手机分期消费贷款信用风险研究
2019-11-22龙海明邹汉铮朱建
龙海明 邹汉铮 朱建


摘 要:识别手机分期消费贷款违约因子是防范手机消费贷款业务信用风险的关键所在。为此,基于融合随机森林(RF)和逻辑回归(Logistics)两阶段模型,通过数据挖掘揭示风险特征重要性含义,并结合经济计量方法诠释异质性客户信用违约的基准逻辑。结果表明:入网时长、终端个数、客户月流量、终端时长是影响手机分期消费贷款客户信用风险的重要性特征变量,且边际影响分别为-0.039%、3.18%、-0.01%、-1.06%,模型泛化能力强,准确率达到74%。所以,要完善手机分期消费贷款信用风险管理应从交叉数据获取、社交网络、兴趣热点和消费习惯等方面着手。
关键词: 信用风险;随机森林;变量重要性;逻辑回归
中图分类号:F832.4 文献标识码: A 文章编号:1003-7217(2019)05-0027-07
一、引 言
经济新常态下,消费金融由平滑消费、风险管理和资产保值增值等传统职能向消费升级、内需拉动和兼具包容性等新型职能转换。随着5G通讯技术、互联网支付和社交新媒体等快速发展,手机已具备即时通讯、网购消费、投资理财、社交娱乐和商务运用等多样化功能,已成为居民日常生活重要消费品。相关数据表明,截至2018年底中国手机用户规模达到15.7亿①,国内手机市场总体出货量为4.14亿部②,手机产品已成为万亿级消费市场。与手机消费市场蓬勃发展不相适应的是,手机消费贷款缺乏针对特定消费群体的产品设计、模式开发及风险防范机制,尤其是在校学生、农民工等低收入群体信用担保不足,导致校园贷、裸贷、民间贷等乱象丛生,探索手机消费金融已成为继汽车消费金融后的新趋势和新方向。强化对手机消费贷款信用风险的相关研究,不仅可以为消费金融新领域、新业务、新场景提供理论支持,而且通过异质性对象风险特征识别为锁定目标客户、用户画像及精准营销奠定坚实基础。
目前,针对手机消费贷款信用风险评估研究较少,但可以借鉴商业银行客户、互联网P2P借款人、中小企业等评估对象的信用风险测度方法。
一是针对客户信用风险分级,设定贷款决策信用评分的阈值来控制风险。Norden和Weber(2004)利用事件分析法验证了股市和信用违约互换市场(CDS)与三大机构的信用评级存在相互影响[1]。迟国泰等(2014)利用G1法、均值方差法、拟合分布和模拟评分法将46家商业银行信用风险进行九级分类[2]。赵志冲等(2017)以等级信用差值最大化为目标构建了信用分级模型,解决了信用等级与违约损失率非一致性问题[3];张卫国等(2018)提出基于非均衡模糊近似支持向量机的P2P借款人六梯度信用评级方法[4]。
二是通过统计计量、机器学习及两者结合的方法来提高评估模型准确率,验证其可行性。统计计量方面包括多元线性回归、判别分析、Logistic回归、数学规划等方法[5,6],机器学习方面包括SUM、神经网络、决策树、随机森林等方法[7-11];两者结合的方法包括Lasso-logistic回归、Adaptive lasso-logistic回归、Logistic-SVM回归等[12,13]。其他方法方面,Yang和Shi(2009)引入免疫算法建立个人违约的信用风险模型,对比采用ROC检验的Logistic模型,该模型在双抗体人工免疫理论下对数据敏感度更高,更具备智能性和动态性[14]。Wekesa等(2012)采用比例风险模型方法估计贷款申请人的违约风险,结果表明性别、就业部门和教育水平在信用风险模型中不显著;然而,婚姻状况、年龄居家自有率和居留时间是显著的[15]。张润驰和杜亚斌(2018)改进经典加权k均值聚类算法,提出了多预测器粒子群优化加权k均值聚类算法(MPWKM)模型,解决了权重选择问题[16]。
