生学业成绩预测。Harrell I L和Bower B L[4]针对学生的听课风格、成绩的平均绩点以及计算机掌握情况三个特征向量,利用逻辑回归分析模型对学习者的学期表现进行预测,对可能辍学的学生达到预警效果。韩睿鹏[5]应用FP-growth关联分析算法挖掘影响学生成绩的课程之间的隐藏规则,可以得出前期课程成绩对后续课程成绩的影响,进而为管理人员提供政策指导。
上述文献的研究,重点集中在利用历史绩点、课程成绩和学生消费行为数据,基于同一种参数进行学生成绩预测。忽略了学习状态、学生社交关系导致相互影响的特点对成绩的影响,导致预测精度降低,无法对具体学生进行个性化成绩预测。针对上述不足,本文提出基于历史课程成绩变化趋势的多任务成绩预测模型,该模型首先通过谱聚类算法对课程进行分类,采用加权平均法得到不同学期不同类别的课程成绩变化趋势,用于反映学生每类课程的学习状态,并与历史绩点、学生行为数据共同构建初始变量集。根据学生社交信息交流导致相互影响的特点,引入多任务学习[6-7]结合逻辑回归用于成绩预测,采用一种权重聚类分组方法,将相关任务分为一组,使多个学生成绩预测的任务共同训练预测模型,实现个性化成绩预测。
1 学生成绩影响因素分析
学生成绩受诸多因素的影响,已有的研究多是对历史成绩、上网行为、消费行为等影响因素进行分析,但都忽略了学生学习状态对学生成绩预测的影响[8],本文将按学期和类别定义课程成绩变化趋势变量,用于反映学生的学习状态。最后将课程成绩变化趋势与历史绩点、学生行为数据共同构建初始特征变量集。
1.1 学习状态分析
为更好的反映学生学习状态,分析学生在不同学期中,属于同课程类别的课程成绩之间的变化趋势。采用谱聚类算法[9]对课程成绩的分类,经实验验证,课程1,2,…,k被分为四类。按照分类结果将各个学期的课程进行类别标记。不同学期相同类别的课程按照学期前后顺序进行排列,通过对相邻学期同类别课程间学生课程成绩的变化趋势进行分析,课程成绩变化趋势示意图如图1所示。
从中发现了成绩变化规律:各学期的同类别课程成绩具有一定的线性关系;在这个规律基础上,考虑各门课程成绩所占比重不同,采用加权平均法,根据公式(1)得到学生所学课程成绩的加权平均值ValueiK,定义如下:

式中,i=2,…,m,m≥2,i表示历史学期数;j=1,2,…,n,j表示属于课程个数;cij表示课程所占学分;表示课程学分总和;Sij表示所学课程的成绩;K表示课程的类别数;K∈1,2,3,4。

