基于知识图谱的学位论文送审专家推荐方法
2019-11-21王泽林广艳谭火彬张铄孟烈
王泽,林广艳,谭火彬,张铄,孟烈
(北京航空航天大学 软件学院,北京 100191)
0 引言
学位论文是硕士和博士研究生培养最重要的一个环节,由于学位论文的专业性,对学位论文水平的评价必须依赖于合适的学术专家,这对于研究生论文管理者是一个很大的挑战,如何在保证公平公正的情况下,找到最合适的学术专家进行论文评审是迫切需要解决的问题。而推荐系统和推荐算法[1],就是解决这一难题的重要手段。
传统的论文评审方式多采用部分匿名评审的方式,但这一评审流程仍存在诸多问题[2]:(a)目前研究领域细化,尤其是博士论文,研究内容更加专业化。在匿名评审中,管理部门很难对论文内容、作者研究方向以及评审人研究背景有全方面的了解,如果评审专家不匹配,评审人对论文所研究的领域不够了解,不仅极大影响评价结果客观性,还损害了专家对评审工作的热情,而利用专家推荐算法,可以有效解决这个问题;(b)目前大的研究领域下有着繁杂的研究方向,不同领域和学科间相互交叉,界限划分模糊。而论文的关键词、分类号等原生信息虽有一定的划分,但模糊性极强,管理部门难以从中有效提取论文的最为精准的领域归属,通过构建领域知识图谱,可以有效实现领域概念对齐,将论文进行精确标记和分类,从而有效推荐出同领域评审专家,实现精确推荐。综上,构建一个学术领域知识图谱,将学术领域的概念进行定义和对齐,并基于图谱提出一种学位论文的评审专家推荐算法,显得尤为重要。
1 相关工作
知识图谱的概念最早由Google公司提出,是一种结构化的语义知识库[3],Google公司通过从网页中抽取概念及关系来构建知识库,使检索服务更加精准高效。目前国内外已有一些开源的知识图谱,但大部分图谱的领域限定性较强,在不同场景下的复用性较差。本文所研究构建的学术领域知识图谱的专业性较高,开源的通用知识图谱无法满足需求,因此需要依据学术数据重新抽取构建,以实现领域概念的精准对齐。
传统意义上的论文推荐系统是为用户推荐与其研究兴趣相关的论文信息,目的是帮助用户在大量的论文文献中快速准确地发现自己可能关心的内容[4]。Beel统计分析了与传统论文推荐系统相关的200多篇英文文献[5]:55%的系统使用基于内容过滤的方法(content-based filtering,CBF),18%的系统使用协同过滤(collaborative filtering,CF),16%的系统使用基于图的方法(graph-based),少量系统采用混合推荐或基于规则的方法。主流使用的内容过滤和协同过滤都有着一定的缺陷:CBF的方法存在内容冷启动问题,CF的方法存在用户冷启动问题。考虑到本文的数据特性,本文在内容过滤方法的基础上,使用基于知识图谱和内容过滤相结合的方法进行推荐。