三是信用风险的动态评估方法,与静态模型相比,动态评估能克服信息突变下的结果失真问题[17,20]。
综上所述,国内外学者针对消费贷款信用风险的研究,往往遵循经济理论逻辑或数据事实导向单一思路。传统计量方法侧重研究信用风险的影响因素,而依靠经济学直觉选取变量可能存在遗漏变量、内生性、反向因果等问题;数据挖掘方法揭示信用风险要素的高相依度,泛化结果准确率高,但统计相关或数理相关往往缺乏可靠的经验依据。为此,本文在借鉴传统信用风险评估方法基礎上,提出个体信用风险评价模型,利用随机森林方法违约样本与正常样本差异度的先验规律,挖掘用户违约诱因特征信息,并进行模型训练得到用户画像,由此得到风险因素重要性排序结果;然后,利用逻辑回归模型对其进行边际分解,得到各维度下个体信用贷款违约概率结果,并结合事实依据和理论逻辑来提供防范手机消费信贷信用风险的可行建议。
二、实证方法应用
(一) 算法及模型简介
1.随机森林算法。随机森林算法利用Boost-strap抽样法从原始训练集N中抽取N个样本,然后对 N 个样本分别建立决策树模型,每棵决策树都由根节点、叶节点和树枝组成,其中每个决策树模型均包含随机M个变量属性,以M个特征中最佳分裂方式对该节点进行分裂,每棵树都完整生长而不进行剪枝,得到组合分类器。利用 N个决策树模型分别对每个测试样本分类,得到 N 种分类结果,最后对N种分类投票决定其最终分类结果。
本文选取基尼系数(Gini)作为分裂或竞争规则。
分类数采用Gini系数的减少量测度异质性下降的程度,其数学表达式为:
2. Logistic模型。Logistic的条件概率为:
(二)样本及变量说明
1.样本来源。手机分期消费贷款数据来源于中国云南省某金融机构线下在2017年3月-12月的手机分期消费贷款客户跟踪数据③,共5900条原始数据,筛选得到4475条有效数据,其中逾期违约数据1578条,非违约数据2897条,组成实验的全样本。假设总共有N个样本,则每个样本被选中的概率是1/N,未被选中的概率是1-1/N,那么某样本没有出现在训练集中的概率就是(1-1/N)n。当N 趋于无穷大时,这一概率趋近于 0.368。本文随机从样本中按比例选取30%为测试集,则剩余70%作为训练集。数据样本见表1。
2.变量定义及说明。本文选择用户是否逾期违约作为信用风险的响应变量,个体信用风险评估是一个典型二元分类器问题,当客户出现违约时取1,否则取0。借鉴其他学者相关研究,客户消费信贷信用风险影响因素涵盖个体特征、社交环境、用户兴趣和消费能力等多个方面。变量赋值及说明见表2。
3.数据预处理。通过利用数据合并、数据清洗和数据采样等手段对数据预处理,充分保障实验结果准确性、完整性、一致性、惟一性、适时性、有效性。通过插值法来补齐不完整、缺失部分数据,利用统计检验对错误值、异常值和重复值进行检测并及时删除。尤其是针对客户违约与非违约数据类别不平衡问题,采用过采样(Synthetic Minority Oversampling Technique、Border-line SMOTE、Adaptive Synthetic Sampling)、欠采样(Near Miss)、过采样和欠采样结合(SMOTE+ENN、SMOTE+Tomek)等技术,调整样本范围。
三、实证结果及分析
(一)变量重要性识别