图1 课程成绩变化趋势示意图
进而根据课程分类结果,计算不同学期同类课程成绩之间的变化趋势:
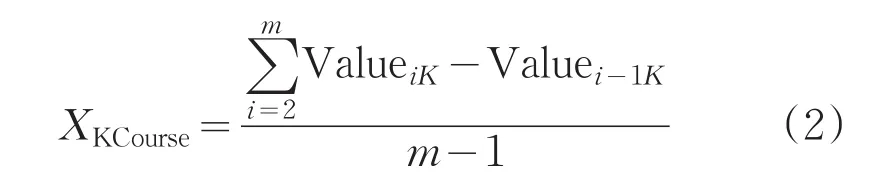
依据公式(2)计算的结果,表示不同学期不同类别的课程成绩数据隐藏的变化趋势,用于反映学生的学习状态。为更清晰的体现出学生在不同学期中的学习状态,本文从14级学生中随机选取单一学生的不同学期下同类别的课程成绩,通过课程成绩的变化趋势进一步分析学生的学习状态,如图2所示。
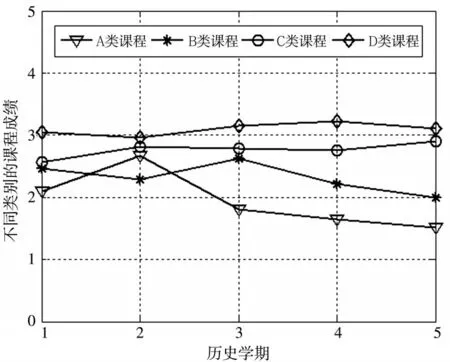
图2 不同学期下同类别课程成绩的变化趋势图
由图2可知,横坐标表示学生的历史学期数,共5个学期,纵坐标表示学生在同一学期课程不同类别的课程成绩加权平均值。该同学在第一学期的期末考试中,A、B、C类型课程总体成绩偏低,D类课程总体成绩相对较好。随着时间的推移,该同学对这四种类型课程的态度表现为成绩越好的课程类型,越喜欢学习,越不好的课程,越不喜欢学习,一定程度反映学生对待不同类别课程的学习态度和状态,进而影响总体的学生成绩。由此得到结论:不同课程类别的成绩变化趋势反映学生对于不同课程类别的学习状态,与学生的学习成绩具有较强相关性。
1.2 学生行为分析
在学生行为中,文献[10]提出了消费行为、上网行为是学生学习成绩的影响因素,因此本文重点对消费行为以及上网行为数据进行定性定量分析,构建多维度学生行为数据,作为成绩预测的特征向量。
(1)消费行为分析
①早餐活跃度分析
对学生早餐行为的定量统计分析,本文引入文献[11]提出的活跃度概念,对学生早餐行为进行刻画,早餐活跃度XBreakfastParoxysmal,计算公式为:
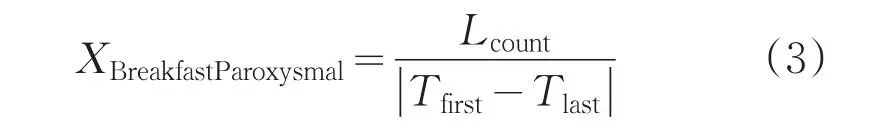
式中,Lcount表示某学生吃早餐次数表示学生一学期吃早餐的第1次记录和最后1次记录之间间隔的天数。
②消费规律分析
学生消费行为具有时间序列特性,针对学生消费的时间间隔分布情况,本文结合人类行为动力学,引入阵发性概念[12-13],以学期为单位来刻画学生的消费规律XConsumpParoxysmal,进而反映学生是否按学校正常作息时间去食堂消费。如式(4)所示,即:
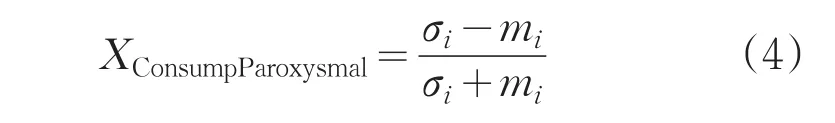
式中,mi,σi分别为连续消费行为间隔时间分布的平均值和标准差。
(2)上网行为分析
从上网行为角度来看,文献[14]针对上网行为进行分析,并提出上网时长是影响学生学习质量的主要因素。由于正常的作息时间应为早睡早起,如果学生在十一点学校熄灯后,还在继续熬夜上网,上网时间长,会影响第二天的学习状态。因此按照学校作息时间安排,时间阈值设定为晚上十一点后,计算熬夜上网次数,统计以学期为单位有效学习时间内上网时长和上网流量。
将公式(3)、公式(4)得到的指标结果以及上网时长、熬夜上网次数、上网流量数据进行归一化处理,并与学生成绩进行相关性分析。针对光电和经管学院2014级学生在2017年3月至2017年8月的行为指标结果与该学期的期末成绩,采用Pearson相关系数定量描述其线性关系,绘出学生行为指标与成绩相关性分析直方图,如图3所示。

图3 行为指标与成绩的相关性分析
由图3可知,两个学院学生的行为指标中前四个指标与成绩的相关系数较高,全部都在0.5以上,而上网流量的相关系数小于0.5,可以看出上网流量与成绩的相关性较弱。因此选择前四个相关性较强的指标作为成绩预测的特征向量。
在学生成绩预测中,输入变量代表着不同的参数信息对学生成绩的影响,变量的选取是构建学生成绩预测模型的基础,是进行有效、精准预测的依据。使用2014级学生在2014年至2017年6个学期的成绩数据,将第6学期成绩作为预测成绩,与其相邻的前5个学期历史成绩进行相关性分析,通过Pearson相关系数分析后得到前三个学期的成绩与预测成绩具有较强相关性。再将学生行为通过上述分析后筛选出对学生成绩预测较为重要的变量。本文将课程按照历史课程成绩关联度分为4类,基于历史课程成绩与学生行为对初始特征变量集向量进行定义,如下所示:

式中,Xt-3为前三个学期的学生成绩(GPA);Xt-2为前两个学期的GPA;Xt-1为前一个学期的GPA;XACourse为不同学期A类别的课程成绩变化趋势;XBCourse为不同学期B类别的课程成绩变化趋势;XCCourse为不同学期C类别的课程成绩变化趋势;XDCourse为不同学期D类别的课程成绩变化趋势;XBreakfastParoxysmal为以学期为单位早餐行为的频率;XConsumpParoxysmal为以学期为单位消费行为的规律;XInternetTime为以学期为单位有效学习时间内上网时长,XNightCount为以学期为单位超过晚十一点上网的次数。
2 学习成绩预测模型构建
目前成绩预测模型大多需要对学生的成绩进行全局的预测,存在同质性并且无法对具体的学生进行个性化预测的缺陷,忽略了学生之间的相互影响作用,不能更精准的预测学生成绩。在校园生活中,由于学生之间存在社交影响力作用[15-16],因此可认为每个学生成绩之间存在相关性。在预测学生成绩时,充分考虑该特性对学生成绩的影响来提高预测性能。
本文根据学生之间进行社交信息交流的特点,引入多任务学习(MTL),以逻辑回归预测模型作为基准算法,预测模型把每个学生成绩的预测对应为多个任务,根据学生间的社交影响特点对这些任务进行关联。由于MTL是通过权重共享实现的,利用K-means对顶层的权重聚类,将具有相似权重的分布任务分为一组,组内任务共同训练,共享任务间的相似性提高模型学习能力,从而缓解小样本过学习问题,具体的网络结构如图4所示。
假设共有m个任务Mm={xir,yir}lri=1,M为这m个任务的合集。将每个学生的成绩预测对应一个独立的任务,定义每一个任务需要学习的权值向量Vi,任务目标分为两部分:wq+wg,r∈(1,2,…,m),wq代表全局任务的权值特征向量,wg代表相对于单个学生的局部权值特征向量。wq是根据所有学生行为数据历史成绩数据进行学习得到的,wg是对单个学生的学习行为及历史成绩数据进行学习得到的向量。以逻辑回归为基准算法对学生成绩进行预测,其带有正则化的目标函数为:
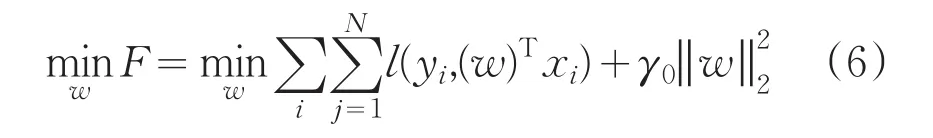
则引入多任务后的预测模型可归纳为:
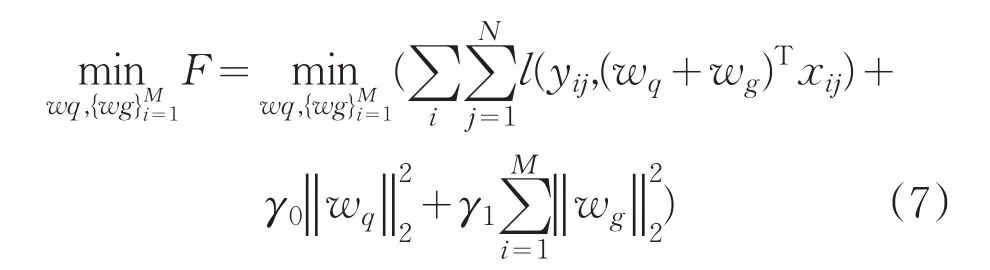
式中,M为学生数量;xij表示学生i的第j个数据样本点;wq和wg同时训练计算出结果。所有的任务都具有相同的wq,各个任务拥有自己的wg,通过正则化系数γ0,γ1的权值调整,能够调节个性化对模型的影响。

图4 多任务逻辑回归预测
多任务逻辑回归进行学生成绩预测,根据网络结构顶层权重进行分组,将具有相似权重分布的任务分为一组,组内任务同时训练模型并共享信息。既考虑到了任务之间的差别,又考虑到任务之间的联系,通过共享隐层权重,提高预测精度。相对于单任务学习仅需要训练一个模型,该模型可同时训练出多个模型,从而对学生成绩进行个性化预测。
3 实验结果与分析
3.1 实验数据
本文针对学生成绩预测问题的研究,提出了基于成绩变化趋势的多任务成绩预测模型,为验证该预测模型的准确性与适用性。实验选取2014年9月至2017年8月学生的课程信息及行为数据作为实验数据集,数据量约为5 000条,选取90%的学生样本数据集作为训练数据集进行归一化预处理来产生输入输出向量,10%的学生样本数据集作为测试数据集对网络性能进行评价。
3.2 评价指标
为进一步对所提出的预测模型的性能进行评价,本文选用均方根误差(RMSE)、平均绝对百分误差(MAPE)这两个性能指标来衡量。具体公式如下所示:


3.3 预测结果对比分析
本文利用TensorFlow进行基于成绩变化趋势的多任务成绩预测模型的实现。根据第1节对成绩影响因素分析得到的初始变量集作为预测模型的输入,学生成绩作为预测模型的输出。为检验学习状态对预测成绩的重要性,利用逻辑回归模型分别对加入反映学习态度的课程成绩变化趋势指标和未加入该指标的学生样本数据集进行成绩预测,对真实值和预测值进行比较,通过误差评价指标进行性能评估。为验证根据学生之间相互影响这一特点而引入多任务学习的逻辑回归预测模型的有效性,将学生真实成绩和经过逻辑回归和多任务逻辑回归两个模型的预测成绩进行对比,检验模型中预测值和真实值的拟合程度。为进一步验证相关任务分组对成绩预测的有效性,利用权重聚类分组将相似任务分为一组,与随机分组的任务分别采用多任务逻辑回归模型进行成绩预测,利用误差评价指标进行性能评估。
实验1:加入成绩变化趋势指标与未加入该指标的性能比较
为了验证学习状态对学生成绩预测中的有效性,使用加入成绩变化趋势特性和未加入该特性的逻辑回归预测方法相比较,两个方法针对所有学生进行成绩预测。两种方法的性能指标对比如表1所示。

表1 性能指标对比
由上述实验结果分析,加入成绩变化趋势特性的预测误差更小,预测精度有所提高。将这两种方法与真实的成绩预测值进行比较,由于学生样本数较多,图5中只选择了2014年9月至2017年8月部分学生样本数据集的成绩预测值与实际成绩值的分布图进行展示。
从图5中可以看出,在对实际成绩的预测结果中,加入成绩变化趋势特性的预测结果与实际成绩数据偏差较小,更加接近真实成绩曲线,从而验证了加入成绩变化趋势特性对成绩预测的有效性,进一步说明成绩变化趋势这一特征向量所反映的学生学习状态对成绩的影响程度。
实验2:逻辑回归与多任务逻辑回归预测结果对比
为了验证多任务学习对学生成绩预测中的有效性,对比图5(b)的逻辑回归和多任务逻辑回归两个模型的预测成绩与真实成绩。图6为部分学生基于多任务逻辑回归模型的预测结果与真实值对比。

图5 两种方法与真实值对比

图6 多任务逻辑回归预测值与真实值对比
图6相对图5(b),该方法的误差更接近于真实值,具有更好的效果,说明根据学生之间相互影响这一特点而引入多任务学习对成绩预测的有效性。这是因为在多任务学习过程中,多个学生成绩预测任务同时进行训练,任务之间相互起到了归纳偏置的作用,从而提高了每个任务的预测精度,实现个性化成绩预测。
实验3:验证权重聚类相关任务分组的有效性
利用权重聚类对任务进行分组,将具有相似权重的分布任务分为一组,组内任务具有较强相关性,与随机分组的任务分别使用多任务逻辑回归模型进行成绩预测。由于学生样本数量较多,只选取其中5组作为实验对象,同时依据上述相关任务分组的各组别数据维度,采用随机划分方式对相同学生数据集进行分组,并选取与上述实验对象相同数据维度的5组作为对比实验数据,对比实验数据与实验对象为一一对应关系。预测模型误差比较如图7所示。

图7 两种方法误差值对比
从图7中可以看出,利用权重聚类分组后的5组相关任务,分别与相应数据维度随机划分的5组任务采用误差评价指标相比较。经过权重聚类相关任务分组的5组任务,其MAPE值和RMSE值均比随机分组的误差值小。说明利用权重聚类方法将相关任务分为一组,才能够更好的提高整体性能,不相关的任务可能会对模型训练产生负面影响。
4 结论
本文针对学生成绩预测,提出一种基于成绩变化趋势的多任务成绩预测模型。其中针对单纯依据学生历史成绩或学生行为进行预测的不准确问题,将基于课程分类的学生成绩变化趋势特性与历史绩点、学生行为数据共同作为学生成绩的影响因素。根据学生社会网络关系及相互影响的特点,引入多任务学习,采用权重聚类分组方法,将相关任务分为一组同时训练提高预测精度。实验结果表明,本文所提出的预测模型具有较高的准确性,其预测结果可为大数据技术的多维度高校学情评教分析平台提供数据支持。