目前在推荐系统领域,已经提出了基于知识的推荐算法,通过将知识以网络形式进行表达,从网络知识中挖掘用户的知识需求。文献[6]构建了融合上下文信息的知识图谱,使用基于深度学习的网络表示方法Node2Vec抽取知识图谱特征,与用户的兴趣迁移模型混合构建混合推荐模型来实现推荐。文献[7]在文献[6]的基础上,引入了排序学习模型,通过排序学习衡量这些多维特征的权重比例,解决了不同特征的融合问题,有效的提高了推荐算法的性能。文献[8]在知识图谱的结构基础上,提出了一种基于图神经网络的协同过滤算法,可以显式地将User-Item的高阶交互编码进Embedding中来提升Embedding的表示能力,进而提升整个推荐效果。
2 基于图谱的推荐方法
本文提出了一种基于知识图谱的学位论文送审专家推荐方法KGRec(Knowledge Graph-based Recommendation)。文章基于自底向上的知识图谱构建技术[9],从大量论文数据中抽取领域概念及概念间的同义关系和共现关系,并进行知识融合对齐,构建起学术领域知识图谱;使用基于TextRank[10]的方法提取学位论文中的候选关键词,形成关键词向量;使用基于TextRank与逆文档频率(Inverse Document Frequency,IDF)的方法对评审专家进行关键词向量提取,并剔除无意义的高权重词;利用Levenshtein Distance算法[11]计算出候选关键词与节点的距离,实现关键词向量到节点向量的加权映射;通过共现度计算扩充学位论文的节点映射向量;最终根据送审论文与专家的向量余弦值计算相似度,获取得分最高的评审专家,实现学位论文最匹配送审专家的推荐。总体方案如图1所示。

Fig.1 Knowledge graph-based recommendation algorithm图1 基于知识图谱的论文推荐算法
2.1 领域知识图谱构建
领域知识图谱是以学术领域概念作为节点,以概念间的关系为边组成的关系网络。通过构建领域知识图谱,可以有效解决同一意义的领域概念不同表示形式的对齐问题,从而实现对专家和论文的所属领域精准标记分类,将其有效对应到领域知识图谱中。
2.1.1 领域知识图谱构建
通过观察和分析数据,将领域概念及其关系构成的本体(Ontology)结构定义为一个4元组:
O=
(1)C为领域概念的集合;
(2)V为领域概念的值的集合,每个领域概念值用其在论文数据集中的出现频次进行表示;
(3)M为领域概念与其值的映射;
(4)R为领域概念之间的关系,包括领域层级关系和领域共现关系。共现关系的关系值用领域概念在论文数据集中共现的频次表示。