本文初步选择40个变量作为可能影响个体消费贷款信用风险因子(见表2),但上述变量并不完全符合个体信用风险预测,可能存在多重共线性、自相关等不利因素,从而降低预测精准度和有效性,因此,从初始变量中识别和遴选出核心变量是建立个体信用风险评估指标体系的关键。
从表3可以看出,个体信用违约风险最显著的影响因子是X9(入网时长),其Gini指标平均下降值为46.193;其次是X5(业务类型)、X21(交往圈人数)、X10(所属地市)、X25(终端个数)、X12(客户月流量)、X22(交往圈移动用户占比)、X13(终端时长)、X11(客户星级)、X19(通话活跃天数)等因素,它们对个体信用违约存在较大影响;而最不显著的是X36(国际交往圈占比)、X16(是否校园网)、X24(紧急联系人终端)、X27(阅读类APP天数)、X31(是否网购)、X37(交往圈星级)、X18(单位类型)、X17(是否实名)等变量。
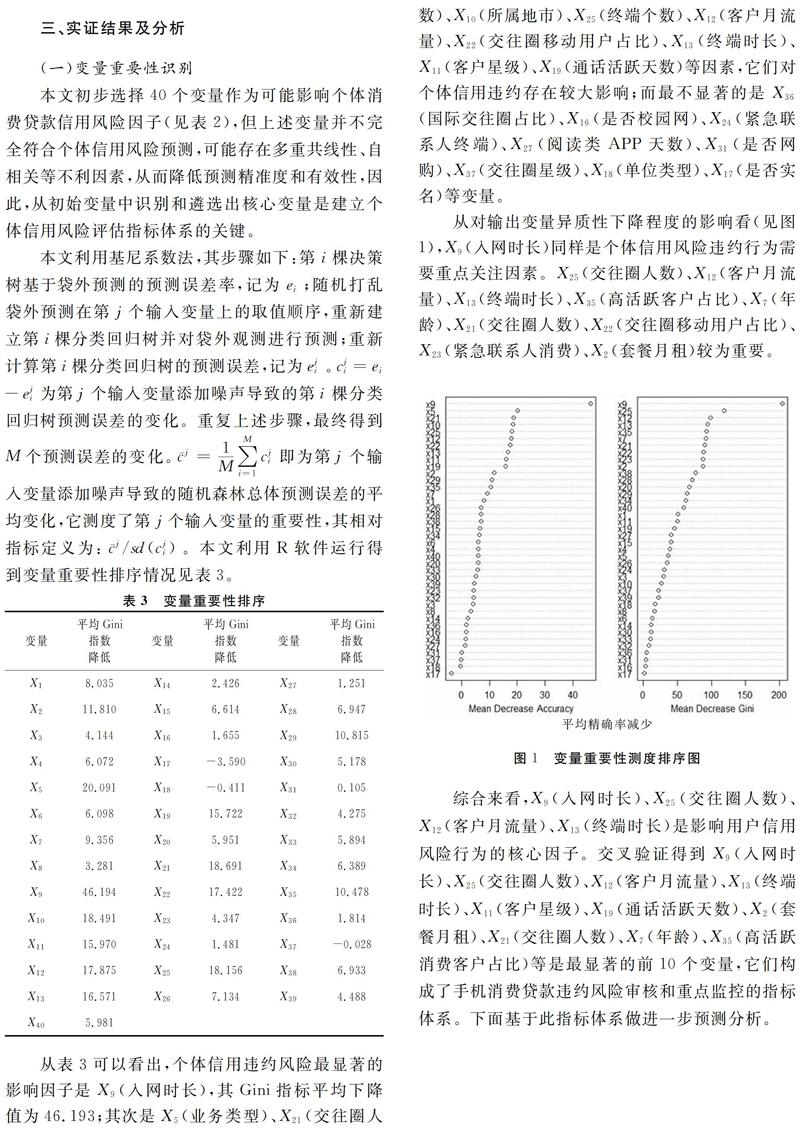
从对输出变量异质性下降程度的影响看(见图1),X9(入网时长)同样是个体信用风险违约行为需要重点关注因素。X25(交往圈人数)、X12(客户月流量)、X13(终端时长)、X35(高活跃客户占比)、X7(年龄)、X21(交往圈人数)、X22(交往圈移动用户占比)、X23(紧急联系人消费)、X2(套餐月租)较为重要。
综合来看,X9(入网时长)、X25(交往圈人数)、X12(客户月流量)、X13(终端时长)是影响用户信用风险行为的核心因子。交叉验证得到X9(入网时长)、X25(交往圈人数)、X12(客户月流量)、X13(终端时长)、X11(客户星级)、X19(通话活跃天数)、X2(套餐月租)、X21(交往圈人数)、X7(年龄)、X35(高活跃消费客户占比)等是最显著的前10个变量,它们构成了手机消费贷款违约风险审核和重点监控的指标体系。下面基于此指标体系做进一步预测分析。
(二)实验效果检验
本文通过构建多指标体系评价算法实验效果,其中精准率(precision)表示预测为正例的样本中,真实为正例的比例;召回率(recall)定义为真实为正例中为正例的比例;准确率(accuracy)计算在所有样本里面预测正确的比例。
最终利用精准率、召回率和准确率、f1-score和ROC面积比等五个指标来衡量算法效果。从表5可见,非平衡样本的五个指标值分别为0.73、0.72、0.72、0.70和0.646,对应的平衡样本五个指标分别为0.73、0.74、0.74、0.72和0.676,说明平衡样本之后各项指标都有提升,且算法的整体效果较好。
除此之外,引入ROC曲线进一步刻画模型的分类效果,ROC横坐标表示FRP,纵坐标表示TPR,对于一个分类器,改变实验设计阈值,每一个阈值都可以得到ROC曲线。其中FRP(伪正类率)表示预测为正但实际为负的样本占所有负样本的比例,TPR(真正类率)表示预测为正且实际为正的样本占所有正样本的比例,实际上与召回率含义相同(见图2、3)。对比图2和图3可以看到,样本平衡前后的ROC曲线都呈现折线形,算法泛化能力强,具有较强的适应性,且平衡样本之后ROC面积比值有所提高,说明平衡样本有效提高了算法精度。
(三)Logistic回归结果