模型示意结构如图2所示。
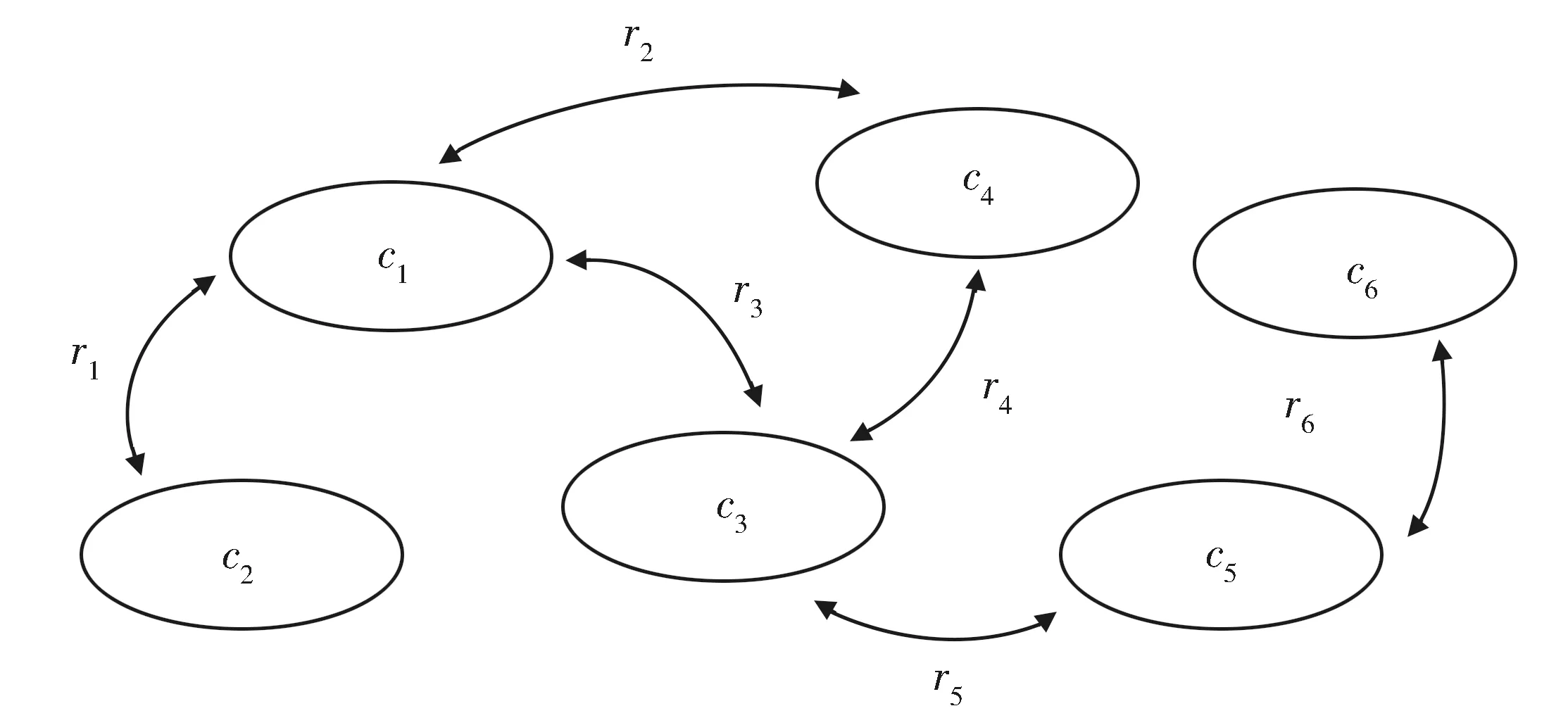
Fig.2 Academic domain knowledge graph model图2 学术领域知识图谱示意模型
2.1.2 概念关系抽取
构建知识图谱,首先就是抽取核心的领域概念,对于学位论文研究领域来说,虽然有明确的所属学科的界定,然而各个学科的具体研究领域并没有统一的标准。而且学科间的领域交叉,跨学科跨领域的研究日渐增多,因而对于领域这一繁杂的概念,并未形成统一的明确的分类和定义。国家科技资源部所给出的领域分类[12],是目前最为学者们所认可的,可以作为领域知识图谱的核心概念枝干,并沿用其给定的领域分级结构表示图谱中的领域层级关系,图3给出了信息科学领域的部分示例。在此基础上,再由大量论文数据进行概念抽取和补充,并融入领域间的共现关系描述,形成学术领域知识图谱。
Fig.3 Schematic diagram of domain division of NMST图3 国家科技资源部部分领域分级示意图
学术论文中的关键词是具有一定规范的名词、动词、词组,包括学科技术名词、动词、词组,专有术语,物品名称和产品型号以及少部分因技术发展产生的自由词[13]。通过对大量论文中的关键词进行抽取和词频统计分析,发现词频数高于指定阈值的关键词,具有一定规模的研究学者和明确的领域概念特征,因此将这类关键词加入领域概念集合中以丰富图谱。将同篇论文中的关键词以共现关系边进行概念联结,将大样本下的共现次数作为边的描述权值。
2.1.3 同义概念对齐
现在同义异型的概念对齐方式主要有三种:模式匹配、基于知识库和机器翻译[14]。模式匹配要求语料文本具有一定的长度并满足一定的模式约束,对于资源要求性较高,难以在当前场景下进行发挥;现有知识库如知网、WordNet等,虽然知识覆盖范围较宽,但其适用范围较窄,难以使用这些知识库去发现学术领域概念间的关系。本文结合论文资源本身的特点,采用机器翻译与英汉互译相结合的方式实现同义概念对齐。
对于初始时无英文对照的领域概念,采用机器翻译获取其对应的英文表示。对于从论文中补充的领域关键词,由于论文资源本身的特殊性,每篇学位论文中,都会给出论文的中文关键词及其对应的英文关键词。这些数据是用户提供的标记数据,对齐程度很高。本文通过不同作者在中英文翻译时使用词汇的差异,来发现同义异型的概念信息,实现同义概念对齐。
将概念集合记为C={c1,c2,…,cn},每个概念ci初始为一个中英对应集合ci={chi,eni},则同义概念对齐算法为
(1)
将对齐后的结果记为
ci={ci1,ci2,…,cimi} .
(2)
对齐结果示例:{主成分分析,主元分析,主元分析方法,主元成分分析,主要成分分析,主成分分析法,主分量分析,主分量分析法,principal component analysis,PCA,principle component analysis}为同义领域概念的不同表述形式,通过同义概念对齐算法,最终对齐到知识图谱中的相同概念节点。
通过知识图谱的构建和同义概念的对齐,既便利了对学位论文和评审专家的精确分类和标签,又有效解决同领域论文和专家因为领域概念表述不一而丢失推荐的问题。
2.2 关键词抽取
关键词抽取分为对学位论文的关键词抽取和评审专家的关键词抽取,目的是将输入的文本数据转化为候选关键词特征向量,以便于到知识图谱的映射计算。本文使用基于TextRank的抽取算法对论文的关键词进行抽取,使用TextRank与逆文档频率IDF相结合的方法对评审专家的关键词进行抽取,最终分别抽取出学位论文和评审专家的候选关键词特征向量。
2.2.1 论文关键词抽取
学位评审论文因其格式限定,具有定义规范的结构化文本数据。本文使用基于TextRank的抽取算法,把输入的结构化论文数据分割成若干组成单元并建立图模型,利用投票机制对文本中的重要成分进行投票排序,从中抽取论文关键词。
候选关键词抽取算法为:

输入: Paperi={p1,p2,p3,…,pn}Paperi表示一篇论文,其中p1,p2,p3,…,pn表示论文的标题、关键词、摘要等不同结构部分的文本内容。输出:G=(V,E)G=(V,E)为候选关键词的有向有权图。For pj of Paperi Sentence cutting Part of speech tagging Stop words filteringThen get pj={kj1,kj2,kj3,…,kjn}Set Node Set V={}For pj of Paperi For kij of pjV=V∪{kij} Then get V={v1,v2,v3,…,vt}Set Edge Set E={}For vi of V For vj of VIf vi and vj in K-Len WindowE=E∪(vi,vj)∪(vj,vi) Then get G=(V,E)
在图G=(V,E)中,将所有指向点vi的点的集合记为In(vi),将所有vi指向的点的集合记为out(vi)。则在图G=(V,E)中,节点vi基于TextRank算法的得分递归计算公式为
(3)
其中d为阻尼系数,一般取值为0.85。wji表示有向图G=(V,E)中节点vj指向节点vi的权重,用于表示节点间转移概率的大小。由递归公式可知,图中任意节点的分值由其相邻节点的投票贡献组成,因此wji的构建是实现关键词分值递归计算的关键。在关键词抽取的过程中,wji的大小主要与两个因素有关:a)指向节点vi的不同节点的个数;b)节点vi的出现频次数。用W表示节点vi的整体影响力,分别用a,b表示两个影响因素所占影响力比重,则W=a+b;用函数a(vi,vj)和b(vi,vj)分别表示两个因素从节点vi传到节点vj的影响力大小,则
wji=a×a(vi,vj)+b×b(vi,vj) .
(4)
将所有wji构建成候选词的影响力转移矩阵M,则M为

(5)
论文Paperi的关键词点集合V={v1,v2,v3,…,vt},记初始分值为S0,则S0为
(6)
考虑非连通图存在的情况,则论文得分的递归计算公式为[15]
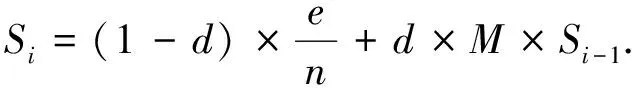
(7)
其中d为阻尼系数,e为一个所有分量为1,维数为t的向量。
通过多次公式递归,迭代传播各节点的权重直至收敛,可将输入的学位评审论文数据表示为一个关键词特征向量Pi:
Pi=(〈vi1,si1〉,〈vi2,si2〉,…,〈vit,sit〉) ,
(8)