通过构建用户违约事件的影响因素逻辑回归模型,并利用Stata软件得到实证结果(见表6)。从表6结果来看,X9(入网时长)、X25(终端个数)、X12(客户月流量)、X13(终端时长)、X11(客户星级)、X19(通话活跃天数)、X2(套餐月租)、X21(交往圈人数)、X7(年龄)、X35(高活跃客户占比)对违约风险都存在一定程度的影响。其中X9(入网时长)、X12(客户月流量)、X11(客户星级)、X19(通话活跃天数)、X2(套餐月租)、X7(年龄)、X35(高活跃客户占比)与违约风险负相关。事实上,用户入网时间越长、年龄越大,客户星级越高,表示用户稳定性更高,更有可能拥有良好的信用;通話活跃天数越大、客户流量消费越大,套餐月租越高,表示用户对手机实际用途更加重视,对手机依赖程度越高,用户粘性越强。X25(终端个数)、X13(终端时长)、X21(交往圈人数)、X35(高活跃客户占比)与违约风险正相关。终端个数越多、交往圈人数越多,高活跃客户占比越大,说明用户对单一手机品牌依赖程度低,社交网络关系越复杂,手机消费更新换代越快,则用户违约的概率越高。同时,从模型1结果来看,入网时长、交往圈人数、客户月流量、终端时长分别提高1%,个体违约风险分别提高-0.039%、3.18%、-0.01%、-1.06%,说明用户对手机社交、娱乐功能和品牌忠诚度的重视程度与信用违约概率的相依度越来越高,且社交功能和娱乐功能越丰富,平均流量消费越大,个体违约的概率越小。
四、结论及政策启示
以上通过利用随机森林算法有效解决风险因子重要性排序问题,结合逻辑回归模型解释风险因子的边际影响,研究表明:入网时长、终端个数、客户月流量、终端时长是基于Gini指数重要性排序下的核心因子,且边际影响为-0.039%、3.18%、-0.01%、-1.06%,且算法整体准确率达到74%,入网时长、客户月流量、终端时长与违约风险负相关,而交往圈人数与违约风险正相关,并由此得到相关的政策启示:
1.通过交叉端口获取数据来研究消费主体信贷行为。当前居民消费正从量向质、从有形商品向品质服务转变,传统信贷数据、消费信息已经得到充分挖掘,而互联网、大数据、云计算和物联网技术的发展,使得通过交叉来源分析消费主体行为成为时下的前沿和趋势。
2.通过社交网络、兴趣热点和消费习惯来多维度识别信贷风险。从消费主体出发研究现实场景带来的消费偏效应要结合时代发展和营销对象的特征因子,而社交网络、兴趣热点和消费习惯无疑是侧面反映消费主体特征的重要方面,消费主体的一致性、偏好性和社交性是影响信贷违约的重要因子,从消费个体画像、消费群体特征到消费细分领域都离不开对多维视角下消费者的微观行为和选择的研究,要想改善供给端产品质量、服务水准必须创造需求、挖掘需求。
3.融合传统计量和数据挖掘技术是未来信用风险识别和评估的方向。长远来看,大数据、云计算和互联网等技术发展提供了海量的个体信用风险数据,如何摆脱数据驱动、算法驱动和数据至上理念,透过数据来挖掘隐含的理性经济行为人决策是未来的重要方向,由信用风险因子的相关关系向因果关系转变,利用前沿的挖掘技术来推动和发展消费信贷理论,既可克服传统计量的主观性,又可为数据实验提供可靠的经验依据和理论逻辑。
注释:
① 数据来源于《中国无线电管理年度报告(2018年)》。
② 数据来源于《中国互联网发展报告(2019)》。
③ 由于消费信贷数据一般涉及商业机密及道德问题,出于实际研究中数据获得渠道的可得性、可靠性考虑,本文选用云南省的数据。
参考文献:
[1] Norden L, Weber M. Informational efficiency of credit default swap and stock arkets: the impact of credit rating announcements[J]. Journal of Banking & Finance, 2004, 28(11):2813-2843.