vij表示论文Paperi权值排序后的第j个关键词,sij表示vij对应的权重得分。
2.2.2 专家关键词抽取
每位评审专家都发表过一定的学术成果,这些论文蕴含着每位专家的主要研究方向和兴趣点,是对专家进行关键词提取的核心数据。本文考虑到部分专家可能会在不同领域发表多篇弱关联论文,为避免抽取出的专家关键词存在大量无意义的数据,需要在TextRank算法基础上,引入关键词逆文档频率IDF,来对同一专家多篇论文抽取关键词时进行权值优化。因此,本文采用TextRank×IDF的方法进行专家的关键词提取。
本文中IDF的计算公式为
(9)
其中|D|表示语料库中某一专家所发表的论文总数;|{j:ti∈dj}|表示该专家所发表的论文集合中包含关键词ti的论文数目。在抽取一位评审专家的关键词时,先对专家发表的所有论文数据使用TextRank算法得出候选关键词以及其对应的权值,由式(8)知第i篇论文的抽取的候选关键词向量结果Pi,再使用IDF算法:

(10)
算出所有关键词在该专家所有论文集合下的总分值。最终可以得到第i个评审专家的候选关键词特征向量Ki:
(11)
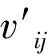
2.3 领域图谱向量转换
Levenshtein距离[11]是指两个字串之间进行转换所需的最少编辑操作次数。将评审论文和评审专家的关键词特征向量分别与领域知识图谱的领域节点间通过Levenshtein距离计算实现加权转换,可以实现论文关键词特征向量、专家关键词特征向量和领域概念节点的对齐,获取论文和专家最为匹配的领域特征向量。
2.3.1 论文领域特征向量映射
由式(8)得第i篇论文的关键词特征向量Pi=(〈vi1,si1〉,〈vi2,si2〉,…,〈vit,sit〉),由式(2)得领域知识图谱的概念集合为C={c1,c2,…,cn},其中ci={ci1,ci2,…,cimi};将字符串s的长度用函数L(s)表示,将两个字符串s1,s2间的Levenshtein距离用函数LD(s1,s2)表示,则一个候选关键词vij与一个领域概念ck之间的相似度sim(vij,ck)为
(12)
则通过相似度计算和排序,论文关键词特征向量Pi映射到学术领域知识图谱的领域特征初始向量PAi为
PAi=(〈ci1,simi1〉,〈ci2,simi2〉,…,〈cit,simit〉) ,
(13)
其中simij取值为
(14)
考虑到论文关键词特征向量Pi中包含的低于一定阈值的无意义候选关键词以及映射领域特征初始向量PAi中的低于一定阈值相似度的领域概念会在综合加权后影响向量结果,将候选关键词阈值记为α,相似度阈值记β,则过滤后的学术领域知识图谱的领域特征向量PBi为
PBi=(〈ci1,swi1〉,〈ci2,swi2〉,…,〈cir,swir〉) ,
(15)
其中,swij为论文的候选词初始权重值与领域概念图谱相似度的综合量化权值,即swij=sij×simij,特征向量PBi仅保留满足sij>α,simij>β过滤条件下的〈cij,swij〉向量结果。
2.3.2 论文共现向量扩充
对部分存在文段简短、描述模糊等问题的论文数据,所能提取到的高于阈值的候选关键词较少,可以利用领域知识图谱的节点间的共现关系,用高频共现概念扩充论文的图谱节点映射向量。
若图谱中,节点(ci,vi)和节点(cj,vj)间存在共现关系边(ri,j,vi,j),则共现度Coi,j为
(16)
由式(15)可以得到论文Paperi候选关键词特征向量Pi映射到图谱的领域特征向量PBi,记共现度阈值为γ,则由节点间共现关系边扩充后的领域特征向量PCi为
(17)
其中cijk是与节点cij存在共现关系边且满足共现度Coij,ijk>γ的第k个节点。
为方便推导,将扩充后的PCi进一步记为
PCi=(〈ci1,cwi1〉,〈ci2,cwi2〉,…,〈cim,cwim〉) .
(18)
2.3.3 专家领域特征向量映射
KBi=(〈ci1,cwi1〉,〈ci2,cwi2〉,…,〈cir,cwir〉) ,
(19)
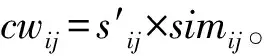
2.4 匹配相似度计算
根据式(18)和式(19),可以得到送审学位论文映射到领域知识图谱下的特征向量PCi和每位评审专家映射到领域知识图谱下的特征向量KBi。在进行学位论文与评审专家的匹配相似度计算时,需要综合考量二者在领域知识图谱下映射节点的匹配数量以及节点权值进行计算。因此本文使用基于向量余弦值的匹配相似度计算方法,计算送审论文与专家间的匹配相似度。匹配相似度计算公式为
(20)
利用该公式,可以计算出每篇送审学位论文的所有专家的匹配分数,实现论文的最佳匹配评审专家的推荐。
3 实验
3.1 实验数据及评测指标
考虑数据数量和质量因素,本文构建一个学科下的领域知识图谱进行验证,对于其他学科而言,推荐方法有类比性。为验证推荐算法的性能,本文选择计算机科学与技术学科,采集该学科的学术论文194 926篇,用于构建学科知识图谱;采集相关评审专家1 148名,专家所发表的学术论文15 373篇作为候选评审专家以及对应论文成果数据;采集100篇计算机科学与技术的博硕士毕业论文作为待评审论文。为进行对照,分别对100篇待评审论文采取人工推荐方式、传统向量相似度计算方式和本文中的基于知识图谱的图谱向量相似度计算方式来对论文进行送审专家推荐,并将人工推荐方式的推荐结果作为评价基准。
为方便说明比较,本文中将传统的特征向量间相似度计算的算法vsRec(vector similarity Recommendation)的计算方式定义为式(8)向量与式(11)向量的余弦值。
令u表示审稿人,R(u)表示在根据人工推荐方式做出的推荐列表,T(u)表示使用推荐算法做出的推荐列表。则推荐结果的准确率为
(21)
推荐结果的召回率为
(22)
综合考察准确率和召回率的F值为
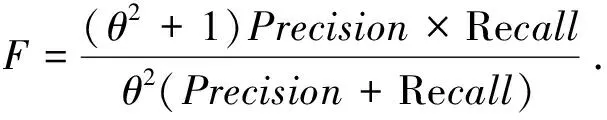
(23)
3.2 实验结果分析
本实验中,为避免偶然性,每种算法的实验结果都取多次实验的平均值。阻尼系数d依据之前textRank算法的工作,取值0.85;为平均节点的不同影响力因素的影响值,影响因素a比重取值50%,影响因素b比重取值50%。阈值变量与实验结果呈单调函数关系,通过反复实验,发现关键词权重阈值α取0.25,相似度阈值β取0.8,共现度阈值γ取0.1时,KGRec的推荐结果达到收敛。
由于应用场景的领域特殊性,数据集与传统的公共推荐标注数据集不同,一般的推荐算法无法在本场景下复用,实验中使用KGRec、vsRec与bpr这3种不同的推荐算法作为对照,其中bpr算法在实验过程中由于待评审论文与专家之间本身没有交互,导致矩阵过于稀疏,因此引入了一些内容上的相似性,利用专家对论文的评分进行加权平均,其中的权重为内容相似度,从而得到专家对论文的评分估计。最终推荐结果如表1所示。

表1 实验结果对比
实验结果表明,相较于传统的向量相似度计算方式,本文基于知识图谱的图谱向量相似度计算方式可以有效地弥补论文关键词提取模糊、论文关键词与专家关键词同义异型难以匹配以及领域标签分类不明确的问题,从而使得推荐结果有了全面的优化和提升。
4 结论
本文通过构建领域知识图谱、关键词特征向量抽取、领域节点向量的加权映射以及匹配相似度计算实现学位论文最为匹配的评审专家推荐。在构建知识图谱时,采用自底向上的图谱构建方法从大量论文数据中抽取出领域概念以及概念间的同义关系和共现关系,进行知识融合对齐,构建出学术领域知识图谱;在进行关键词抽取时,用基于TextRank的关键词抽取方法对待审论文进行关键词向量提取,用TextRank与IDF相结合的方式对专家进行关键词向量提取;在进行向量与图谱节点间加权映射时,并利用Levenshtein距离计算关键词特征向量与领域知识图谱的领域概念间的距离,实现关键词特征向量到领域概念节点向量的加权映射;最终根据送审论文与评审专家图谱向量的余弦相似度计算,计算出匹配得分最高的评审专家,实现学位论文的送审专家推荐。通过实验验证,该推荐算法能够较好地实现学位论文评审专家的推荐,对今后的学位论文送审专家的推荐工作有较高的意义。但本文仍存在着不足,在后续的工作中,作者将进一步改进和优化算法,提高推荐结果的准确度,在更大的数据集上进行验证。