[2] 迟国泰, 潘明道, 齐菲. 一个基于小样本的银行信用风险评级模型的设计及应用[J]. 数量经济技术经济研究, 2014(6):102-116.
[3] 赵志冲, 迟国泰, 潘明道. 基于信用差异度最大的信用等级划分优化方法[J]. 系统工程理论与实践, 2017, 37(10):2539-2554.
[4] 张卫国, 卢媛媛, 刘勇军. 基于非均衡模糊近似支持向量机的P2P网贷借款人信用风险评估及应用[J]. 系统工程理论与实践, 2018, 38(10):66-78.
[5] Bekhet H A , Eletter S F K . Credit risk assessment model for jordanian commercial banks: neural scoring approach[J]. Review of Development Finance, 2014, 4(1):20-28.
[6] 付永贵, 朱建明. 基于大数据的网络供应商信用评估模型[J]. 中央财经大学学报, 2016(8):74-83.
[7] 肖会敏, 候宇,崔春生. 基于BP神经网络的P2P网贷借款人信用评估[J]. 运筹与管理, 2018,27(9):112-118.
[8] Zhang Z L . Identification of credit risk of personal loan in commercial bank based on SVM[J]. Applied Mechanics and Materials, 2013, 281:682-687.
[9] 陆爱国, 王珏, 刘红卫. 基于改进的SVM学习算法及其在信用评分中的应用[J]. 系统工程理论与实践, 2012, 32(3):515-521.
[10]Namvar A, Siami M, Rabhi F, et al. Credit risk prediction in an imbalanced social lending environment[J]. 2018,11(1):925-935.
[11]Zhang Z , Cao M . Notice of retraction research of credit risk of commercial bank's personal loan based on CHAID decision tree[C].International Conference on Artificial Intelligence. IEEE, 2011.
[12]張奇, 胡蓝艺, 王珏. 基于Logit与SVM的银行业信用风险预警模型研究[J]. 系统工程理论与实践, 2015, 35(7):1784-1790.
[13]阮素梅, 周泽林. 基于L1惩罚Logit模型的P2P网络借贷信用违约识别与预测[J]. 财贸研究, 2018(2):54-63.
[14]Yang Y , Shi X H . Personal credit risk measurement: bilateral antibody artificial immune probability model[J]. Systems Engineering-Theory Practice, 2009, 29(12):88-93.
[15]Wekesa O A, Samuel M, Peter M. Modelling credit risk for personal loans: cox proportional hazards model approach[J]. Far East J.theor.stat, 2012, 40(2):107-125.
[16]张润驰, 杜亚斌. 基于粒子群优化聚类算法的多预测器信用评估模型[J]. 系统工程, 2017(10):154-158.
[17]Zhang Y , Chen L , Zhou Z , et al. A geometrical method on multidimensional dynamic credit evaluation[J]. International Journal of Information Technology & Decision Making, 2011,7(1):103-114.
[18]Jing H, Yang W S. Structural design of dynamic credit evaluation system oriented multi-service principal[C].International Conference on Information Management,2012.
[19]Huang Q H, Sun J, Mao W D. Dynamic modeling on credit risk evaluation with fixed time window and imbalanced ensemble of support vector machine[J]. Recent Patents on Computer Science, 2012, 5(1):51-58.
[20]張发明. 一种融合 SOM 与 K-means 算法的动态信用评价方法及应用[J]. 运筹与管理, 2016(6):186-192.
(责任编辑:宁晓青)
